







kubectl get crd | grep coreos
alertmanagers.monitoring.coreos.com 2020-03-26T12:27:08Z
podmonitors.monitoring.coreos.com 2020-03-26T12:27:08Z
prometheuses.monitoring.coreos.com 2020-03-26T12:27:09Z
prometheusrules.monitoring.coreos.com 2020-03-26T12:27:10Z
servicemonitors.monitoring.coreos.com 2020-03-26T12:27:11Z
默认情况下,prometheus-serviceMonitorKubelet.yaml关联的kubelet的https-metrics(10250)端口拉取metrics数据,为了安全起见,kubelet关闭了匿名认证并开启了webhook授权,访问https-metrics端口需要认证和授权。http-metrics(10255)为只读端口,无须认证和授权。但默认情况下是不打开的,可以如下配置打开该端口。注意所有安装了kubelet服务的集群主机都需要配置。
vi /var/lib/kubelet/config.yaml
readOnlyPort: 10255
systemctl restart kubelet
然后将prometheus-serviceMonitorKubelet.yaml文件中的https-metrics更改成http-metrics即可。
cd ..
vi prometheus-serviceMonitorKubelet.yaml
port: https-metrics
scheme: https
#改为
port: http-metrics
scheme: http
为了Kubernetes集群外访问prometheus、grafana和alertmanager,可以配置NodePort或者Ingress,此处简单起见,直接修改为NodePort。
vi prometheus-service.yaml
type: NodePort
nodePort: 39090
vi grafana-service.yaml
type: NodePort
nodePort: 33000
vi alertmanager-service.yaml
type: NodePort
nodePort: 39093
prometheus-serviceMonitorKubeScheduler.yaml定义了监控kube-scheduler的ServiceMonitor。serviceMonitorKubeScheduler通过k8s-app=kube-scheduler和kube-scheduler服务关联,但Kubernetes缺省没有创建该service。可以先看一下对应的kube-scheduler-k8s-master这个pod,然后直接在manifests目录下定义kube-scheduler服务,下面统一部署。10251是kube-scheduler服务metrics数据所在的端口。
kube-scheduler:调度器主要负责为新创建的pod在集群中寻找最合适的node,并将pod调度到Node上。
kubectl get pod kube-scheduler-k8s-master -nkube-system --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kube-scheduler-k8s-master 1/1 Running 4 103d component=kube-scheduler,tier=control-plane
vi prometheus-kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
同样,prometheus-serviceMonitorKubeControllerManager.yaml定义了监控kube-controller-manager的ServiceMonitor。serviceMonitorKubeControllerManager通过k8s-app: kube-controller-manager和kube-controller-manager服务关联,但Kubernetes缺省没有创建该service。可以先看一下对应的kube-controller-manager-k8s-master这个pod,然后直接在manifests目录下定义kube-controller-manager服务。10252是kube-controller-manager服务metrics数据所在的端口。
kube-controller-manager:管理控制中心负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
kubectl get pod kube-controller-manager-k8s-master -nkube-system --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kube-controller-manager-k8s-master 1/1 Running 4 103d component=kube-controller-manager,tier=control-plane
vi prometheus-kubeControllerManagerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
继续安装。
kubectl apply -f .
