







1. 前言
近年来,在许多NLP任务中,无监督学习单词嵌入已经取得了巨大的成功。他们的效果如此之好,以至于在许多NLP体系结构中,几乎完全取代了更传统的分布式表示,如LSA特征和Brown聚类。
可以看看2017的EMNLP和ACL会议,他们都及其关注词嵌入,即使最近的ACL Communication,也直言道词嵌入是NLP突破的催化剂,这时候我们不仅要仔细思考,词嵌入真的需要如此的大肆宣传吗?
本综述旨在深入了解单词嵌入及其有效性。我们将讨论它们的起源,比较流行的嵌入单词模型和与之相关的挑战,并尝试回答/揭穿一些常见的问题和误解。然后,我们将通过将它们与分布语义学中的文献联系起来,并强调实际上能够解释单词嵌入模型成功的因素,来消除单词嵌入的假象。
2. 词嵌入简史
向量空间模型自20世纪90年代以来一直被应用于分布语义学中,从那时起,我们已经看到了一个用于估计词的连续表示的数字模型的发展,潜在dirichlet分配(LDA)和潜在语义分析(LSA)就是两个典型技术。
词嵌入一词最初是由bengio等人创造的。2003年,他用神经语言模型和模型的参数训练他们。然而,collobert和weston无疑是第一个在2008年的论文中展示了预先训练过的单词嵌入威力的研究学者,这是一个统一的自然语言处理架构,在该架构中,当在下游任务中使用时,他们将单词嵌入作为一种非常有效的工具,同时也将其应用于解开今天许多方法所建立的神经网络结构。Mikolov等人(2013年)通过创建Word2vec(一种能够训练和使用预训练的词嵌入的工具包)真正将嵌入单词推向了前台。2016年,Pennington等人向我们介绍了Glove,一组更具竞争力的预训练词嵌入模型,使得词嵌入突然成为主流。
目前,词汇嵌入被认为是少数成功应用于无监督学习的方法之一。他们不需要昂贵的词性标注,这是主要优势,它们可以从已经存在的未经标记的语料库中派生出来新的词向量表示。
3. 词嵌入模型
- Embedding Layer :(Bengio et al., 2006)
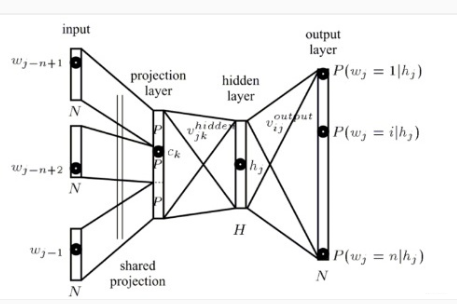
自然地,每一个前馈神经网络将词汇作为输入,并将它们作为向量嵌入到一个较低维的空间中,然后通过反向传播对其进行微调,必然产生词汇嵌入作为第一层的权重,这通常被称为layer emdbeding。
像这样的网络和像word2vec这样的方法的关键区别在于其计算复杂性,这解释了为什么直到2013年,单词嵌入才在nlp空间变得如此突出。近年来,计算能力的迅速发展和可承受性无疑帮助了它的出现。
Glove和Word2vec的训练目标是另一个不同之处,相同之处两者都是为了产生编码一般语义关系的词嵌入,并在许多下游任务中提供好处。相比之下,常规神经网络通常产生特定于任务的嵌入,但在其他地方使用它们时存在局限性。
在接下来的模型对比中,约定一下符号是成立的:
- T :预训练语料库中的序列;
- w1,w2,w3,⋯,wT :训练的单词,归属于词汇集合V,vocabulary的大小表示为|V|;
- n:表示单词所在的上下文环境,也就是surrounding单词的数量;
- vw:表示单词w的输入词嵌入(d维),其输出的词嵌入为vw`;
- Jθ :表示词嵌入的优化目标函数,θ指网络中设计的高参数;
- fθ(x):表示每个输入x的模型输出得分;
4. Classic neural language model 经典的语言模型
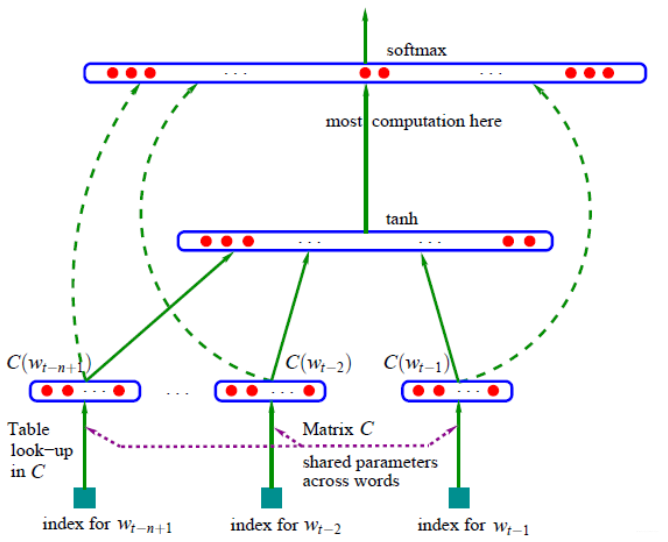
Bengio等人(2013[1])提出了最经典神经语言模型。[它由一个隐藏层的前馈神经网络组成,该网络可以预测图2中序列中的下一个单词。他们的模型最大化了我们上面描述的原型神经语言模型目标(为了简单起见,省略了正则化项):
