







5.pytorch加载数据初认识
如何加载数据
对于神经网络训练,要从数据海洋里找到有用的数据
1.读取数据涉及两个类:Dataset和Dataloader
**Dataset:**提供一种方式,获取其中需要的数据及其对应的真实的 label 值,并完成编号。主要实现以下两个功能:
1.如何获取每一个数据及其label
2.告诉我们总共有多少的数据
**Dataloader:**打包(batch_size),为后面的神经网络提供不同的数据形式
dataset与dataloader的区别:
dataset是告诉程序数据集在什么位置,dataloader是将数据加载到神经网络中
dataloader的作用:从dataset中取数据,每次取多少或取哪一个是由dataloader的参数决定
2.数据集的几种组织形式
下载up我是土堆提供的数据集hymenoptera_data,这个数据集下载稍微简单且更接近真实的构建的数据集
数据集 hymenoptera_data(蚂蚁和蜜蜂的数据集,二分类)
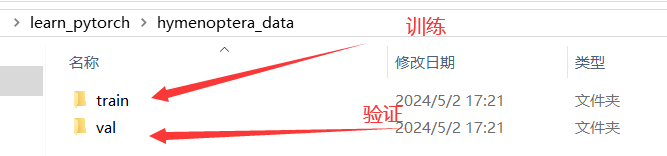
-
