






 本文详细介绍了如何自定义实现线性回归和岭回归,包括数学原理、代码实现以及对比sklearn内置版本。作者通过实例展示了使用梯度下降法优化参数的过程,并讨论了数据预处理中的标准化问题。
本文详细介绍了如何自定义实现线性回归和岭回归,包括数学原理、代码实现以及对比sklearn内置版本。作者通过实例展示了使用梯度下降法优化参数的过程,并讨论了数据预处理中的标准化问题。
自定义类,实现线性回归和岭回归,完成主体部分,一个字--清爽简洁。
内容:
1.简单复制粘贴下数学原理
2.代码及测试
3.思考
一、数学原理
由于数学公式太多,直接粘贴了;
图片复制自:Python手写实现线性回归(从原理到代码) - 知乎 (zhihu.com)
python机器学习手写算法系列——线性回归_python手写代码实现一元线性回归设计思想-CSDN博客

解法1.最小二乘法:
在数据量大、样本稍微有点难度下,很难算出来
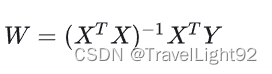
解法2:梯度下降
万物皆可迭代,梯度下降是个不错的选择

二、数据及代码
2.1 数据
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
np.set_printoptions(suppress=True)
# 导入数据
diabetes_x,diabetes_y = datasets.load_diabetes(return_X_y=True,as_frame=True)
diabetes_x自带的糖尿病数据集,其实该数据集用单纯的线性回归效果很一般。
首先我们瞄一眼sklearn中自带的线性回归的参数,对比分析下要实现什么功能:

1是否要带截距,肯定要啊!2是否复制数据 ,3是用几个核心,4是强制让所有系数都为正,看起来不是很聪明。
2.2 代码
比较简单,如下,但是悄悄埋下一个坑,后面分解:
# 避免重名
class MyLinearRegression(object):
def __init__(self, alpha=0.01, n_iters=1000,norm=False):
self.alpha = alpha # 学习率
self.n_iters = n_iters # 迭代次数
self.norm = norm # 是否标准化
self.losslist=[] # 记录损失函数变化好画图
def fit(self, x, y):
num_samples, num_features = x.shape
if self.norm:
# 标准化
x = (x-x.mean(axis=0))/x.std(axis=0)
# 初始化模型参数
self.theta = np.zeros(num_features) # 系数
self.b = 0 # 截距
for i in range(self.n_iters):
# 矩阵预算 (m,n)dot(n,1)
y_pred = np.dot(x, self.theta) + self.b
# 计算损失 (均方误差, Mean Squared Error)
loss = 1/2 * np.mean((y - y_pred) ** 2) # 乘个1/2
self.losslist.append(loss)
# 计算梯度
dw = -(1 / num_samples) * np.dot(x.T,(y - y_pred))
db = -(1 / num_samples) * np.sum(y - y_pred)
# 更新参数
self.theta -= self.alpha * dw
self.b -= self.alpha * db
def predict(self, x):
if self.norm:
x = (x-x.mean(axis=0))/x.std(axis=0)
return np.dot(x, self.theta) + self.b
def plotloss(self,title='Loss_descend'):
plt.plot(range(self.n_iters),self.losslist,color='lightblue',alpha=0.8)
plt.title(label=title)
plt.show()2.3对比分析
那我们来看看跟sklearn自带的有什么区别:
model_test = MyLinearRegression(n_iters=5000,norm=False,alpha=0.05)
model_test.fit(x_train,y_train)
y_ = model_test.predict(x_test)
from sklearn.metrics import mean_squared_error
error1 = mean_squared_error(y_test,y_)
error1
-> 3312.5459764918764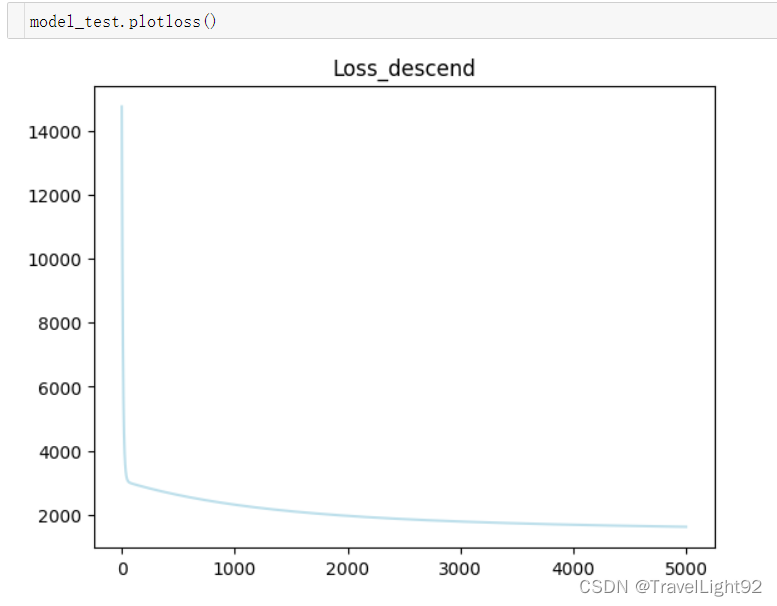
用sklearn的看看:
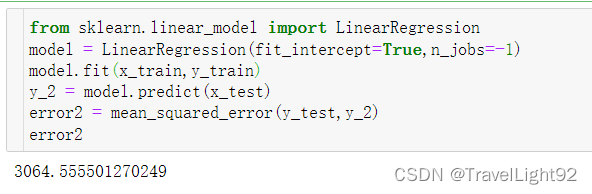
sklearn看起来要强一点,但强得不多,应该是学习率和迭代次数的区别,这个数据集用单纯的线性回归还是不行,不过自带好找的数据集并不是那么多。
画图看看:
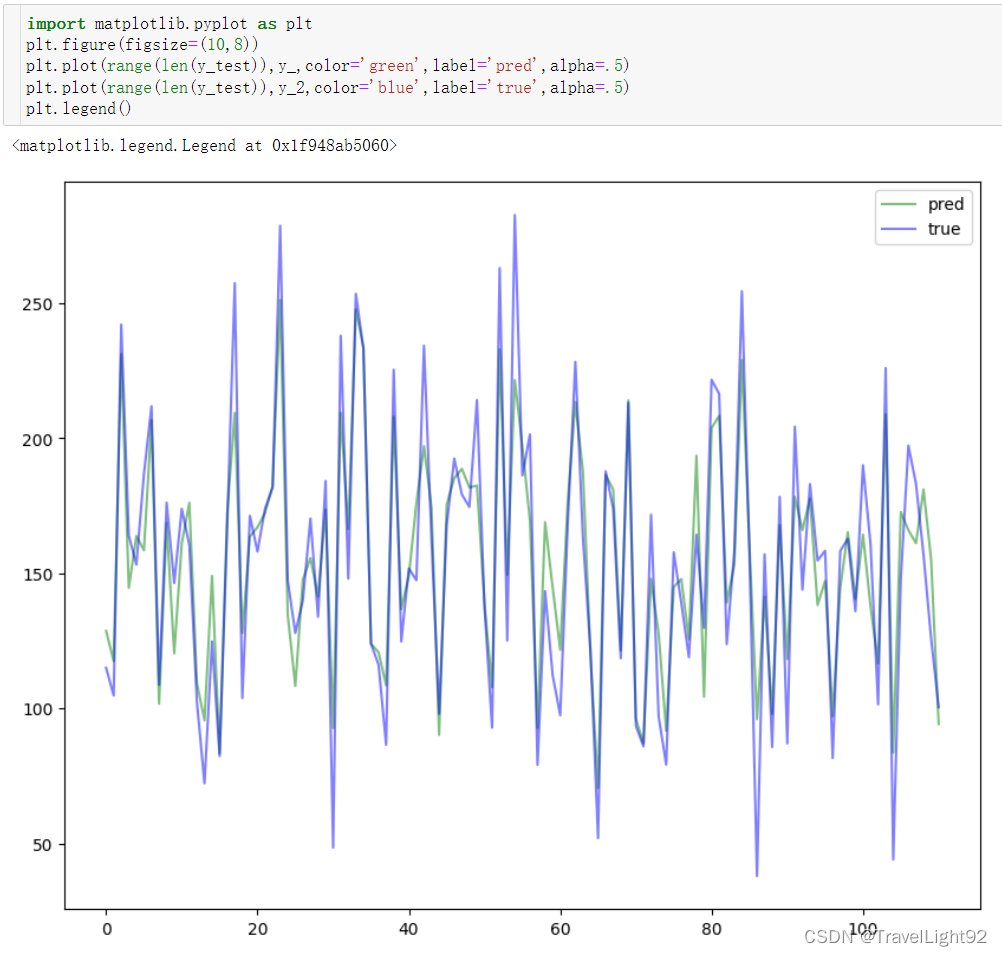
画了又没有完全画,把索引调一下:
# 将y_test从小到大排列
# 要先重塑索引
y_test_reindex= y_test.reset_index(drop=True)
y_test_sort_index = np.argsort(y_test_reindex)
# 画图
plt.plot(range(len(y_test)),y_[y_test_sort_index],color='green',label='pred',alpha=.5)
plt.plot(range(len(y_test)),y_test_reindex[y_test_sort_index],color='blue',label='true',alpha=.5)
plt.plot(range(len(y_test)),y_2[y_test_sort_index],color='orange',label='sklearn',alpha=.5)
plt.legend()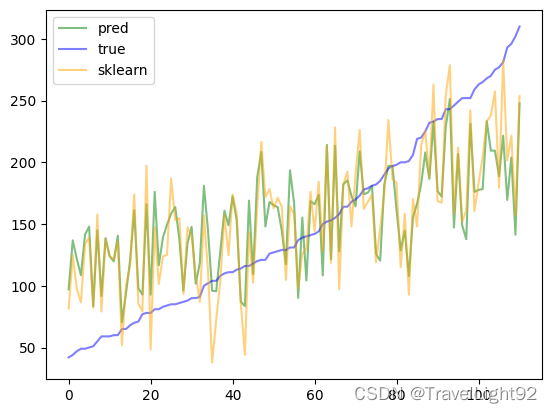
看起来好一点。
注意看代码的话,我们悄悄加入了是否归一化的选项,来看看归一化是否好点。
这个数字大到离谱,但自带的数据集,用于回归的好像就只有这一个,波士顿房价因为零元购而被正确掉了。
