







MapReduce是分布式计算编程模型。【就是每个人的业务都可用】。只要我实现具体的业务逻辑即可,底层的细节不需要我关心。Google在2004年提出了这种模型,非常简单即可实现分布式计算模型。
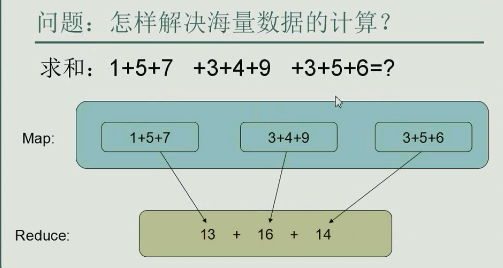
 面试题:我有一个1G的文件,有许多数,用空格分隔,机器的内存只有1M 我怎样将这样的数据计算出来?
面试题:我有一个1G的文件,有许多数,用空格分隔,机器的内存只有1M 我怎样将这样的数据计算出来?
方法:我把文件切分成1024分,每份1M,每次先把1M放在内存里,然后把计算结果放在磁盘,第二份加载到内存。。。。。然后1024次之后,再把1024个结果分别放在磁盘里。再相加
同理,我们的任务不是“串行执行”,而是“并行执行”
map阶段:把任务切分成一个一个小任务,然后交给每一台机器来计算。得到中间结果
reduce阶段:对中间结果汇总。
弄成一个计算模型就难了。【就像把程序正常写出来很简单,要把程序写的非常灵活,有容错性,但是如果出现各种各样的问题,怎么处理——hadoop一旦一台机器出现问题,要把计算转到其他机器上。】

 翻墙有软件,浏览外国网站和前沿文献用。
翻墙有软件,浏览外国网站和前沿文献用。
, hadoop1.0之前
jobtraker 在Hadoop2.0后叫RM(resource manager)【他们俩的实现机制已经完全变化了】:资源分配——决定哪台机器上运行多少map和reduce。监测各个项目的进度——大boss
tasktraker在hadoop2.0后叫NM(node manager):也跟踪一些进度——小组长,下面还有一些子进程

hadoop2.0
一个客户端提交mapreduce任务,首先将计算的数据上传到HDFS里,然后还有一个打好的jar包,通过一定的命令提交mapreduce作业,提交到一定集群之后,集群进行资源的分配,然后启动任务来执行计算逻辑。
提交作业的流程:我【客户端client】有个jar包(比如Wordcount,大约几M),提交到集群——提交给resource manager【它主要功能不是发jar包,而是资源分配,因此不能让它去把客户端client的jar包发给各个NM,因此,把jar包提交给RM并不好】,小弟去领jar包,(心跳机制)小弟隔一段时间去找老大,去领jar包,领任务,看有没有活可干)然后NM去hdfs那里领数据,然后mapreduce完再写还给hdfs。
NM从hdfs读数据,经过map和reduce结果输出到hdfs,最终结果输入输出都在hdfs
 问题:jar包到底提交给谁??
问题:jar包到底提交给谁??
流程:client把jar包提交到hdfs中,小弟可以去hdfs中下载jar包,客户端client向RM提交任务的描述信息(任务名字,jar包在什么位置等等),RM得到任务描述信息而不是jar包本身,之后,NM去领任务的描述信息息,然后去hdfs里下载jar包,之后启动个任务执行该程序。
jobtracker负责资源分配(分配多少个map,多少个reduce)和监控进程(一个进程坏掉了,要重新分配)
hadoop1.0
数据上传到hdfs之后,先把他进行物理的切分,切分成block块,然后把打任务切分成小任务,每个小任务交给一个Mapper来执行【这样可以达到并行计算】,Mapper计算完成之后把结果【Mapper的输出作为Reducer的输入】,Reducer计算完成后将结果输出到hdfs中。

hadoop2.0
实现作业的流程:【这张图非常重要,闭眼能说清楚】
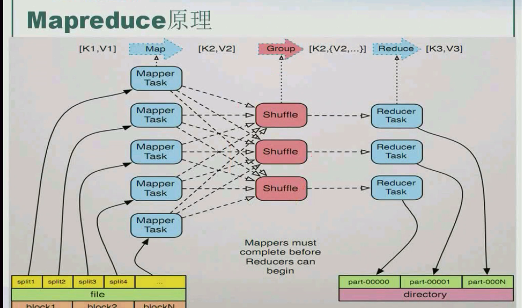
数据有可能很大,所以需要首先将文件上传到hdfs,然后被切分为很多块,默认情况下块大小128M,【文件是被物理切分,文件真变成一块一块】(1G文件切分成8块),然后运行Mapreduce,然后Mapreduce会把这个很大的任务切分成多个小任务【逻辑切分,在块的基础之上打标记】,每个小任务交给一个Map来计算(map和reduce都是以key、value的形式存在)。map计算完的数据给reducer【其实是reducer来取的】,产生新的key、value,再将新的key,value输回到hdfs中
shuffle非常重要
map的输入输出起个小名:
[K1,V1]表示map的输入,[K2,V2]既可以表示map的输出,也可以表示reduce的输入,[K3,V3]表示reduce的输出
前一段在hdfs里是物理切分(真的把大文件切成一个个128M的小块儿了),后一段map阶段是逻辑切分(挨个进行map)















 4113
4113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









