







引入
在修建道路时,为了让尽可能多的点连通,需要修建连通两个点的公路,这就需要随时询问两个点是否已经连通。
若将已经连通的点看作一个集合,那么修建一条公路的意义,就是合并两个集合,所以如何快速查询两个点是否属于同一个集合,以及快速地合并两个集合,十分重要。
集合
集合与并查集的概念
集合是由一个或多个确定的元素所构成的整体。集合中的元素有如下 三个特征:
-
确定性:一个元素要么属于集合,要么不属于集合。
-
互异性:集合中的元素互不相同。
-
无序性:集合中的元素没有先后顺序。
并查集是一个可以维护集合的数据结构,它能高效支持集合的基本操作:
- 合并两个集合。
- 查询两个指定元素是否属于同一个集合。
需要注意的是,由于计算机存储结构的限制,并查集维护的集合是离散意义下的集合,而不是广义的集合。集合中的元素是有限的。
集合的存储
-
数组存储
存储一个集合最简单的方式就是直接用数组。我们将一个集合的所有元素按某种特定顺序存储在数组里。使用数组存储集合,可以支持较丰富的集合操作,但是维护集合的时间复杂度较高,对于几乎所有操作,单次操作的时间复杂度都是和集合大小成正比的。在C++语言中, 我们可以使用STL中的vector来实现数组存储集合。
-
链表存储
可以模仿数组存储方式,将集合中的元素存储在一个链表里。链表一大好处是可以避免元素的复制,这对于合并操作是比较有帮助的,在定位元素所在的集合的两端后,直接将两个集合的端点相接即可合并完成。然而,使用链表维护集合的最坏情况时间复杂度仍然是与集合大小成正比的,在时间效率上还不够优秀。
在 C++ 语言中,我们可以使用 STL 中的 list 来实现链表存储集合。如果题目对时间效率的要求较高,也可以选择自行实现链表。
值得一提的是,假设元素总数是 nn,且仅需要支持合并和查询操作,那 么上述两种方式可以采用启发式合并的技术(即每次将较小集合合并入较大集合并修改较小集合所有元素的信息)做到总时间复杂度 O(n\log_2 n)O(nlog2n)。虽然 单次操作的时间复杂度较高,但是可以证明总时间复杂度是可以接受的。
-
森林存储
这就是并查集。
并查集
因为一个元素只可能属于一个集合,所以我们可以为每一个集合选取一个代表元。于是查询两个元素是否属于同一个集合实际上就是询问两个元素所在集合的代表元是否相同。这个询问的时间复杂度可以利用数组标记优化为 O(1)O(1)。
但是合并两个集合时需要改变其中一个集合中所有元素的代表元,时间复杂度仍然非常高,如何优化呢?
注意到,合并操作的时间复杂度远高于查询操作的复杂度,这启发我们通过一定的方式,提高查询操作的复杂度,降低合并操作的复杂度。
我们并不需要 O(1)O(1) 知道每个元素所属集合的代表元,这启发我们用森林来维护代表元。用森林中的一棵树代表一个集合,树根为对应集合的代表元。
这样,对于每棵树上的元素,查询其代表元时,时间复杂度与树的高度成正比。
对两个集合进行合并操作时,只需将其中一个集合的代表元(树根)指向另一个集合(树)的代表元即可。时间复杂度也与树的高度成正比。
这就是并查集。
并查集是一种树形的数据结构,顾名思义,它用于处理一些不交集的 合并 及 查询 问题。它支持两种操作:
- 查找(Find):确定某个元素处于哪个子集;
- 合并(Union):将两个子集合并成一个集合。
w ⚠️ 并查集不支持集合的分离,但是并查集在经过修改后可以支持集合中单个元素的删除操作(详见 UVA11987 Almost Union-Find)。
定义
int fa[N]; // fa[i]: i 所属的集合(i 的祖先节点)
Copy
初始化
void makeSet(int size) {
for (int i = 0; i < size; i++) fa[i] = i; // i就在它本身的集合里
return;
}
Copy
查找
通俗地讲一个故事:几个家族进行宴会,但是家族普遍长寿,所以人数众多。由于长时间的分离以及年龄的增长,这些人逐渐忘掉了自己的亲人,只记得自己的爸爸是谁了,而最长者(称为「祖先」)的父亲已经去世,他只知道自己是祖先。为了确定自己是哪个家族,他们想出了一个办法,只要问自己的爸爸是不是祖先,一层一层的向上问,直到问到祖先。如果要判断两人是否在同一家族,只要看两人的祖先是不是同一人就可以了。
在这样的思想下,并查集的查找算法诞生了。
此处给出一种 C++ 的参考实现:
int fa[MAXN]; // 记录某个人的爸爸是谁,特别规定,祖先的爸爸是他自己
int find(int x) {
// 寻找 x 的祖先
if (fa[x] == x) // 如果 x 是祖先则返回
return x;
else
return find(fa[x]); // 如果不是则 x 的爸爸问 x 的爷爷
