









摘要
目前大多数模型都是在基于英伟达的设备上进行训练的,在当前的环境下,国内研究团队很难获得足够的计算资源,严重限制了国内大模型的快速发展。在本文中,华为团队提出了Pangu Ultra,一个大型语言模型(LLM),具有1350亿个参数的密集大模型,这些模块在Ascend神经处理单元(NPU,即华为自己的GPU)上训练,实现了国产GPU落地的重要一步。
为了稳定训练,作者提出了两种技术:深度缩放夹心归一化(depth-scaled sandwich norm)和微小初始化(tiny initialization)。这两种技术都是为了保持梯度范数的稳定。具体来说:
- 作者首先用夹心归一化替换了归一化,并且根据模型的深度,在后层归一化中调整初始化值的缩放比例。这种基于深度的调整能够有效控制梯度波动的范围。
- 此外,作者还根据模型的宽度和深度调整权重初始化的标准差,从而实现微小初始化。
这两种技术使得整个训练过程中的梯度更加稳定,消除了在训练盘古超大模型时出现的损失峰值,提升了模型的整体性能。
对多个不同基准的评估表明,Pangu Ultra显着提高了Llama 405 B和Mistral Large 2等密集LLM的最先进能力,甚至与DeepSeek-R1取得了相当的结果。团队的探索表明,Ascend NPU能够高效地训练具有超过1000亿个参数的密集模型。
论文地址:https://github.com/pangu-tech/pangu-ultra/blob/main/pangu-ultra-report.pdf
-
-
模型架构
Pangu Ultra的基本架构类似于Llama 3。它有1350亿个参数,隐藏层维数为12,288,基于SwiGLU的前馈网络(FFN)中间维度大小为28,672,有94层。Pangu Ultra中的注意力块利用组查询注意力(GQA),通过合并96个查询头和8个KV头来减少KV缓存大小。
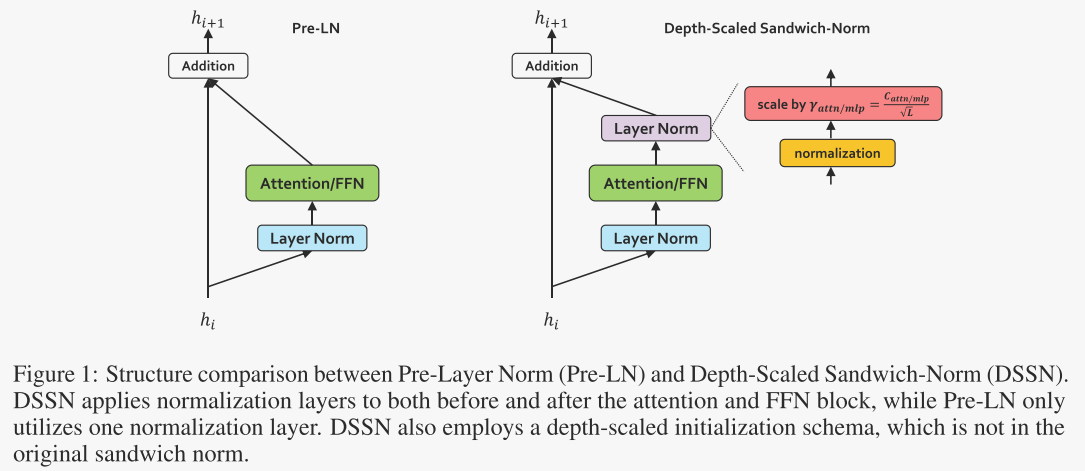
在解决大型密集LLM中训练稳定性和收敛性的根本挑战方面有两个关键区别。作者提出了深度缩放夹心归一化(depth-scaled sandwich norm)来代替层归一化和新的参数初始化方法微小初始化(tiny initialization)。通过集成这些技术,Pangu Ultra实现了对以前密集模型的实质性改进。
深度缩放夹心归一化(depth-scaled sandwich norm)
大规模密集模型通常采用更深的架构,而混合专家(MoE)模型则主要通过扩展宽度来扩展规模。不过,增加深度会给保持训练稳定性带来更大的挑战。由于预训练的成本非常高,确保大规模密集语言模型(LLM)的稳定训练变得至关重要。
预层归一化(Pre-LN)被发现能让深度Transformer的反向传播更高效,因此在基于Transformer的大规模语言模型架构中得到了广泛应用。
Pre-LN(前归一化)是Transformer架构中一种层归一化(Layer Normalization)的实现方式,与Post-LN(后归一化)相对。在Pre-LN中,归一化操作是在每个层的计算之前进行的。具体来说,输入数据首先经过层归一化处理,然后再传递到子层进行计算。这种设计有助于缓解训练过程中梯度消失和梯度爆炸的问题,从而提高训练的稳定性和速度。
然而,Pre-LN也存在一些潜在的缺点。例如,在预训练期间,早期层的梯度可能会比后期层大,这可能会影响训练的稳定性。为了解决这些问题,研究者们提出了多种改进方案,例如NormFormer,通过在每个Transformer层中增加额外的归一化操作来解决梯度幅度不匹配的问题。
Pre-LN(前归一化)和Post-LN(后归一化)是Transformer架构中两种不同的层归一化(Layer Normalization)策略,它们的主要区别在于归一化操作的执行位置不同。