alertmanager.monitoring.coreos.com/main created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager created
secret/grafana-datasources created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-pods created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-statefulset created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-operator created
prometheus.monitoring.coreos.com/k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-rules created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
service/kube-controller-manager created
service/kube-scheduler created
查看Kubernetes资源,可以看出prometheus-k8s和alertmanager-main的控制器类型为statefulset,
kubectl get all -nmonitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 4 12h
pod/alertmanager-main-1 2/2 Running 0 12h
pod/alertmanager-main-2 2/2 Running 6 12h
pod/grafana-58dc7468d7-d8bmt 1/1 Running 0 12h
pod/kube-state-metrics-78b46c84d8-wsvrb 3/3 Running 0 12h
pod/node-exporter-6m4kd 2/2 Running 0 12h
pod/node-exporter-bhxw2 2/2 Running 6 12h
pod/node-exporter-tkvq5 2/2 Running 0 12h
pod/prometheus-adapter-5cd5798d96-5ffb5 1/1 Running 0 12h
pod/prometheus-k8s-0 3/3 Running 10 12h
pod/prometheus-k8s-1 3/3 Running 1 12h
pod/prometheus-operator-99dccdc56-89l7n 1/1 Running 0 12h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main NodePort 10.1.96.0 <none> 9093:39093/TCP 12h
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 12h
service/grafana NodePort 10.1.165.84 <none> 3000:33000/TCP 12h
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 12h
service/node-exporter ClusterIP None <none> 9100/TCP 12h
service/prometheus-adapter ClusterIP 10.1.114.161 <none> 443/TCP 12h
