







SOME INSIGHTS
定义
一种新的神经网络结构,可以对图形结构数据进行操作,使用隐藏的自我注意层来解决以前基于图形卷积或其近似的方法的缺点。
思想
通过关注其邻居,遵循自我关注策略,计算图中每个节点的隐藏表示。
出现的原因
解决GNN聚合邻居节点的时候没有考虑到不同的邻居节点重要性不同的问题
优化
借鉴了Transformer的idea
引入masked self-attention机制
允许(隐式地)为同一个邻域的节点分配不同的重要性
多头注意力机制
自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐特征表示。
优点
通过叠加层获取邻域特征,可以为邻域中的不同节点指定不同的重要性,也就是注意力系数,而不需要昂贵的矩阵运算。
适用于归纳式学习和直推式问题
直推式
在模型训练之初,就已经了解得训练集和测试集,训练之时我们不知道测试集的真实标签,但可以从其特征分布中学到些额外的信息(如分布聚集性),从而带来模型效果上的增益。只要有新的样本进来,模型就得重新训练。
归纳式
基于训练集,我们构建并训练模型,而后将其应用于测试集的预测任务中,训练集与测试集之间是相斥的,即测试集中的任何信息是没有在训练集中出现过的。即模型本身具备一定的通用性和泛化能力。
该操作是高效的,因为它可以跨节点-邻居对进行并行化;
自注意力机制的
缺陷
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,
解决
多头注意力机制
理论实现
输入的图,一个graph attention layer
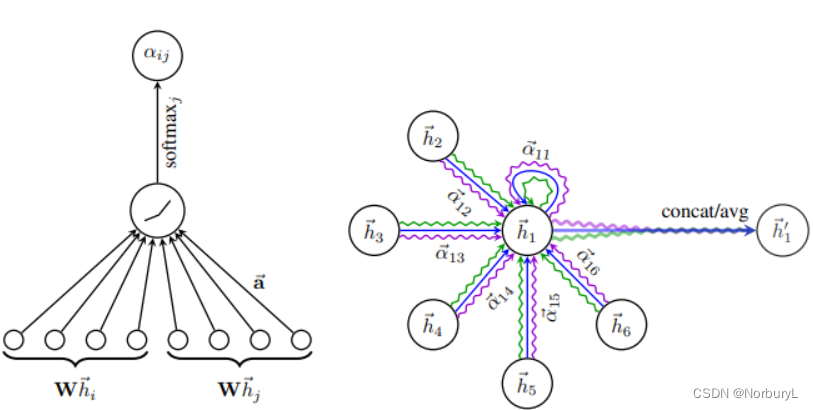
节点特征集
h
=
{
h
1
⃗
,
h
2
⃗
,
.
.
.
,
h
N
⃗
}
,
h
i
⃗
∈
R
F
h = \{ \vec{h_1},\vec{h_2}, . . . ,\vec{h_N} \},\vec{h_i} ∈ R^F
h={h1,h2,...,hN},hi∈RF
节点
j
j
j对节点
i
i
i的重要性
e
i
j
=
a
(
W
h
i
⃗
,
W
h
j
⃗
)
(
1
)
e_{ij} = a(W\vec{h_i},W\vec{h_j}) \ (1)
eij=a(Whi,Whj) (1)
α
\alpha
α是一个单层前馈神经网络,计算过程如下(注意权重矩阵
W
W
W对于所有的节点是共享的):
α
i
j
=
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
⃗
T
[
W
h
⃗
i
∣
∣
W
h
⃗
j
]
)
)
∑
k
∈
N
i
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
⃗
T
[
W
h
⃗
i
∣
∣
W
h
⃗
k
]
)
)
(
3
)
\alpha_{ij} = \frac{ exp(LeakyReLU(\vec{a}^T[W\vec{h}_i || W\vec{h}_j]) )} {\sum_{k \in N_i} exp(LeakyReLU(\vec{a}^T[W\vec{h}_i || W\vec{h}_k]))} \ (3)
αij=∑k∈Niexp(LeakyReLU(aT[Whi∣∣Whk]))exp(LeakyReLU(aT[Whi∣∣Whj])) (3)
∥ \| ∥ 表示拼接
i i i 表示当前节点, j j j表示其邻居节点集合(包含其本身)
a ⃗ T \vec{a}^T aT表示一个 2 ∗ F 2*F 2∗F维度的向量
W W W 的作用仅在于将映射特征到另一个维度
W是权重。开始的初始化权重是随机产生的,之后的权重是在训练中自动更新的。训练更新的权重一般而言是看不到的,
某个节点聚合其邻居节点信息的新的表示,计算过程如下:
h
′
⃗
i
=
σ
(
∑
j
∈
N
i
α
i
j
W
h
⃗
j
)
.
(
4
)
\vec{h'}_i = σ(\sum_{j∈N_i}α_{ij}W\vec{h}_j). (4)
h′i=σ(j∈Ni∑αijWhj).(4)
优化 多注意力机制
定义
在计算结点i和结点j的Attention系数,不仅仅考虑一次Attention系数,而是计算多次Attention,
通过多次计算,来更好的学习结点j和结点i的相关性
提高模型的拟合能力,引入了多头的self-attention机制,即同时使用多个 W k W^k Wk计算self-attention,
对于Multi-Head Attention,作者给出两个方法,然后将计算的结果合并(连接或者求和):
h
′
⃗
i
=
∥
l
=
1
k
σ
(
∑
j
∈
N
i
α
i
j
K
W
K
h
⃗
j
)
.
(
5
)
(
其
他
层
)
h
′
⃗
i
=
σ
(
1
K
∑
k
=
1
K
∑
j
∈
N
i
α
i
j
K
W
K
h
⃗
j
)
.
(
6
)
(
最
后
一
层
)
\vec{h'}_i = \|^{k}_{l=1} σ(\sum_{j∈N_i}α^K_{ij}W^K\vec{h}_j). (5) \\ (其他层)\\ \vec{h'}_i = σ(\frac{1}{K} \sum^K_{k=1} \sum_{j∈N_i}α^K_{ij}W^K\vec{h}_j). (6)\\ (最后一层)
h′i=∥l=1kσ(j∈Ni∑αijKWKhj).(5)(其他层)h′i=σ(K1k=1∑Kj∈Ni∑αijKWKhj).(6)(最后一层)
∥
\|
∥表示拼接,
a
i
j
k
a^k_{ij}
aijk是由第k个注意机制(
a
k
a^k
ak)计算的归一化注意系数,
W
k
W^k
Wk是相应的输入线性变换的权重矩阵。
在此设置中,最终返回的输出
h
′
h'
h′将包含每个节点的
K
F
′
KF'
KF′功能(而不是
F
′
F'
F′)。
实际使用