Pre-LN:归一化操作在子层计算之前进行。
Post-LN:归一化操作在子层计算之后进行。
然而,在采用预层归一化(Pre-LN)结构的模型中,每个子层的输出规模容易波动,这很容易导致训练不稳定。为了解决这个问题,夹心归一化(sandwich-norm)在每个子层的输出进入残差连接之前,对其应用了层归一化。尽管夹心归一化能够保持单个子层输出的规模稳定,但通过多层的残差连接逐步累积输出范数,仍然可能引发训练不稳定。
为了缓解这一问题,作者提出了深度缩放夹心归一化(Depth-scaled Sandwich-Norm,DSSN)。它将夹心归一化与基于深度的初始化方案相结合。通过可训练的gamma参数,层归一化调节各层层间输出的幅度,这些gamma参数的初始化值与网络深度的倒数成比例。图1展示了深度缩放夹心归一化与预归一化架构之间的差异。深度缩放夹心归一化的公式为:
,
其中 L 是网络的层数, 和
分别是注意力层和前馈网络(FFN)层的初始输出标准差。对于盘古超大模型,作者将
设置为 0.283,将
设置为 0.432。
-
初始化
现有的研究观察到,模型初始化在训练的稳定性和性能中起着至关重要的作用。基于Transformer的LLM通常采用小初始化(small initialization),即将所有权重初始化为标准差为 的正态分布,其中d是隐藏层维度。此外,还有一种常见的做法是在初始化时将残差层的权重按
的因子进行缩放,其中L是层数。
作者的研究发现,通过使用来根据模型的深度和宽度进行缩放初始化,可以实现更快的损失收敛,并且在下游任务中表现更好。作者把这种初始化方法称为 TinyInit。作者推测,TinyInit 能够在整个模型中实现更一致的参数规模,这可能有助于优化和收敛。
研究表明,与其他层相比,嵌入层需要不同的初始化策略。具体地,保持嵌入权重的标准偏差接近于1可以增强训练稳定性。作者的实验结果表明,初始化的标准偏差为0.5实现了良好的模型性能。
-
tokenizer
分词器的设计对模型性能有显著影响。一个理想的词汇表需要在领域覆盖(处理文本、数学和代码等多种任务)和效率(用更少的标记编码数据)之间取得平衡。常见的方法是使用字节对编码(Byte-Pair Encoding,BPE)和SentencePiece,通过计算整个训练数据集中的词频来构建词汇表。然而,这种方法存在领域不平衡的问题,因为像普通文本这样的常见领域会在词汇表中占据主导地位,而数学和代码等专业领域则由于数据量有限而被低估。
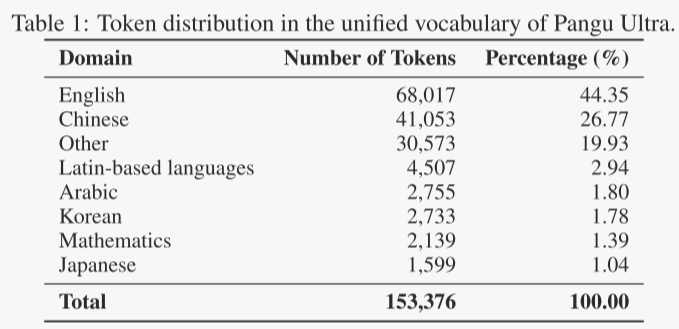
盘古超大模型采用了一种领域感知的词汇表策略。作者在包括普通中文、普通英文、代码和数学在内的多个领域分别进行独立的频率分析,生成各自领域特定的词汇表。然后,作者将这些词汇表合并并去重,形成一个包含153,376个独特标记的统一词汇表。这种策略在保持整体压缩效率的同时,确保了各个领域在词汇表中的平衡表示。表1总结了不同领域中详细的标记分布情况。
-
-
模型训练
训练过程包括三个主要阶段:预训练、长上下文扩展和后训练。每个阶段都有特定的训练策略和数据构建方法,以逐步提升模型的能力。
预训练阶段
数据构建:Pangu Ultra模型的预训练语料库包含13.2万亿个由分词器生成的高质量和多样化的标记。表2显示预训练过程分为三个连续的阶段:通用阶段、推理阶段和退火阶段。这些阶段旨在逐步发展通用知识和语言能力、增强推理技能,并进一步完善知识和行为。每个阶段使用的数据量为12万亿,包括两个不同的子阶段,分别为7.4万亿和4.6万亿数据,以及0.8万亿和0.4万亿标记。
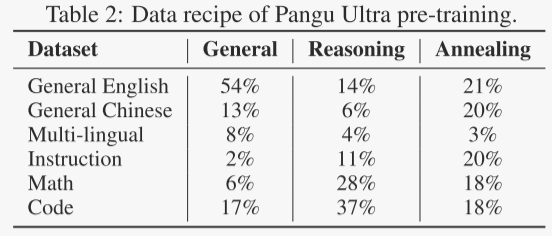
- 在最初的通用训练阶段,作者使用专注于发展广泛语言能力和通用知识的语料库。这一阶段主要由来自各种来源的英语和中文数据组成,包括网页、书籍、百科全书等。还融入了多语言和各种行业领域的数据。
