







1、神策概述
这里的打点服务,是用于替代神策的数据埋点服务,然后仍然使用神策的数据分析功能。
所以,需要先了解神策数据的情况:
神策数据提供数据埋点和数据分析的全套的解决方案。
1、通过神策提供的各个端的客户端SDK来实时收集数据到神策服务端。
2、结合具体的业务需求,使用抽象的各个数据分析模型,生成所关心的核心指标供用户进行查询。
1.1、神策的数据模型简介
在神策分析中,使用“事件模型(Event 模型)”来描述用户在产品上的各种行为,这也是神策分析所有的接口和功能设计的核心依据。
事件模型包括事件(Event)和用户(User)两个核心实体,在神策分析中,分别提供了接口供使用者上传和修改这两类相应的数据,在使用产品的各个功能时,这两类数据也可以分别或者贯通起来参与具体的分析和查询。
采用神策的数据分析模型,只需要通过SDK上传一个类似下面的json即可:
{
"distinct_id": "2b0a6f51a3cd6775",
"time": 1434556935000,
"type": "track",
"event": "PageView",
"properties": {
"$ip" : "180.79.35.65",
"user_agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.)",
"page_name" : "网站首页",
"url" : "www.demo.com",
"referer" : "www.referer.com"
}
}
1.1.1、神策的Event实体
一个 Event 就是描述了:一个用户在某个时间点、某个地方,以某种方式完成了某个具体的事情。一个完整的 Event,包含如下的几个关键因素:
Who
即参与这个事件的用户是谁。在我们的数据接口中,使用 distinct_id 来设置用户的唯一 ID:对于未登录用户,这个 ID 可以是 cookie、设备 ID 等匿名 ID;对于登录用户,则建议使用后台分配的实际用户 ID。同时,我们也提供了 track_signup 这个接口,在用户注册的时候调用,用来将同一个用户注册之前的匿名 ID 和注册之后的实际 ID 贯通起来进行分析。
When
即这个事件发生的实际时间。在我们的数据接口中,使用 time 字段来记录精确到毫秒的事件发生时间。如果调用者不主动设置,则各个 SDK 会自动获取当前时间作为 time 字段的取值。
Where
即事件发生的地点。使用者可以设置 properties 中的 $ip 属性,这样系统会自动根据 ip 来解析相应的省份和城市,当然,使用者也可以根据应用的 GPS 定位结果,或者其它方式来获取地理位置信息,然后手动设置 $city 和 $province。除了 $city 和 $province 这两个预置字段以外,也可以自己设置一些其它地域相关的字段。例如,某个从事社区 O2O 的产品,可能需要关心每个小区的情况,则可以添加自定义字段“HousingEstate”;或者某个从事跨国业务的产品,需要关心不同国家的情况,则可以添加自定义字段“Country”。
How
即用户从事这个事件的方式。这个概念就比较广了,包括用户使用的设备、使用的浏览器、使用的 App 版本、操作系统版本、进入的渠道、跳转过来时的 referer 等,目前,神策分析预置了如下字段用来描述这类信息,使用者也可以根据自己的需要来增加相应的自定义字段。
- $app_version:应用版本
- $city: 城市
- $manufacturer: 设备制造商,字符串类型,如"Apple"
- $model: 设备型号,字符串类型,如"iphone6"
- $os: 操作系统,字符串类型,如"iOS"
- $os_version: 操作系统版本,字符串类型,如"8.1.1"
- $screen_height: 屏幕高度,数字类型,如1920
- $screen_width: 屏幕宽度,数字类型,如1080
- $wifi: 是否 WIFI,BOOL类型,如true
What
描述用户所做的这个事件的具体内容。在我们的数据接口中,首先是使用“event”这个事件名称,来对用户所做的内容做初步的分类。event的划分和设计也有一定的指导原则,我们会在后文详细描述。除了“event”这个至关重要的字段以外,我们并没有设置太多预置字段,而是请使用者根据每个产品以及每个事件的实际情况和分析的需求,来进行具体的设置,下面给出一些典型的例子:
- 对于一个“购买”类型的事件,则可能需要记录的字段有:商品名称、商品类型、购买数量、购买金额、 付款方式等;
- 对于一个“搜索”类型的事件,则可能需要记录的字段有:搜索关键词、搜索类型等;