service/prometheus-k8s NodePort 10.1.162.187 <none> 9090:39090/TCP 12h
service/prometheus-operated ClusterIP None <none> 9090/TCP 12h
service/prometheus-operator ClusterIP None <none> 8080/TCP 12h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 3 3 3 3 3 kubernetes.io/os=linux 12h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 12h
deployment.apps/kube-state-metrics 1/1 1 1 12h
deployment.apps/prometheus-adapter 1/1 1 1 12h
deployment.apps/prometheus-operator 1/1 1 1 12h
NAME DESIRED CURRENT READY AGE
replicaset.apps/grafana-58dc7468d7 1 1 1 12h
replicaset.apps/kube-state-metrics-78b46c84d8 1 1 1 12h
replicaset.apps/prometheus-adapter-5cd5798d96 1 1 1 12h
replicaset.apps/prometheus-operator-99dccdc56 1 1 1 12h
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 12h
statefulset.apps/prometheus-k8s 2/2 12h
地址:http://192.168.1.55:39090/。
查看Prometheus的targets页面,可以看到所有的targets都可以正常监控。
查看Prometheus的alerts页面,可以看到预置了多个告警规则。
地址:http://192.168.1.55:33000/。
Grafana缺省内置了多个dashboard。
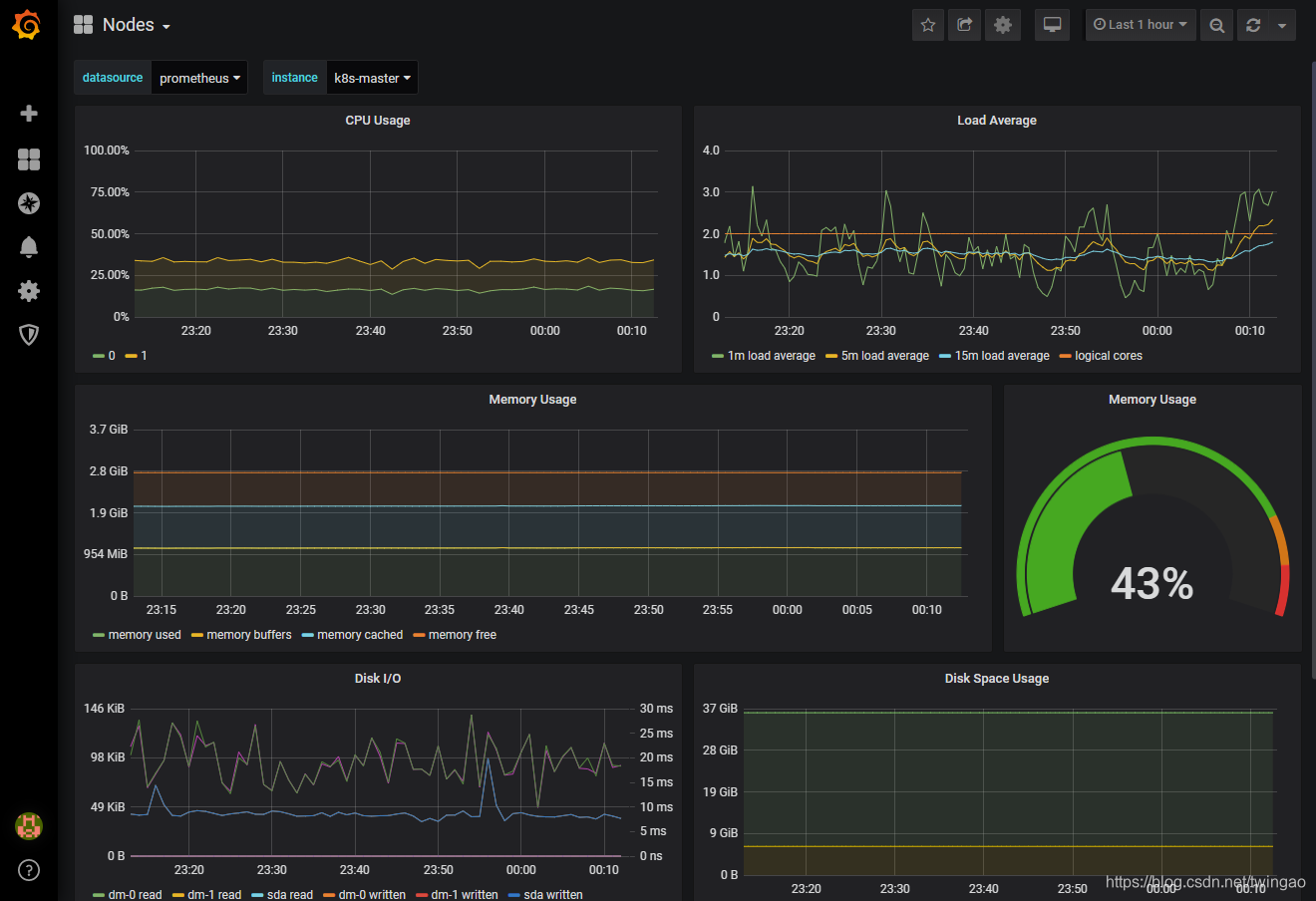
以下为和Node相关的Dashboard,可以看到自动添加了prometheus数据源,可以查看不同Node的监控数据。
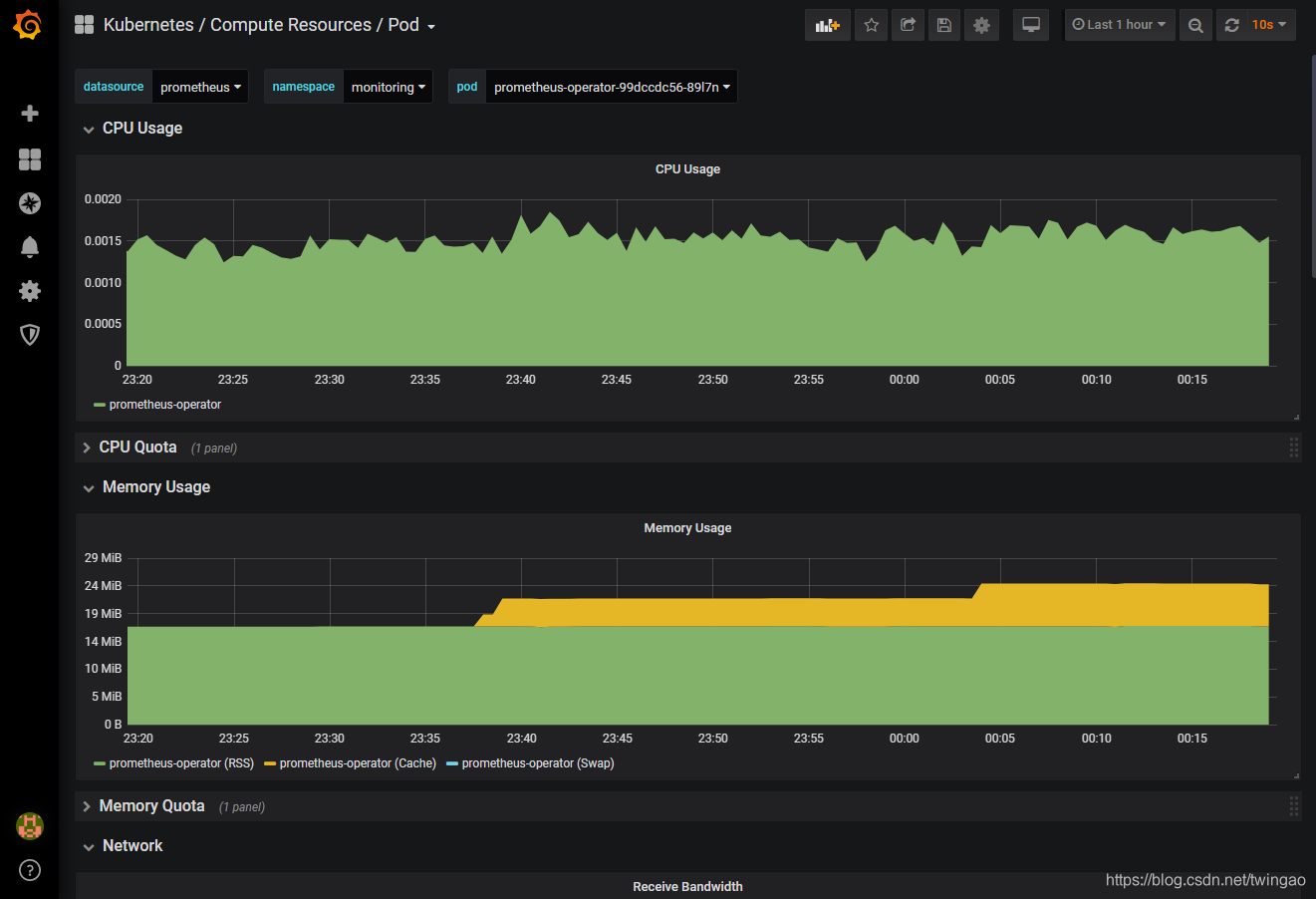
以下为和Pod相关的Dashboard,可以查看不同命名空间和Pod的监控数据。
地址:http://192.168.1.55:39093/。
我们以Nginx Ingress为例,使用Prometheus Operator来监控Nginx Ingress。我们先通过Helm部署,选择nginx/nginx-ingress。
helm repo add nginx https://helm.nginx.com/stable
helm search repo nginx
NAME CHART VERSION APP VERSION DESCRIPTION
bitnami/nginx 5.1.1 1.16.1 Chart for the nginx server
bitnami/nginx-ingress-controller 5.2.2 0.26.2 Chart for the nginx Ingress controller
nginx/nginx-ingress 0.4.3 1.6.3 NGINX Ingress Controller
stable/nginx-ingress 1.27.0 0.26.1 An nginx Ingress controller that uses ConfigMap...