}
Copy
显然这样最终会返回 xx 的祖先。并且上述查询操作的代码的时间复杂度取决于每个集合对应的树的高度。
合并
宴会上,一个家族的祖先突然对另一个家族说:我们两个家族交情这么好,不如合成一家好了。另一个家族也欣然接受了。
我们之前说过,并不在意祖先究竟是谁,所以只要其中一个祖先变成另一个祖先的儿子就可以了。
此处给出一种 C++ 的参考实现:
void unionSet(int x, int y) {
// x 与 y 所在家族合并
x = find(x);
y = find(y);
fa[x] = y; // 把 x 的祖先变成 y 的祖先的儿子
}
Copy
可以看出,合并操作的时间复杂度取决于查找操作的时间复杂度,也就是每个集合对应的树的高度。
时间复杂度优化
不幸的是,上面代码看似优秀,但实际上,在最坏情况下时间复杂度仍然很高——因为森林中树的深度可能比较大。如果我们不停地从一个深度比较大的点向上寻找代表元,时间复杂度就令人难以接受。
下面我们来讲讲上述操作的优化操作。
查找的优化——路径压缩
这样的确可以达成目的,但是显然效率实在太低。为什么呢?因为我们使用了太多没用的信息,我的祖先是谁与我父亲是谁没什么关系,这样一层一层找太浪费时间,不如我直接当祖先的儿子,问一次就可以出结果了。甚至祖先是谁都无所谓,只要这个人可以代表我们家族就能得到想要的效果。 把在路径上的每个节点都直接连接到根上 ,这就是路径压缩。
此处给出一种 C++ 的参考实现:
int find(int x) {
if (x != fa[x]) // x 不是自身的父亲,即 x 不是该集合的代表
fa[x] = find(fa[x]); // 查找 x 的祖先直到找到代表,于是顺手路径压缩
return fa[x];
}
Copy
合并的优化——启发式合并(按秩合并)
一个祖先突然抖了个机灵:「你们家族人比较少,搬家到我们家族里比较方便,我们要是搬过去的话太费事了。」
由于需要我们支持的只有集合的合并、查询操作,当我们需要将两个集合合二为一时,无论将哪一个集合连接到另一个集合的下面,都能得到正确的结果。但不同的连接方法存在时间复杂度的差异。具体来说,如果我们将一棵点数与深度都较小的集合树连接到一棵更大的集合树下,显然相比于另一种连接方案,接下来执行查找操作的用时更小(也会带来更优的最坏时间复杂度)。
当然,我们不总能遇到恰好如上所述的集合————点数与深度都更小。鉴于点数与深度这两个特征都很容易维护,我们常常从中择一,作为估价函数。而无论选择哪一个,时间复杂度都为 O (m\alpha(m,n))O(mα(m,n)) ,具体的证明可参见 References 中引用的论文。
在算法竞赛的实际代码中,即便不使用启发式合并,代码也往往能够在规定时间内完成任务。在 Tarjan 的论文[参考1]中,证明了不使用启发式合并、只使用路径压缩的最坏时间复杂度是 O (m \log n)O(mlogn) 。在姚期智的论文[参考2]中,证明了不使用启发式合并、只使用路径压缩,在平均情况下,时间复杂度依然是 O (m\alpha(m,n))O(mα(m,n)) 。
如果只使用启发式合并,而不使用路径压缩,时间复杂度为 O(m\log n)O(mlogn) 。由于路径压缩单次合并可能造成大量修改,有时路径压缩并不适合使用。例如,在可持久化并查集、线段树分治 + 并查集中,一般使用只启发式合并的并查集。
此处给出一种 C++ 的参考实现,其选择点数作为估价函数:
vector<int> siz(N, 1); // 记录并初始化子树的大小为 1
void unionSet(int x, int y) {
int xx = find(x), yy = find(y);
if (xx == yy) return; // 在同一集合,无需合并
if (siz[xx] > siz[yy]) // 保证小的合到大的里
swap(xx, yy);
fa[xx] = yy;
siz[yy] += siz[xx]; // 更新集合中元素个数
}
Copy
时空间复杂度
时间复杂度
同时使用路径压缩和启发式合并之后,并查集的每个操作平均时间仅为 O(\alpha(n))O(α(n)) ,其中 \alphaα 为阿克曼函数的反函数,其增长极其缓慢,也就是说其单次操作的平均运行时间可以认为是一个很小的常数。
Ackermann 函数 A(m, n)A(m,n) 的定义是这样的:
A(m, n) = \begin{cases}n+1&\text{if }m=0\\A(m-1,1)&\text{if }m>0\text{ and }n=0\\A(m-1,A(m,n-1))&\text{otherwise}\end{cases}A(m,n)=⎩⎪⎪⎨⎪⎪⎧n+1A(m−1,1)A(m−1,A(m,n−1))if m=0if m>0 and n=0otherwise
