







Transforms的使用(一)
Transforms是什么?
Transforms主要是对图片进行一些变换,一般用于数据预处理,数据在读取到pytorch之后通常都需要对数据进行预处理,包括尺寸缩放、转换张量、数据中心化或标准化等等,这些操作都是通过transforms进行的。
1.transforms的结构及用法
结构
创建一个transforms.py的python文件,然后导入库(从torchvision中引用transforms函数)。
from torchvision import transforms
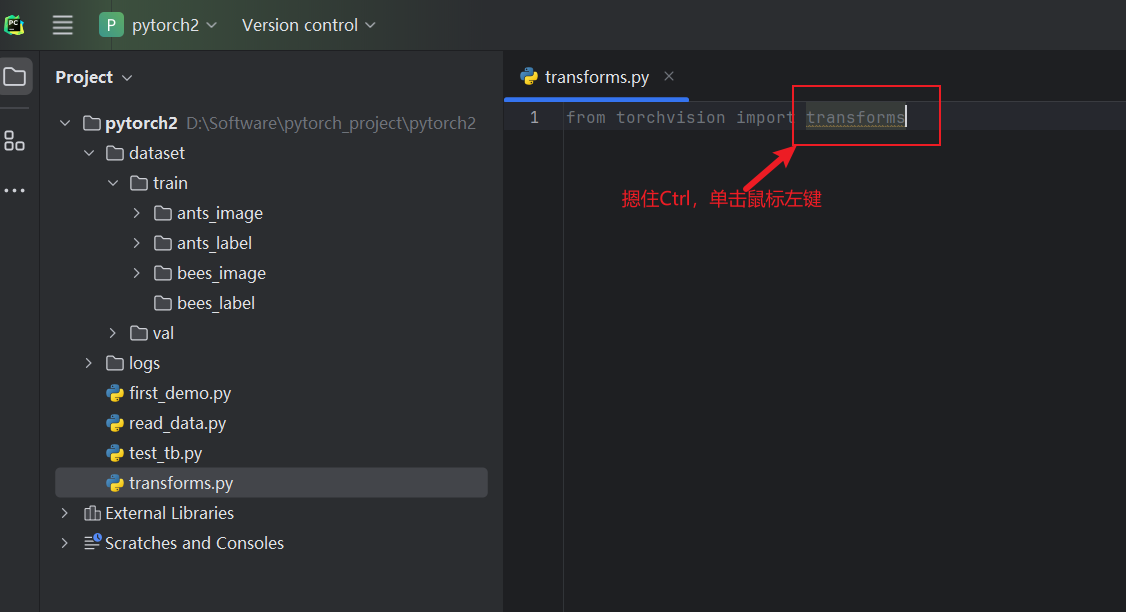

通过上图两次按住Ctrl,查看 transforms.py文件(工具箱),可以看到它定义了很多 class文件(工具)
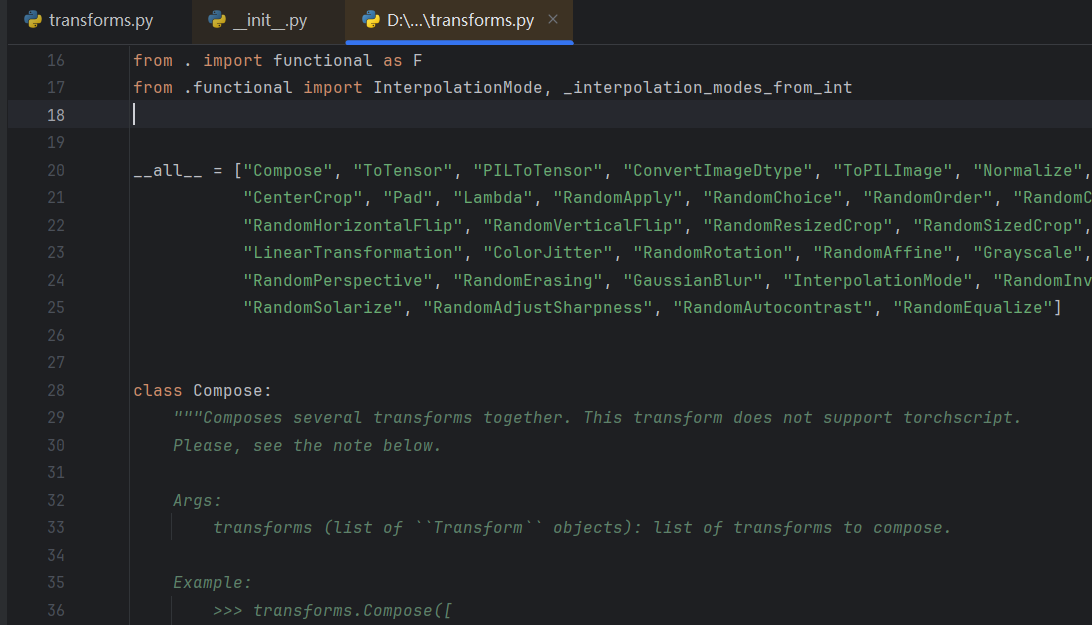
一些类(工具)
Compose类:结合不同的transforms
ToTensor类:把一个PIL的Image或者numpy数据类型的图片转换成 tensor 的数据类型
