







 本文介绍了迁移学习的概念,区别了它与监督学习、半监督学习和自我学习的区别。迁移学习通过利用预训练模型在少量目标样本上进行再训练,提升分类效果。文章还列举了图像识别、对象检测和文字识别等迁移学习的实际应用案例,探讨了预训练模型的使用挑战,如调试难度、数据需求和模型维护等。
本文介绍了迁移学习的概念,区别了它与监督学习、半监督学习和自我学习的区别。迁移学习通过利用预训练模型在少量目标样本上进行再训练,提升分类效果。文章还列举了图像识别、对象检测和文字识别等迁移学习的实际应用案例,探讨了预训练模型的使用挑战,如调试难度、数据需求和模型维护等。
1.前言
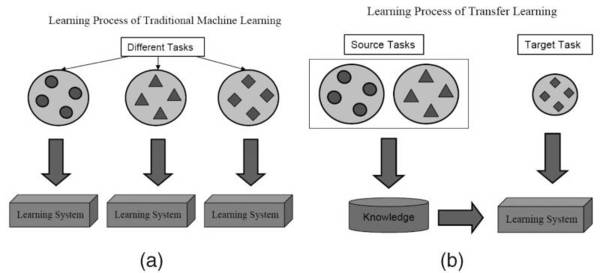
在面对某一领域的具体问题时,通常可能无法得到构建模型所需规模的数据。然而在一个模型训练任务中针对某种类型数据获得的关系也可以轻松地应用于同一领域的不同问题。这种技术也叫做迁移学习(Transfer Learning)。
Qiang Yang、Sinno Jialin Pan,“A Survey on Transfer Learning”,IEEE Transactions on Knowledge & Data Engineering,vol. 22, no. , pp. 1345–1359, October 2010, doi:10.1109/TKDE.2009.191
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









