









FiLM:一种通用的视觉推理条件层方法
对于深度学习研究者来说,Transformer 结构早已是耳熟能详的明星模型,其在自然语言处理和计算机视觉领域的成功让人惊叹。然而,在视觉推理(Visual Reasoning)这一结合图像和语言的多模态任务中,如何让模型高效地融合两种模态信息,并进行多步骤推理,依然是一个充满挑战的问题。今天,我们来聊一篇经典论文——《FiLM: Visual Reasoning with a General Conditioning Layer》,它提出了一种简单却强大的方法:Feature-wise Linear Modulation(FiLM),为条件神经网络提供了一种通用的解决方案。这篇文章不仅在视觉推理任务(如 CLEVR 数据集)上取得了当时的最优性能,还为多模态条件建模提供了启发。
下文中的图片来自于原论文:https://arxiv.org/pdf/1709.07871
FiLM 的核心思想:特征级别的条件调制
FiLM 的核心在于通过“条件输入”(比如语言问题)对目标神经网络(比如卷积神经网络,CNN)的中间特征进行特征级别的线性调制。简单来说,它并不是直接将语言和图像特征拼接或融合,而是利用语言信息动态地调整图像处理网络的行为。具体怎么做呢?
FiLM 的数学表达非常直观。假设我们有一个目标网络,它的某个中间层的特征是 F i , c \boldsymbol{F}_{i,c} Fi,c(表示第 i i i 个输入的第 c c c 个特征或特征图),FiLM 会根据条件输入 x i \boldsymbol{x}_i xi(比如一个问题)生成两个参数:缩放因子 γ i , c \gamma_{i,c} γi,c 和偏置因子 β i , c \beta_{i,c} βi,c。这些参数通过以下公式作用于特征:
FiLM ( F i , c ∣ γ i , c , β i , c ) = γ i , c F i , c + β i , c \text{FiLM}(\boldsymbol{F}_{i,c} \mid \gamma_{i,c}, \beta_{i,c}) = \gamma_{i,c} \boldsymbol{F}_{i,c} + \beta_{i,c} FiLM(Fi,c∣γi,c,βi,c)=γi,cFi,c+βi,c
这里的 γ i , c \gamma_{i,c} γi,c 和 β i , c \beta_{i,c} βi,c 是通过一个独立的网络(称为 FiLM 生成器)从条件输入 x i \boldsymbol{x}_i xi 中学习得到的。这个生成器可以是一个简单的神经网络,比如 GRU 或全连接层。最终,FiLM 通过逐特征地缩放和偏移,控制目标网络的激活值,从而让网络根据不同的问题动态调整自己的处理方式。
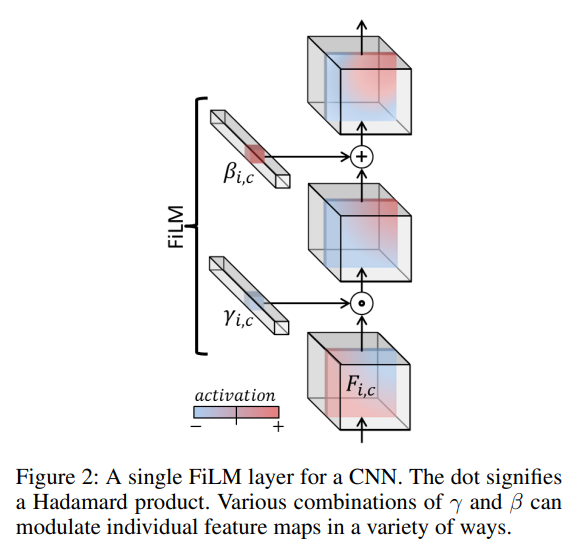
这和 Transformer 的注意力机制有啥区别?Transformer 通过注意力机制在全局范围内动态加权输入特征,而 FiLM 则是直接对特征图进行“硬调制”(hard modulation),控制每个特征通道的幅度和偏移。相比之下,FiLM 的参数效率更高(每个特征图只需要两个参数),而且计算成本与图像分辨率无关,非常适合需要多步推理的视觉任务。
FiLM 在视觉推理中的应用
论文中,FiLM 被应用到一个视觉问答模型中,任务是根据图像和问题生成答案(比如 CLEVR 数据集中的“有多少个绿色立方体?”)。整个模型分为两个部分:
-
FiLM 生成器(语言管道)