ToPILImage类:把一个图片转换成PIL Image
Normalize类:归一化,标准化,用来对数据预处理
Resize类:尺寸变换,即输入一张图片,将图片转变为指定的大小。如果只传入一个参数,就将最小边变成size,最大边等比例变成原来最小边的倍数
CenterCrop类:中心裁剪
Regularize类:正则化,防止模型过拟合的技术
使用
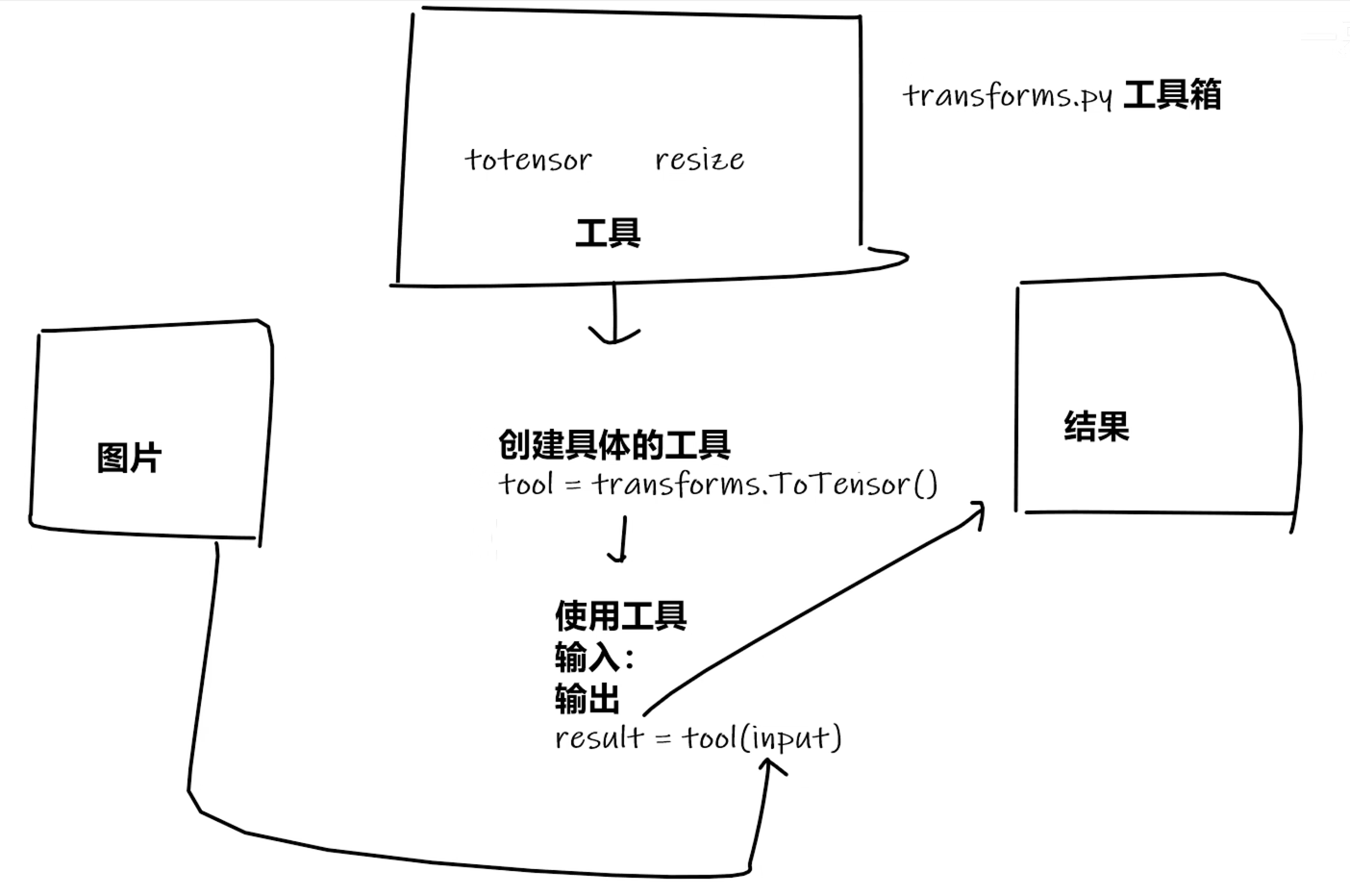
- transforms.py 工具箱
- 工具箱里放着 totensor / resize等类 工具
拿一些特定格式的图片,经过工具(class文件)后,就会输出我们想要的图片变换的结果。
2.tensor数据类型
通过transforms.Totensor去解决两个问题:
(1)transforms该如何使用;
(2)我们为什么需要tensors数据类型。
2.1 transforms该如何使用
从transforms中选择一个class,首先对它创建,根据创建的工具知道需要什么东西,返回出结果。
可以理解为,transforms.py是一个工具箱,里面有很多工具,像ToTensor/Resize等,可以将这些工具看成模板,利用这些模板来创建我们需要的工具,根据这些工具的使用方法,输入数据,输出结果。
