








本文是基于马里兰大学教授 Hal Dame III(Blogger)课程内容的笔记。
感知器(Perceptron)这个词会成为Machine Learning的重要概念之一,是由于先辈们对于生物神经学科的深刻理解和融会贯通。
对于神经(neuron)我们有一个简单的抽象:每个神经元是与其他神经元连结在一起的,一个神经元会受到多个其他神经元状态的冲击,并由此决定自身是否激发。(如下图)
Neuron Model (From Wikipedia)
这玩意儿仔细想起来可以为我们解决很多问题,尤其是使用决策树和KNN算法时解决不了的那些问题:
- 决策树只使用了一小部分知识来得到问题的答案,这造成了一定程度上的资源浪费。
- KNN对待数据的每个特征值都是一样的,这也是个大问题。比如一组数据包含100种特征值,而只有其中的一两种是起最重要作用的话,其他的特征值就变成了阻碍我们找到最好答案的噪声(Noise)。
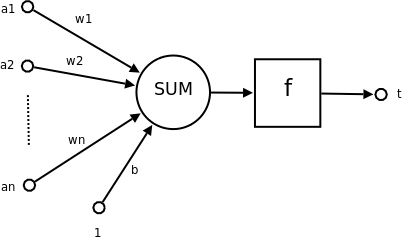
根据神经元模型,我们可以设计这样一种算法。对于每种输入值(1 - D),我们计算一个权重。当前神经元的总激发值(a)就等于每种输入值(x)乘以权重(w)之和。
neuron sum
我们还可以推导出以下几条规则:
- 如果当前神经元的某个输入值权重为零,则当前神经元激发与否与这个输入值无关
- 如果某个输入值的权重为正,它对于当前神经元的激发值 a 产生正影响。反之,如果权重为负,则它对激发值产生负影响。
接下来我们要将偏移量(bias)的概念加入这个算法。有时我们希望我们的神经元激发量 a 超过某一个临界值时再激发。在这种情况下,我们需要用到偏移量 b。
neuron sum with bias
偏移量 b 虽然只是附在式子后面的一个常数,但是它改变了几件事情:
- 它定义了神经元的激发临界值
- 在空间上,它对决策边界(decision boundary) 有平移作用,就像常数作用在一次或二次函数上的效果。这个问题我们稍后再讨论。
在了解了神经元模型的基本思路之后,我们来仔细探讨一下感知器算法的具体内容。
感知器算法虽然也是二维分类器(Binary Classifier),但它与我们所知道的决策树算法和KNN都不太一样。主要区别在于:
- 感知器算法是一种所谓“错误驱动(error-driven)”的算法。当我们训练这个算法时,只要输出值是正确的,这个算法就不会进行任何数据的调整。反之,当输出值与实际值异号,这个算法就会自动调整参数的比重。
- 感知器算法是实时(online)的。它逐一处理每一条数据,而不是进行批处理。

perceptron algorithms by Hal Dame III
感知器算法实际上是在不断“猜测”正确的权重和偏移量:
- 首先,感知器算法将所有输入值的权重预设为0。这意味着,输入值预设为对结果不产生任何影响。同时,偏移量也被预设为0。
- 我们使用参数MaxIter。这个参数是整个算法中唯一一个超参数(hyper-parameter)。这个超参数表示当我们一直无法找到准确答案时,我们要最多对权重和偏移量进行几次优化。
- 在算法PerceptronTrain第5行,我们用之前提到的加法公式计算出当前激发值a。由于这个简单的感知器算法只可以产生二维结果,我们只检查激发值a的符号是否与实际值同号(第6行)。如果同号,这意味着算法为当前数据的输入值找到了合适的权重和偏移量,算法结束。
- 如果激发值与实际值异号,感知器算法就要进行自调节的过程(第7, 8行)。自调节过程分成两步:
1. 对于每种输入值的权重w,我们根据标准值y的符号将其增大或减少x。这是基于:
activation self-adjust
2. 增大或减小一点偏移量 b。
再说一下MaxIter这个唯一的超参数。如果我们将MaxIter调到很大,这意味着我们会将每一条训练数据(Training data)用到极致。俗话说“物极必反”,训练过度(over-fitting)也不是什么好事,在实际应用过程中可能会由于缺少变通性而导致实际测试结果不尽如人意。而如果我们将MaxIter调到很低,比如1,可能又会导致训练不足(under-fitting)。
接下来我们从空间的角度形象的来研究一下感知器算法。所谓感知器算法,其实是在数据空间中找一个边界(boundary),使得落在边界两边的数据点分别为正值或负值。

decision boundary sample
换句话说,这个边界代表的是具有激发值a为0的点的集合。
先前我们提到偏移量 b 这个概念。为了由浅入深,我们先不考虑这个值对图像造成的影响,或者说 b = 0的情况。当b = 0或 b 不存在时,我们的激发值 a 可以由之前讨论过的下面这个式子求出:
activation
如果对线性代数有一些了解的话,可以想到,这个式子其实可以写作:
a = w · x (向量w <点乘> 向量x)
回顾一下点乘的概念: 两个互相垂直的向量的点积总是零。若a和b都是单位向量(长度为1),它们的点积就是它们的夹角的余弦。
所以,我们所说的边界,其实就是在空间中与w向量垂直的线或平面。

simple decision boundary
如上图所示,B是垂直于w <1, 1>的直线,也是这个平面上数据的边界。因为只有w的方向对求出边界比较重要,我们一般用单位向量来标记w的方向。
了解完边界的基本概念后,我们来引入偏移量这个值。这个值的作用是非常简单的。
上面我们所说的边界将正负两种激发值划分开来。偏离量 b 这个值可以帮我们沿着w向量的方向来移动这个边界:
- 如果偏移量b 是正数,我们的边界将沿着w向量的反方向平移。这表示有更多的激发值 a 被分类为正值。
- 反之,如果偏移量b是负数,边界将沿着w向量所指方向移动。这表示有更多的激发值 a 被分类成负值。














 2525
2525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