三、思考
要不要归一化呢?
如果要归一化,不要在算法里面搞,在数据处理阶段就搞!!!
Z-score标准化,z = x_i - mu / sigma
只有保证训练、测试是先标准化,再切分的,才有可比性。
假如在算法里面标准化,几十几百也会被弄到0附近,几千几万也会被弄到0附近,比如你一家店日活几百跟几万,差距肯定很大啊!
3.2 岭回归
顺手把岭回归也搞一下:
删掉偷偷藏下的雷--norm
也是梯度下降法,主要在损失函数和梯度计算上有区别:
其实还缺点东西,比如tolerance,不过这样讲还有solver呢,会越写越多,就到这吧
class MyRidge(object):
def __init__(self, learning_rate=0.01, n_iters=1000,lambda_=1):
self.learning_rate = learning_rate # 学习率改下避免和L1重复
self.n_iters = n_iters # 迭代次数
self.losslist=[] # 记录损失函数变化好画图
self.lambda_ = lambda_ # L2正则,加_避免重名
def fit(self, x, y):
num_samples, num_features = x.shape
# 初始化模型参数
self.theta = np.zeros(num_features) # 系数
self.b = 0 # 截距
for i in range(self.n_iters):
# 矩阵预算 (m,n)dot(n,1)
y_pred = np.dot(x, self.theta) + self.b
# 都乘1/2比较方便
loss = 1/2 * np.mean((y - y_pred) ** 2) +1/2*self.lambda_*np.sum(self.theta**2)
self.losslist.append(loss)
# 系数的梯度&更新
gradient = np.dot(x.T,(y_pred-y))+self.lambda_*self.theta
gradient = gradient/num_samples
self.theta -= self.learning_rate*gradient
# 截距偏导跟正则项没关系
db = -(1 / num_samples) * np.sum(y - y_pred)
self.b -= self.learning_rate * db
def predict(self, x):
return np.dot(x, self.theta) + self.b
def plotloss(self,title='Loss_descend'):
plt.plot(range(self.n_iters),self.losslist,color='lightblue',alpha=0.8)
plt.title(label=title)
plt.show()因为代码比较简单,所以直接全部重写了,实际上聪明一点应该继承的写法:
# 使用继承的方法
class MyRidge(MyLinearRegression):
def __init__(self,alpha=0.05,n_iters=100,lambda_=1): # 必须附上默认值
super().__init__(alpha, n_iters) # 调用父类的构造方法
self.lambda_ = lambda_ #
def fit(self, x, y):
num_samples, num_features = x.shape
self.theta = np.zeros(num_features) #
self.b = 0
for i in range(self.n_iters):
y_pred = np.dot(x, self.theta) + self.b
loss = 1/2 * np.mean((y - y_pred) ** 2) +1/2*self.lambda_*np.sum(self.theta**2)
self.losslist.append(loss)
gradient = np.dot(x.T,(y_pred-y))+self.lambda_*self.theta
gradient = gradient/num_samples
self.theta -= self.alpha*gradient
db = -(1 / num_samples) * np.sum(y - y_pred)
self.b -= self.alpha * db
# 这样少写下面两个方法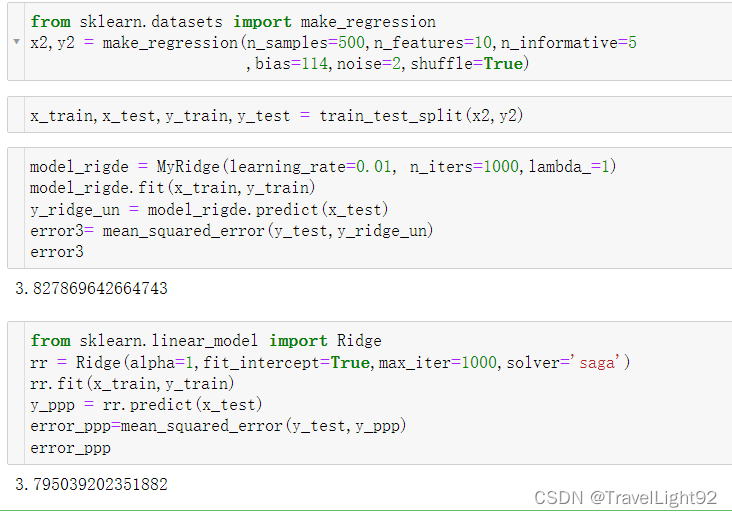
结果差不多
















 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