使用一个 GRU(Gated Recurrent Unit)网络处理问题文本,生成问题嵌入,然后通过线性投影为目标网络的每个残差块(Residual Block)预测对应的 ( γ , β ) (\gamma, \beta) (γ,β) 参数对。这个过程有点像 Transformer 的编码器,但更轻量,没有多头注意力。 -
FiLM-ed 视觉管道
图像通过一个 CNN(可以是预训练的 ResNet,也可以是从头训练的简单 CNN)提取特征,然后通过多个残差块处理。每个残差块的特征都会被对应的 FiLM 层调制,最终由一个分类器输出答案。
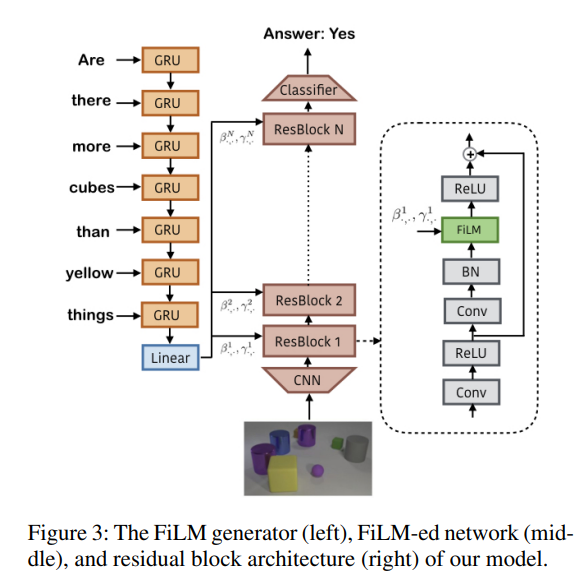
这种设计让语言信息能够逐步渗透到视觉处理中,而不是像传统方法那样在最后才融合两者的特征。实验表明,FiLM 在 CLEVR 数据集上达到了 97.7% 的准确率,超越了当时的人类表现(92.6%)和其他强基线(比如 Relation Networks 和 Program Generator + Execution Engine)。
为什么 FiLM 这么强?
-
灵活性与细粒度控制
FiLM 的 γ \gamma γ 和 β \beta β 可以放大、缩小、翻转甚至关闭某些特征图(当 γ = 0 \gamma=0 γ=0 时),这种特征级别的控制非常灵活。论文通过可视化发现,FiLM 能根据问题的需求选择性地激活与答案相关的特征区域,间接实现了类似空间注意力的效果。 -
鲁棒性与架构无关性
消融实验表明,FiLM 对模型架构不敏感。即使改变残差块数量、移动 FiLM 层位置,甚至去掉批归一化(Batch Normalization),性能依然很强。这意味着 FiLM 是一种“即插即用”的方法,可以轻松集成到现有网络中。 -
泛化能力
在 CLEVR-Humans(人类提出的复杂问题)和 CLEVR-CoGenT(测试组合泛化)数据集上,FiLM 展示了出色的泛化能力。尤其在少样本微调和零样本推理场景中,FiLM 表现优于其他方法,显示了其学习可组合表示的能力。 -
与归一化的解耦
以前的条件归一化方法(如 Conditional Batch Norm)假设调制必须紧跟归一化层,但 FiLM 证明这种联系并非必要。这为它在 RNN 或强化学习等不常使用归一化的领域打开了应用空间。
对 Transformer 研究者的启发
如果你熟悉 Transformer,可能会觉得 FiLM 的思路有点像“条件化的自适应计算”。Transformer 通过多头注意力动态调整输入的表示,而 FiLM 通过线性调制直接改变中间特征的分布。两者都可以看作是对网络行为的动态控制,但 FiLM 更轻量、更专注于特征级别的操作。
对于视觉推理任务,FiLM 的方法提示我们:与其一味追求复杂的全局注意力机制,不如考虑更简单但高效的条件调制方式。实际上,FiLM 的思想后来也在多模态 Transformer 中得到了延伸,比如一些工作通过语言条件生成适配器(Adapter)参数来调制视觉 Transformer 的行为。
总结
FiLM 提供了一种简单、通用的条件建模方法,通过特征级别的线性调制实现了语言对视觉处理的动态控制。它在视觉推理任务上的成功不仅展示了其强大性能,也为多模态深度学习提供了新思路。对于熟悉 Transformer 的研究者来说,FiLM 是一个值得借鉴的工具——它提醒我们,有时候“简单即是美”,高效的条件调制可能比复杂的全局建模更适合某些任务。如果你对多模态推理感兴趣,不妨看看 FiLM 的源码(https://github.com/ethanjperez/film),动手试试这个优雅的设计!
