







集合简述(一)
前言
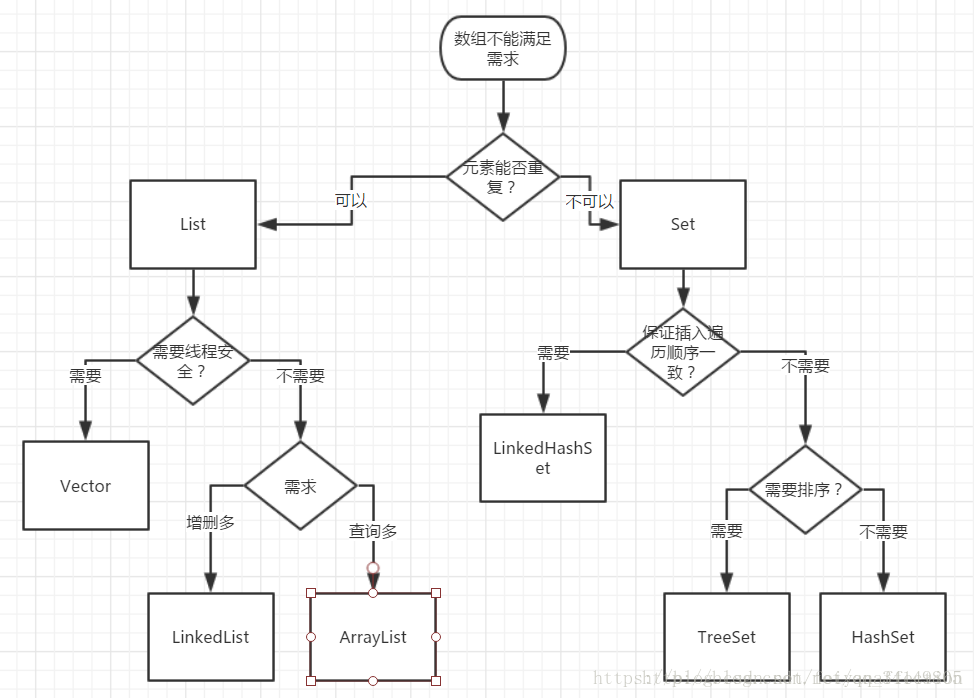
Java是一种面向对象语言,如果我们要针对多个对象进行操作,就必须对多个对象进行存储。而数组长度固定,不能满足变化的要求。所以,java提供了集合。
一 容器的继承体系
Collection接口 容器的根层次接口,它表示所有容器类的标准,如何来判断 一个类是否是容器,那么要看它是否实现了Collection接口
List 接口 ---列表
Queue 接口 ---队列 先进先出
Set 接口 ----集合
SortedSet ----有序集合