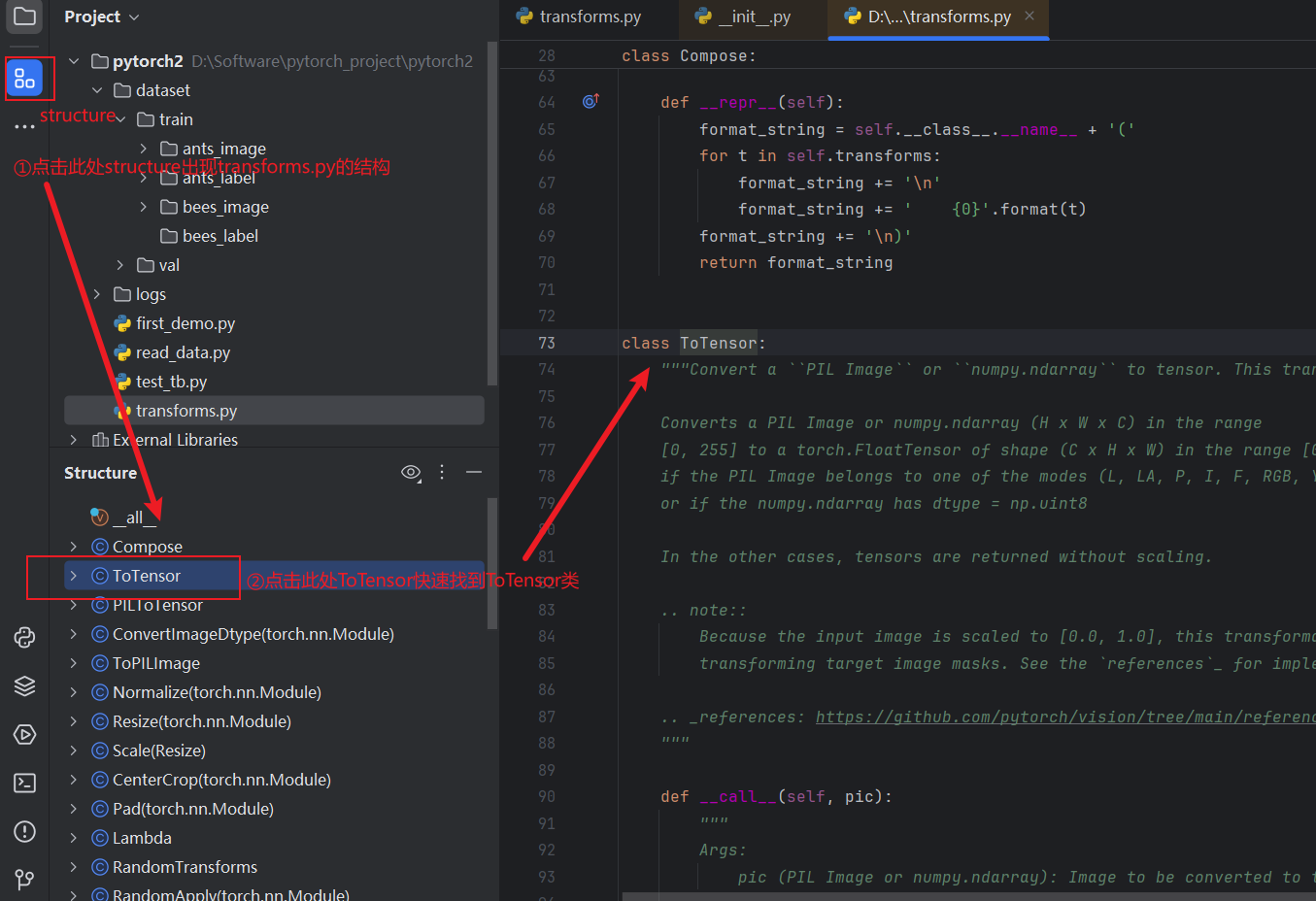
例如,ToTensor可以将一个 PIL Image 或 numpy.ndarray 转换为 tensor的数据类型
代码实战
Ctrl+P可以提示函数里需要填什么参数
(PIL Image数据处理):
from PIL import Image
from torchvision import transforms
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path) #Image是python中的一个图片的库,使用open()读取图片,得到的img数据类型是Image对象
tensor_trans = transforms.ToTensor() # 引用transforms中的totensor,返回的是totensor的对象。可以理解为用tensor_trans接收totensor的对象。