stable/nginx-ldapauth-proxy 0.1.3 1.13.5 nginx proxy with ldapauth
stable/nginx-lego 0.3.1 Chart for nginx-ingress-controller and kube-lego
stable/gcloud-endpoints 0.1.2 1 DEPRECATED Develop, deploy, protect and monitor...
先渲染模板来分析一下,为了集群外访问,“type: LoadBalancer"应该改为"type: NodePort”,并将nodePort配置为固定端口。Pod公开了prometheus端口"containerPort: 9113",我们下面先使用PodMonitor进行监控。
helm template gateway nginx/nginx-ingress
......
# Source: nginx-ingress/templates/controller-service.yaml
apiVersion: v1
kind: Service
metadata:
name: gateway-nginx-ingress
namespace: default
labels:
app.kubernetes.io/name: gateway-nginx-ingress
helm.sh/chart: nginx-ingress-0.4.3
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: gateway
spec:
externalTrafficPolicy: Local
type: LoadBalancer
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
- port: 443
targetPort: 443
protocol: TCP
name: https
selector:
app: gateway-nginx-ingress
---
# Source: nginx-ingress/templates/controller-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gateway-nginx-ingress
namespace: default
labels:
app.kubernetes.io/name: gateway-nginx-ingress
helm.sh/chart: nginx-ingress-0.4.3
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: gateway
spec:
replicas: 1
selector:
matchLabels:
app: gateway-nginx-ingress
template:
metadata:
labels:
app: gateway-nginx-ingress
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9113"
spec:
serviceAccountName: gateway-nginx-ingress
hostNetwork: false
containers:
- image: "nginx/nginx-ingress:1.6.3"
name: gateway-nginx-ingress
imagePullPolicy: "IfNotPresent"
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
- name: prometheus
containerPort: 9113
......
