






专注于文本分类、关键词抽取、文本摘要、FAQ问答系统、对话系统语义理解NLU、知识图谱等。结合工业界具体案例和学术界最新研究成果实现NLP技术场景落地。更多精彩内容加入“NLP技术交流群” 学习。
当我们理解attention 和self-attention 后就可以学习transformer模型,BERT 了。可以看出在当前NLP领域attention 机制的重要性。
作者:走在前方
本文分享主要内容
- 什么是self-attention
- self-attention 的概念
- attention 和 self-attention 区别
- self-attention 解决问题
- 图解self-attention
- 动态图方式介绍self-attention 计算过程
- 图解self-attention 代码实现
- 模拟代码完成图解self-attention全部流程
什么是Self-Attention
BERT, RoBERTa, ALBERT, SpanBERT, DistilBERT, SesameBERT, SemBERT, SciBERT, BioBERT, MobileBERT, TinyBERT 和CamemBERT 有什么相同点?“BERT” 不是我需要的答案。
答案: Self-Attention
首先我们讨论下BERT的架构,更重要的是讨论下基于Transformer模型架构,尤其在语言模型中非常重要。最后,我们通过代码的方式,从0到1来看看self-attention 是如何计算的。
什么是self-attention?
Self Attention也经常被称为intra Attention(内部Attention),最近一年也获得了比较广泛的使用,比如Google最新的机器翻译模型内部大量采用了Self Attention模型。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子。
