






为什么叫支持向量机?
对于感知机而言,我们只需要找到一个超平面,将所需分类的两个类别分开即可。
假设集合,代表所有误分类点,感知机的损失为所有误分类点所对应的集合,取其最小值,就可以得到超平面的参数
。
然而,通过这个损失函数选择出来的分类超平面并不是唯一的, 比如图中的虚线可以作为超平面,红线和蓝线也可可能是这个数据集的分离超平面。
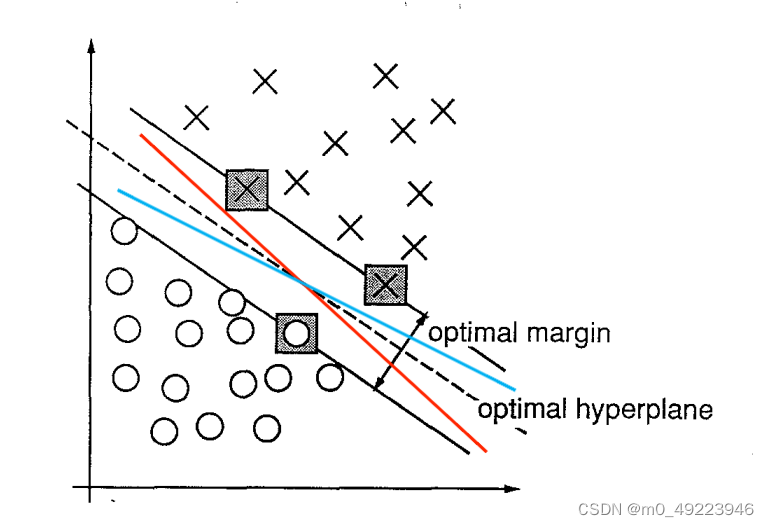
对于这些超平面,他们分类的性能是不一样的,比如我们有另外一个数据集,它比这个数据集多了一个样本点,如图中蓝圈。对于虚线来说它仍能将所有样本正确分类,而蓝线就出现了误分类。

这里就涉及到了分类确信度的问题,假设我们所拥有的样本点为,我们可以用样本点到决策面的距离来度量确信度。
除了分类确信度,我们还需要度量分类的正确性。如果分类正确,那么与
同号。即当样本点为正样本时,样本点位于决策面上方,
,
;当样本点为负样本时,样本点位于决策面下方,
,
。
接下来,我们如何将分类确信度和分类正确性结合起来呢?
我们可以定义这样一个指标:几何间隔。
每个样本点都可以通过上式计算出几何间隔,那么哪些样本点最有用呢?
我们现在最需要的是离决策面最近的样本点。对几何间隔取最小值,即可得到最近的样本点。
回到最开始的这幅图,我们可以看到,这样的点正类有两个,负类有一个。如果我们想要找到最佳的超平面,我们自然希望,能够把这些样本点分的越远越好,也就是把上述最小的间隔最大化。
因此我们可以在几何间隔最小化的基础上加上最大化来求取参数。
前面我们提到了只有距离决策面最近的点才有用,所以只需要找到距离超平面最近的点,它们决定了分离超平面。我们把训练数据集的样本点中与分离超平面距离最近的样本点的实例成为支持向量(support vector)。
内容来自:【合集】十分钟 机器学习 系列视频 《统计学习方法》















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