- 在第二个推理阶段,作者增加了高质量和多样化的数学和编程数据的比例,将其提高到语料库的60%以上,以增强盘古超大模型的推理能力。编程数据包括纯代码和混合文本代码样本。数学数据也包含大量的英文和中文文本。此外,广泛使用LLM生成的合成数据来丰富语料库。
- 第三个退火阶段旨在帮助模型巩固和有效应用在前几个阶段学到的知识和推理技能。因此,作者更加注重指令数据,它占语料库的约20%。作者策划了涵盖广泛主题的内部题库,并构建了短链和长链思维(CoT)响应。这些推理路径经过精心提炼,以确保清晰和逻辑连贯。
总体而言,Pangu Ultra模型的预训练数据经过精心设计,以确保高质量、多样化和最小冗余。作者为数据分配质量和难度标签,并在所有三个阶段采用基于课程的采样策略,从简单的例子逐渐过渡到更复杂的例子,贯穿整个训练周期。
数据质量评估:数据质量评估在提升数据整体质量方面起着至关重要的作用。在训练盘古超大模型时,作者采用基于规则的启发式方法和基于模型的评估方法来提升数据质量。
对于基于模型的质量评估,作者以盘古系列模型作为基础模型。为了更好地使质量评估与人类的价值判断保持一致,作者使用人工标注的数据集对模型进行微调。经过微调的评估器随后被应用于超过10万亿标记的大规模预训练语料库。数据样本在多个维度上进行评分,包括清洁度、流畅性、教育价值和丰富性。这些标注的分数随后被用于优先采样策略,其中高质量的样本被分配更高的采样概率。
为了验证数据质量评估的有效性,作者使用一个拥有26亿参数的代理模型进行消融研究。实证结果表明,为了达到相当的性能,使用低分数据训练的模型需要比使用高质量高分数据训练的模型多1.6倍的标记。因此,高质量的数据对于提升训练效率至关重要。
预训练参数:
Pangu Ultra模型使用AdamW优化器进行训练,权重衰减设置为0.1,epsilon设置为。动量参数设置为
和
。梯度裁剪范数设置为1.0。为了提高训练的稳定性和整体性能,Pangu Ultra模型的预训练分为以下阶段:
- 0T–7.4T tokens:序列长度设置为4K(RoPE基底为
)。批量大小从1,024增加到1,536(1.2T)和2,048(1.9T)。增加的批量大小提高了训练效率和吞吐量。学习率遵循余弦衰减,从
衰减到
,并设置4,000步的预热步骤以确保早期训练的稳定。
- 7.4T–12.0T tokens:序列长度保持为4K,批量大小为2,048。在这个阶段,学习率固定为
- 12.0T–12.8T tokens:序列长度增加到8K(RoPE基底为
)。批量大小减少到1,536。学习率使用余弦调度从
。
-
长上下文扩展
LLM理解长文本输入的能力在深度思考过程和实际应用中至关重要。在预训练的最后阶段,盘古超大模型通过训练长序列数据来支持最大上下文长度达到128K。训练分为两个逐步扩展的阶段:第一阶段将上下文长度扩展到32K,第二阶段进一步扩展到128K。
旋转位置嵌入(RoPE)是支持超长输入序列的核心模块。目前,开源的LLM通常通过增加RoPE中的基础频率,或者采用类似YaRN的方法来扩展上下文长度。作者的研究发现,如果超参数选择得当,这两种方法的表现都很出色。在盘古超大模型中,作者采用了增加基础频率的方法。
为了确定长上下文扩展中RoPE的基础频率,作者在目标序列长度下,使用“大海捞针”(Needle In A Haystack,NIAH)任务评估不同基础频率的离线性能,并选择表现最佳的基础频率。这确保了长上下文训练的初始损失相对较低。在实际应用中,32K的基础频率被确定为,而128K的基础频率为
。盘古超大模型长上下文训练的详细超参数总结如下:
- 8K到32K阶段:序列长度扩展到32K(RoPE基础频率为
。批量大小为384,学习率设置为
- 32K到128K阶段:序列长度进一步扩展到128K(RoPE基础频率为
。批量大小减少到96,学习率保持在
-
后训练对齐