集合
Collection接口中的方法:
迭代器
List系的集合
ArrayList
LinkedList
Vector
Vector与ArrayList的区别
Set系的集合
HashSet
HashSet的实现原理:
TreeSet
Queue队列
Queue的常用实现类
ArrayBlockingQueue
LinkedBlockingQueue
PriorityBlockingQueue
DelayQueue
SynchronousQueue
LinkedTransferQueue
非阻塞队列
ConcurrentLinkedQueue
双端队列
LinkedBlockingDeque
Map系集合
HashMap
TreeMap
Hashtable
WeakHashMap
二、集合是什么?
Java集合是java提供的一个工具包,全部继承自java.util.*。主要包括两大接口Collection接口和Map接口以及相关的工具类(Iterator迭代器接口、Enumeration枚举类、Arrays和Colletions)。
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
集合框架体系:
(一).Queue队列
1.核心接口
push(): 核心接口 将一个元素置入queue中,该元素成为其最后的元素
pop(): 移除queue中的第一元素此函数无返回值,想处理被移除的元素,必须先调用
front(): 调用者保证queue非空front()返回第一个被置入的元素,即返回queue最前端的元素调用者保证queue不空
back(): 返回最后一个被插入的元素调用者保证queue非空
public class Main {
public static void main(String[] args) {
//add()和remove()方法在失败的时候会抛出异常(不推荐)
Queue<String> queue = new LinkedList<String>();
//添加元素
queue.offer("a");
queue.offer("b");
queue.offer("c");
queue.offer("d");
queue.offer("e");
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("poll="+queue.poll()); //返回第一个元素,并在队列中删除
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("element="+queue.element()); //返回第一个元素
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("peek="+queue.peek()); //返回第一个元素
for(String q : queue){
System.out.println(q);
}
}
}2.双端队列:Deque接口及ArrayDeque类
一般的队列只能在头部删除元素、在尾部添加元素,即只有一个端。而双端队列有两个端,支持在两端同时添加或删除元素。Deque接口是Java SE 6引入的,并由ArrayDeque类和LinkedList类实现,这两个类都提供了双端队列,并在必要的时候可以增加队列的长度。其实,还有一种队列,叫做有限队列,当然也包括有限双端队列,这两个队列不在本文的讨论之内。
2.1Deque接口
Deque接口在Queue接口的基础之上增加了一些针对双端添加和删除元素的方法,这些方法根据出错时的行为也可以分为几组。这些方法就是在Queue接口中的方法名后面加上“First”和“Last”表明在哪端操作。方法如下:
(1)添加元素
void addFirst(E e);
void addLast(E e);
boolean offerFirst(E e);
boolean offerLast(E e);2)删除并返回元素
E removeFirst();
E removeLast();
E pollFirst();
E pollLast();(3)返回但不删除元素
E getFirst();
E getLast();
E peekFirst();
E peekLast();2.2ArrayDeque类
ArrayDeque类实现了Deque接口,是一个双端队列。不像LinkedList是一个双向链表,ArrayDeque是一个双向数组。这么说有点不准确,应该是,ArrayDeque的底层实现是一个循环数,ArrayDeque是一个可变长度队列
双端队列只可以在两端做添加和删除操作,但ArrayDeque类还增加了两个方法可以在中间删除给定的元素:
public boolean removeFirstOccurrence(Object o)
public boolean removeLastOccurrence(Object o)3.优先级队列:PriorityQueue
优先级队列中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。然而,优先级队列并没有对所有的元素进行排序。如果用迭代的方式处理这些元素,并不需要对它们进行排序。优先级队列使用了一个优雅且高效的数据结构,称为堆(heap)。堆是一个可以自我调节的二叉树,对树执行添加(add)和删除(remove)操作,可以让最小的元素移动到根,而不必花时间对元素进行排序;
PriorityQueue类的底层是使用数组保存数据的:
transient Object[] queue;
private int size = 0;使用优先级队列的典型示例是任务调度。每一个任务都有一个优先级,任务以随机顺序添加到队列中。每当启动一个新的任务时,都将优先级最高的任务从队列中删除
例:
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue<GregorianCalendar> pq=new PriorityQueue<>();
pq.add(new GregorianCalendar(1906,Calendar.DECEMBER,9));
pq.add(new GregorianCalendar(1815,Calendar.DECEMBER,10));
pq.add(new GregorianCalendar(1903,Calendar.DECEMBER,3));
pq.add(new GregorianCalendar(1910,Calendar.JUNE,22));
System.out.println("Iterating over elements...");
for(GregorianCalendar date:pq){
System.out.println(date.get(Calendar.YEAR));
}
System.out.println("Removing elements...");
while(!pq.isEmpty()){
System.out.println(pq.remove().get(Calendar.YEAR));
}
}
}(二) Map映射
什么map -----映射 ---对应数学中的函数
Map中的key 叫键
Map 中的Value 叫值
总称也叫键值对
Map本身是一个接口与Collection任何关系
Map特点和用法:
1.通常情况下一个key对应一个value
2. 一个key可以对应两个value 但是对应后值会被覆盖
3. 多个key可以对应一个值
4. Map不存在index 也没有迭代器接口
public class MapTest {
public static void main(String[] args) {
Map<String,String> map = new HashMap<String,String>();
map.put("1", "zhangsanfeng");
map.put("2", "zhangsanfeng");
map.put("3", "zhangsan");
map.put("4", "feng");
map.put("5", "sanfeng");
Set<Entry<String,String>> set = map.entrySet();
Iterator it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
Set<String> setstring = map.keySet();
Iterator it1 = setstring.iterator();
while(it1.hasNext()){
System.out.println(it1.next());
}
Collection list = map.values();
Iterator it2 = list.iterator();
while(it2.hasNext()){
System.out.println(it2.next());
}
// System.out.println(list);
map.remove("2");
System.out.println(map);
}
}HashMap
1. HashMap中允许存放null键null值
2. 线程不安全 –线程不同步
3. 与HashTable类似
4. Hashset是HashMap的实例 HashMap的底层是HashTable哈希表
5.在Java中 HashTable的父类是Dictionary
HashMap底层原理
HashMap 继承 AbstractMap<K,V>
HashTable 继承 Dictionary
Map接口<K,V> entry<K,V>是Map接口的内部接口
主要属性:
初识容量 ---16
| /** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
最大容量 1*2的30次方
| static final int MAXIMUM_CAPACITY = 1 << 30; |
加载因子
| static final float DEFAULT_LOAD_FACTOR = 0.75f; |
HashMap.hashcode算法
| static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } |
HashMap 初识容量为16 HashTable 初识容量为11 加载因子都默认为0.75
HashTable扩容方式:Capacity*2 + 1
HashTable hash计算方式: key的hashcode 对table数组的长度进行取模
HashMap的 hash计算方式: key 的hashcode 进行了二次hash 为了能够得到更好的散列值
public class MapTest {
public static void main(String[] args) {
Map<String,String> map = new HashMap<String,String>();
map.put("1", "zhangsanfeng");
map.put("2", "zhangsanfeng");
map.put("3", "zhangsan");
map.put("4", "feng");
map.put("5", "sanfeng");
Set<Entry<String,String>> set = map.entrySet();
Iterator it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
Set<String> setstring = map.keySet();
Iterator it1 = setstring.iterator();
while(it1.hasNext()){
System.out.println(it1.next());
}
Collection list = map.values();
Iterator it2 = list.iterator();
while(it2.hasNext()){
System.out.println(it2.next());
}
// System.out.println(list);
map.remove("2");
System.out.println(map);
}
}HashTable
1、HashTable是可以序列化的。是线程安全的。HashTable之所以是线程安全的,是因为方法上都加了synchronized关键字。
2、Hashtable的遍历方式比较简单,一般分两步:
1). 获得Entry或key或value的集合;
2). 通过Iterator迭代器或者Enumeration遍历此集合。
3. 通过Iterator迭代器遍历Entry,或者是通过Enumeration遍历key、value的效率都比较高。
public class _HashtableText {
public static void main(String[] args) {
HashMap<String, Integer> xm = new HashMap<>();
hm.put(null, 23);
hm.put("王二麻", null);
System.out.println(hm);
HashTabled的扩容方法
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
//阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}















 4272
4272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









