









目录
1. 为什么要构建特征库?
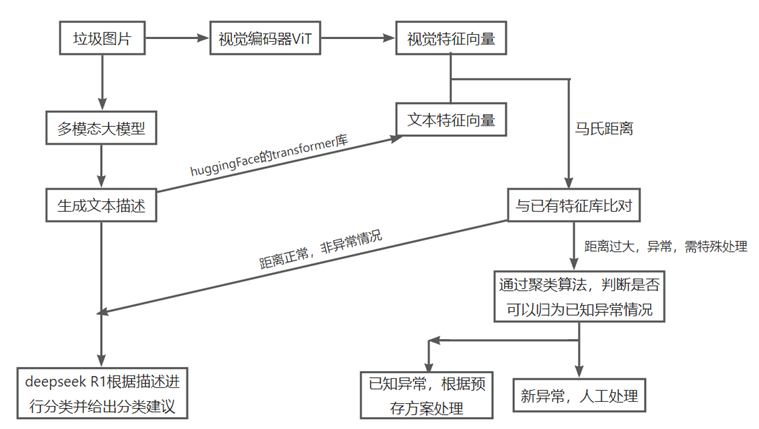
图1展示了《基于大模型和聚类算法的垃圾分类平台》的技术流程图,可以看到特征库的作用主要是当用户新上传垃圾图片时,与图片转为的文本特征向量和视觉特征向量计算马氏距离。如果距离过大,超出阈值,就会被判定为异常情况,后面会再进行一系列处理。
【1】:异常的出现可能有多种原因,常见的有对某个垃圾的视觉判断为“塑料”,但在其文本描述中出现“纸质感”;复合材质,即某个垃圾既有金属反光,又有塑料纹理。
2. 特征库构建总体流程
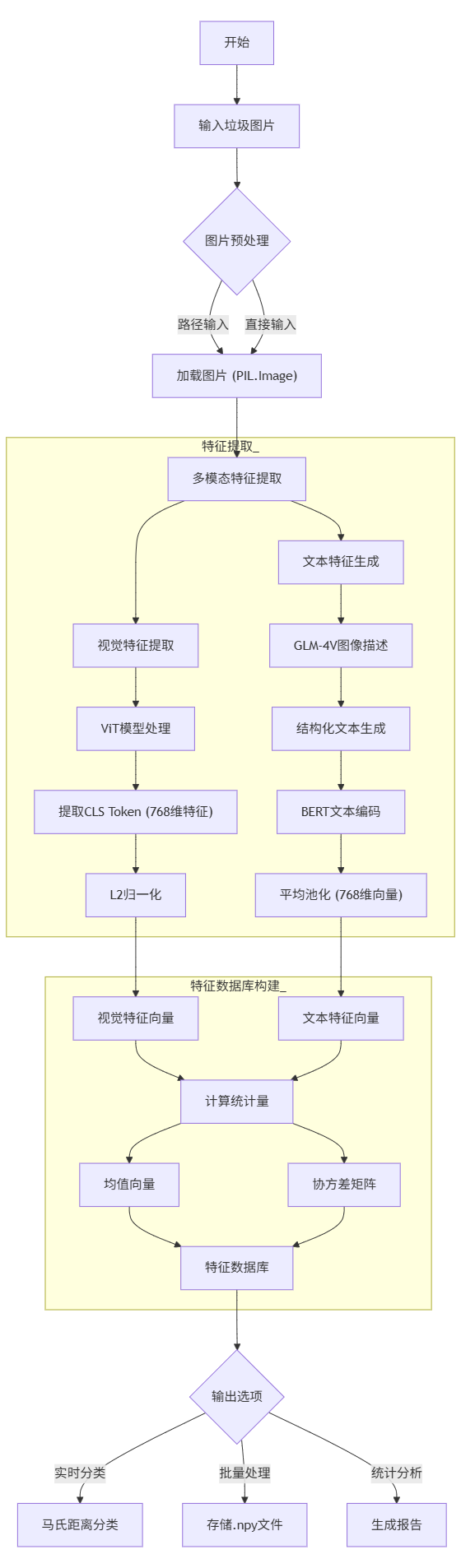
图2展示了特征库构建的总体流程:
① 输入处理阶段
- 支持两种输入方式:图片路径或直接图像数据
- 统一转换为PIL.Image对象进行标准化处理
② 多模态特征提取
- 视觉特征通路,首先由调用ViT模型,将图像分块嵌入,再经过Transformer编码,提取CLS Token,最后对特征进行归一化。
- 文本特征通路,首先将随机抽取的图片经由【glm-4v-flash】生成结构化描述,接着由【bert-base-chinese】进行分词,形成文本编码,经平均池化后,最终形成文本向量。
③ 特征数据库构建
- 统计量采用矩阵计算
- 特征库数据结构。如下方代码所示,按照垃圾四大类别进行分类,包括可回收物,厨余垃圾,有害垃圾和其他垃圾,每个类别都包括mean_visual(视觉特征向量均值),cov_visual(视觉特征向量协方差矩阵),mean_text(文本特征向量均值)和cov_text(文本特征向量协方差矩阵)。
self.feature_db = {
"recyclable": {"mean_visual": None, "cov_visual": None, "mean_text": None, "cov_text": None},
"hazardous": {"mean_visual": None, "cov_visual": None, "mean_text": None, "cov_text": None},
"kitchen": {"mean_visual": None, "cov_visual": None, "mean_text": None, "cov_text": None},
