









这篇文章的目的是写写常见的数据增强模式,也会把对应的标注随着增强模式对应更新,增强模式会持续更新,从最简单的开始...
import random
import torchvision.transforms as transforms
import cv2
import torch
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from skimage import io, transform
import xml.etree.ElementTree as ET
import torch.utils as utils
'''
这个脚本读取的是VOCdata,参考:https://github.com/Lxrd-AJ/YOLO_V1.git
'''
class CustomData(Dataset):
# file_root 是图片的根路径
# train_img 是train.txt的路径
def __init__(self, file_root, train_img, image_size=(448, 448), transform=None, pair_transform=None):
super(CustomData, self).__init__()
self.file_root = file_root
self.img_size = image_size
self.transform = transform
self.pair_transform = pair_transform
with open(train_img, 'r') as f:
self.img_and_target = [(os.path.join(file_root, 'JPEGImages', val.strip()+'.jpg'), os.path.join(file_root, 'Annotations', val.strip()+'.xml')) for val in f.readlines()]
def __getitem__(self, item):
image_path, target_path = self.img_and_target[item]
image = cv2.imread(image_path)
target = self.parseXml(target_path)
return image, target
def __len__(self):
return len(self.img_and_target)
def parseXml(self, xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
cls_bbox = []
for obj in root.iter('object'):
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('ymin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymax').text))
cls_bbox.append((cls, (w, h), b))
return cls_bbox
class RandomVerticalFlip(object):
def __init__(self, probability=1):
self.p = probability
def __call__(self, items):
if random.random() < self.p:
img, det = items
img = cv2.flip(img, flipCode=0)
update_det = []
for cls, wh, bbox in det:
xmin, ymin, xmax, ymax = bbox
update_ymin = wh[1] - ymax # 一种转换
update_ymax = wh[1] - ymin
update_det.append((cls, wh, (xmin, update_ymin, xmax, update_ymax)))
return (img, update_det)
else:
return items
class RandomHorizontalFlip(object):
def __init__(self, probability=1):
self.p = probability
def __call__(self, items):
if random.random() < self.p:
img, det = items
img = cv2.flip(img, flipCode=1)
update_det = []
for cls, wh, bbox in det:
xmin, ymin, xmax, ymax = bbox
update_xmin = wh[0] - xmax
update_xmax = wh[0] - xmin
update_det.append((cls, wh, (update_xmin, ymin, update_xmax, ymax)))
return (img, update_det)
else:
return items
def plot_bbox(img, bndbox):
for cls, wh, bbox in bndbox:
xmin, ymin, xmax, ymax = [int(val) for val in bbox]
point_color = (random.randint(0,255), random.randint(0,255), random.randint(0,255))
thickness = 2
line_type = 4
pt1, pt2 = (xmin, ymin), (xmax, ymax)
cv2.putText(img, cls, (xmin, ymin), cv2.FONT_HERSHEY_COMPLEX, fontScale=0.5, color=point_color, thickness=thickness)
cv2.rectangle(img, pt1, pt2, point_color, thickness, line_type)
return img
if __name__ == '__main__':
file_root = r'D:\data\voc\VOCdevkit\VOC2007'
train_txt = r'D:\data\voc\VOCdevkit\VOC2007\ImageSets\Main\train.txt'
custom_data = CustomData(file_root, train_txt)
# data_loader = utils.data.DataLoader(customData, batch_size=1, shuffle=True, num_workers=4)
random_vertical = RandomVerticalFlip()
random_horizontal = RandomHorizontalFlip()
for img, bbox in iter(custom_data):
vertical_img = img.copy()
vertical_bbox = bbox.copy()
horizontal_img = img.copy()
horizontal_bbox = bbox.copy()
update_img = plot_bbox(img, bbox)
# 展示原图
cv2.imshow('update_img', update_img)
cv2.waitKey(0)
# 展示水平翻转
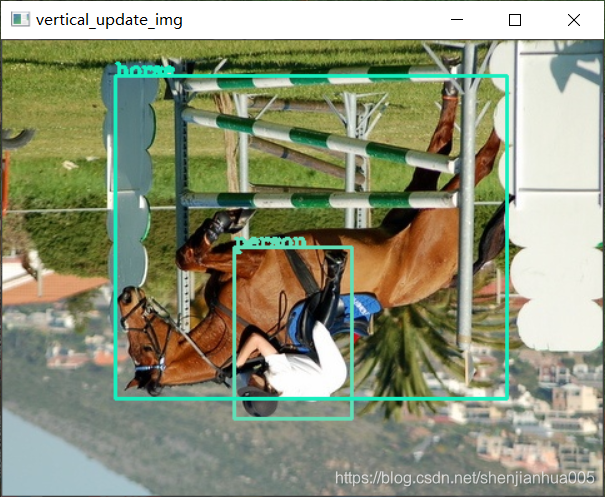
vertical_img, vertical_bbox = random_vertical((vertical_img, vertical_bbox))
vertical_update_img = plot_bbox(vertical_img, vertical_bbox)
cv2.imshow('vertical_update_img', vertical_update_img)
cv2.waitKey(0)
# 展示垂直翻转
horizontal_img, horizontal_bbox = random_horizontal((horizontal_img, horizontal_bbox))
horizontal_update_img = plot_bbox(horizontal_img, horizontal_bbox)
cv2.imshow('horizontal_update_img', horizontal_update_img)
cv2.waitKey(0)

















 5363
5363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









