









Spark on Yarn的两种运行模式实战:
此时不需要启动Spark集群,只需要启动Yarn即可,Yarn的ResourceManager就相对于Spark Standalone模式下的Master!(我们启动spark集群是要用到standalone,现在有yarn了,就不用spark集群了)
1、Spark on Yarn的两种运行模式:唯一的决定因素是当前Application从任务调度器Driver运行在什么地方!
a) Cluster:(如果Spark运行在on Yarn上,根本就没必要启动Spark集群,Master是ResourceManager)
b) Client:Driver运行在当前提交程序的客户机器上;
需要说明的是:无论什么模式,只要当前机器运行了Spark。
将并行任务变成50000个(50000台虚拟机)
2、Sparkon Yarn的运行实战:
a) Client模式:方便在命令终端
启动Spark集群是启动Master和Worker,因为这两个进程是用来管理的资源的,做计算是在Executor中JVM进程中的线程的代码,Spark集群的计算跟Spark集群没有关系,实质是;
天机解密:Standalone模式下启动Spark集群(也就是启动Master和Worker)其实启动的是资源管理器,真正作业计算的时候和集群资源管理器没有任何关系,所以Spark的Job真正执行作业的时候不是运行在我们启动的Spark集群中的,而是运行在一个个JVM中的,只要在JVM所在的集群上安装配置了Spark即可!
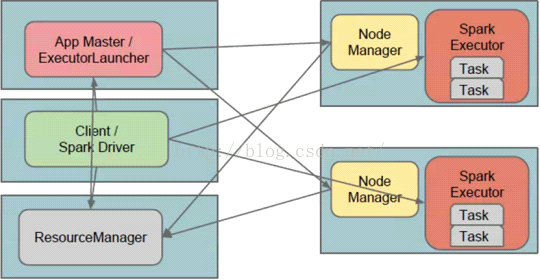
上述程序的运行证明了Cluster.YarnSchedulerBackend来接受计算资源的注册。3、Sparkon Yarn模式下Driver与ApplicationMaster的关系:
a) Cluster:Driver位于ApplicationMaster进程中,我们需要通过Hadoop默认指定的8088端口来通过Web控制台查看当前的Spark程序运行的信息,例如进度、资源的使用;
b) 只负责资源的申请和launchExecutor,此时启动后的Executor
三:最佳实践
1、在Spark on Yarn的模式下HadoopYarn的配置yarn.nodemanager.local-dirs会覆盖Spark的Spark.local.dir;
2、在 实际生产环境下一班都是采用Cluster,我们会通过HistoryServer来获取最终全部的集群运行的信息;
3、如果想直接看运行的日志信息,可以使用以下命令:
yarn logs -ApplicationId <app ID>

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









