






《LIMA: Less Is More for Alignment》
paper: https://arxiv.org/abs/2305.11206

Meta在2023年5月发布了论文《LIMA: Less Is More for Alignment》,基于LLaMa-65B微调了大模型LIMA,号称只用了1000个精心策划的问题和答复进行微调,就达到了非常好的效果。
大型语言模型的训练分为两个阶段:
1. 无监督预训练,从原始文本中学习通用表示;
2. 大规模的指令调整和强化学习,以更好地适应终端任务和用户偏好。
作者用1000条挑选的指令数据微调的LIMA模型,期间没用任何强化学习或人类偏好模型,LIMA就表现出了极强的性能,它能从训练数据中只有少量的样本中学习到特定的响应格式,包括从规划旅行行程到推测历史等复杂任务。此外,该模型能泛化到未出现在训练集中的新任务。
如下图所示,在评估中,LIMA的答复有43%等同于或优于GPT-4,有58%等同于或优于Bard,有65%等同于或优于DaVinci003。

图 1 显示了人类偏好评估结果,图 2 显示了 GPT-4 偏好评估结果。
该研究第一个观察结果是,尽管使用 52 倍的数据进行训练,Alpaca 65B 输出的结果往往不如 LIMA,而使用高级对齐方法 RLHF 训练的 DaVinci003 也是如此。
虽然 Claude 和 GPT-4 通常比 LIMA 表现更好,但在很多情况下 LIMA 确实产生了更好的回答。值得注意的是,即使是 GPT-4 也有 19% 的情况更喜欢 LIMA 的输出。
评估表明,大语言模型中几乎所有的知识都是在预训练阶段学习的,只需要有限的指令微调数据就可以使得模型产生高质量的输出。
为什么「Less More」?
作者通过消融实验探讨了训练数据的多样性、质量和数量的影响。他们观察到,对于对齐的目的,扩大输入多样性和输出质量有可衡量的积极影响,仅仅扩大数量则可能不会有。
多样性
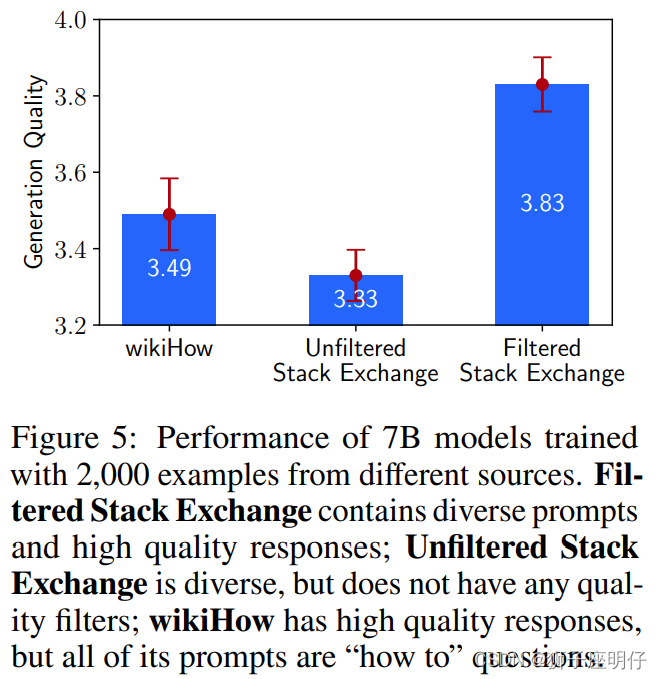
为了测试prompt多样性的效果,同时控制质量和数量,研究者比较了经过质量过滤的Stack Exchange数据和wikiHow数据的训练效果,前者有异质的prompt,后者则多是同质的prompt。他们从每个来源中抽出2000个训练样本,如上图所示,更多样化的Stack Exchange数据产生了明显更好的性能。
质量
为了测试回答质量的影响,研究者从Stack Exchange中抽取了2000个样本,没有经过任何质量或风格的过滤,并将在这个数据集上训练的模型与在过滤过的数据集上训练的模型进行比较。如图5所示,在经过过滤和未经过滤的数据源上训练的模型之间有0.5分的显著差异。
数量
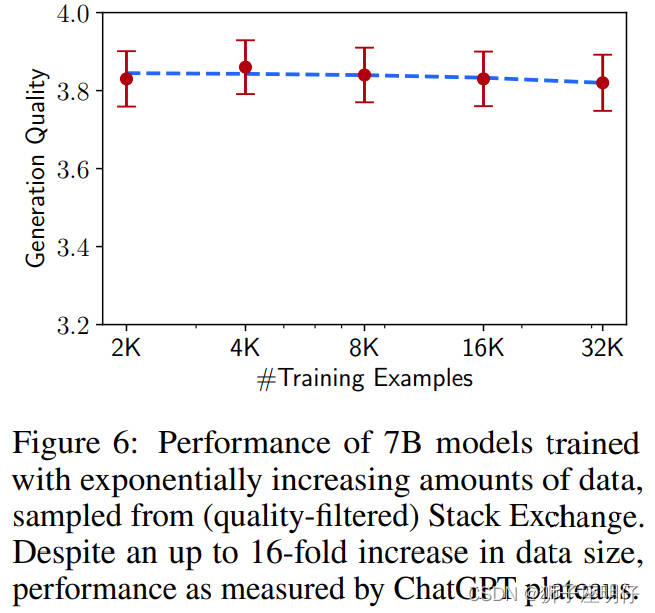
增加样本的数量是机器学习中提高性能的常用方法。为了测试它的影响,研究者从Stack Exchange中抽取了指数级增加的训练集。如下图所示,训练集规模的翻倍并没有改善回答质量。这个结果表明,对齐不一定只受制于训练样本的数量,还与prompt多样性有关。
总结
在 1000 个精心策划的样本上对一个强大的预训练语言模型(LLaMa-65B)进行微调,可以在广泛的prompt中产生显著的、有竞争力的结果。
然而,这种方法也有局限性:首先,构建这样的样本所付出的脑力劳动是巨大的,而且很难扩大规模。其次,LIMA 并不像产品级模型那样鲁棒,虽然 LIMA 通常会产生良好的反应,但对抗性prompt可能会生成错误的答复。
尽管如此,这项工作表明,用简单的方法来解决复杂的对齐问题是有潜力的。
《QLORA: Efficient Finetuning of Quantized LLMs》
论文:https://arxiv.org/pdf/2305.14314.pdf
代码:GitHub - artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs

Washington大学2023年5月新提出一种高效的微调方法QLoRA,通过降低显存使用,实现在单个48GB GPU上对65B参数的大模型进行微调,只需微调12个小时就可以达到97%的ChatGPT水平。同时只用int4就可以保持fp16精度的效果。
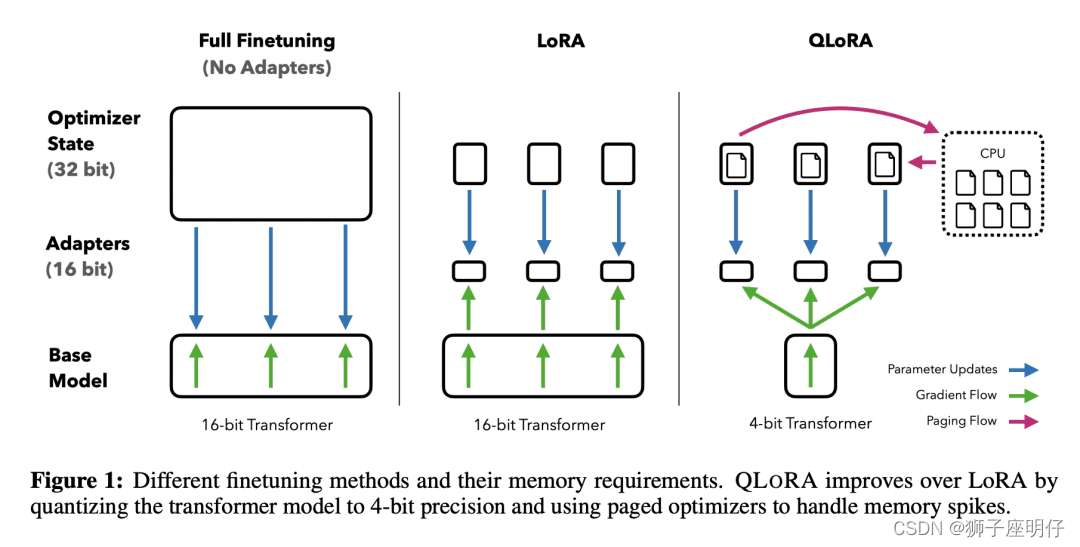
- 动机:希望降低显存占用,实现在单个48GB GPU上对65B参数模型进行微调,并保留fp16推理性能。
- 方法:QLoRA通过int4量化预训练模型,并用LoRA,实现了通过少量显存消耗来保持性能的高效微调方法。
- 优势:QLoRA引入了多项创新,旨在在不牺牲性能的情况下减少显存占用,包括4bit的NormalFloat数据类型(NF4)、双重量化(Double Quantization)和分页优化器(Paged Optimizers)等,同时保留完整的fp16的推理性能。
下面解释下QLoRA的四项创新工作:
- 4位量化(NF4):想象一下,你有一盒16种不同颜色的蜡笔。但你发现只用4种颜色就能画出几乎相同的画面。这就是量化所做的事情。它减少了模型用来表示其知识的不同“颜色”(或数字)的数量,从而节省了大量空间。在这种情况下,他们使用了一种特殊的4位量化,这意味着他们只使用了16个不同的数字,而不是模型通常可能使用的成千上万个数字。
- LoRA:这是一种在不需要调整模型所有部分的情况下改变模型知识的方法。想象一下,你有一个巨大、复杂的乐高结构,你想改变它。与其拆掉整个结构,你只需在此处和那处添加或更改几个部分。这就是 LoRA 的作用。它允许研究人员在不使用大量显存的情况下微调模型。
- 双重量化(Double Quantization):这是节省显存的另一个技巧。就好像你意识到可以用只有2个符号来表示你的4种蜡笔颜色,这样你就能节省更多的空间。
- 分页优化器(Paged Optimizers):这是处理模型一次性需要大量显存的情况的方法,就好像你有一个小桌子,但有时你需要做一个大项目。你不需要换个更大的桌子,而是一次清理并使用桌子的小部分区域。显存跟内存做交换来处理需要大显存的模型。