在后训练阶段,Pangu Ultra模型通过监督微调(SFT)和强化学习(RL)与人类偏好对齐。这一阶段的重点是构建高质量、多样化的指令数据,并设计可扩展且高效的训练策略。
数据构建:在构建后训练数据时,作者注重数据的质量、多样性和复杂性。数据池涵盖了广泛领域和任务类型,包括一般性问答、人工智能生成内容(AIGC)、文本分类与分析、编程、数学、逻辑推理和工具使用等。这些任务覆盖了金融、医疗保健和公共服务等应用领域。数据来源包括开源指令数据集、现实世界的行业查询以及从预训练语料库中衍生的合成问题。
为了促进数据的多样性,数据样本的选择基于两个正交维度:领域和任务类型。使用具有不同粒度级别的层次化标签模型来支持平衡的数据采样。通过结合基于规则的验证和基于模型的验证来管理数据质量,这有助于消除低质量或模糊的样本。
为了更好地激发Pangu Ultra模型的推理能力,后训练数据中大约有七十分之六的部分由推理任务组成,如数学、编程和逻辑。后训练数据涵盖了各种复杂性,重点是中等至高难度的任务。
后训练策略:在后训练阶段,Pangu Ultra模型首先通过监督微调(SFT)来建立初步的指令遵循能力。在SFT之后,作者应用基于结果的奖励信号的强化学习(RL),以进一步增强盘古超大模型的推理能力、对齐能力和指令遵循能力。作者实现了一个针对昇腾(Ascend)基础设施优化的容延迟强化学习框架,该框架使得在昇腾上能够高效地进行大规模策略优化。
为了指导强化学习过程,作者实现了一个混合奖励系统,为数学、编程和一般问题解决等任务提供特定的反馈。这个混合奖励系统结合了确定性的奖励信号和基于模型的评估,以促进稳定且高效的策略优化。
-
-
训练系统
在13.2万亿tokens上训练拥有1350亿参数的盘古超大模型,需要确保在大规模计算集群中的训练稳定性和效率。在这一部分,作者将从两个重要角度详细说明训练系统:并行化策略和系统级优化技术。总的来说,在8192个昇腾NPU上训练Pangu Ultra模型时,作者实现了超过52%的模型浮点运算利用率(MFU)。
计算设置
作者部署了一个拥有8192个昇腾神经处理单元(NPUs)的计算集群来训练盘古超大模型。集群中的每个节点都配备了8个NPU,这些NPU通过华为缓存一致性系统(Huawei Cache Coherence System,HCCS)以全网状拓扑结构相互连接,每个设备都配备了64GB的内存。节点间的通信通过基于以太网的RDMA(RoCE)网络实现,利用200Gbps的高速互联来支持不同节点上NPU之间的通信。
-
模型缩放的并行策略
为了扩展模型训练,作者采用了多种并行策略的组合,将模型分布在多个NPU上,包括数据并行(DP)、张量并行(TP)、序列并行(SP)和流水线并行(PP)。对于Pangu Ultra模型,作者使用128路数据并行(结合ZERO技术)来降低模型参数和相关优化器状态的内存成本。作者应用8路张量并行来利用节点内高带宽进行高效的激活传输,同时采用8路流水线并行来利用节点间的连接,因为流水线并行只需要在分区边界传输激活。
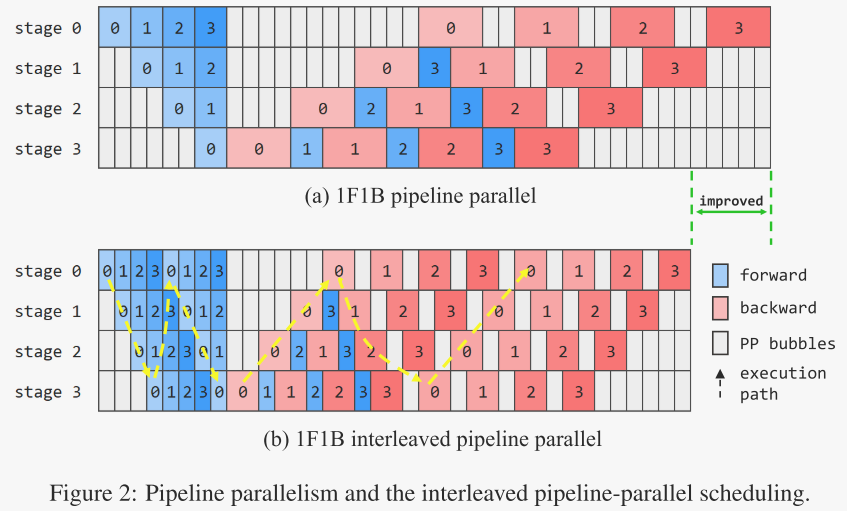
然而,正如现有研究所提到的,当训练集群规模扩大时,流水线并行会遇到严重的流水线气泡(PP bubbles)问题,这主要是由于批量大小的限制。对于一前向一反向(1F1B)的流水线调度,气泡比例定义为,其中p表示流水线阶段的数量,n表示每个数据并行的微批量数量。这个比例代表了加速器的空闲时间,如图2所示。大规模训练集群会增加数据并行的数量,这反过来又会由于批量大小的限制而减少分配给每个数据并行的微批量数量,从而导致气泡比例显著增加。因此,最小化气泡比例对于提高系统效率至关重要。
PP bubbles 指的是流水线并行(Pipeline Parallelism,PP)过程中出现的“气泡”现象。这些“气泡”是指在流水线并行中,由于不同阶段(Stage)之间的依赖关系,导致某些设备在等待数据或计算结果时出现的空闲时间。