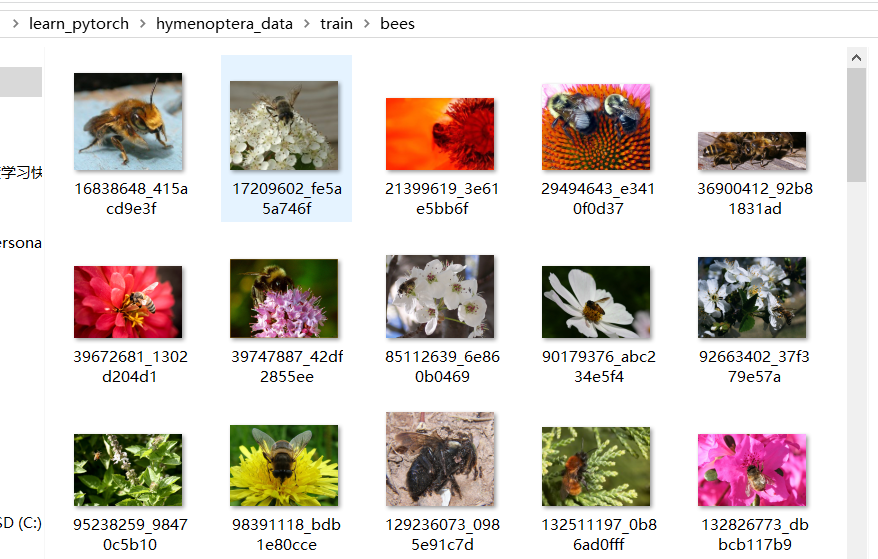
train 里有两个文件夹:ants 和 bees,其中分别都是一些蚂蚁和蜜蜂的图片。

-
train_images是一个文件夹,train_labels是另一个文件夹,如OCR数据集。
-
label直接为图片的名称。
3 Dataset类
from torch.utils.data import Dataset
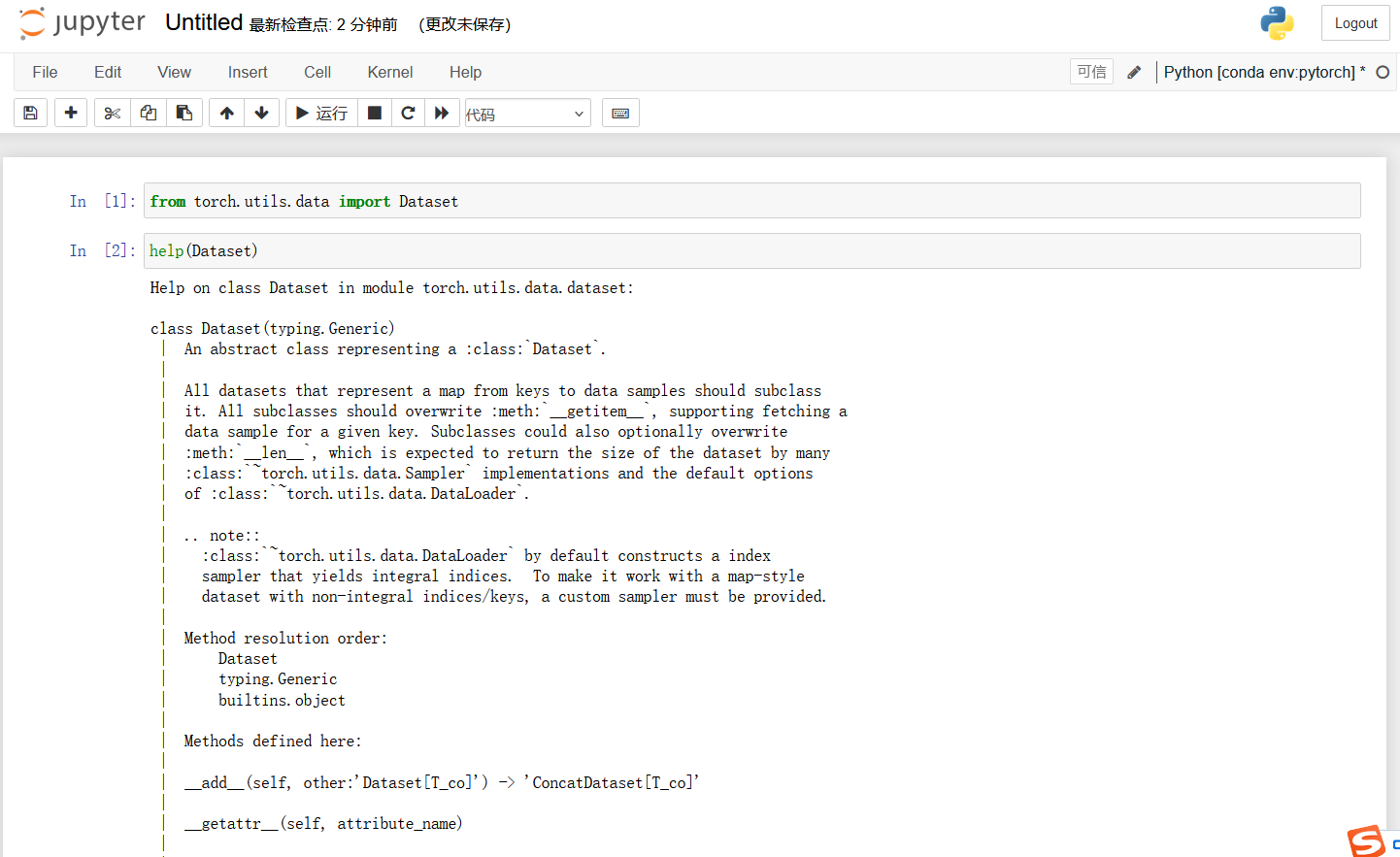
Jupyter段落整理的比较清晰,到Jupyter里面运行代码,查看官方文档里Dataset类的介绍,它是如何使用的:
help(Dataset)
还可以使用代码:
Dataset??
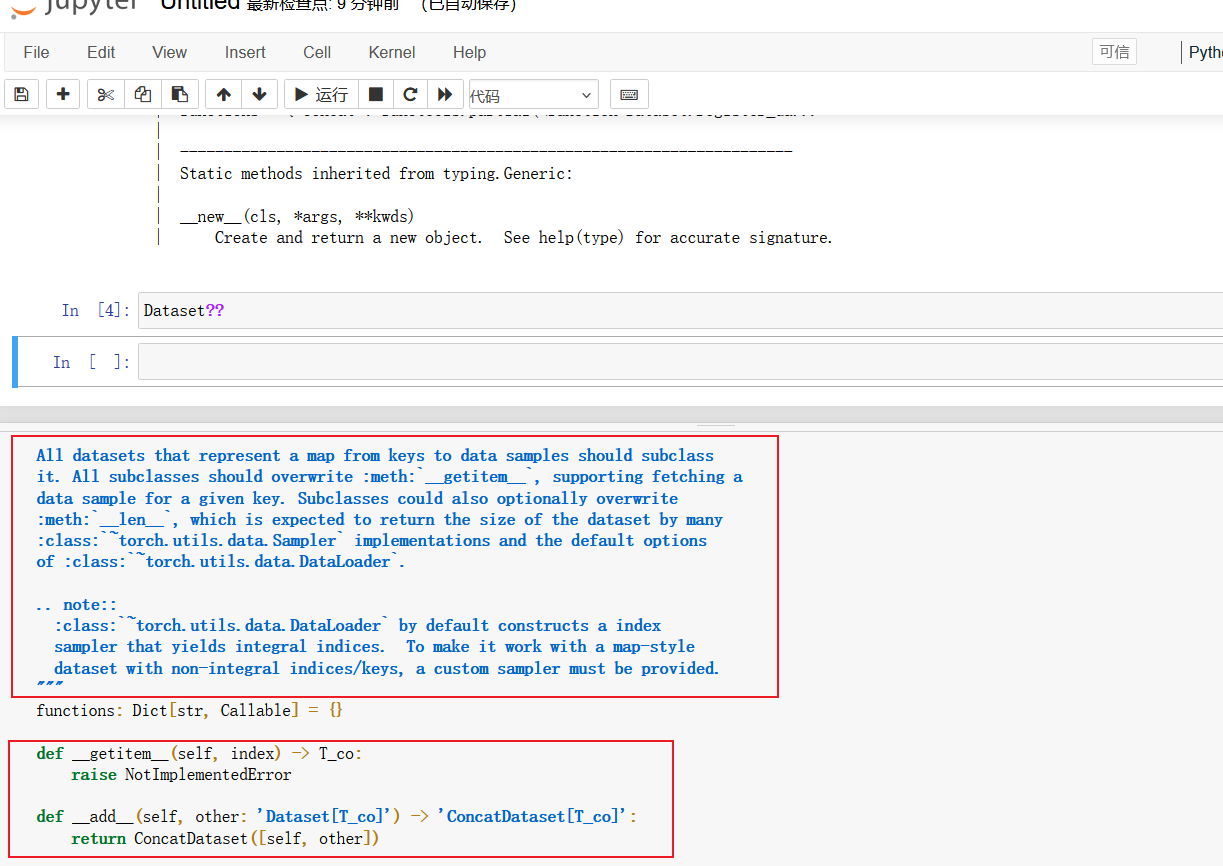
Dataset 是一个抽象类,所有数据集都需要继承这个类,所有子类都需要重写 getitem 的方法,这个方法主要是获取每个数据集及其对应 label,还可以重写长度类__len__。
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