而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。
- Attention
Target不等于Source情形下的注意力计算,比如对于机器翻译来说,本质上是目标语单词和源语单词之间的一种单词对齐机制。
- Self-Attention
Self Attention可以捕获同一个句子中单词之间的一些句法特征.引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征
如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
图解Self-Attention
输入数据离散化表示Prepare inputs
Fig. 1.1: Prepare inputs
对于本文学习来讲,提供三个input,每个input的维度都设置4
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
初始化权重矩阵Initialise weights
Fig. 1.2: Deriving key, query and value representations from each input
每个input进行embedding后转为相同大小的向量来表示,分别为 **key **(orange), **query **(red), and **value **(purple)。
key,query,value 向量维度3,输入向量维度4,这里我们可以转弯4×3 矩阵来表示。
Note
We’ll see later that the dimension of value is also the dimension of the output.
如何得到我们的query、key、value的向量表示呢?
我们初始化三个矩阵,分别对应W(query)、W(key)、W(value) ,这三个矩阵是模型训练过程中得到的参数。
Weights for query:=W^Q
[[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]]
Weights for key:= W^K
[[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]]
Weights for value: = W^V
[[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]]
计算过程如下: 我们以 X= input#1 为例进行演示K、Q、V的计算
query = X * W^Q
key = X * W^K
value = X * W^V
我们把query 给出了详细的计算过程,对应的key、value 计算也是同样的操作。就是两个矩阵相乘。
在神经网络中,这三个权重通常是一个非常小的数值,我们在模型训练之前,可以通过一些方法进行初始化权重(例如:Gaussian, Xavier and Kaiming distributions)
KQV 向量计算Derive key, query and value
这里针对每个input详细介绍key、query、value计算过程(针对每个input#1~input#3 都会使用query,key,value 三种向量进行表示 )
query = X * W^Q
key = X * W^K
value = X * W^V
说明:
- X 表示input#1、input#2、input#3 。。。。。
- W^Q 、W^K、 W^V 分别对应query,key,value 初始化的权重W。
Key representation for Input 1:
[0, 0, 1]
[1, 0, 1, 0] x [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