"other": {"mean_visual": None, "cov_visual": None, "mean_text": None, "cov_text": None}
}④ 输出模块
3. 视觉特征向量提取
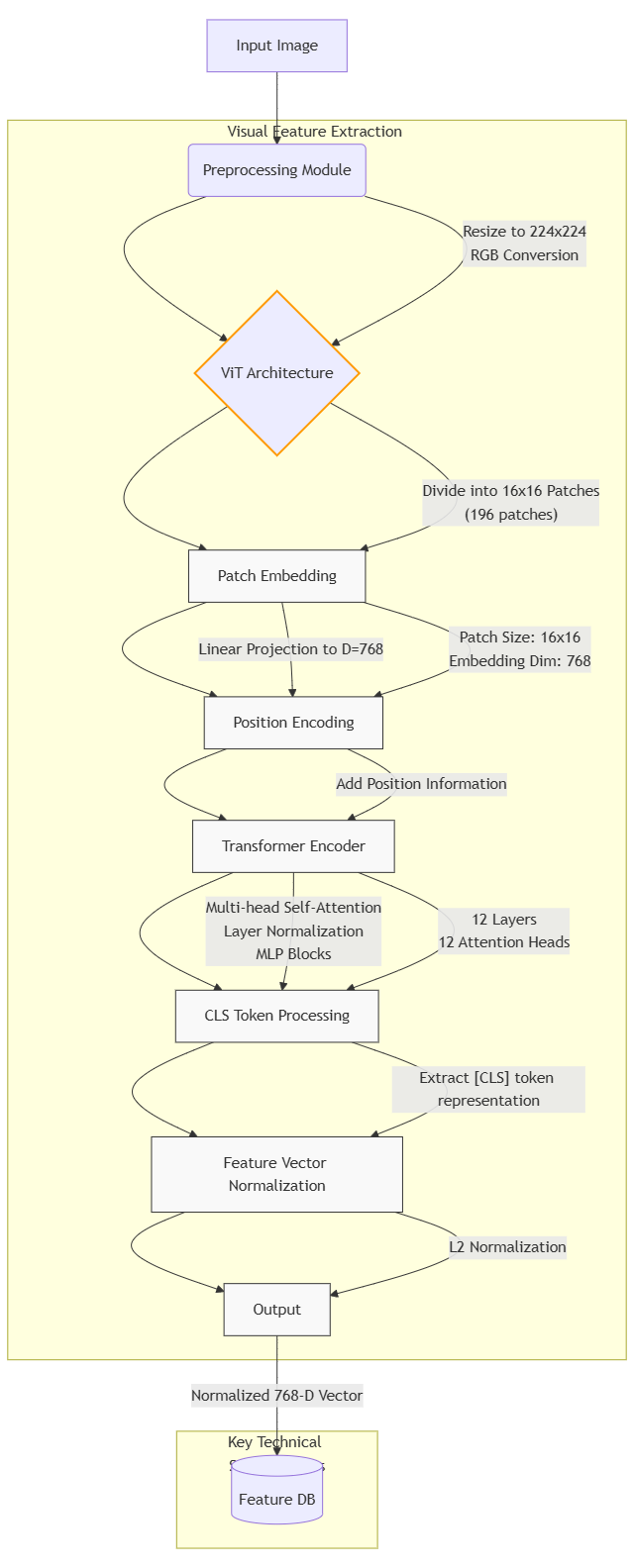
视觉特征向量提取我采用了模型【google/vit-base-patch16-224】。
输入图像首先经过标准化预处理(缩放到224×224分辨率、RGB通道归一化),随后被分割为16×16的图像块,每个块通过线性投影转换为768维嵌入向量,并叠加可学习的位置编码。这些向量经过12层Transformer编码器的迭代处理,最终提取序列首位的[CLS]标记,将其作为全局图像表示,再经过层归一化和L2归一化,最后输出768维视觉特征向量。
核心代码如下:
class ViTFeatureExtractor:
"""ViT视觉特征提取器
功能: 基于Vision Transformer提取图像特征
"""
def __init__(self, model_name: str = "google/vit-base-patch16-224", device: str = None):
"""
初始化ViT特征提取器
params:
- model_name: 预训练模型名称
- device: 计算设备(cpu/cuda)
"""
self.device = device or ("cuda" if torch.cuda.is_available() else "cpu")
self.processor = ViTImageProcessor.from_pretrained(model_name)
self.model = ViTModel.from_pretrained(model_name).to(self.device).eval()
self.feature_dim = 768 # ViT-base模型的特征维度
def extract_features(self, image_path: Union[str, Image.Image]) -> np.ndarray:
"""
提取图像特征
params:
- image_path: 图片路径或PIL Image对象
return:
- np.ndarray: 归一化后的视觉特征向量
"""
if isinstance(image_path, str):
image = Image.open(image_path).convert("RGB")