而反 Ackermann 函数 \alpha(n)α(n) 的定义是阿克曼函数的反函数,即为最大的整数 mm 使得 A(m, m) \leqslant nA(m,m)⩽n 。
时间复杂度的证明见附录。
空间复杂度
显然为 O(n)O(n) 。
模板题与例题
- 合并集合 - TopsCoding —— 模板题
- 连通块中点的数量 - TopsCoding —— 记录集合内节点数量
- 亲戚 - TopsCoding
- 冗余关系 - TopsCoding
- 家庭问题 - TopsCoding
- 通信系统 - TopsCoding
- 打击犯罪 - TopsCoding —— 枚举+并查集
- 格子游戏 - TopsCoding
- 团伙 - TopsCoding —— 反集
- NOI2002 银河英雄传说 - TopsCoding
- 可爱的猴子 - TopsCoding —— 离线算法、删边并查集
- JSOI2008 星球大战 - TopsCoding —— 离线算法、删边并查集
- NOI2015 程序自动分析 - TopsCoding —— 并查集 + 离散化
- NOI2001 食物链 - TopsCoding ——带权并查集
- UVA11987 Almost Union-Find 好像并查集 - TopsCoding ——带权并查集
其他应用
最小生成树算法 中的 Kruskal 和 最近公共祖先 中的 Tarjan 算法是基于并查集的算法。
并查集与反集
引入
我们在做并查集的问题时,一般都是分三步去解决问题的:
- 给定 nn 个点,初始化并查集。
- 给你 mm 个关系(条边),每个关系对应地,连接两个点 x,yx,y 对应的集合。
- 求一些问题:两点之间是否连通、判断连通性、统计连通块个数。
这些都可以通过一些小优化在 O(1)O(1) 的时间内完成处理。
但是,如果在第二步上做一些变更呢?比如给定两种关系。第一种:给定一对朋友关系;第二种, 给定一对敌人关系,满足 敌人的敌人就是朋友。那么传统并查集就捉襟见肘了。(题目:团伙 - TopsCoding)。
此时,反集就派上用场了。
反集
反集的思路是再构造一个集合(称之为反集),然后将“敌人”关系通过原集和反集表示出来。
比如假设有 33 个元素 1,2,31,2,3。我们称他们的反集元素分别为 1',2',3'1′,2′,3′。(如下图)

那么,如何体现 敌人关系 呢?
假如有一对敌人关系 (1,2)(1,2)。
我们只需要连接两条边 (1,2'),(1',2)(1,2′),(1′,2) 就行了。
由于 1'1′ 和 2'2′ 不会相连,所以这在并查集中也就意味着, 这两个结点不会连到一起了,这样,在 1,21,2 之间构成了一个敌对关系。(如下图)

等等!还有一个 敌人的敌人就是朋友 关系,在这里是否是正确的呢?
假如还有一对敌人关系 (2,3)(2,3),那么,根据规则,11 与 33 应该是朋友关系(在一个集合中)。
我们按照上面的规则,连接 (3,2'),(3',2)(3,2′),(3′,2),则图变成了下图这样。图中有两个连通块:\{1,2',3\}{1,2′,3} 和 \{1',2,3'\}{1′,2,3′}。自然地,1,31,3 在一个连通块中了。
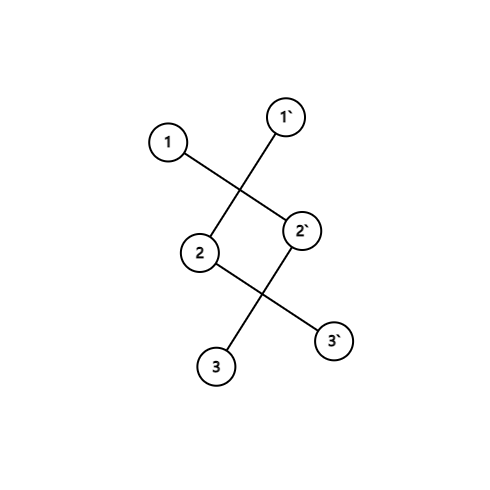
因此,经过这么一处理, 敌人的敌人就是朋友 关系也是正确的。
反集的代码实现
在代码中,我们可以开 2 \times n2×n 的数组,利用 i+n(0<i≤n)i+n(0<i≤n) 来代替上面的 i'i′,初始化时,也别忘了初始化这些节点。
初始化
for(int i = 1; i <= 2 * n; i++)
{
fa[i]=i;
}
Copy
反集操作
cin >> isfriend >> x >> y;
if(isfriend)
{
union(u, v);
}
else
{
union(u, v + n);
union(v, u + n);
}
Copy
反集虽然不是一个特别常见的数据结构,但是在并查集的优化中很有用。
带权并查集
我们还可以在并查集的边上定义某种权值、以及这种权值在路径压缩时产生的运算,从而解决更多的问题。比如对于经典的「NOI2001」食物链,我们可以在边权上维护模 3 意义下的加法群。
















 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