产生原因:流水线并行机制:在流水线并行中,模型被划分为多个阶段(Stage),每个阶段在不同的设备上执行。当一个阶段完成计算后,需要等待下一个阶段的输入数据,这会导致设备在某些时刻处于空闲状态。
在这种情况下,作者在每个设备上采用了6路虚拟流水线阶段的交错流水线并行调度,并成功地将气泡比例从30.45%降低到6.8%。通过仔细调整流水线并行(PP)和虚拟流水线并行(VPP)阶段之间的负载平衡,作者能够在8192个NPU的集群上实现大约43%的模型浮点运算利用率(MFU)作为基线。
-
系统优化
在上文提到的优化基础上,实现了43%的模型浮点运算利用率(MFU),作者进一步实施了额外的系统级增强措施,以将训练效率提升到新的高度。通过一系列内核融合、通过子序列划分实现的上下文并行、数据缓存和共享机制以及其他改进,盘古超大模型在训练效率方面获得了显著提升。这些全面的优化使系统能够实现超过52%的MFU,与基线配置相比,相对提高了9%。
核融合(Kernel fusion)
内核融合在LLM训练中被广泛采用以提高效率。它将多个操作合并到一个内核中,减少了对全局内存的数据访问次数。在Pangu Ultra模型的训练阶段,关键操作符被融合,从而显著提高了硬件利用率和整体训练效率。
Kernel Fusion(内核融合) 是一种用于优化计算任务(尤其是深度学习任务)的技术,通过将多个计算内核(Kernel)合并为一个更大的内核,减少内存访问开销和内核启动时间,从而提高计算效率
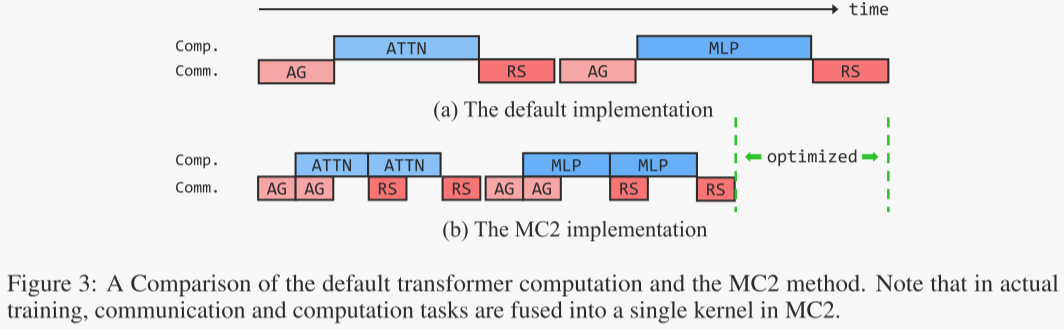
MC²-合并计算与通信张量并行(MC2 - Merged Compute and Communication):当与序列并行结合时,MC²引入了全聚集(All-Gather,AG)和归约分散(Reduce-Scatter,RS)通信操作,用于在分布式设备之间交换输入和输出激活。这种方法在矩阵乘法(MatMul)和AG/RS通信之间存在直接依赖关系,这从根本上限制了张量并行通信与计算工作流的重叠。MC²通过将MatMul计算与通信操作融合来应对这一挑战。它将大型计算和通信任务分解为细粒度的子任务,并采用流水线执行方式,以最大化通信与计算之间的重叠。因此,MC²显著减少了通信延迟,并提高了硬件利用率(见图3)。
NPU融合注意力(NPU Fusion Attention):随着序列长度的增加,训练具有长序列长度的LLM时,自注意力机制的内存和计算需求呈二次方增长。为了应对这些挑战,Flash Attention(FA)因其卓越的性能而成为LLM训练中的标准技术。盘古超大模型采用了一种名为NPU融合注意力(NFA)的自注意力融合操作符,该操作符针对昇腾NPU进行了专门优化,为各种自注意力计算场景提供了系统级改进。
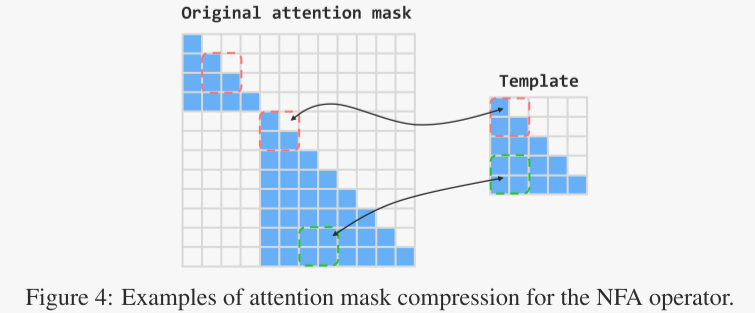
值得一提的是,盘古超大模型采用了一种重置注意力掩码策略,以防止序列内不同文档之间的自注意力。这需要为每个序列计算相应的注意力掩码,从而导致显著的内存和计算开销。为了减轻生成注意力掩码的时间和内存需求,NPU融合注意力(NFA)操作符采用了掩码压缩优化。
如图4所示,NFA利用一个2048×2048的因果掩码作为模板,在融合注意力操作符内构建计算掩码。在每次迭代中,盘古超大模型根据文档结束标记(end-of-document,EOD)的位置检索实际序列长度,然后将其作为输入提供给NFA操作符,以加速自注意力的计算。NFA的详细用法在昇腾文档中有提供。
除了MC²和针对昇腾NPU优化的融合注意力(NFA)外,盘古超大模型的训练还集成了RMSNorm、SwiGLU、RoPE等关键组件的融合算子优化,以及梯度累加融合和流水线并行(PP)的发送/接收通信融合等技术。这些融合算子旨在减少内核启动和内存访问的开销,同时保持高数值精度并增强整体训练性能。
长上下文训练的优化