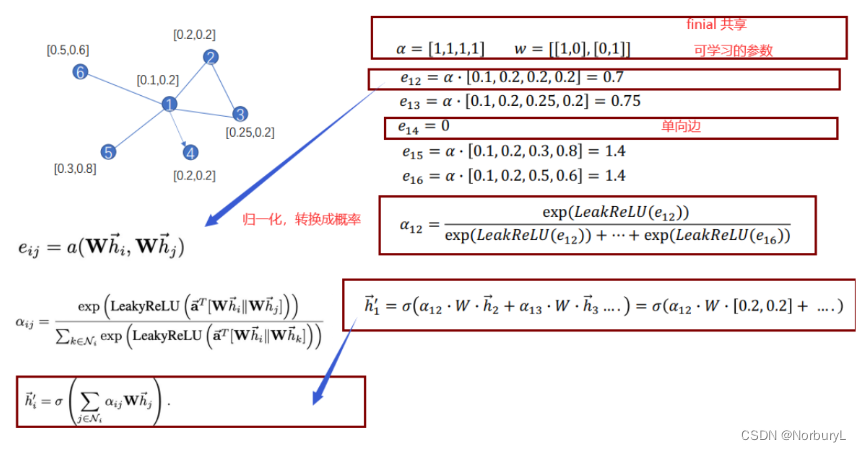
e
x
p
exp
exp是高等数学里以自然常数e为底的指数函数。 exp (x)表示的是e的x次方,x可以是一个函数。

















 3129
3129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









