









有一个20个问题的游戏,参与有游戏的一方在脑海里想某个事物,其他参与者向他提问,只允许20个问题,答案只能回答对或错。问问题的人通过推断分解,逐步缩小范围。决策树的原理将和这个游戏类似。
决策树
处理数据时,先计算数据的不一致性,然后寻找最优方案划分数据集。直到数据集所有数据属于同一个分类。使用matplotlib注解功能,将存储树转化为容易理解的图形。
信息增益和决策树基础
熵的定义:
H(p)=−∑nip(xi)∗log2(p(xi))
条件熵:
H(Y|X)=∑ni=1piH(Y|X=xi)
信息增益:
g(D,A)=H(D)−H(D|A)
具体实验和结果
实验构造了决策树分类器,并用matplotlib进行了注解,最后使用决策树预测隐形眼镜类型:
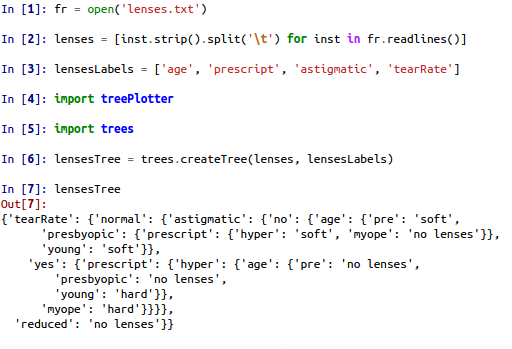
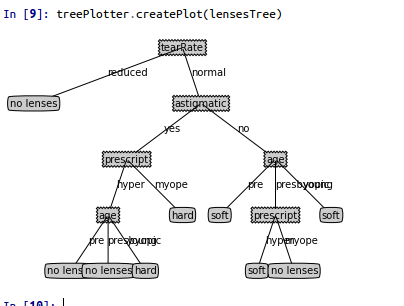
tree.py
#! /usr/bin/env python
# coding=utf-8
from math import log
#计算香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCount = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCount.keys():
labelCount[currentLabel] = 0
labelCount[currentLabel] += 1
shanonEnt = 0.0
for key in labelCount:
prob = float(labelCount[key])/numEntries
shanonEnt -= prob*log(prob,2)
return shanonEnt
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
#划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [ example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i , value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
import operator
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#创建树的函数代码
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def classify(inputTree, featLabels, testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
def stroeTree(inputTree, filename):
import pickle
fw = open(filename, 'w')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)treePlotter.py
#! /usr/bin/env python
# coding=utf-8
from math import log
#计算香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCount = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCount.keys():
labelCount[currentLabel] = 0
labelCount[currentLabel] += 1
shanonEnt = 0.0
for key in labelCount:
prob = float(labelCount[key])/numEntries
shanonEnt -= prob*log(prob,2)
return shanonEnt
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
#划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [ example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i , value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
import operator
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#创建树的函数代码
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def classify(inputTree, featLabels, testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
def stroeTree(inputTree, filename):
import pickle
fw = open(filename, 'w')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