tensor_img = tensor_trans(img) # 将img图片转换成tensor格式。(鼠标放括号里,ctrl+p可以查看需要什么括号里需要什么参数。)
print(tensor_img) # 查看tensor_img的数据类型
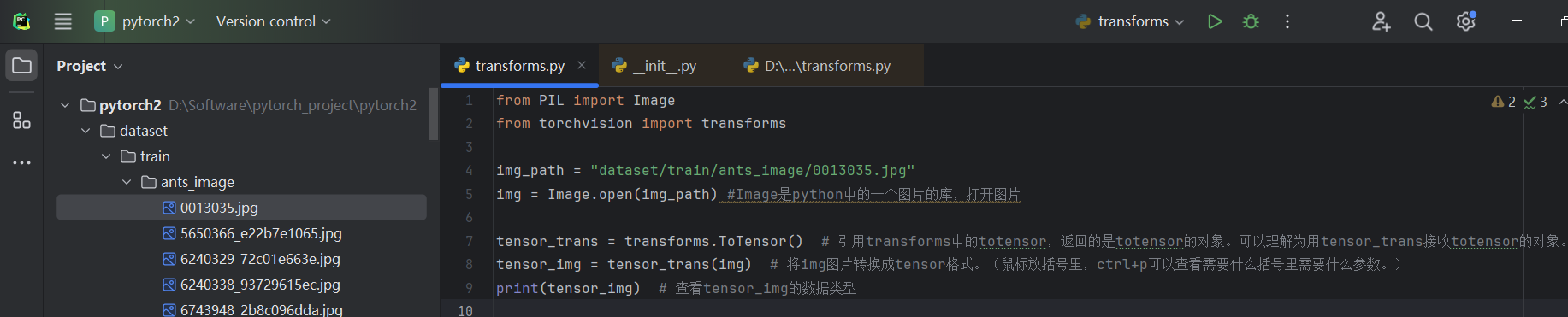
运行结果:
2.2 Tensor数据类型与其他图片数据类型有什么区别?为什么需要tensors数据类型。
因为在神经网络当中,肯定要将数据转化为tensor的类型,才能继续处理,进行训练。
Tensor 数据类型包装了反向神经网络所需要的一些理论基础的参数**,如:_backward_hooks、_grad等**(先转换成Tensor数据类型,再训练)
在Python Console输入下列代码,回车运行:
from PIL import Image
from torchvision import transforms
img_path= "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
右侧属性栏:
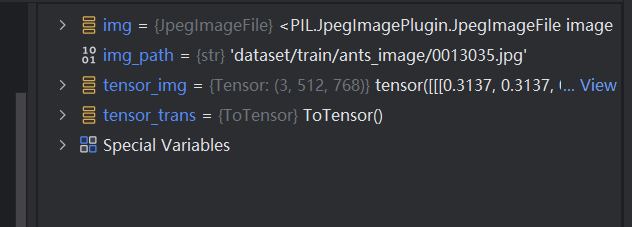
