






核心思想
线性回归是解决回归类问题中最常使用的模型,算法思想和基本原理源于统计分析。
在一个数据集中, X含有n个特征,X = (x1,x2 … xn),每个xi都是某次观测结果 y 下的某个维度表现出来的数值。我们将各个维度的数值进行加权求和并推导计算出最后的结果,可以用线性回归的方程式表达:
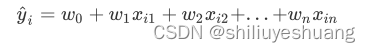
其中w0被称为截距,w1~wn被称为回归系数,有时候会使用β表示。这个式子与初中 一元一次函数 y = kx +b性质相同,将其推广到多元,可以使用矩阵表示这个方程:

模型评估与计算
模型的评估指标通常可以使用SSE,线性方程的SSE表达式:
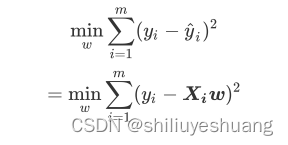
对于上述函数,可以对其求偏导算极值,推导过程在此不加以赘述,直接给出最后的结果:
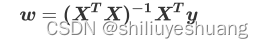
简单线性模型
有了w后,下面进行一个简单的手写:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#设置绘图样式
plt.rcParams["font.sans-serif"] = ["YouYuan"]
plt.rcParams["axes.unicode_minus"] = False
plt.style.use("seaborn")
#模拟一些数据
seed = np.random.RandomState(100)
#生成100个0-5的随机数
x = 5*seed.rand(100)
#y值加上干扰项
y = 2*x-1+seed.randn(100)
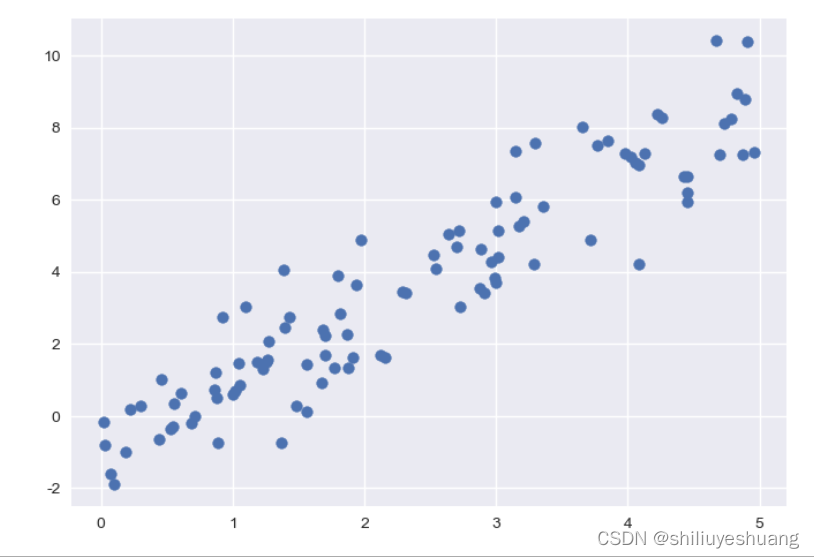
plt.scatter(x,y)
散点图:
data = pd.DataFrame({"x":x,"y":y})
def simple_linear(X,y):
#将数据集的特征dataframe转为matrix
x_matrix = np.mat(X)
#将数据集的目标dataframe转为matrix
y_matrix = np.mat(y).reshape(-1,1)
#增广矩阵,第一列全为1
x_expand_mat = np.hstack((np.ones([x_matrix.shape[0],1]),x_matrix))
#计算w
w = (x_expand_mat.T * x_expand_mat).I * x_expand_mat.T*y_matrix
#计算y的估计值
y_pred = x_expand_mat.dot(w)
#计算R²
SSE = (y_matrix-y_pred).T.dot(y_matrix-y_pred)
SST = y_matrix.var()*x_matrix.shape[0]
R2 = 1-SSE/SST
return w,R2
进行简单验证:
simple_linear(data.iloc[:,:-1],data.iloc[:,-1])
结果如下:
(matrix([[-1.01514025],
[ 1.94493042]]),
matrix([[0.87253189]]))
导入sklearn中的线性回归模型:
from sklearn.linear_model import LinearRegression
lr = LinearRegression().fit(data.iloc[:,:-1],data.iloc[:,-1])
lr.score(data.iloc[:,:-1],data.iloc[:,-1])
[lr.intercept_,lr.coef_]
结果如下:
0.8725318861670294
[-1.0151402472042217, array([1.94493042])]
比对结果,上述的手写的函数基本上给出了正确的截距、回归系数和R² 。















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