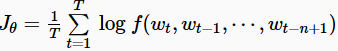
模型的输出是f(wt,wt−1,⋯,wt−n+1);意味着p(wt|wt−1,⋯,wt−n+1)通过softmax计算的概率;n表示该该单词所在序列的前n个单词;毕竟Bengio想利用前n-1个单词作为输入,预测第n个单词。
Bengio等人最先介绍的这种模型被称为词嵌入的先驱(就是emgbeding layer),即R空间中的实值词对应的特征向量。他们的模型的基础仍然可以在今天的神经语言和嵌入单词的模型中找到。包括:
- Embedding Layer: 该层通过一个索引词向量与词嵌入矩阵相乘,从而生成词嵌入;
- Intermediate Layer(s): 通过一个或多个层将输入映射为中间层,例如,采用非线性全连接层将前n个单词的词嵌入连接;
- Softmax Layer:对应于单词库V,最终模型对每个word产生一个概率分布(概率最大的单词对应的应该是下一个要预测的词,训练的目的就是使得概率最大的单词逼近金标准);
Bengio等人也揭示了当时最先进模型遇到的两个问题:
- 首先,可以利用LSTM进行替换,引入上下文的记忆,该方法被[6][7]所采用;
- 最终的SoftMax层(更准确地说,归一化项)确定为网络的主要瓶颈,因为计算SoftMax的成本与vocabulary 中的单词数量成比例,而vocabulary通常包含数十万个,百万个words;
因此,在Large Vocaburary[9]上减轻计算SoftMax的成本是神经语言和嵌入单词模型的主要挑战/机遇之一。
5. C&W model
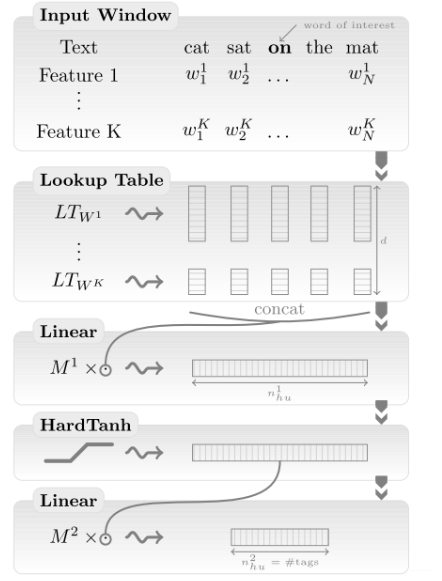
在Bengio等人在神经语言模型方面的初步探索之后,随着计算能力和算法还没有达到能够训练大量词汇的水平,对单词嵌入的研究一直停滞不前。2008年,collobert和weston[4](就是c&w)证明了在足够大的数据集上训练的单词嵌入具有语法和语义意义,并提高了下游任务的性能。在他们2011年的论文中,他们进一步解释了这一点[8]。
为了避免计算昂贵的SoftMax,collobert和weston[4]的解决方案是使用一个可以替代的目标函数:而不是Bengio等人的交叉熵准则,该准则最大化给定前面n个词的下一个词的概率,Collobert和Weston训练一个网络输出一个更高分数fθ,作为正确的单词预测(而在Bengio的模型中可能是单词序列)。为此,他们使用pairwise ranking criterion,如下所示:
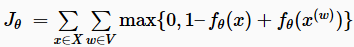
在语料库中,他们从所有可能的窗口X中采样包含n个words的正确窗口x。然后,对于每个窗口x,他们生成一个错误的x)。进而,他们的目标是使模型输出的分数之间的距离最大化,以获得正确和错误的窗口,并留有1的margin。如果没有ranking objective,他们的模型架构如图3所示,类似Bengio等人的模型。
由此生成的的语言模型的embeding,已经拥有语义关联,例如,国家聚集在一起,语法上相似的词在vector空间中形成聚类效应。尽管ranking objective 舒缓了softmax的复杂性,他们保留了中间的全连接隐含层和hardTanh层,这仍然是计算代价的主要来源,在词汇量|V|=130000情况下,训练这样的模型也需要几周的时间。
6. Word2Vec
Word2vec可以说是最流行的嵌入模型。由于单词嵌入是NLP深度学习模型的一个关键元素,因此一般认为它也属于深度表示的一种。然而,从技术上讲,word2vec并不被视为深度学习的一个组成部分,理由是它的架构既不深入,也不使用非线性(与bengio的模型和C&W模型相比)。