打开img,可以看到用Python内置函数读取的图片具有的参数:
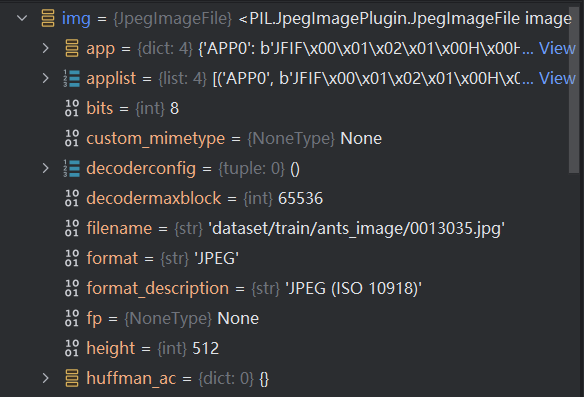
再打开tensor_img,看一下它具有的参数:
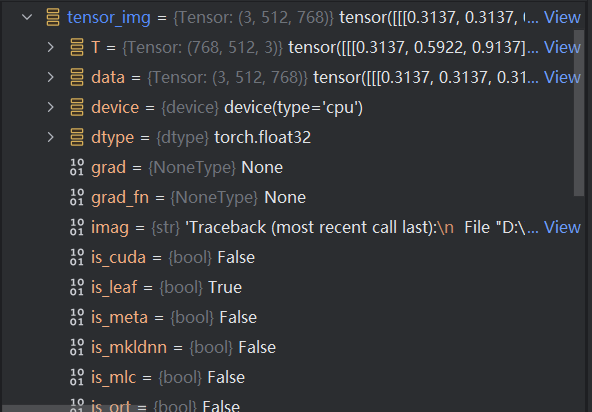
3.两种读取图片的方式
1.PIL Image
from PIL import Image
img_path = "dataset/train/ants_image/0013035.jpg" #要打开的图片路径
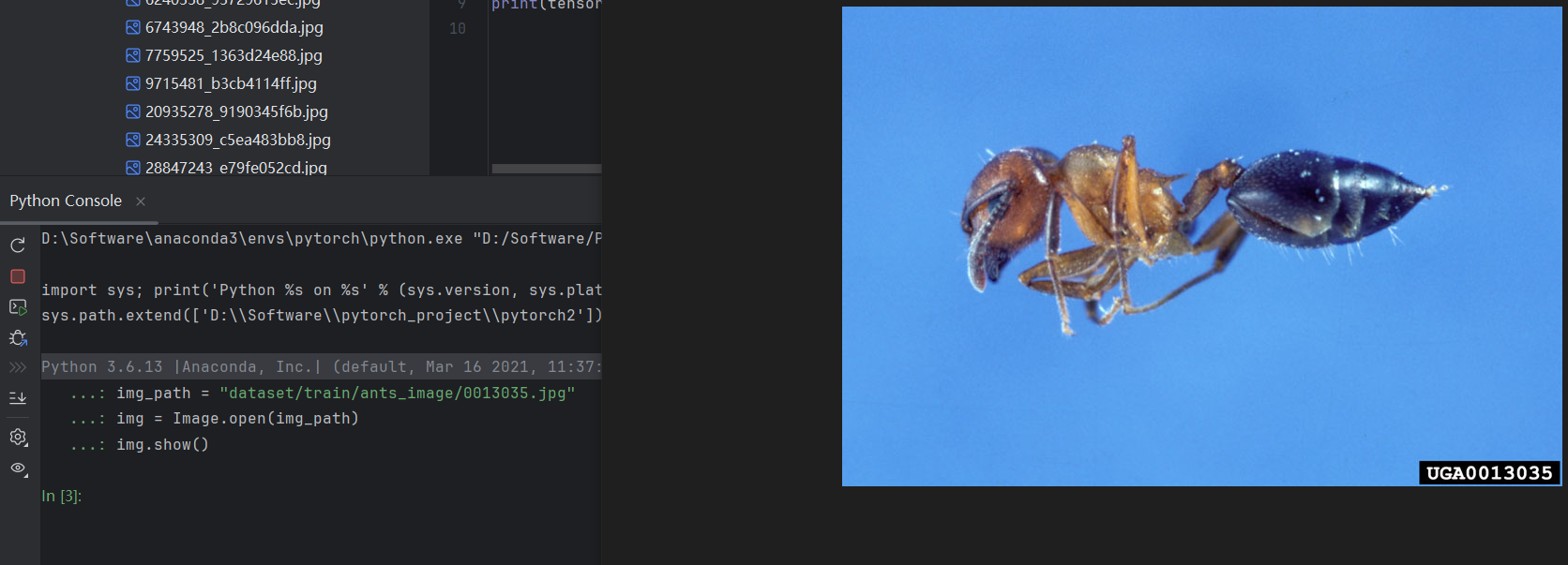
img = Image.open(img_path)
img.show()
在控制台调试结果如下:
2. numpy.ndarray(通过opencv)
import cv2
cv_img=cv2.imread(img_path) #括号里的参数是图片路径
控制台调试发现没安装OpenCV,去anaconda prompt面板安装一下:
conda activate pytorch
pip install opencv-python==4.3.0.38

验证是否安装成功:
python
import cv2

重新在控制台调试读取图片,属性栏出现cv_img,说明读取成功了

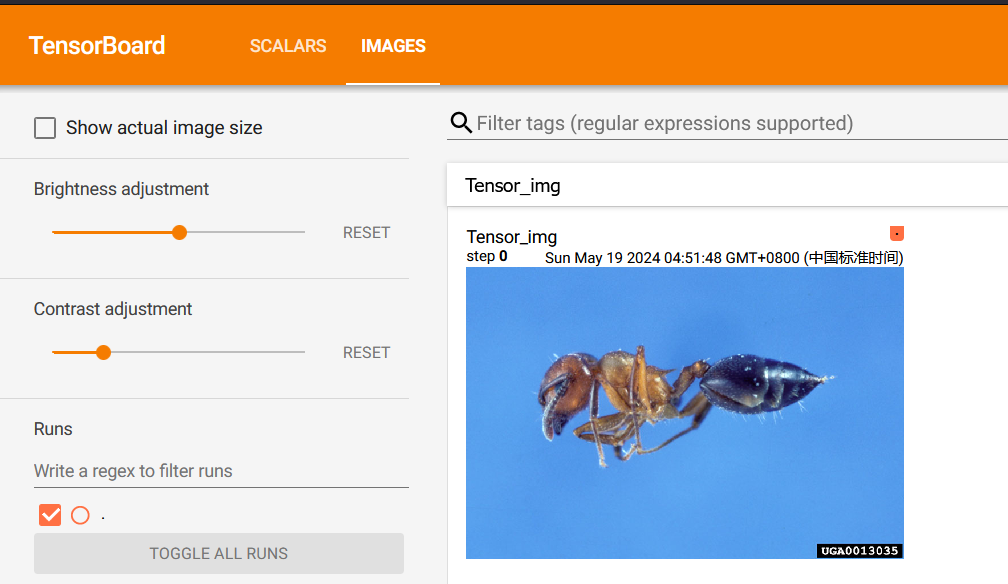
上节课以 numpy.array 类型为例,这节课使用 torch.Tensor 类型,结合TensorBoard,观察训练结果:
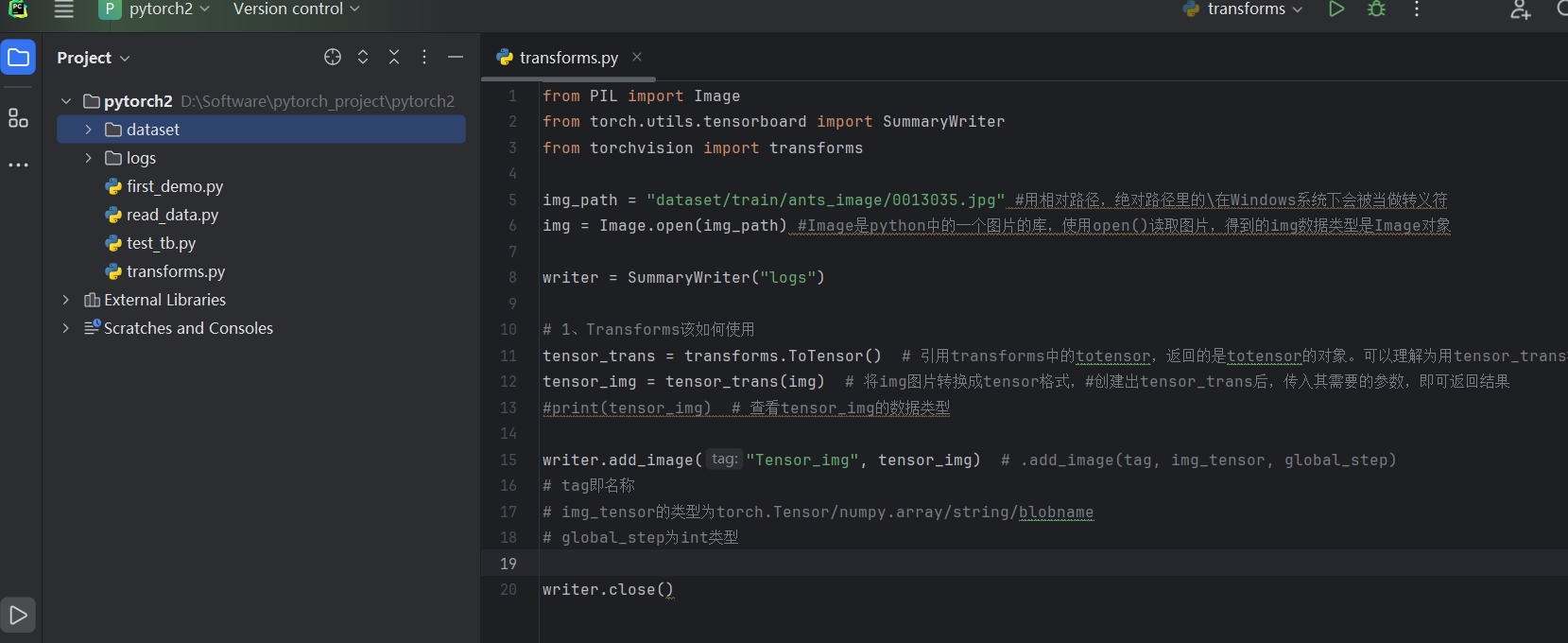
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "dataset/train/ants_image/0013035.jpg" #用相对路径,绝对路径里的\在Windows系统下会被当做转义符
img = Image.open(img_path) #Image是python中的一个图片的库,使用open()读取图片,得到的img数据类型是Image对象
writer = SummaryWriter("logs")
# 1、Transforms该如何使用
tensor_trans = transforms.ToTensor() # 引用transforms中的totensor,返回的是totensor的对象。可以理解为用tensor_trans接收totensor的对象。
tensor_img = tensor_trans(img) # 将img图片转换成tensor格式,#创建出tensor_trans后,传入其需要的参数,即可返回结果
#print(tensor_img) # 查看tensor_img的数据类型
writer.add_image("Tensor_img", tensor_img) # .add_image(tag, img_tensor, global_step)
# tag即名称
# img_tensor的类型为torch.Tensor/numpy.array/string/blobname
# global_step为int类型
writer.close()
运行后,在 Terminal 里输入:
tensorboard --logdir=logs

打开链接,查看TensorBoard:















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