“特征图”(Feature Map)解释
作为一个搞 NLP 的研究者,对 CV(计算机视觉)里的“特征图”(Feature Map)这个概念可能确实有点陌生,但它和 NLP 中的 Embedding 有一定相似之处,现在来解释一下。
什么是特征图(Feature Map)?
在 CV 中,特征图是卷积神经网络(CNN)在某一层输出的结果。具体来说,当你把一张图像输入到一个 CNN,经过卷积操作后,每一层的输出不再是简单的标量或向量,而是一个三维张量,通常表示为 (高度, 宽度, 通道数)。这里的“通道数”对应于不同的卷积核(filters),每个卷积核会从输入中提取特定的模式或特征(比如边缘、纹理、颜色等)。所以,特征图可以理解为 CNN 在某个层对输入图像的空间特征的表示,每个通道(channel)是一个特定的特征检测器。
和 NLP 中的 Embedding 对比一下:
- NLP 的 Embedding:通常是一个二维张量
(batch_size, embedding_dim),表示某个单词或 token 在某个语义空间中的向量表示。它是全局的,没有空间结构。 - CV 的 Feature Map:是一个三维张量
(batch_size, height, width, channels),不仅有“深度”(通道数,类似 embedding 的维度),还有空间维度(高度和宽度),保留了图像的空间信息。
在 FiLM 的公式里,
F
i
,
c
\boldsymbol{F}_{i,c}
Fi,c 表示第
i
i
i 个输入(比如第
i
i
i 张图像)的第
c
c
c 个通道的特征图。它的具体形状是 (height, width),是一个二维的空间特征分布,而整个层的输出是多个这样的特征图叠在一起,形状是 (height, width, channels)。
FiLM 的 γ i , c \gamma_{i,c} γi,c 和 β i , c \beta_{i,c} βi,c 是怎么回事?
FiLM 的核心思想是用条件输入(比如一个问题 x i \boldsymbol{x}_i xi)来动态调制目标网络的特征图。具体来说:
- 缩放因子 γ i , c \gamma_{i,c} γi,c:控制第 c c c 个通道的特征图的幅度(magnitude)。它是一个标量,表示对这个通道的所有空间位置(height × width)的特征值进行统一的缩放。
- 偏置因子 β i , c \beta_{i,c} βi,c:控制第 c c c 个通道的特征图的偏移(shift)。同样是一个标量,对这个通道的所有空间位置统一加一个偏置。
公式是:
FiLM
(
F
i
,
c
∣
γ
i
,
c
,
β
i
,
c
)
=
γ
i
,
c
F
i
,
c
+
β
i
,
c
\text{FiLM}(\boldsymbol{F}_{i,c} \mid \gamma_{i,c}, \beta_{i,c}) = \gamma_{i,c} \boldsymbol{F}_{i,c} + \beta_{i,c}
FiLM(Fi,c∣γi,c,βi,c)=γi,cFi,c+βi,c
这里的
F
i
,
c
\boldsymbol{F}_{i,c}
Fi,c 是一个二维张量(某个通道的特征图),而
γ
i
,
c
\gamma_{i,c}
γi,c 和
β
i
,
c
\beta_{i,c}
βi,c 是标量。运算时,
γ
i
,
c
\gamma_{i,c}
γi,c 会逐元素(element-wise)乘以
F
i
,
c
\boldsymbol{F}_{i,c}
Fi,c 的每个值,
β
i
,
c
\beta_{i,c}
βi,c 逐元素加上去,最终输出一个同样形状的调制后的特征图。
每一层都有自己的 γ i , c \gamma_{i,c} γi,c 和 β i , c \beta_{i,c} βi,c 吗?