根据上面的分析,设置以下覆盖参数来安装nginx-ingress。
helm install gateway nginx/nginx-ingress \
--set controller.service.type=NodePort \
--set controller.service.httpPort.nodePort=30080 \
--set controller.service.httpsPort.nodePort=30443
查看Kubernetes资源。
NAME READY STATUS RESTARTS AGE
pod/gateway-nginx-ingress-55886df446-bwbts 1/1 Running 0 12m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/gateway-nginx-ingress NodePort 10.1.10.126 <none> 80:30080/TCP,443:30443/TCP 12m
service/kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 108d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/gateway-nginx-ingress 1/1 1 1 12m
NAME DESIRED CURRENT READY AGE
replicaset.apps/gateway-nginx-ingress-55886df446 1 1 1 12m
kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gateway-nginx-ingress-55886df446-bwbts 1/1 Running 0 13m 10.244.2.46 k8s-node2 <none> <none>
可以直接从Pod地址访问metrics。
curl http://10.244.2.46:9113/metrics
# HELP nginx_ingress_controller_ingress_resources_total Number of handled ingress resources
# TYPE nginx_ingress_controller_ingress_resources_total gauge
nginx_ingress_controller_ingress_resources_total{type="master"} 0
nginx_ingress_controller_ingress_resources_total{type="minion"} 0
nginx_ingress_controller_ingress_resources_total{type="regular"} 0
# HELP nginx_ingress_controller_nginx_last_reload_milliseconds Duration in milliseconds of the last NGINX reload
# TYPE nginx_ingress_controller_nginx_last_reload_milliseconds gauge
nginx_ingress_controller_nginx_last_reload_milliseconds 195
# HELP nginx_ingress_controller_nginx_last_reload_status Status of the last NGINX reload
# TYPE nginx_ingress_controller_nginx_last_reload_status gauge
nginx_ingress_controller_nginx_last_reload_status 1
# HELP nginx_ingress_controller_nginx_reload_errors_total Number of unsuccessful NGINX reloads
# TYPE nginx_ingress_controller_nginx_reload_errors_total counter
nginx_ingress_controller_nginx_reload_errors_total 0