扩展长上下文能力对于长文档摘要和对话式人工智能等应用正变得越来越重要。然而,长序列的训练在时间和内存复杂性方面都面临诸多挑战。为了提高长上下文训练的效率,我们提出了以下两个关键策略。
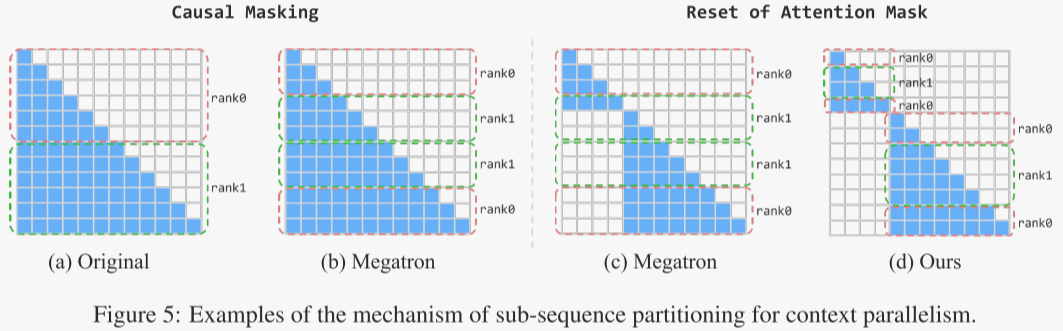
子序列划分实现上下文并行:上下文并行(CP)是训练非常长序列的一个重要方法,它将输入序列划分为多个片段以减少内存消耗。然而,采用因果掩码时,简单地将序列划分为CP块会导致环形自注意力(RSA)的负载严重失衡(如图5(a)所示)。Megatron-LM通过将序列划分为2×CP块来解决这一问题,每个等级(rank)都会收到来自顶部和底部的块,从而在CP组内平衡负载(图5(b))。不过,当重置注意力掩码时,这种方法仍然会导致负载失衡(图5(c))。因此,在进行128k长上下文的训练时,作者提出了一种负载平衡的划分策略用于CP训练,每个等级负责计算每个子序列内的两个块(图5(d))。
快速掩码生成与数据复用:当作者将Pangu Ultra模型的训练序列扩展到128k时,生成注意力掩码或计算实际序列长度仍然会产生不容忽视的性能开销。此外,在重置注意力掩码的训练场景中,每个虚拟流水线阶段(VPP)都需要在每次迭代中检索相应的掩码或实际序列长度,这导致了重复计算和开销增加。作者通过以下方式优化这些问题:(1)使用高效的NPU操作来计算注意力掩码,而不是在CPU上构建它,从而加速掩码生成并消除CPU和NPU之间数据传输的需要;(2)启用跨VPP阶段掩码共享,其中注意力掩码由第一阶段(VPP0)生成,并在同一等级的不同VPP阶段之间共享,从而避免重复的掩码计算和内存成本。
 -
-
-
结果
预训练训练损失曲线
在这一部分,我们将讨论盘古超大模型的评估结果,包括预训练性能和后训练结果。此外,我们还提供了全面的消融研究,以检验模型架构,并进一步讨论训练盘古超大模型的观察结果。
图6展示了Pangu Ultra模型在整个预训练过程中的训练损失曲线。损失曲线中的每个部分对应一个训练阶段,这些损失曲线在所有训练阶段均显示出一致的下降趋势。在第二阶段,尽管由于学习率保持不变,下降速度有所放缓,但性能指标在整个阶段仍持续稳定改进。
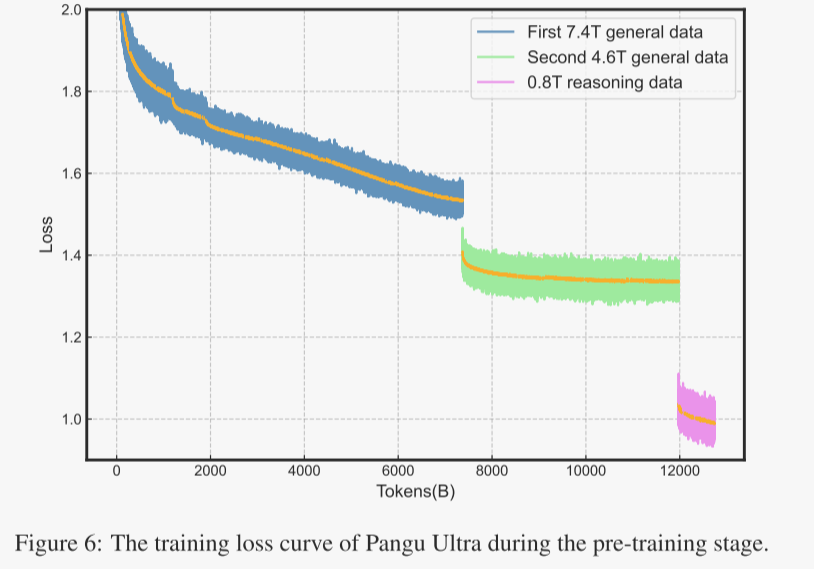
零损失峰值(Zero loss spike):如图6所示,在整个预训练过程中没有出现任何损失峰值。尽管在LLM训练中损失峰值是常见的现象,但在这里没有出现损失峰值,这突显了作者采用的深度缩放夹心归一化(Depth-scaled Sandwich Norm)和TinyInit在确保训练稳定方面的重要性。损失峰值对模型性能的负面影响将在第5.4.1节中进一步详细阐述。
-
预训练阶段
基准测试
作者使用开源基准测试在多个领域对Pangu Ultra模型的基础模型进行了评估,包括语言理解、问答、代码生成和数学问题解决。评估主要使用英文和中文测试集,并加入了一些多语言基准测试以扩大覆盖范围。
- 语言理解:作者使用Hellaswag和Winogrande进行上下文推理任务的评估,使用DROP、RACE和ARC系列进行综合阅读理解评估,同时使用PIQA、Natural Questions和TriviaQA来评估知识检索能力。
- 问答:评估包括使用C-Eval来评估中文知识,使用MMLU及其高级变体MMLU-Pro来评估英语领域知识,并通过BigBenchHard来评估创造性问题解决能力。
- 代码生成与理解:作者使用HumanEval和MBPP进行标准代码生成任务的评估,而使用CruxEval进行代码理解和推理能力的评估。
- 数学推理:作者使用CMath和GSM8K来评估基础算术和简单问题解决能力,使用MATH来评估高级数学推理能力,使用MGSM来评估多语言数学问题解决能力。
基线与比较设置