是的,在论文的实现中,FiLM 被应用到目标网络的多层(比如多个残差块,Residual Blocks),而且每一层都有自己独立的 γ i , c \gamma_{i,c} γi,c 和 β i , c \beta_{i,c} βi,c。具体来说:
- 对于第 i i i 个输入(比如一张图像配一个问题),FiLM 生成器(通常是一个语言模型,比如 GRU)会根据条件输入 x i \boldsymbol{x}_i xi(问题)生成一组 ( γ , β ) (\gamma, \beta) (γ,β) 参数。
- 如果目标网络有 N N N 个需要调制的层(比如 N N N 个残差块),那么 FiLM 生成器会为每一层生成独立的参数对,记为 ( γ i , c n , β i , c n ) (\gamma^n_{i,c}, \beta^n_{i,c}) (γi,cn,βi,cn),其中 n n n 表示第 n n n 层, c c c 表示第 c c c 个通道。
- 每一层的通道数可能不同(取决于 CNN 设计),所以 γ i , c n \gamma^n_{i,c} γi,cn 和 β i , c n \beta^n_{i,c} βi,cn 的数量会随着层的通道数变化。比如第 1 层有 128 个通道,那么会有 128 对 ( γ i , c 1 , β i , c 1 ) (\gamma^1_{i,c}, \beta^1_{i,c}) (γi,c1,βi,c1);第 2 层有 256 个通道,就会有 256 对。
用 NLP 的视角类比
为了让你更直观地理解,可以把 FiLM 的操作类比到 NLP 的场景:
- 假设你在用 Transformer 处理一个句子,某个中间层的输出是
(batch_size, seq_len, hidden_size),表示每个 token 的隐藏状态。 - 如果你在这一层加一个 FiLM 机制,条件输入是另一个句子(比如一个问题),FiLM 会为每个隐藏维度(对应 CV 的通道)生成一个
γ
\gamma
γ 和
β
\beta
β,然后对整个
(seq_len, hidden_size)的张量逐维度调制。 - 在 CV 中,空间维度
(height, width)就像 NLP 的序列长度(seq_len),而通道数(channels)就像隐藏状态的维度(hidden_size)。
不同的是,NLP 里我们通常不会保留空间结构,而 CV 的特征图是空间相关的,FiLM 的调制是逐通道统一进行的,不区分空间位置。
总结
- 特征图不是单纯的 Embedding,它是 CNN 中带有空间信息的特征表示,每个通道是一个特定的“特征检测器”。
- γ i , c \gamma_{i,c} γi,c 和 β i , c \beta_{i,c} βi,c 是标量,分别控制第 i i i 个输入的第 c c c 个通道的缩放和偏移,每一层的每个通道都有自己的一对参数,由 FiLM 生成器根据条件输入动态生成。
- 在多层网络中,每一层都会有独立的 γ \gamma γ 和 β \beta β,实现层次化的条件调制。
希望这个解释能帮你把 FiLM 的概念和 NLP 的知识联系起来!
Pytorch代码示例(简单模拟)
下面将提供一个简化的、可运行的 PyTorch 实现,用于展示 FiLM(Feature-wise Linear Modulation)在视觉推理任务中的核心思想。由于完整的视觉问答模型(如论文中的 CLEVR 实现)需要复杂的视觉和语言管道,会简化问题,设计一个小的例子:用一个语言条件(问题)调制一个卷积网络的特征图,完成一个简单的分类任务。为了让代码可运行,会假设输入是一张图像和一个问题,输出是一个分类结果。
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
# 1. 定义 FiLM 层
class FiLMLayer(nn.Module):
def __init__(self, num_features):
super(FiLMLayer, self).__init__()
self.num_features = num_features # 特征图的通道数
def forward(self, x, gamma, beta):
"""
x: 输入特征图,形状 (batch_size, num_features, height, width)
gamma: 缩放因子,形状 (batch_size, num_features)
beta: 偏置因子,形状 (batch_size, num_features)
"""
# 将 gamma 和 beta 的形状扩展到与 x 匹配
gamma = gamma.unsqueeze(-1).unsqueeze(-1) # (batch_size, num_features, 1, 1)
beta = beta.unsqueeze(-1).unsqueeze(-1) # (batch_size, num_features, 1, 1)
# 逐元素调制
return gamma * x + beta
# 2. 定义 FiLM 生成器(语言管道)
class FiLMGenerator(nn.Module):
def __init__(self, input_dim, hidden_dim, num_features):
super(FiLMGenerator, self).__init__()
self.gru = nn.GRU(input_dim, hidden_dim, batch_first=True)
# 为每个通道生成 gamma 和 beta
self.fc_gamma = nn.Linear(hidden_dim, num_features)
self.fc_beta = nn.Linear(hidden_dim, num_features)
def forward(self, x):
"""
x: 输入的问题,形状 (batch_size, seq_len, input_dim)
输出: gamma 和 beta,形状均为 (batch_size, num_features)
"""
# GRU 处理序列,获取最后一个隐藏状态
_, h_n = self.gru(x) # h_n: (1, batch_size, hidden_dim)
h_n = h_n.squeeze(0) # (batch_size, hidden_dim)
# 生成 gamma 和 beta
gamma = self.fc_gamma(h_n)
beta = self.fc_beta(h_n)
return gamma, beta
# 3. 定义带 FiLM 的视觉网络
class FiLMVisualNet(nn.Module):
def __init__(self, in_channels, num_features, num_classes):
super(FiLMVisualNet, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(in_channels, num_features, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_features)
