







目录
前言
在当今这个数据驱动的时代,机器学习和深度学习已经成为解决复杂问题的重要工具。它们不仅在科学研究中扮演着关键角色,而且在商业智能、医疗诊断、自动驾驶车辆、个性化推荐系统等众多领域都有着广泛的应用。随着技术的进步,这些算法变得越来越高效和易于使用,使得更多的人能够利用它们来解决实际问题。
逻辑回归作为一种经典的机器学习算法,虽然名字中带有“回归”二字,但实际上它是一种广泛应用于二分类问题的算法。它的原理简单,易于实现,并且在许多实际场景中表现出色。逻辑回归通过使用Sigmoid函数将线性回归的输出映射到0和1之间,从而得到一个概率值,这个概率值表示样本属于某个特定类别的可能性。
一、logistic回归原理
逻辑回归是一种广泛使用的统计方法,用于处理二分类问题。它的基本原理是使用逻辑函数(通常是Sigmoid函数)来预测一个样本属于某个类别的概率。
Sigmoid函数的数学表达式是:
其中,( z ) 是输入特征的线性组合,即:
这里的 是权重(weights),
是特征值,
是偏置项(bias)。
逻辑回归模型的输出是一个概率值,表示样本属于正类的概率。如果输出概率大于0.5,则预测样本属于正类;如果小于0.5,则预测样本属于负类。
在代码中,逻辑回归的实现步骤如下:
1.初始化权重和偏置为0。
2.通过梯度下降算法更新权重和偏置,以最小化损失函数。损失函数通常是对数损失,它衡量的是模型预测概率与真实标签之间的差异。
3.重复步骤2,直到模型收敛或达到预设的迭代次数。
4.使用训练好的模型进行预测,计算每个样本属于正类的概率。
梯度下降算法通过以下方式更新权重和偏置:
其中,是学习率(lr),
是真实标签,
是模型预测的概率。
通过这种方式,逻辑回归模型能够学习到不同特征对样本分类的影响,并做出准确的预测。
二、使用步骤
1.导入所需的库:
import numpy as np
import matplotlib.pyplot as plt
这两行代码导入了NumPy和Matplotlib.pyplot库,NumPy用于数值计算,Matplotlib.pyplot用于绘图。
2.定义数据集和标签:
X = np.array([[0.180, 0.001*1], [0.100, 0.001*2],
[0.160, 0.001*3], [0.080, 0.001*4],
[0.090, 0.0018*5], [0.110, 0.001*6],
[0.120, 0.001*7], [0.170, 0.001*8],
[0.150, 0.001*9], [0.140, 0.001*10],
[0.130, 0.001*11]])
y = np.array([1, -1, 1, -1, -1, -1, -1, 1, 1, 1, -1])
这里定义了一个二维数组X,它包含了11个样本,每个样本有两个特征。y是一个一维数组,包含了11个标签,其中1表示正类,-1表示负类。
3.初始化模型参数:
n_samples, n_features = X.shape
weights = np.zeros(n_features)
bias = 0.0
lr = 0.0001
epoch = 100000
这段代码初始化了权重向量weights为全零,偏置项bias为0.0,学习率lr为0.0001,迭代次数epoch为100000。
4.梯度下降算法:
for _ in range(epoch):
mis_flag = False
for i in range(n_samples):
y_pred = np.dot(weights, X[i]) + bias
if y_pred * y[i] <= 0:
weights += lr * y[i] * X[i]
bias += lr * y[i]
mis_flag = True
if not mis_flag:
break
这段代码使用梯度下降算法来更新权重和偏置。它遍历了100000次(epoch),对于每个样本,如果预测值和真实标签的乘积小于或等于0,说明预测错误,就更新权重和偏置。如果一次迭代中没有错误预测,则提前终止训练。
5.预测:
y_pred = []
for i in range(n_samples):
pred = np.dot(weights, X[i]) + bias
if pred >= 0:
y_pred.append(1)
else:
y_pred.append(-1)
使用训练好的权重和偏置进行预测,并将预测结果存储在y_pred列表中。
6.打印真实标签和预测标签:
print(y)
print(y_pred)
这两行代码分别打印出真实标签和预测标签。
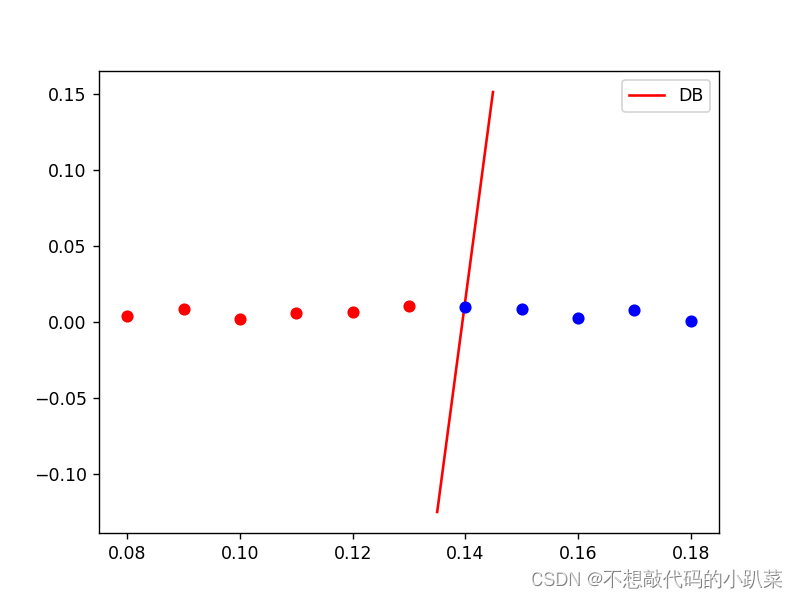
7.绘制决策边界和散点图:
x1 = np.arange(0.135, 0.145, 0.0001)
x2 = (-weights[0] * x1 - bias) / weights[1]
plt.plot(x1, x2, 'r', label='DB')
for ii in range(11):
if y[ii] == 1:
plt.plot(X[ii][0], X[ii][1], 'bo')
else:
plt.plot(X[ii][0], X[ii][1], 'ro')
plt.legend()
plt.show()
最后,使用Matplotlib绘制了决策边界(红色线条)和样本点(蓝色圆圈表示正类,红色圆圈表示负类)。
三、运行结果

总结
本文通过一个Python代码示例,深入探讨了逻辑回归的实现过程。代码首先初始化模型参数,然后通过梯度下降算法不断迭代,优化权重和偏置,以最小化损失函数。在迭代过程中,代码会检查预测是否正确,并在错误发生时更新模型参数。
通过实际编写和调试代码,我们不仅理解了逻辑回归的数学原理,还掌握了使用Python进行机器学习编程的技巧。此外,我们还利用Matplotlib库绘制了决策边界和样本点,使得模型的预测结果更加直观。
















 4418
4418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