- 对于一个“点击”类型的事件,则可能需要记录的字段有:点击 URL、点击 title、点击位置等;
- 对于一个“用户注册”类型的事件,则可能需要记录的字段有:注册渠道、注册邀请码等;
- 对于一个“用户投诉”类型的事件,则可能需要记录的字段有:投诉内容、投诉对象、投诉渠道、投诉方式等;
- 对于一个“申请退货”类型的事件,则可能需要记录的字段有:退货金额、退货原因、退货方式等。
1.1.2、神策的User实体
1.1.2.1、记录和搜集User Profile
每个 User 实体对应一个真实的用户,用 distinct_id 进行标识,描述用户的长期属性(也即 Profile),并且通过 distinct_id 与这个用户所从事的行为,也即 Event 进行关联。
神策分析提供了一系列 profile_xxx 类型的接口,用来对某个 user 的 Profile 进行记录和修改。
一般记录 User Profile 的场所,是用户进行注册、完善个人资料、修改个人资料等几种有限的场合,与 Event 类似,我们也强烈建议在后端记录和收集 User Profile。
应该收集哪些字段作为 User Profile,也完全取决于产品形态以及分析需求。简单来说,就是在能够拿到的那些用户属性中,哪些对于分析有帮助,则作为 Profile 进行收集。
1.1.2.2、字段记录在 Profile 还是 Event 的取舍
有些时候,我们可能会纠结,某个与用户相关的字段是应该记录在 Profile 还是记录在 Event,一个基本的原则就是,Profile 记录的是用户的基本固定不变的属性,例如性别、出生年份(请注意,记录的不是年龄而是出生年份)、注册时间、注册地域、注册渠道等。而还有一些字段,例如用户级别、设备类型、地域、是否是 Vip 等,虽然也是用户相关的字段,但是可能是会经常变化的,则应该在用户的某个 Event 发生的时候,作为 Event 的一个字段来进行记录。
1.1.3、神策的Item实体
在 Event-User 模型中,出于性能和可解释性等各方面的考虑,Event 是被设计为不可变的。从逻辑上看似乎没有问题,因为 Event 代表的是历史上已经发生过的事件,一般来说不应该需要进行更新。
但是,在实际的应用过程中,并不一定是这么理想的状态。
如,在采集和分析中会发现:
Event 实体中一些基本信息中会有许多是不断变化的
埋点采集中,发现某些 Event 在最初的阶段采集到的数据不完善。
这时,可通过 Item 实体对 Event-User 模型进行补充。
这里的所谓 Item,在严格意义上是指一个和用户行为相关联的实体,可能是一个商品、一个视频剧集、一部小说等等。Item 的应用场景有很多,下面介绍两个最常见的应用场景。
2、打点服务
这里的打点服务,主要指客户端的打点,包括web, android, iOS。
2.1、打点服务的架构
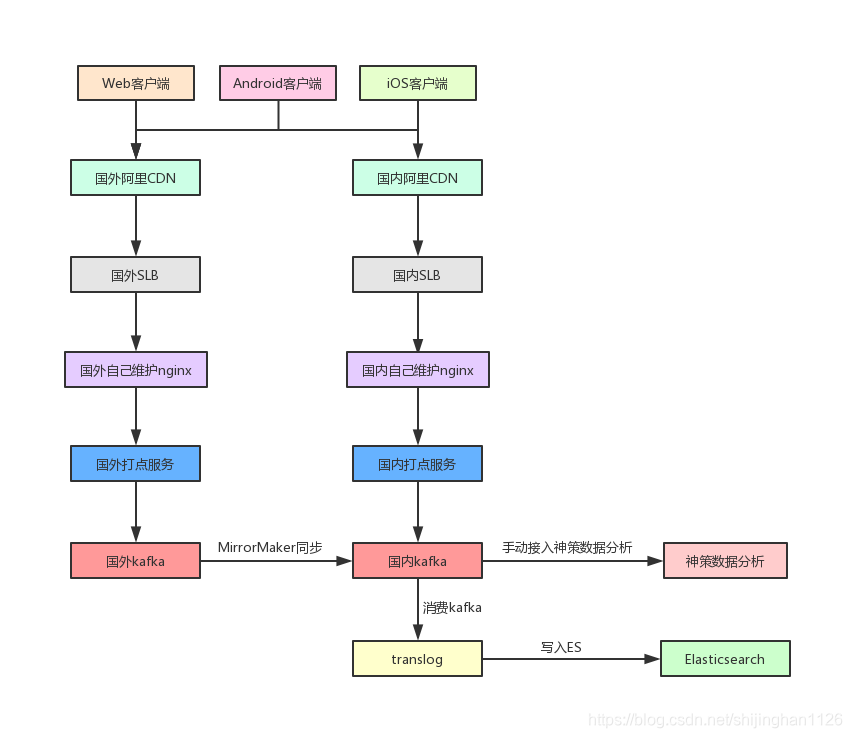
打点服务是通过Http接口,为web端和移动端做代理,把埋点写入kafka,然后接入到神策数据分析系统,业务方可查询神策数据分析系统做数据分析查询;同时也通过translog写入ES供业务方做查询。
2.2、打点服务比神策的埋点服务好在哪?
1、理论上丢点了低。(神策丢点率在7%左右)
2、接入了ES,业务方可通过ES查询。
3、通过kafka mirror maker做跨国数据专线同步,可做到全球加速。
2.3、打点服务剩余问题
1、怎样精确计算丢点率
2、增加收集日志时的过滤条件
3、链路上没有加安全防护waf、云顿等
4、Web端兼容问题:
要用我们的打点web端SDK替换掉神策的SDK,有如下的问题:
- 神策SDK有个distinct_id,也就是用户登录的user_id,匿名用户的cookie(web端)或device_id(手机端)。
- 而我们的web SDK只有device_id,无法对接user_id?【这不应该啊,如果我们么没有登录功能,那么使用神策SDK时,怎样获取的用户登录的user_id? 此外,即使没有登录功能,也可以用匿名用户的方式使用cookie或device_id】
- 手机端SDK做完了,但还没上线,不确定有什么问题。
总之,我们就模仿神策的SDK,就可以了。
2.4、打点服务OKR
1、丢点率小于1%【这个1%怎样统计?(据说神策丢点率在7%)】
2、打点延迟小于5秒【目前是多少?目前的瓶颈在哪?】
3、提升打点服务的稳定性【目前几个9?ES故障是否算在打点服务上?】

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









