







数据结构系列(二) 集合的升级——并查集
前言
上一讲我们讲解了集合,以及集合的应用
那么这一章,我们来升级下集合——并查集
一、什么是并查集
并:合并
查:查询
集:集合
即用集合的思想来进行合并和查询
首先它既然是一种集合的数据结构,也是一种算法,那么首先来分析复杂度
先看空间复杂度,集合,如果有 n 项数据,那么空间复杂度就为(n)
在看时间复杂度,并查集的时间复杂度很猛,可以在查询时干到O(1)
在处理时,时间复杂度大概在O(log n)
这个复杂度十分优秀,在下一章图的连通性和连通块的题目中可以代替dfs,优化时间复杂度
注:是指只使用并查集的复杂度,不算其他的解题方法
二、并查集
先来说说并查集的思想
来简单的看道例题
时间限制: 1 Sec 内存限制: 128 MB 文件名 family.*
题目描述:
有 n 个人,编号分别为1 ~ n,这五个人中,可能有几个是亲人
其中,共有 m 组亲戚关系,用一行两个整数 x y 表示,表示 x 和 y 是亲戚
请输出共有几组家庭(及没有亲戚关系)
输入:
第一行两个正整数 n 和 m,表示人数和关系数
以下 m 行,每行两个正整数 x 和 y ,表示一组关系
输出:
一行,一个正整数,表示家庭的数量
样例输入:
5 3
1 4
2 5
5 3
样例输出:
2
数据范围:
n < 10^3
m < 10^4
我们画个图分析一下:
这里运用了点树的说法,但应该能看懂
抽象一个数组,下标为这个人的编号,存储的数据为它指向的父节点(它的亲戚)
先进行初始化数组,让其自己指向自己(及没有指向的父节点)
首先把每个人看成一个节点,关系看成一条边,即:

首先插入第一条边,拥有亲戚关系的 1 和 4 这两个人
可以认定 4 为 1 的亲戚,把 4 添加到 1 的身上,让 4 的父节点信息指向编号 1,即

以此类推,将其他的节点信息指向其父节点

这时,我们处理完了所有的数据,将所有的节点都指向了其父节点,找到了所有的亲戚
即把有亲戚关系的人放进一个树里
最后只要统计森林中树的个数就可以啦~
怎么判断这个节点是不是树根呢?
根据其合并的原理不难发现,我们没有操作 1 和 2 两个节点,所以其父节点还应指向自己,即 f[i] = i
这样就能判断出有几棵树,即有几个家庭啦~
根据刚刚的思路,我们可以把并查集抽象成一个数组,大家先来自己写下,马上附程序!
#include <fstream>
#include <limits>
#include <iomanip>
#include <ios>
#include <stack>
#include <algorithm>
#include <cctype>
#include <string>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <queue>
#include <time.h>
#include <map>
#include <vector>
#include <set>
using namespace std;
#define N 1010
int f[N];//维护一个并查集
int n , m;
void reset()//初始化
{
for(int i = 1 ; i <= n ; i++)
{
f[i] = i;//让其父节点指向自身
}
}
int Find(int x)//查询函数,大写F怕和系统冲突
{
return (f[x] == x ? x : Find(f[x]));//三目运算符简化
}
void updata(int x , int y)//更新函数,合并两个并查集
{
int a = Find(x);
int b = Find(y);
f[a] = b;
Find(a);//调整该集所在的所有子节点
}
int check_tree()//统计树的个数
{
int cnt = 0;
for(int i = 1 ; i <= n ; i++)
{
if(f[i] == i)//其父节点等于其本身
{
cnt++;
}
}
return cnt;
}
int main()
{
scanf("%d %d" , &n , &m);
reset();
int x , y;
for(int i = 1 ; i <= m ; i++)
{
scanf("%d %d" , &x , &y);
updata(x , y);//每次都要更新
}
int ans = check_tree();
printf("%d" , ans);
return 0;
}
那么大家一起考虑这样的一个问题:如果有一个测试点的数据极大,那么会有一个什么问题呢?
对啦~这时,访问路径不难看出是一个递归的过程,那么就会导致时间复杂度很容易超,对于一个没有AC就浑身不爽的选手是十分难受的
那么有没有方法可以解决这个问题呢?
路径压缩
在这里,要隆重介绍一种方法——路径压缩。类似于记忆化搜索,每次将其父节点找到后就直接存储起来不就行了!
如下图
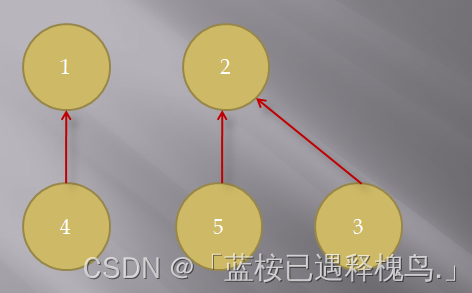
与前一图可以对照下,可以发现这次 3 号的父节点并没有指向 5 号,而是直接更新指向 5 号的父节点—— 2 号节点
这时,我们可以在Find函数中改成这样的一句话:
int Find(int x)
{
return (f[x] == x ? x : f[x] = Find(f[x]);//路径压缩,直接找到其父节点即可,这里还是用使用三目简化
}
这时,我们在搜索的同时也找到了他的父节点,一举两得,怎么样
标程如下:
#include <fstream>
#include <limits>
#include <iomanip>
#include <ios>
#include <stack>
#include <algorithm>
#include <cctype>
#include <string>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <queue>
#include <time.h>
#include <map>
#include <vector>
#include <set>
using namespace std;
#define N 1010
int f[N];//维护一个并查集
int n , m;
void reset()//初始化
{
for(int i = 1 ; i <= n ; i++)
{
f[i] = i;//让其父节点指向自身
}
}
int Find(int x)
{
return (f[x] == x ? x : f[x] = Find(f[x]);//路径压缩,直接找到其父节点即可,这里还是用使用三目简化
}
void updata(int x , int y)//更新函数,合并两个并查集
{
int a = Find(x);
int b = Find(y);
f[a] = b;
Find(a);//调整该集所在的所有子节点
}
int check_tree()//统计树的个数
{
int cnt = 0;
for(int i = 1 ; i <= n ; i++)
{
if(f[i] == i)//其父节点等于其本身
{
cnt++;
}
}
return cnt;
}
int main()
{
scanf("%d %d" , &n , &m);
reset();
int x , y;
for(int i = 1 ; i <= m ; i++)
{
scanf("%d %d" , &x , &y);
updata(x , y);//每次都要更新
}
int ans = check_tree();
printf("%d" , ans);
return 0;
}
你学会了么?
三、初试身手
这次给大家准备了两道练习,考虑到不耽误大家宝贵的时间,第二道题先不在这里展示了,需要可以直接看链接 1402: 亲戚
1401: 家谱
时间限制: 1 Sec 内存限制: 128 MB 文件名 family.*
题目描述
现代的人对于本家族血统越来越感兴趣,现在给出充足的父子关系,请你编写程序找到某个人的最早的祖先。
输入
由多行组成,首先是一系列有关父子关系的描述,其中每一组父子关系由二行组成,用#name的形式描写一组父子关系中的父亲的名字,用+name的形式描写一组父子关系中的儿子的名字;接下来用?name的形式表示要求该人的最早的祖先;最后用单独的一个$表示文件结束。规定每个人的名字都有且只有6个字符,而且首字母大写,且没有任意两个人的名字相同。最多可能有1000组父子关系,总人数最多可能达到50000人,家谱中的记载不超过30代。
输出
按照输入的要求顺序,求出每一个要找祖先的人的祖先,格式:本人的名字+一个空格+祖先的名字+回车。
样例输入
#George
+Rodney
#Arthur
+Gareth
+Walter
#Gareth
+Edward
?Edward
?Walter
?Rodney
?Arthur
$
样例输出
Edward Arthur
Walter Arthur
Rodney George
Arthur Arthur
提示
无
乍一看此题,这是一道明显的并查集,十分简单,比较难的在其对字符串上的操作
直接上标程!
#include <fstream>
#include <limits>
#include <iomanip>
#include <ios>
#include <stack>
#include <algorithm>
#include <cctype>
#include <string>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <queue>
#include <time.h>
#include <map>
#include <vector>
#include <set>
using namespace std;
map <string , string> f;
string a , b;
string Find(string x)
{
return (f[x] == x ? x : f[x] = Find(f[x]));
}
int main()
{
while(true)
{
switch(getchar())
{
case '#':
cin>>a;
if(f[a] == "")
{
f[a] = a;
}
else
{
a = Find(a);
}
break;
case '+':
scanf("%d" , &b);
f[b] = a;
break;
case '?':
scanf("%d" , &b);
cout<<b<<" "<<Find(b)<<'\n';
break;
case '$':
return 0;
break;
}
}
}
四、迎风破浪
1398: 最幸福的国家
时间限制: 1 Sec 内存限制: 128 MB 文件名 country.*
题目描述
某国住着n个人,任何两个认识的人不是朋友就是敌人,被誉为地球最北的幸福国家,各成员之间满足:
1、我朋友的朋友是我的朋友;
2、我敌人的敌人是我的朋友;
所有是朋友的人组成一个社群。告诉你关于这n个人的m条信息,即某两个人是朋友,或者某两个人是敌人,请你编写一个程序,计算出这个城市最多可能有多少个社群?
输入
第1行为n和m,1<n<1000,1≤m≤100 000;
以下m行,每行为p x y,p的值为0或1,p为0时,表示x和y是朋友,p为1时,表示x和y是敌人。
输出
一个整数,表示这n个人最多可能有几个社群。
样例输入
6 4
1 1 4
0 3 5
0 4 6
1 1 2
样例输出
3
提示
无
大家可以稍加练习,下章会来讲解这道练习
总结
这章,我们了解了并查集,需多加练习,因为下章图的部分将运用并查集进行操作
下章预告:数据结构系列(三) :初识图论
还有,在这里想注明下,这个系列我主要会带着大家一起来梳理图的一些重要的知识点,至于树性结构,以后可能会出专辑,感谢~















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