Key representation for Input 2:
[0, 0, 1]
[1, 0, 1, 0] x [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
Key representation for Input 3:
[0, 0, 1]
[1, 1, 1, 1] x [1, 1, 0] = [2, 3, 1]
[0, 1, 0]
[1, 1, 0]
上述计算过程input#1~input#3 单独计算,考虑合并计算,提高性能。
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
下面通过动态效果图来展示key如何进行向量表示的(对应的query,value 计算过程类似。)
Fig. 1.3a: Derive key representations from each input
汇总input#1~input#3 对应的key,query,value 的计算结果如下
- key 向量表示
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
- query 向量表示
[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
- value 向量表示
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
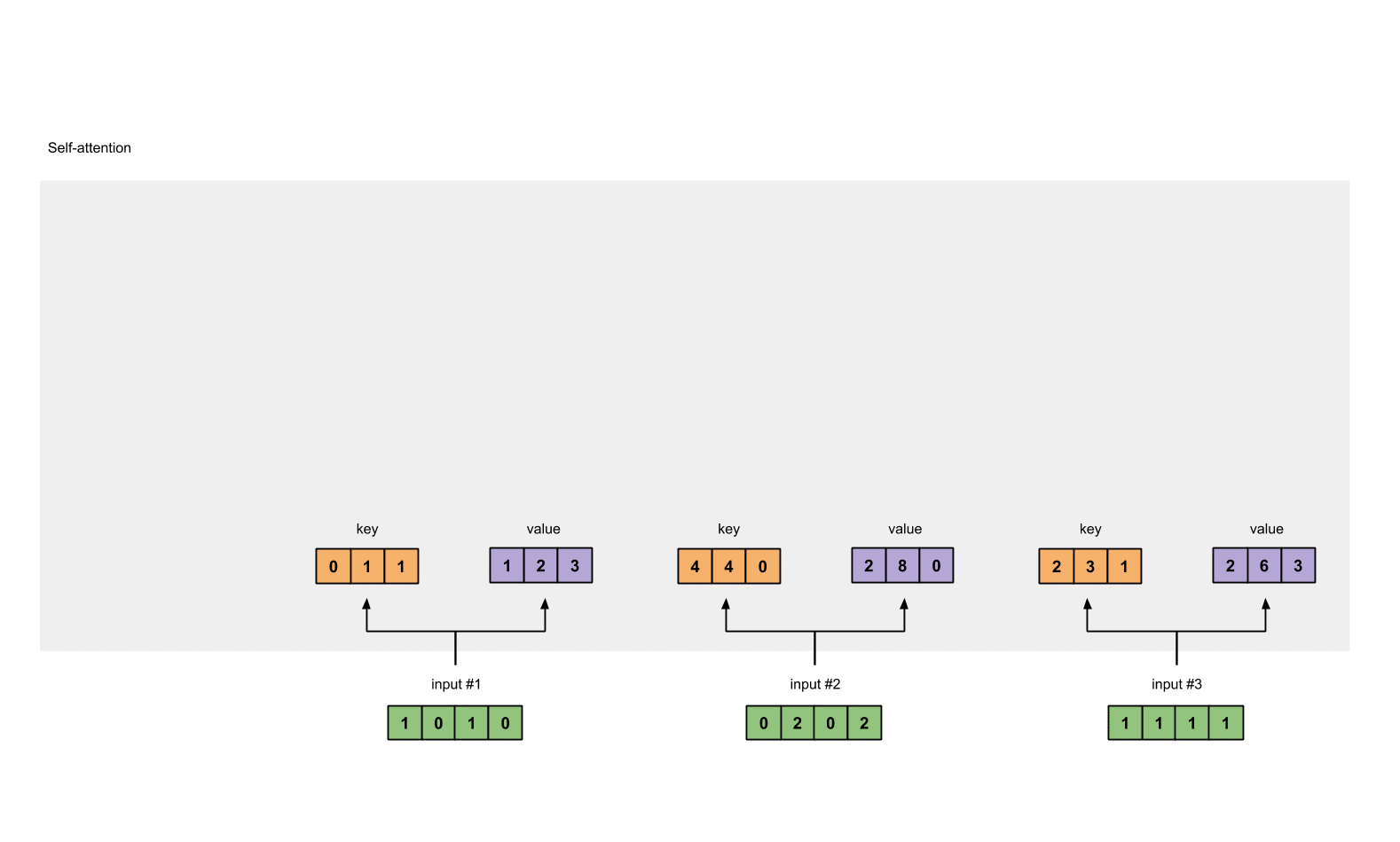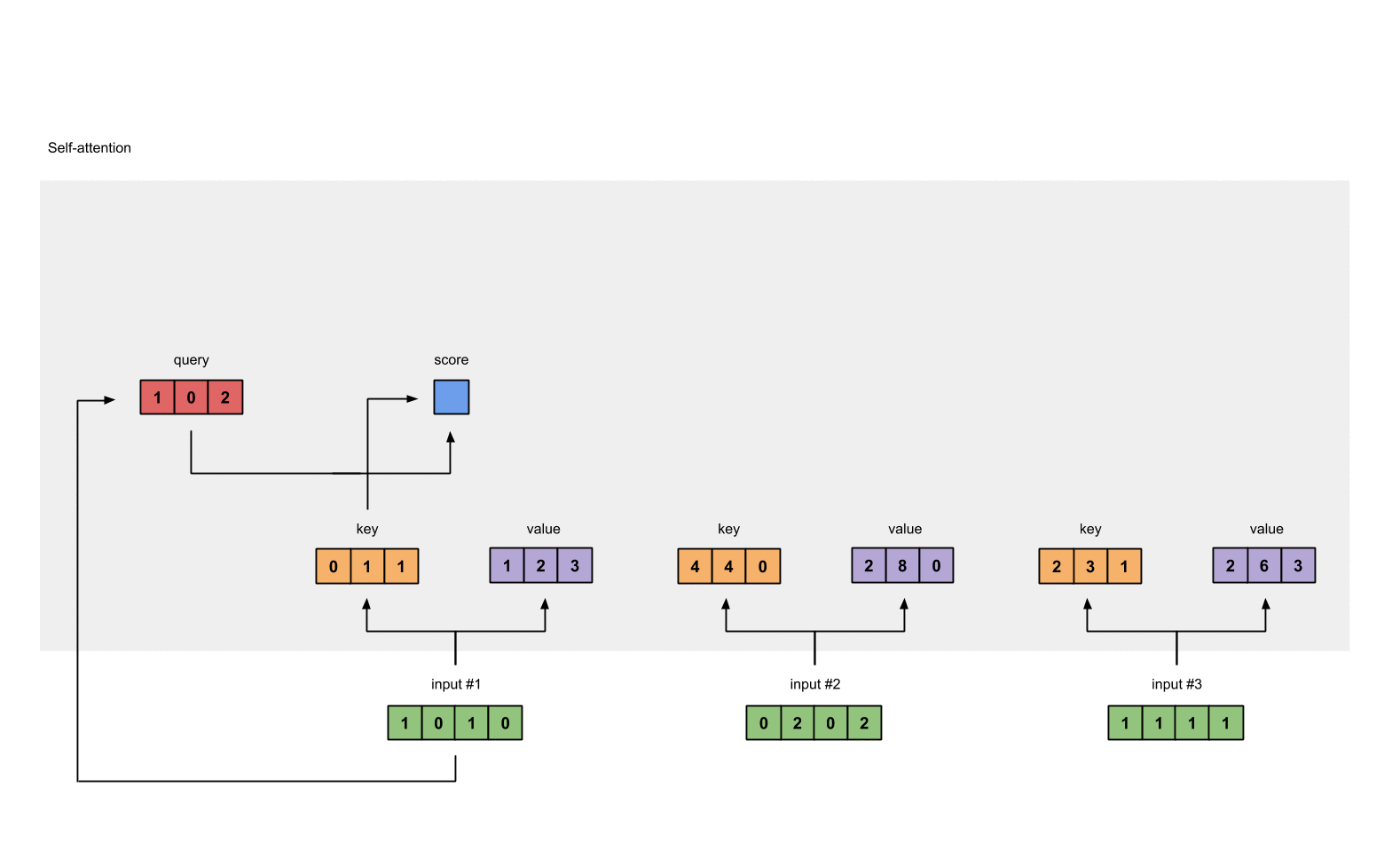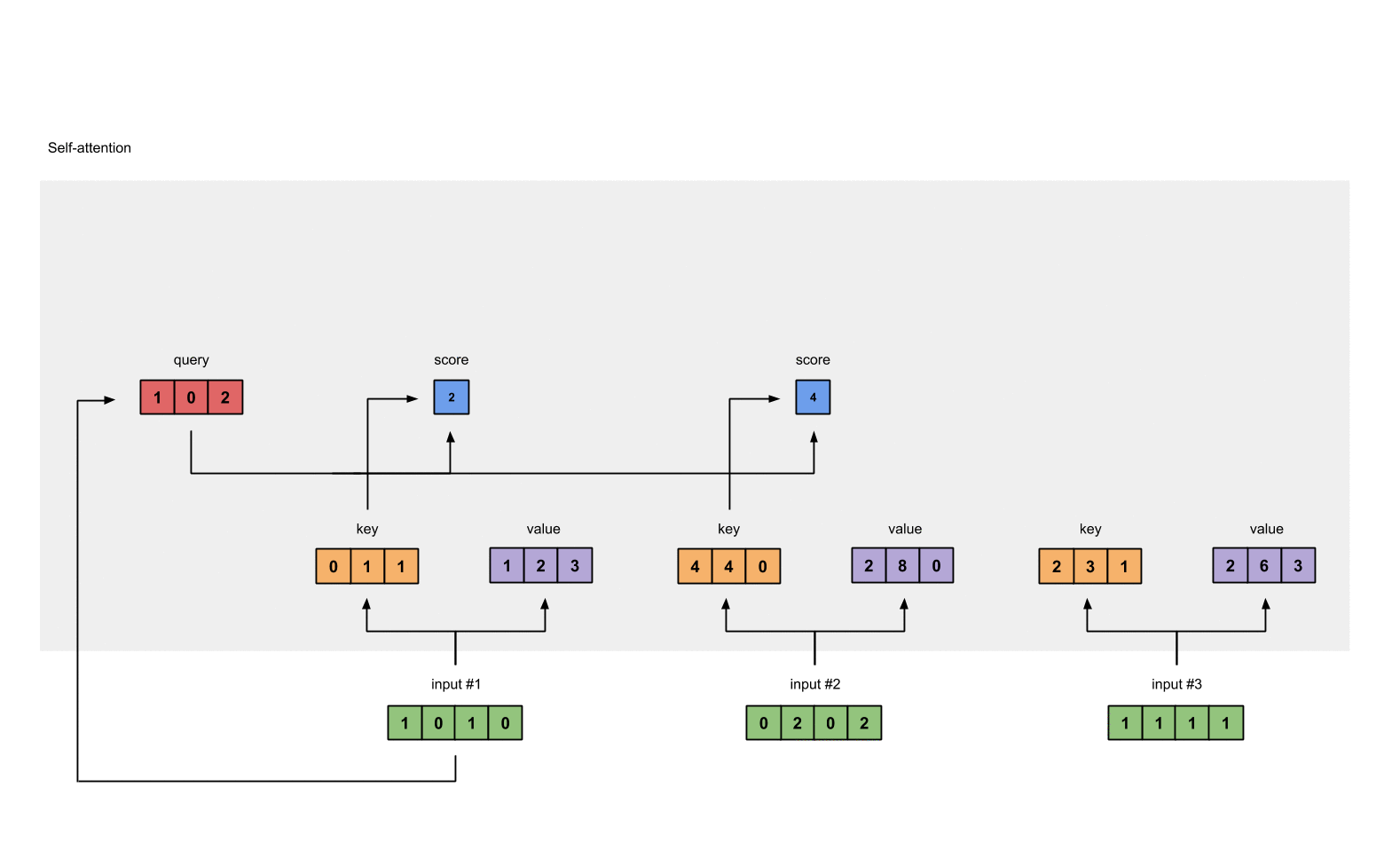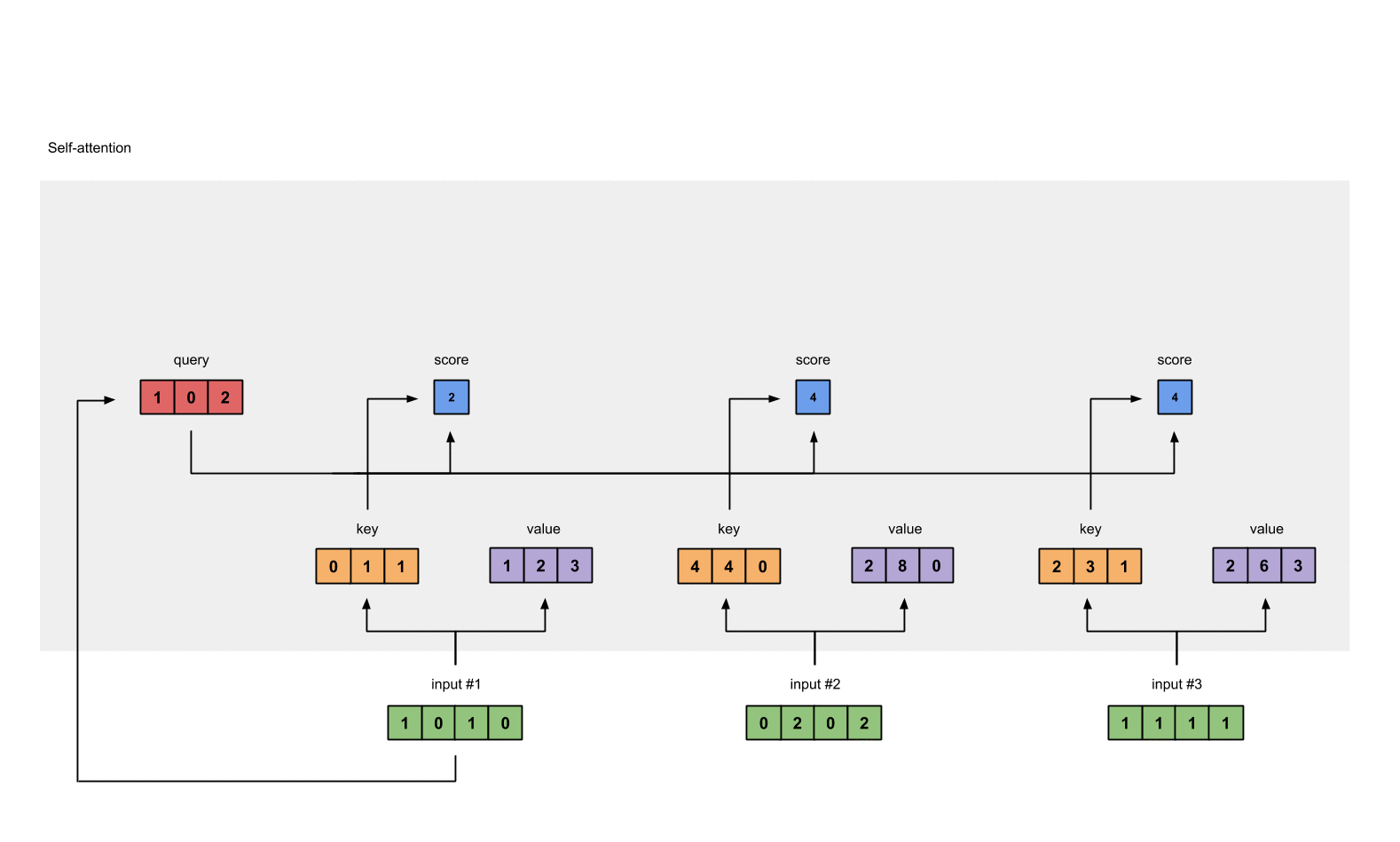
计算attention得分Calculate attention scores for Input 1
我们来看下input#1 如何计算对应的attention score。
为获取 attention scores, 我们这里采用 dot product 方式。 例如:input#1 的 **query **(red) 以此和所有的 **keys **(orange)包括自己进行dot product 计算。我们最终获取 3 个attention scores (blue)。
attention_socre1( input#1 ) = query(input#1) * key1 = [1,0,2] * [0,1,1]^T = 2
attention_socre1( input#1 ) = query(input#1) * key2 = [1,0,2] * [4,4,0]^T = 4
attention_socre1( input#1 ) = query(input#1) * key3 = [1,0,2] * [2,3,1]^T = 4
下面通过两个矩阵直接相乘如下:QK^T (Q,K 分别代表两个矩阵,K表示所有Key;Q表示当前query即需要计算的query)
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
Fig. 1.4: Calculating attention scores (blue) from query 1
上述我们仅仅采用一种dot product 方式来计算attention score.实际上有很多的计算方法。
The above operation is known as dot product attention, one of the several score functions. Other score functions include scaled dot product and additive/concat.