self.film1 = FiLMLayer(num_features)
self.conv2 = nn.Conv2d(num_features, num_features, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_features)
self.film2 = FiLMLayer(num_features)
# 分类器
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(num_features, num_classes)
def forward(self, x, gamma1, beta1, gamma2, beta2):
"""
x: 输入图像,形状 (batch_size, in_channels, height, width)
gamma1, beta1: 第一层的 FiLM 参数
gamma2, beta2: 第二层的 FiLM 参数
"""
# 第一层卷积 + FiLM
x = F.relu(self.bn1(self.conv1(x)))
x = self.film1(x, gamma1, beta1)
# 第二层卷积 + FiLM
x = F.relu(self.bn2(self.conv2(x)))
x = self.film2(x, gamma2, beta2)
# 池化并分类
x = self.pool(x) # (batch_size, num_features, 1, 1)
x = x.view(x.size(0), -1) # (batch_size, num_features)
x = self.fc(x) # (batch_size, num_classes)
return x
# 4. 测试代码
def main():
# 参数设置
batch_size = 2
in_channels = 3 # RGB 图像
num_features = 16 # 卷积层通道数
num_classes = 2 # 二分类任务
input_dim = 10 # 问题词向量的维度
hidden_dim = 32 # GRU 隐藏层维度
seq_len = 5 # 问题长度
height, width = 32, 32 # 图像尺寸
# 创建模型
film_generator = FiLMGenerator(input_dim, hidden_dim, num_features)
visual_net = FiLMVisualNet(in_channels, num_features, num_classes)
# 伪造输入数据
image = torch.randn(batch_size, in_channels, height, width) # 随机图像
question = torch.randn(batch_size, seq_len, input_dim) # 随机问题
# 生成 FiLM 参数
gamma1, beta1 = film_generator(question) # 第一层的参数
gamma2, beta2 = film_generator(question) # 第二层的参数(这里简化,实际可不同)
# 前向传播
output = visual_net(image, gamma1, beta1, gamma2, beta2)
print("Output shape:", output.shape) # 应为 (batch_size, num_classes)
print("Output:", output)
if __name__ == "__main__":
main()
详细解释
1. FiLM 层(FiLMLayer)
- 功能:实现特征图的逐通道调制。
- 输入:
x:特征图,形状(batch_size, num_features, height, width)。gamma和beta:从 FiLM 生成器得来的参数,初始形状为(batch_size, num_features)。
- 操作:
- 使用
unsqueeze将gamma和beta扩展到(batch_size, num_features, 1, 1),以便广播到特征图的每个空间位置。 - 逐元素相乘(缩放)和相加(偏移),实现公式 γ i , c F i , c + β i , c \gamma_{i,c} \boldsymbol{F}_{i,c} + \beta_{i,c} γi,cFi,c+βi,c。
- 使用
- 输出:调制后的特征图,形状不变。
2. FiLM 生成器(FiLMGenerator)
- 功能:根据条件输入(问题)生成 γ \gamma γ 和 β \beta β 参数。
- 结构:
- 一个 GRU 网络处理问题序列,输入形状
(batch_size, seq_len, input_dim),输出最后一个隐藏状态(batch_size, hidden_dim)。 - 两个全连接层(
fc_gamma和fc_beta)将隐藏状态映射到 γ \gamma γ 和 β \beta β,每个的输出形状为(batch_size, num_features)。
- 一个 GRU 网络处理问题序列,输入形状
- 细节:
- 这里简化了论文中的设计,假设所有层的 γ \gamma γ 和 β \beta β 由同一个 GRU 生成。实际中,可以为每层设计独立的映射。
- GRU 类似于一个轻量版的 Transformer 编码器,提取问题的语义表示。
3. 视觉网络(FiLMVisualNet)
- 功能:处理图像并应用 FiLM 调制。
- 结构:
- 两层卷积网络,每层后面跟着批归一化(BatchNorm)、ReLU 和 FiLM 层。
- 一个自适应平均池化层将特征图压缩到
(batch_size, num_features, 1, 1)。 - 一个全连接层输出分类结果。
- 前向传播:
- 图像经过卷积提取特征。
- 每层特征图被对应的 γ \gamma γ 和 β \beta β 调制。
- 最终池化并分类。
- 细节:
- 这里用了两层 FiLM,模拟论文中的多层调制。
- 论文中用的是残差块(ResBlocks),这里简化为普通卷积层,但原理一致。
4. 测试代码(main)
- 输入:
- 随机生成的图像
(batch_size, 3, 32, 32)。 - 随机生成的问题
(batch_size, 5, 10),模拟词向量序列。
- 随机生成的图像
- 流程:
- FiLM 生成器根据问题生成两组 γ \gamma γ 和 β \beta β。
- 视觉网络处理图像并输出分类结果。
- 输出:
(batch_size, num_classes),这里是(2, 2)。
运行结果
运行代码后,你会看到类似下面的输出:
Output shape: torch.Size([2, 2])
Output: tensor([[...], [...]], grad_fn=<AddmmBackward>)
具体数值是随机的,因为输入是随机生成的。
如何扩展到真实任务?