else:
image = image_path
# 图像预处理
inputs = self.processor(images=image, return_tensors="pt").to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
# 使用[CLS]标记作为图像表示
features = outputs.last_hidden_state[:, 0, :]
# L2归一化
features = torch.nn.functional.normalize(features, p=2, dim=1)
return features.cpu().numpy().squeeze(0)技术流程图如下:
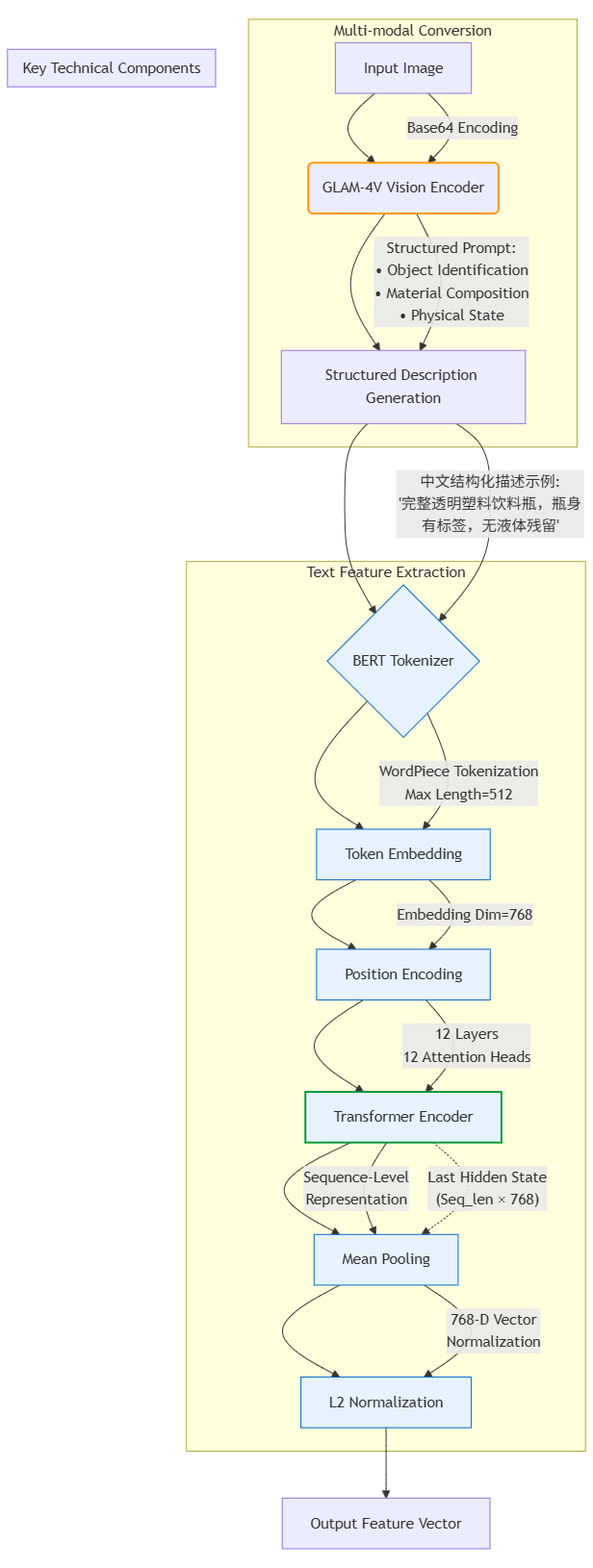
4. 文本特征向量提取
我采用了【bert-base-chinese】来进行文本特征向量提取。首先将垃圾图片,由glm-4v-flash模型,转为结构化文本描述。该描述文本随后会被bert-base-chinese做分词处理,经过12层Transformer编码器提取词向量,通过平均池化层聚合句子级语义,最终输出768维归一化文本特征向量。
核心代码如下:
class MultiModalFeatureExtractor:
"""初始化多模态特征提取器
功能: 集成视觉特征提取和文本特征提取能力
"""
def __init__(self):
"""初始化多模态特征提取器"""
# 视觉特征提取器(ViT)
self.vit_extractor = ViTFeatureExtractor()
# 文本特征提取器(bert-base-chinese)
self.text_tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese")
self.text_model = AutoModel.from_pretrained("google-bert/bert-base-chinese").eval()
def image_to_text(self, image_path: str) -> str:
"""
图像到文本转换
params:
- image_path: 图片文件路径
return:
- str: 结构化文本描述
"""
with open(image_path, 'rb') as img_file:
img_base = base64.b64encode(img_file.read()).decode('utf-8')
# 调用GLM-4V API获取结构化描述
response = client.chat.completions.create(
model="glm-4v-flash",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": img_base}},
{"type": "text", "text": structured_prompt}
]
}
]
)
return response.choices[0].message.content
def text_to_vector(self, text: str) -> np.ndarray:
"""
文本到向量转换
params:
- text: 输入文本
return:
- np.ndarray: 文本特征向量(768维)
"""
# 文本分词和编码
inputs = self.text_tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = self.text_model(**inputs)
# 使用平均池化获得句子级表示
sentence_embedding = outputs.last_hidden_state.mean(dim=1)
return sentence_embedding.numpy().squeeze(0)
def extract_visual_features(self, image_path: str) -> np.ndarray:
"""
提取视觉特征
params:
- image_path: 图片路径或PIL Image对象
return:
- np.ndarray: 视觉特征向量(768维)
"""
return self.vit_extractor.extract_features(image_path)技术流程图如下:
5. 最终结果
模型最终输出是一个结构化的多模态特征库,包含四类垃圾(可回收、有害、厨余、其他)的视觉和文本特征统计量。每个类别存储两个768维均值向量(视觉/文本)和两个768×768协方差矩阵,构成高斯分布参数化表示。特征库的存储格式是.npy文件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