通过softmax函数归一化得分Calculate softmax
Fig. 1.5: Softmax the attention scores (blue)
我们发现计算出来的attention score 计算出来后是一个数值,而我们希望是一个概率数值。可以通过softmax 函数来解决。标准的 softmax函数公式
import numpy as np
def softmax(z):
return np.exp(z) * 1.0 / np.sum(np.exp(z));
if __name__ == '__main__':
z = [2, 4, 4]
print(softmax(z))
# [0.06337894 0.46831053 0.46831053]
图中给的结果和我们不一致,主要原因:为方便用户理解,人工在画图的时候有意去修正了下,并没有实际的意义。大家了解softmax 是如何计算的就可以了。
6. Multiply scores with values
Fig. 1.6: Derive weighted value representation (yellow) from multiply value (purple) and score (blue)
通过 softmax 计算出的 attention scores(blue)与对应的**value **(purple)相乘.。这个结果作为value的权重。
weights_value = softmax(QK^T) * value 。 Q 为input#1 ~ input#3
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
input#1 最终的结果Sum weighted values to get Output 1
| [0.0, 0.0, 0.0] + [1.0, 4.0, 0.0] + [1.0, 3.0, 1.5] ----------------- = [2.0, 7.0, 1.5] |
|---|
input#1 经过self-attention 后得到输出向量output#1 是 [2.0, 7.0, 1.5] (dark green) 。
- 句子经过self-attention 整个过程
我们看下完整个结果如下
Fig. 1.8: Repeat previous steps for Input 2 & Input 3
图解 Self-Attention代码实现
通过PyTorch 完成代码编写,PyTorch 是一个深度学习计算框架。提供了灵活的API。Python≥3.6 和 PyTorch 1.3.1+来完成。代码可在Python/IPython 和 Jupyter Notebook直接运行。
Step 1: Prepare inputs
x = [
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1] # Input 3
]
x = torch.tensor(x, dtype=torch.float32)
x
Step 2: Initialise weights
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
print("Weights for key: \n", w_key)
print("Weights for query: \n", w_query)
print("Weights for value: \n", w_value)
输出的结果如下:
Weights for key:
tensor([[0., 0., 1.],
[1., 1., 0.],
[0., 1., 0.],
[1., 1., 0.]])
Weights for query:
tensor([[1., 0., 1.],
[1., 0., 0.],
[0., 0., 1.],
[0., 1., 1.]])
Weights for value:
tensor([[0., 2., 0.],
[0., 3., 0.],
[1., 0., 3.],
[1., 1., 0.]])
Step 3: Derive key, query and value
# numpy 两个矩阵相乘
import numpy as np
keys = np.matmul(x,w_key)
querys = np.matmul(x,w_query)
values = np.matmul(x,w_value)
print("Keys: \n", keys)
# tensor([[0., 1., 1.],
# [4., 4., 0.],
# [2., 3., 1.]])
print("Querys: \n", querys)
# tensor([[1., 0., 2.],
# [2., 2., 2.],
# [2., 1., 3.]])
print("Values: \n", values)
# tensor([[1., 2., 3.],
# [2., 8., 0.],
# [2., 6., 3.]])
Step 4: Calculate attention scores
print('numpy....')
attn_scores = np.matmul(querys,keys.T)
print(attn_scores)
# tensor([[ 2., 4., 4.], # attention scores from Query 1
# [ 4., 16., 12.], # attention scores from Query 2
# [ 4., 12., 10.]]) # attention scores from Query 3
# print('torch....')
# attn_scores = torch.matmul(querys,keys.T)
# print(attn_scores)
Step 5: Calculate softmax
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1) # 按照列唯独求解attent_scores
print(attn_scores_softmax)
# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],
# [6.0337e-06, 9.8201e-01, 1.7986e-02],
# [2.9539e-04, 8.8054e-01, 1.1917e-01]])
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
print(attn_scores_softmax)
Step 6:Multiply scores with values
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
print(weighted_values.shape)
print(weighted_values)
输入的结果:
torch.Size([3, 3, 3])
tensor([[[0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000]],
[[1.0000, 4.0000, 0.0000],
[2.0000, 8.0000, 0.0000],
[1.8000, 7.2000, 0.0000]],
[[1.0000, 3.0000, 1.5000],
[0.0000, 0.0000, 0.0000],
[0.2000, 0.6000, 0.3000]]])
Step 7: Sum weighted values
outputs = weighted_values.sum(dim=0)
print(outputs)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1
# [2.0000, 8.0000, 0.0000], # Output 2
# [2.0000, 7.8000, 0.3000]]) # Output 3
















 5870
5870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}