作者将Pangu Ultra模型与其他几个强大的基线模型进行了比较,这些基线模型既包括密集模型(如Qwen2.5-72B、Llama-405B),也包括混合专家(MoE)架构(如DeepSeek-V3)。对于基础模型,作者的大多数评估使用少量样本输入(few-shot inputs),少数情况下使用零样本提示(zero-shot prompts)。作者对大多数基准测试使用标准答案进行精确匹配评估,而对于代码生成任务则采用基于执行的验证方法。
评估结果
在表3中,作者将Pangu Ultra模型的预训练基础模型与其他领先的模型进行了比较。总体而言,Pangu Ultra模型在大多数通用英文基准测试和所有中文基准测试中均达到了最先进的性能水平。尽管在与代码和数学相关的任务上落后于DeepSeek-V3,但在这些领域仍具有竞争力。更深入的分析表明,Pangu Ultra模型在中文基准测试中表现出色,超过了Qwen 2.5-72B和DeepSeek-V3,后者是当前表现最佳的中文模型。此外,与Llama 3.1-405B相比,Pangu Ultra模型在大多数具有挑战性的基准测试中获得了更好的分数,同时仅使用了Llama 405B所需训练浮点运算量的约29%。这些结果表明了我们模型架构的有效性和训练数据的高质量。
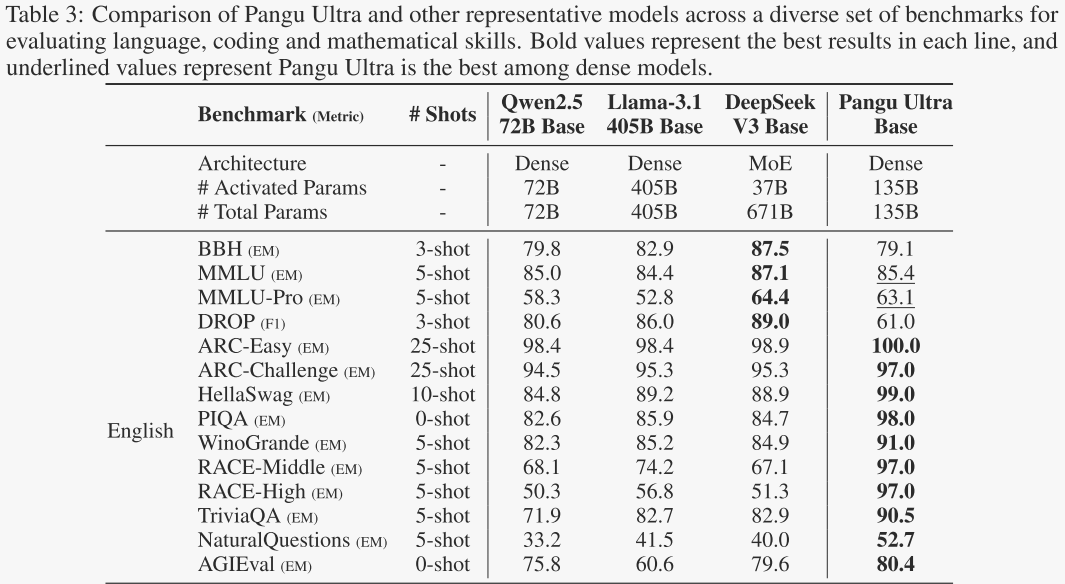
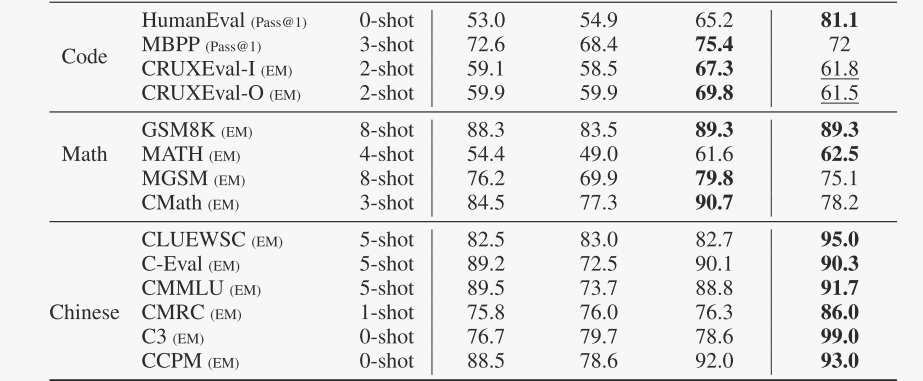
-
后训练阶段
基准测试
作者对Pangu Ultra模型在推理和非推理任务上的能力进行了全面评估:
- 复杂推理任务:涵盖三个专业子类别:
- 数学能力:通过AIME 2024和MATH-500进行评估。
- 编程竞赛基准:使用LiveCodeBench进行评估。
- 科学推理任务:通过GPQA Diamond进行评估。
- 通用语言理解和推理能力:通过MMLU-Pro和Arena Hard进行评估。
基线与比较设置
作者将Pangu Ultra模型与多个强大的基线模型进行了比较,包括GPT-4o0513、推理模型DeepSeek-R1、Hunyuan-T1,以及大型密集模型Qwen2.5-72B-Instruct和Mistral-Large 2。作者使用Pass@1(多次独立运行的平均通过率)作为评估指标来衡量性能。
评估结果
在表4中,作者将Pangu Ultra模型的评估结果与其他基线模型进行了比较。Pangu Ultra模型在推理基准测试(包括AIME 2024、MATH-500、GPQA和LiveCodeBench)上达到了最先进的性能,同时在通用语言理解任务中也保持了强大的能力。与密集型LLM(Qwen和Mistral-Large 2)相比,盘古超大模型在推理任务中表现出显著的优势。这种卓越的性能源于预训练阶段使用的0.8万亿推理专项数据(见第3.1.3节)。推理增强的基础模型为后续的后训练阶段带来了显著的好处。
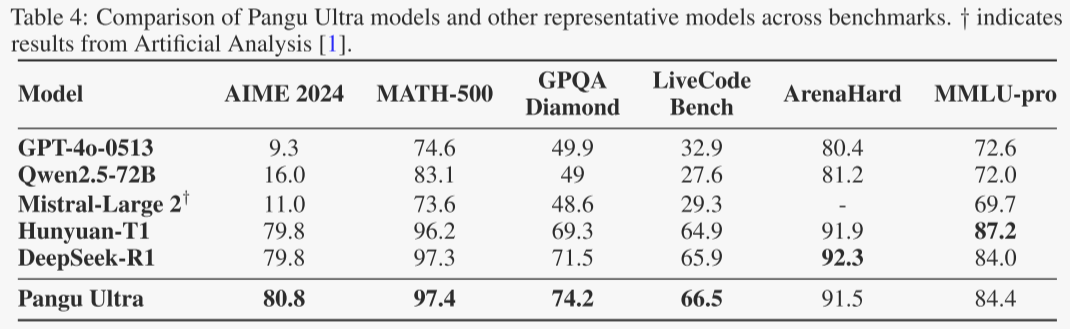
消融实验
本节介绍了模型架构的其他消融研究,并分析了关键的训练行为,以促进对密集LLM训练的更深入理解和讨论。
实验验证深度缩放夹心归一化的有效性
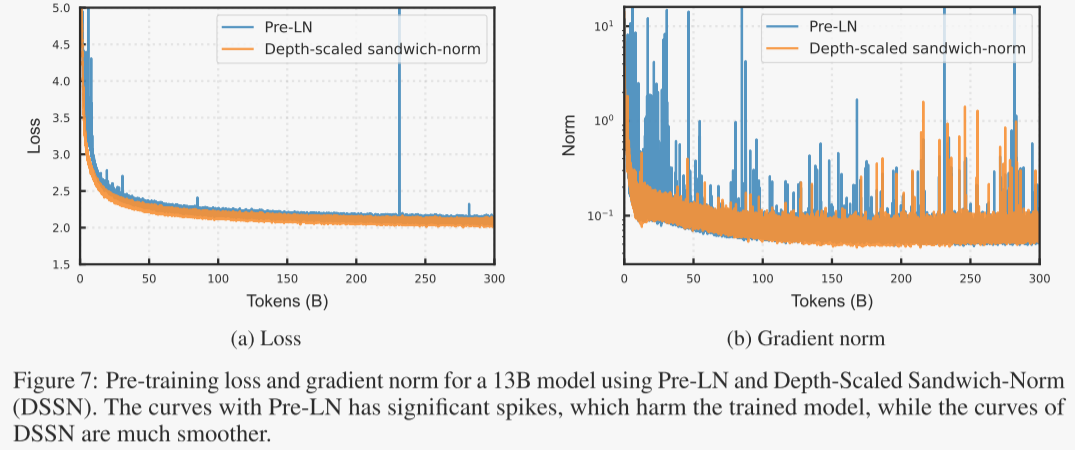
作者通过实验验证了深度缩放夹心归一化(Depth-scaled Sandwich Norm)相比于预归一化(Pre-Norm)架构的有效性。实验使用了一个包含130亿参数的密集Transformer模型,在3000亿标记上进行训练,两种配置均采用相同的超参数。结果表明,深度缩放夹心归一化显著提升了训练的稳定性和收敛速度。
- 梯度稳定性和损失峰值消除:如图7所示,深度缩放夹心归一化架构能够稳定梯度范数,并有效消除损失峰值,从而实现更快的训练收敛。
- 性能评估:作者在两个综合基准测试上评估了性能:EN basic(包含多个英文基准测试)和ZH basic(代表中文基准测试)。此外,作者还使用LAMBADA(英文)和WPLC(中文)的下一个标记预测任务进行了额外评估,结果进一步证实了应用深度缩放夹心归一化的优势。