# HELP nginx_ingress_controller_nginx_reloads_total Number of successful NGINX reloads
# TYPE nginx_ingress_controller_nginx_reloads_total counter
nginx_ingress_controller_nginx_reloads_total 2
# HELP nginx_ingress_controller_virtualserver_resources_total Number of handled VirtualServer resources
# TYPE nginx_ingress_controller_virtualserver_resources_total gauge
nginx_ingress_controller_virtualserver_resources_total 0
# HELP nginx_ingress_controller_virtualserverroute_resources_total Number of handled VirtualServerRoute resources
# TYPE nginx_ingress_controller_virtualserverroute_resources_total gauge
nginx_ingress_controller_virtualserverroute_resources_total 0
# HELP nginx_ingress_nginx_connections_accepted Accepted client connections
# TYPE nginx_ingress_nginx_connections_accepted counter
nginx_ingress_nginx_connections_accepted 6
......
我们创建PodMonitor,其中几个需要注意的关键点。
- PodMonitor的name最终会反应到Prometheus的配置中,作为job_name。
- PodMonitor的命名空间必须和Prometheus所在的命名空间相同,此处为monitoring。
- podMetricsEndpoints.interval为抓取间隔。
- podMetricsEndpoints.port需要和Pod/Deployment中的拉取metrics的ports.name对应,此处为prometheus。
- namespaceSelector.matchNames需要和被监控的Pod所在的命名空间相同,此处为default。
- selector.matchLabels的标签必须和被监控的Pod中能唯一标明身份的标签对应。
创建Pod对应的PodMonitor。
vi prometheus-podMonitorNginxIngress.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
labels:
app: nginx-ingress
name: nginx-ingress
namespace: monitoring
spec:
podMetricsEndpoints:
- interval: 15s
path: /metrics
port: prometheus
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: gateway-nginx-ingress
kubectl apply -f prometheus-podMonitorNginxIngress.yaml
此PodMonitor其实就是一个配置文件,Prometheus Operator会根据PodMonitor进行Prometheus的相关配置,自动对该Pod进行监控。到Prometheus查看监控目标。注意label中有pod="gateway-nginx-ingress-55886df446-bwbts",标明监控Pod。
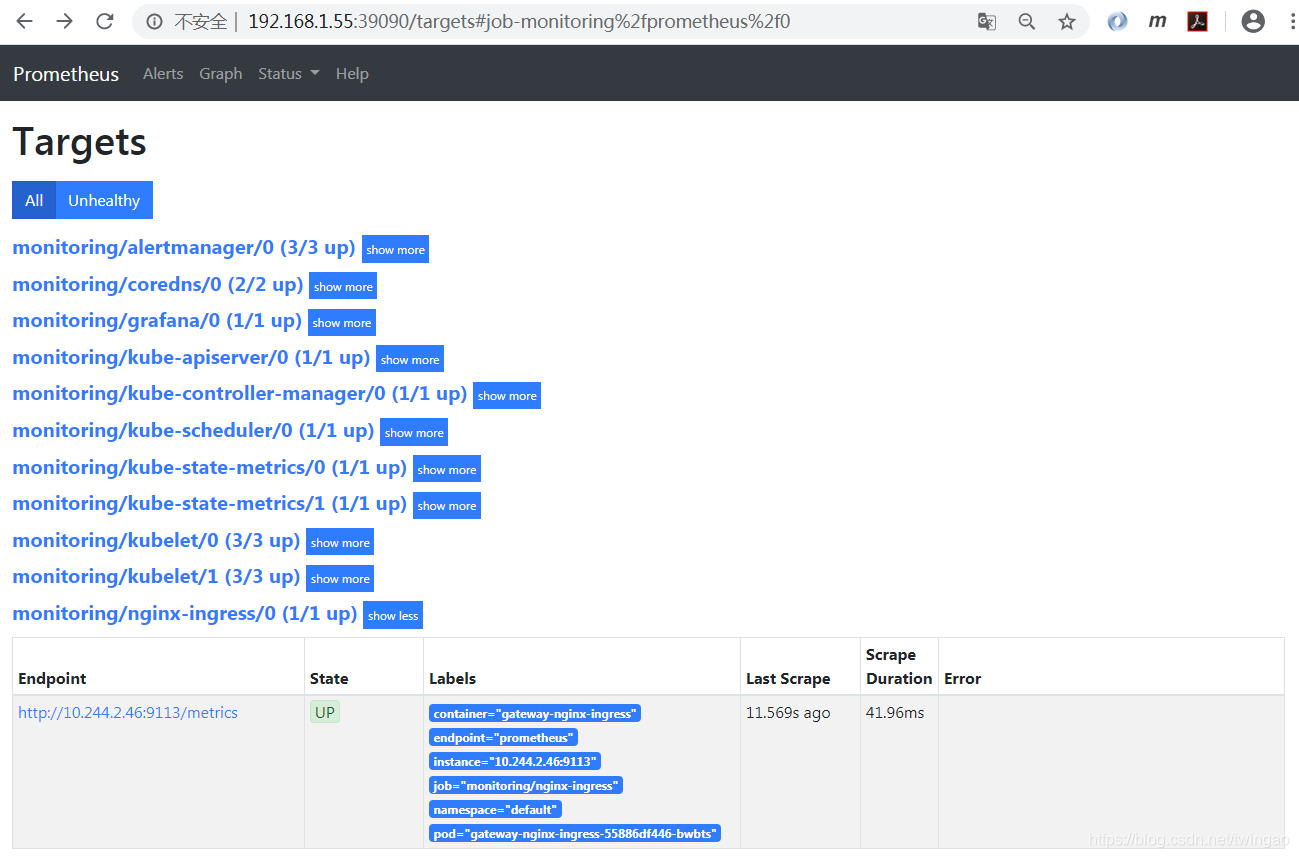
Prometheus已经出现Nginx Ingress相关的配置job_name: monitoring/nginx-ingress/0。
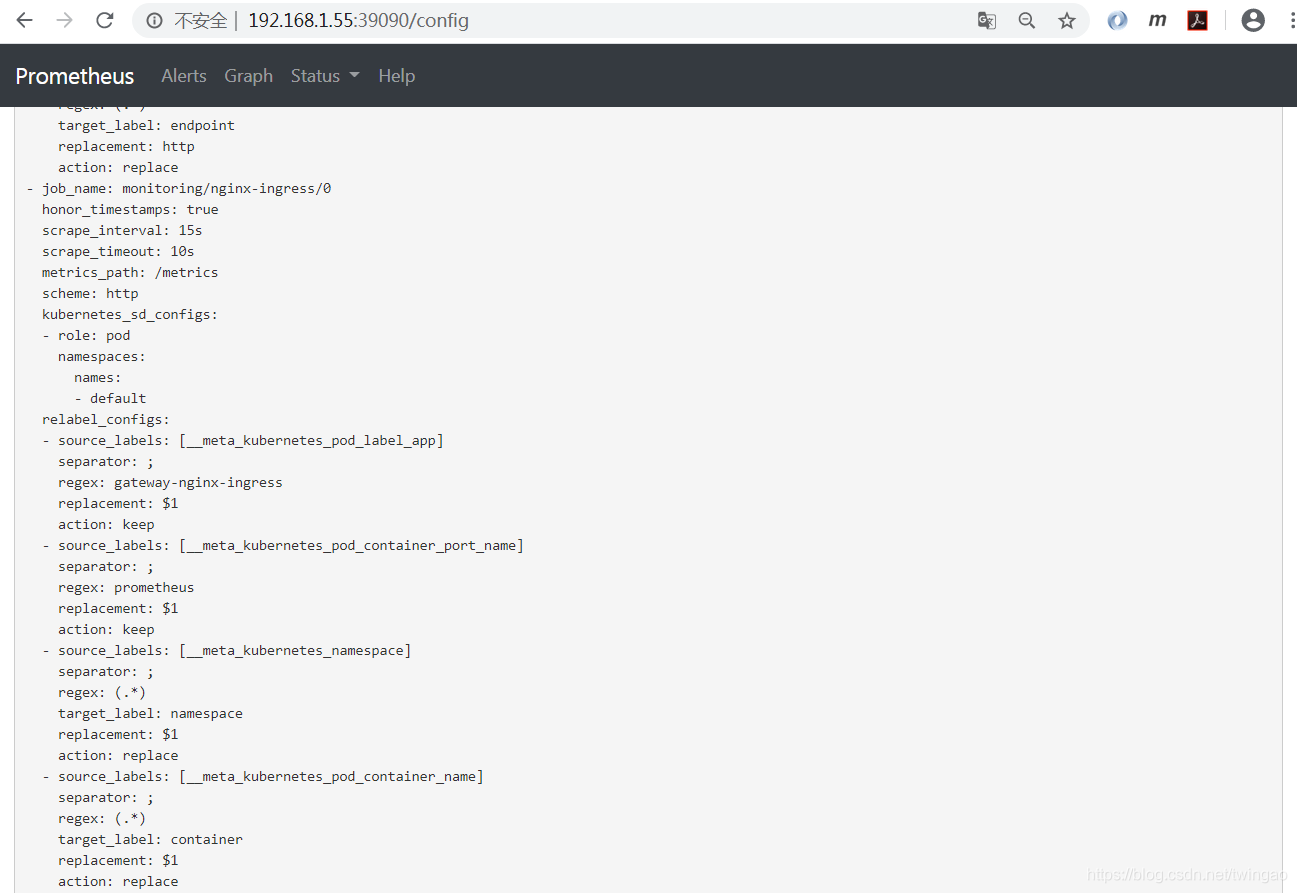
Prometheus监控指标irate(nginx_ingress_nginx_http_requests_total[1m])。