Mikolov等人[2]给出了学习单词嵌入的两种架构,与以前的模型相比,这种架构的计算成本更低。这些体系结构比Bengio和C&W模型有两个主要优点;
- 丢弃了高昂的隐含层
-
允许语言模型考虑word的上下文,虽然最终目的就是为了学习word embeding
模型的成功不仅可以归因于神经网络结构差异,更重要的是来自于具体的训练策略。
6.1 Continuous bag-of-words (CBOW)
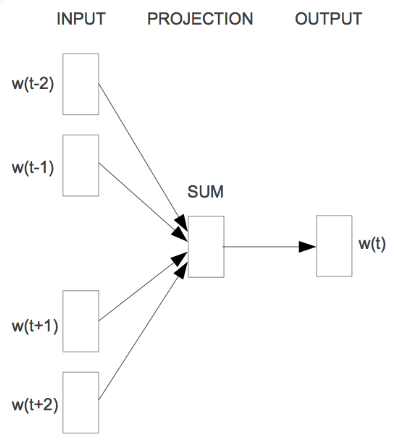
与只能基于过去单词序列进行预测的语言模型不同,CBOW的上下文策略明显不受这种限制,如图4所示。当我们看到他的目标函数的时候,更会恍然大悟。Mikolov等人将Bengio等人的生成模型变成了判别模型:
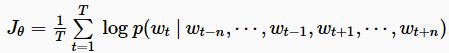
所以,谈到该模型的时候,我们应该认识到,上下文和判别目标函数是他的创新点。当然,我们也会问,该模型仍然面临Vocaburary中那么多words进行softmax的高昂操作。其实作者在原文中也进行了改进,提出了分层softmax及其近似的策略。
6.2 Skip-gram
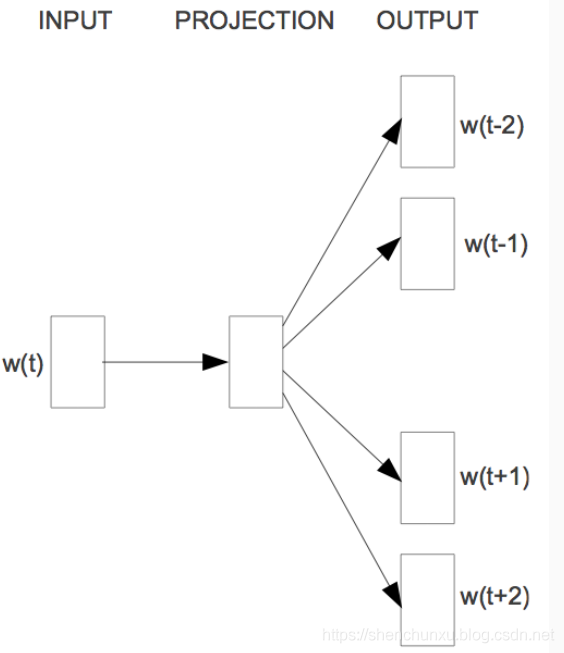
乍一看该模型,我们会感觉这就是CBOW的逆过程。通过目标函数也能看出来,确实是这样:
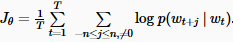
不过,在真实用到他们时,还是有不同的。上一篇博客中也谈到过,由于训练方式的不同,CBOW在句法syntactic分析上效果显著,skip-gram在语意semantic和句法syntactic性能都很优秀。
7. GloVe
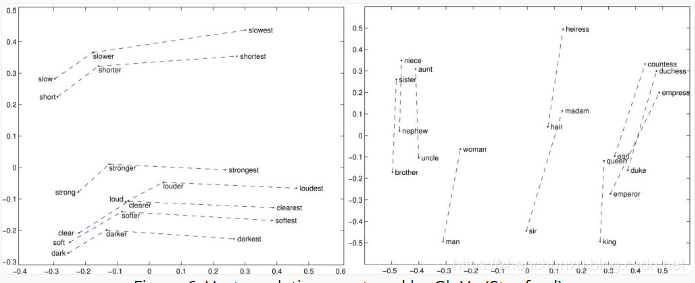
Glove在保留Word2vec优势的同时,引入了全局的统计信息。在后面我会仔细分析Glove的成功原因。具体来说,Glove的创建者阐明两个单词的共现概率的比率(而不是它们的共现概率本身)是包含信息的,因此希望将这些信息编码为矢量差异。为了实现这一点,他们提出了加权最小二乘目标J,其直接目的是减少两个词的矢量的点积与其共现次数的对数之间的差异:
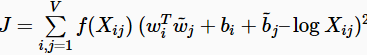
其中,wi和bi表示第i个单词的矢量和偏置;带有~标识的wj和bj上下文第j个单词对应的矢量和偏置;Xij指包含单词j的上下文环境中出现单词i的次数;f(Xij)是权重函数,对于很低的共现频率将会赋予非常小的权重。
由于共现计数可以直接编码在word-context共现矩阵中,所以Glove采用这样的矩阵而不是整个语料库作为输入。
8. Word embeddings vs. distributional semantics models
Word2vec和Glove等嵌入词模型因其具有规律性和显著性优于传统的分布语义模型(DSMs)而获得了广泛的应用。许多人把这归因于word2vec的神经结构,或者它预测单词的事实,而单词似乎天生就比仅仅依靠共现计数有优势。DSMs可以看作是计数模型,因为它们通过在共现矩阵上操作来“计数”单词间的共现。相反,神经嵌入模型可以被看作是预测模型,因为它们试图预测周围的单词。2014年,Baroni等人[11]证明,在几乎所有任务中,预测模型始终优于计数模型。
但是,)Levy等人(2015)在英语维基百科上训练所有模型,并根据常用的单词相似性和类比数据集对其进行评估。得到了以下结论:
- Levy等人发现SVD——而不是单词嵌入算法——在相似性任务上表现最好,而SGN【Skip-gram with Negative Sampling (SGNS)】在相似性数据集上表现最好。此外,与其他选择相比,它们还揭示了超参数的重要性:超参数设置通常比算法选择更重要,没有哪一种算法能比其他方法更好。在更大的语料库上进行训练有助于完成某些任务。在6个案例中,有3个案例中,调整超参数更为有益。
- 有了正确的超参数,没有一种方法比另一种方法具有一致的优势。在Levy等人的所有比较任务中,SGNS优于Glove。这必须用细粒度处理,因为Glove在其他任务上表现得更好。CBOW在任何任务上都不优于SGN。
目前,研究学者对于word Embeding的初步经验是:
-
不要在SVD中使用移位PPMI
-
不要“正确”使用SVD,即没有特征向量加权(性能比特征值加权下降15点,p=0.5)。
-
在短上下文(窗口大小为2)中使用PPMI和SVD。
-
在SGNS中使用许多负样本。
-
对于所有方法,务必使用上下文分布平滑(将unigram分布提高到α=0.75的幂次)。
-
一定要使用SGNS作为基线(强健、快速和廉价的训练)。
-
尝试在SGNS和Glove中添加上下文向量。
初步结论:
Levy等人的结果与普遍的共识相反,即单词嵌入优于传统方法。相反,它们表明无论使用单词嵌入还是分布方法,它通常都没有任何区别。真正重要的超参数得到了调整,并且使用了适当的预处理和后处理步骤。Jurafsky的小组[13],[14]最近的研究反映了这些发现,并说明SVD,而不是SGNS,通常是首选,对于准确的words presentation非常重要。
References:
[1]: Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3, 1137–1155. http://doi.org/10.1162/153244303322533223
[2]: Mikolov, T., Corrado, G., Chen, K., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of the International Conference on Learning Representations (ICLR 2013), 1–12.
[3]: Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. NIPS, 1–9.
[4]: Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing. Proceedings of the 25th International Conference on Machine Learning – ICML ’08, 20(1), 160–167. http://doi.org/10.1145/1390156.1390177
[5]: Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543. http://doi.org/10.3115/v1/D14-1162
[6]: Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2016). Character-Aware Neural Language Models. AAAI. Retrieved from http://arxiv.org/abs/1508.06615
[7]: Jozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., & Wu, Y. (2016). Exploring the Limits of Language Modeling. Retrieved from http://arxiv.org/abs/1602.02410
