









目录
作者:shenmingik
邮箱:2107810343@qq.com
时间:2021/1/17 14:26
开发环境:VS 2017
数据库:MySQL
编程语言:C++
源码连接:https://share.weiyun.com/AKiPPdvt 密码:gur6dr
ID3算法简介
ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法。
在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策空间。
信息熵和信息增益:
在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。在认识信息增益之前,先来看看信息熵的定义:
熵这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度,而在信息学里面,熵是对不确定性的度量。在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
以下是公式内容,由于Markdown编辑器排版有问题,故贴图:
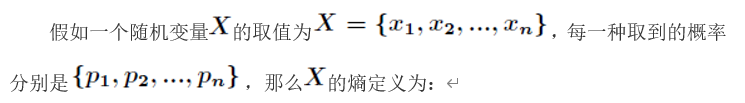

所以通俗的来讲:
以以下的例子来说明ID3是如何构建决策树的:

这个表格共有六列,其实id为ID列,a b c d四列为自变量,class列为因变量。
首先根据class列算出Entorpy(D)= -(15/20 * log(15/20) + 5/20 * log(5/20))=0.811;
然后计算a列的Entorpy(D,a)=0.445;
然后就可以计算出gain(a) = Entorpy(D) - Entorpy(D,a) = 0.366;
依次计算出:
gain(b) = Entorpy(D) - Entorpy(D,b) = 0.065;
gain(c) = Entorpy(D) - Entorpy(D,c) = 0.01;
gain(d) = Entorpy(D) - Entorpy(D,d) = 0.187;
然后选出gain值最大的作为根节点,即a节点。
当a=1时对剩下数据进行筛选,再次计算信息熵Entorpy;
当a=2时对剩下数据进行筛选,再次计算信息熵Entorpy;
…
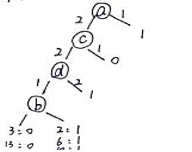
最终便可以得到一个决策树:
系统简介
看了上面的ID3算法简介,我们大致已经理清了 ID3算法的脉络。接下来便是把理论转换为实践成果的时候了。
但是转化的过程中仍然有几个难点:
- 训练集数据的存储、输入
- ID3算法的实现
- 如何在系统中构建出决策树
- 决策树如何判定输入数据
为了解决这些问题,我们可以把系统进行细细的拆分成一个个模块,笔者主要拆分成了以下几个文件且它们的调用关系如下:

- DataBase.h、Table.h文件是有关数据段存储、与输入问题的;
- ID3.h文件是用来实现ID3算法的;
- DecisionTree.h、Key.h、Value.h文件用来生成并存储决策树的信息,并且判定输入数据的
接下来,由我为大家来进行一个详细的剖析。
数据的存储、输入
DataBase.h 文件详解
在这里我借助了MySQL数据库的强大数据管理功能。如果有对MySQL不了解的同学,可以看一下我的博客专栏:MySQL
里面介绍了MySQL的安装教程以及一些基础的操作,后续我也会推出较为高深的MySQL使用教程。
在C++中想要连接MySQL就需要对其进行一些配置,详情可以我的参考这篇博客:VS 2017 C++ 如何连接MySQL
然后便可以使用MySQL的功能了,MySQL设计的原则:
- 传入SQL语句
- 调用执行函数
- 返回去执行结果
这样设计非常简单,但是仍然存在一些问题:SQL语句过于冗长且一旦出现错误很难定位
所以笔者对数据库进行了一些包装:
DateBase()
//构造函数,用于连接数据库MYSQL_RES* sql_select(string table, string cond = "")
//在table表中查询满足cond条件的信息int sql_get_rownumber(string table)
//得到table表中的行数int sql_get_rownumber(string table,string conditions)
//得到table表中满足conditions条件的行数vector<pair<string,int>> sql_get_rownumber_bygroup(string table,string group, string conditions = "")
//得到table表中先筛选出满足conditions条件的信息,再根据group来继续计数统计
此项目基本上用到的就这几个函数,其他函数可以查看源码。
Table.h 文件详解
Table文件中存储了关于操作表的一些信息,其继承自DataBase.h文件。
为什么要这么设计呢?
因为我认为数据库本质上是对表的一个操作,至于库更多的起到的是一个“文件夹”的作用。而我把DataBase.h文件中的函数均设置为保护类型就是基于此理念的。
用户只用操作表就可以,把对数据库的详细操作细节隐藏起来。
在Table有一个string 变量来存储表名、一个vector数组来存储列名。而且vector数组都存储的是string类型,因为我认为string类型十分通用,可以转换为任何类型。而且对于决策数来说,字符型是一个不错的选择。
具体表中有以下几个函数:
Table(string table_name, vector<string> columns)
//构造函数,需传入表名和列名MYSQL_RES* select(string condition)
//得到满足condition条件的信息int get_column_number()
//返回列数int get_row_number()
//得到所有行数int get_row_number(string conditions)
//得到满足condition条件的行数int get_column_index(const char* column_name)
//根据列名返回其在vector中的下标,失败返回-1vector<pair<string, int>> get_rownumber_bygroup(int column_index, string cond = "")
//先筛选出满足conditions条件的信息,再根据group来继续计数统计string get_table_name()
//返回表名string operator[](int index)
//返回对应列名
ID3算法的实现
对于一个机器学习的分类算法来说,ID列,自变量和因变量是必须的,而且ID3算法必须要有一个数据读入的接口一个一个决策树来保存计算出来的结果。所以ID3类中的属性如下:
private:
Table table_;
struct value_attribute
{
int id_;
vector<int> independent_;
int dependent_;
//根据下标返回自变量
int operator[](int index)
{
return independent_[index];
}
}attribute_;
private:
DecisionTree tree_;
然后便可以详解整个算法了:
- 得到总共的行数
- 得到结果为1的行数
- 如果全为1的函数与总行数相等的话或者全为1的行数为0的话,那么这个时候就可以判定在此情况下预测的结构,并且将结果放入决策树
- 计算每一列的信息熵,的到信息熵最大的作为根节点,将根节点放入决策树
- 然后根据根节点的取值筛选出数据,转到步骤1
为了完成这个算法就需要以下函数(只列举了重要的):
double compute_comentropy(double divisor, double dividend)
//通过传入及结果为真的行数和总行数去计算信息熵void generate_decision_tree(string condition="")
//生成决策树 算法的核心函数DecisionTree& get_decision_tree()
//得到决策树
决策树的构建与判定输入数据
根据决策数的名字来看,我们是应当选择树形数据结构来存储节点信息。但是寻常的二叉树结构是做不到这一点的,所以我参考了b+数的思路设计了一种新树——键值树。
Key.h Value.h 文件详解
键值树的起始节点是一个键,其有两个属性,它的值与一个指向值的一个指针:
class Key
{
public:
string key_;
shared_ptr<Value> value_ = nullptr;
};
而值由一个vector存储,每个元素又有三个属性,它的值、一个指向键的指针、一个指向预测结果的指针:
class Value
{
public:
vector<Relation> value_;
};
class Relation
{
public:
string relation_value_;
shared_ptr<Key> key_ = nullptr;
shared_ptr<Prediction> prediction_ = nullptr;
};
而预测结果很简单,就是一个bool值:
class Prediction
{
public:
bool prediction_;
};
根据这一的键值树的结构,我之前在ID3简介那里举过的例子便可表示成如下结果:

DecisionTree.h 文件详解
这个文件包含了决策树的生成方法以及一个指向键的指针作为起始节点。
主要函数如下:
void push_decision(string condition, bool decision)
/*
根据condition条件,得到最近的键
向值中插入结果
*/void push_root(string condition, string root)
/*
根据condition条件,得到最近的键
向值中插入键
*/void push_value(string condition, string value)
/*
根据condition条件,得到最近的键
向键中插入值
*/bool get_prediction(MYSQL_ROW input,Table& table)
//传入一行数据以及表_,返回这行数据的预测结果
最终的运行结果:

以上便是这个系统设计的大体思路,如有错误或者不理解的地方可以给我私信或在底下评论。
参考文献
[1] 无
















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