我们仍旧以Nginx Ingress为例,我们先通过Helm部署。
先重新渲染模板来分析一下,Pod公开了prometheus端口"containerPort: 9113",但Service没有公开该端口。而ServiceMonitor恰恰是是通过Service的prometheus端口拉取metrics数据的,所以我们通过controller.service.customPorts来向Service添加该端口。
helm template gateway nginx/nginx-ingress \
--set controller.service.type=NodePort \
--set controller.service.httpPort.nodePort=30080 \
--set controller.service.httpsPort.nodePort=30443
......
# Source: nginx-ingress/templates/controller-service.yaml
apiVersion: v1
kind: Service
metadata:
name: gateway-nginx-ingress
namespace: default
labels:
app.kubernetes.io/name: gateway-nginx-ingress
helm.sh/chart: nginx-ingress-0.4.3
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: gateway
spec:
externalTrafficPolicy: Local
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
nodePort: 30080
- port: 443
targetPort: 443
protocol: TCP
name: https
nodePort: 30443
selector:
app: gateway-nginx-ingress
---
# Source: nginx-ingress/templates/controller-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gateway-nginx-ingress
namespace: default
labels:
app.kubernetes.io/name: gateway-nginx-ingress
helm.sh/chart: nginx-ingress-0.4.3
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: gateway
spec:
replicas: 1
selector:
matchLabels:
app: gateway-nginx-ingress
template:
metadata:
labels:
app: gateway-nginx-ingress
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9113"
spec:
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**


**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)**

**深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**
[外链图片转存中...(img-csC85vrx-1712856227366)]
[外链图片转存中...(img-FPfVyw8D-1712856227366)]
[外链图片转存中...(img-u146GPnV-1712856227367)]
[外链图片转存中...(img-DJtVBMUY-1712856227367)]
[外链图片转存中...(img-0qELG1fF-1712856227367)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)**
[外链图片转存中...(img-YHUxbuBh-1712856227367)]

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