[8]: Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural Language Processing (almost) from Scratch. Journal of Machine Learning Research, 12 (Aug), 2493–2537. Retrieved from http://arxiv.org/abs/1103.0398
[9]: Chen, W., Grangier, D., & Auli, M. (2015). Strategies for Training Large Vocabulary Neural Language Models, 12. Retrieved from http://arxiv.org/abs/1512.04906
[10]: Levy, O., Goldberg, Y., & Dagan, I. (2015). Improving Distributional Similarity with Lessons Learned from Word Embeddings. Transactions of the Association for Computational Linguistics, 3, 211–225. Retrieved from https://tacl2013.cs.columbia.edu/ojs/index.php/tacl/article/view/570
[11]: Baroni, M., Dinu, G., & Kruszewski, G. (2014). Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. ACL, 238–247. http://doi.org/10.3115/v1/P14-1023
[12]: Levy, O., & Goldberg, Y. (2014). Neural Word Embedding as Implicit Matrix Factorization. Advances in Neural Information Processing Systems (NIPS), 2177–2185. Retrieved from http://papers.nips.cc/paper/5477-neural-word-embedding-as-implicit-matrix-factorization
[13]: Hamilton, W. L., Clark, K., Leskovec, J., & Jurafsky, D. (2016). Inducing Domain-Specific Sentiment Lexicons from Unlabeled Corpora. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Retrieved from http://arxiv.org/abs/1606.02820
[14]: Hamilton, W. L., Leskovec, J., & Jurafsky, D. (2016). Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change. arXiv Preprint arXiv:1605.09096.














 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