消融实验:深度缩放因子的影响
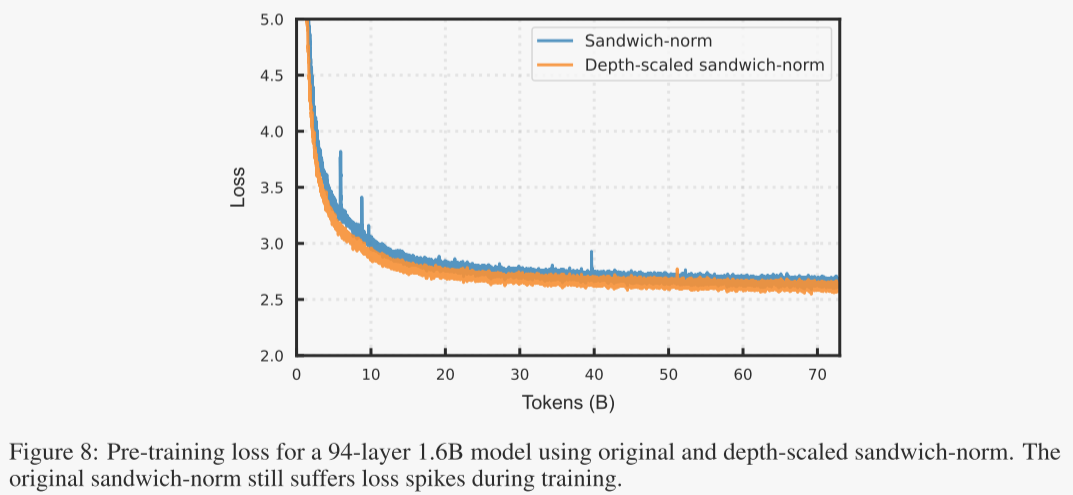
为了进一步验证深度缩放因子在RMSNorm初始化中的作用,作者进行了消融实验。实验使用了一个包含16亿参数和94层的代理模型,该模型与盘古超大模型具有相同的深度。通过这个代理模型,作者检验了夹心归一化在训练非常深的Transformer模型中的有效性。
实验结果:如图8所示,使用普通夹心归一化(没有深度缩放因子)时,会出现一些损失峰值。而我们的深度缩放夹心归一化则能够平稳训练,并获得更低的损失。
这些实验结果表明,深度缩放夹心归一化在消除预训练过程中的损失峰值方面至关重要,这对于实现最优的模型性能非常关键。

作者通过实验验证了TinyInit初始化策略的有效性。在训练了1020亿标记后,使用TinyInit策略初始化的Pangu Ultra(标准差为)相比于使用传统初始化方法的基线模型(标准差分别为
)和
)表现显著更好。评估结果如表6所示。
此外,BIG-bench(aug)是一个通过数据增强开发的内部测试集,旨在减轻测试集泄露的影响。

Pangu Ultra的层数据
图9展示了Transformer各层中注意力模块和前馈网络(FFN)模块的激活模式,包括均值、标准差和最大激活值(top-1)。激活值的分布表现出稳定性,标准差在整个预训练过程中保持一致的规模,同时保留了清晰的层间模式。
作者的分析发现存在“超级激活值”,其大小在浅层达到103量级,这一现象与Llama模型中的发现一致。值得注意的是,图9表明这些最大激活值随着层深度的增加而逐渐减小,表明它们对最终输出的影响相对较小。
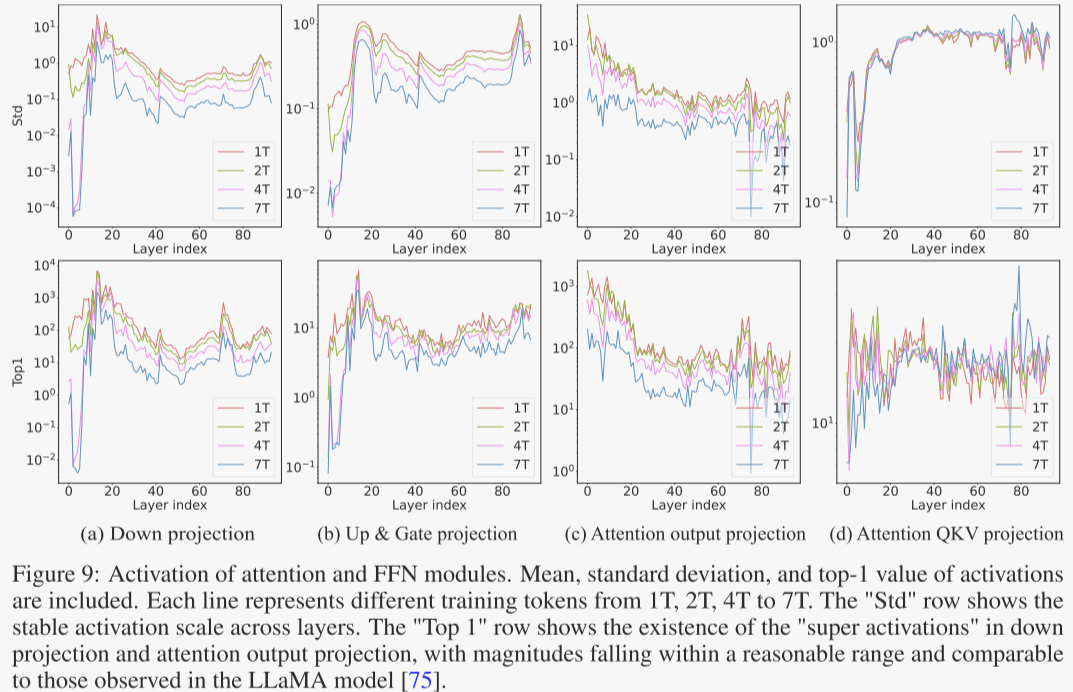
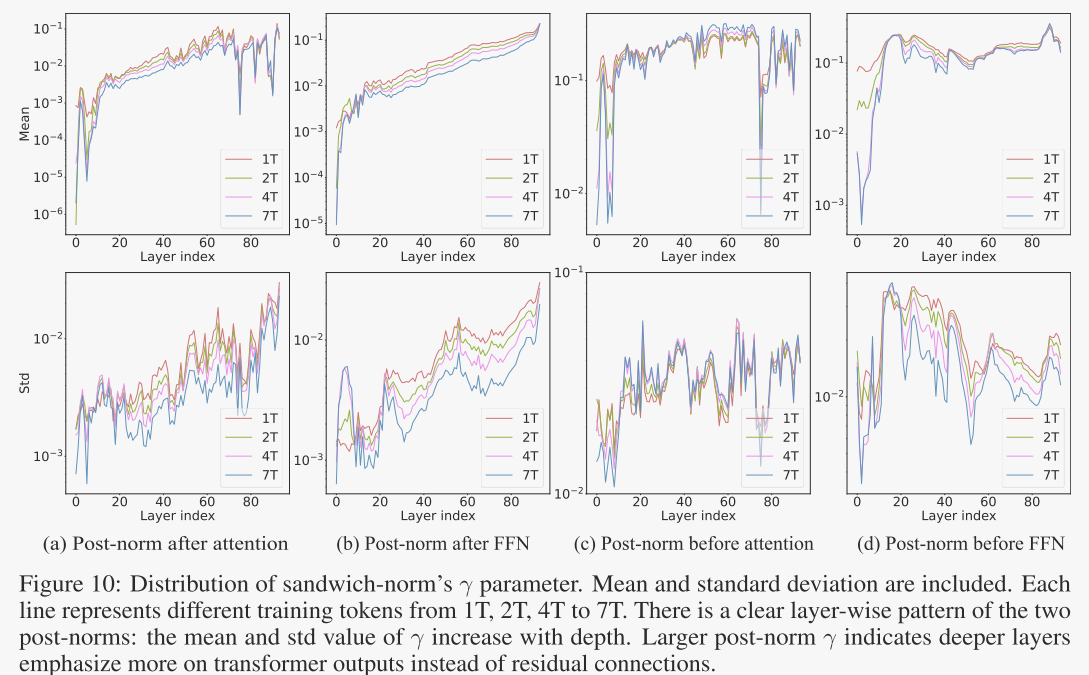
图10展示了所有夹心归一化层中缩放参数 γ 的分布,揭示了几个关键观察结果:
-
所有四个层归一化 γ 参数:在训练过程中,这些参数的均值和标准差均呈下降趋势,这与权重衰减的效果一致。
-
后归一化 γ 值:表现出层依赖的模式。后归一化 γ 的标准差随着层深度的增加显著增加。
-
预归一化 γ:在各层中保持相对恒定的标准差。
这种模式表明了一个有趣的模型行为:浅层主要依赖残差连接,而随着层深度的增加,模型逐渐强调Transformer层的输出,因为缩放因子 γ 的大小在增长。
-
-
总结
盘古Ultra是由华为推出的一款拥有1350亿参数的超大稠密语言基础模型,基于昇腾NPU进行训练。该模型针对大规模深度模型训练中的稳定性问题,提出了深度缩放夹心归一化(Depth-scaled Sandwich-Norm)技术。这一技术有效消除了训练过程中的损失峰值,确保了训练的稳定性。
盘古Ultra在13.2万亿高质量标记上进行了预训练,并通过监督微调(SFT)和强化学习(RL)进一步增强了推理能力。在8192个昇腾NPU的大规模集群上,该模型实现了超过50%的算力利用率(MFU),展现了昇腾NPU在训练超大模型上的高效性。
在多个基准测试中,盘古Ultra不仅超越了Llama 405B和Mistral Large 2等先进的稠密LLM,甚至在某些指标上与参数更多的稀疏模型DeepSeek-R1相媲美。这表明了盘古Ultra在架构和系统优化方面的有效性,为未来可扩展和高效的LLM训练铺平了道路。
感谢你抽出宝贵的时间来看我的内容。如果你觉得这里有一些对你有用的信息,或者让你感到温暖、开心,希望你能给我一个小小的鼓励,点个赞、收藏起来,也欢迎关注我。我会继续努力,为你带来更多有价值的东西,让我们一起成长,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