QLoRA通过NF4的int4量化,并用LoRA训练,得到了Guanaco-65B模型,其性能优于先前公开发布的所有模型,达到了Vicuna基准测试的99.3%的性能水平,而只需要在单个GPU上进行24小时的微调。
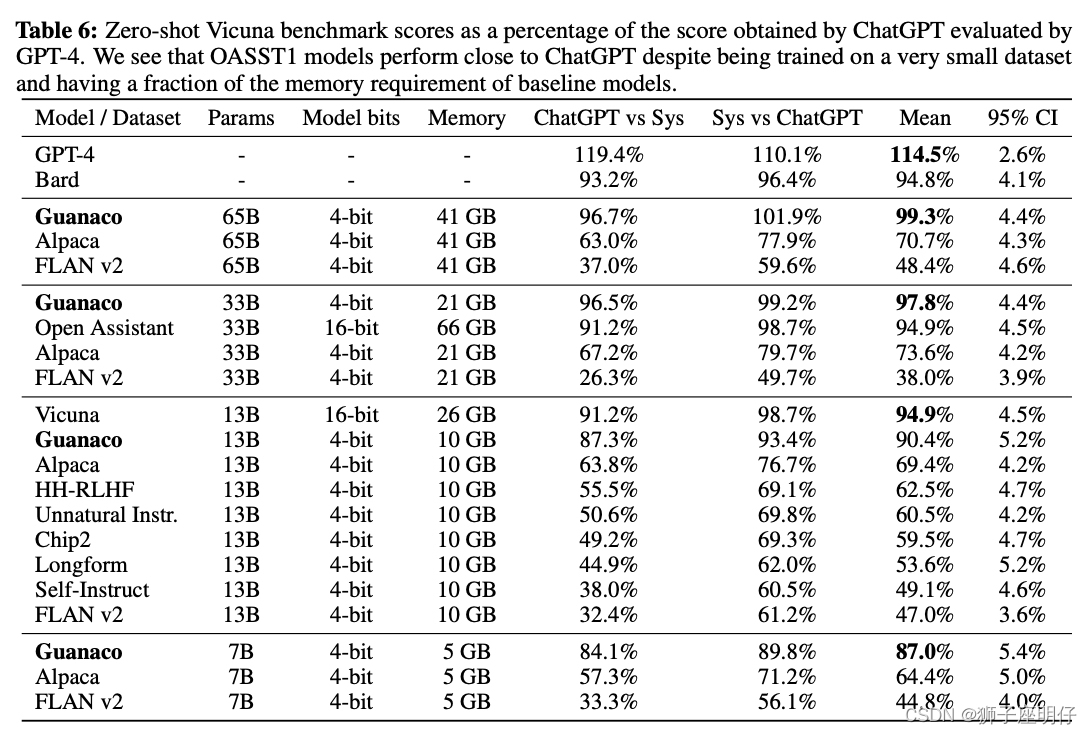
作者使用QLoRA微调了超过1,000个模型,得到如下结论:
- 数据质量远比数据集大小重要,这一点也跟上篇LIMA论文的结论一致,使用Open Assistant的9000条数据调优12小时即可达到很好的效果,相比FLAN v2使用了超过100万条指令数据,finetune可能并不需要非常多的数据集,少部分高质量的数据就能带来较好结果。
- 对于给定的任务,数据集的适用性比大小更重要。指令微调数据只使用与指令相关的任务,在Chatbot上性能并不佳。而Chatbot更适合用Open Assistant数据集去进行finetune,9k样本的OASST1在聊天机器人性能方面优于450k指令微调样本数据集;指令类数据集的微调更能提升大模型的推理能力,并不是为聊天而生的。
- 默认的LoRA超参数不足以实现大模型的最佳性能。研究发现,使用的LoRA adapter数量是一个关键的超参数,并且需要在所有线性层上使用LoRA才能匹配全参模型微调的性能。
- QLoRA使用NF4可以复现fp16全参微调和fp16的LoRA微调性能,而且NF4在量化精度方面优于FP4。
QLoRA的出现确实能给人带来一些新的思考,不管是finetune还是自己部署大模型之后都会变得更加容易。每个人都可以快速利用自己的私有数据进行finetune,同时又能轻松的部署推理大模型。后面我会利用QLoRA的方式来构建私有化QA Bot,看看在中文推理上是否也能取得不错的效果。
















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