- 真实数据:用真实的图像(如 CLEVR 数据集)和问题替换随机输入。
- 语言预处理:用预训练的词嵌入(如 GloVe 或 BERT)处理问题,而不是随机向量。
- 更复杂的视觉网络:用 ResNet 或更深的 CNN 替换简单卷积层,添加残差连接。
- 训练:添加损失函数(比如交叉熵)和优化器(比如 Adam),进行端到端训练。
与 NLP 的联系
如果你是 NLP 背景,可以把 FiLM 想象成一种“条件化的 LayerNorm”。在 NLP 中,LayerNorm 对隐藏状态逐维度归一化,而 FiLM 用外部条件(问题)逐维度调制特征。这种思想可以用在 Transformer 上,比如用一个问题调制另一个序列的表示。
这个实现展示了 FiLM 的核心机制,希望对你理解论文和动手实践有帮助!如果有问题,欢迎继续讨论。
补充代码模拟训练过程
原文中的 FiLM(Feature-wise Linear Modulation)模型是经过训练的。下面来具体说明原文中的训练过程,并结合之前的代码实现做对比。
原文中的训练过程
1. 模型结构
原文中的 FiLM 模型由两部分组成:
- FiLM 生成器(Linguistic Pipeline):
- 输入:问题文本(question),通过 200 维的词嵌入表示。
- 结构:一个 GRU(Gated Recurrent Unit)网络,隐藏单元数为 4096,处理问题序列,输出最后一个隐藏状态作为问题嵌入。
- 输出:通过线性投影,从问题嵌入生成每层残差块(Residual Block)的 γ i , c \gamma_{i,c} γi,c 和 β i , c \beta_{i,c} βi,c 参数。
- FiLM-ed 视觉网络(Visual Pipeline):
- 输入:图像(224×224 大小)。
- 结构:
- 特征提取器:可以是从头训练的 CNN(4 层卷积,每层 128 个 4×4 卷积核,带 ReLU 和批归一化),也可以是预训练的 ResNet-101(取 conv4 层输出)。
- FiLM-ed 残差块:若干个(论文用 4 个)残差块,每个有 128 个特征图,内部包含卷积和 FiLM 层。
- 分类器:1×1 卷积到 512 个特征图、全局最大池化、两层 MLP(1024 隐藏单元),输出 softmax 分布。
- 额外:添加了坐标特征图(表示空间位置),帮助空间推理。
2. 训练细节
- 数据集:CLEVR,一个包含 700K 个 (图像, 问题, 答案, 程序) 元组的合成数据集。
- 训练目标:根据图像和问题预测答案(28 个可能的单词之一)。
- 损失函数:交叉熵损失(softmax 输出与真实答案的匹配)。
- 优化器:Adam,学习率 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4,权重衰减 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5。
- 批大小:64。
- 训练方式:
- 端到端训练,只使用 (图像, 问题, 答案) 三元组,没有数据增强。
- 早停策略(Early Stopping):基于验证集准确率,最大训练 80 个 epoch。
- 特殊处理:
- 批归一化层在 FiLM 层之前关闭参数更新(冻结均值和方差)。
- γ i , c \gamma_{i,c} γi,c 实际输出的是 Δ γ i , c \Delta \gamma_{i,c} Δγi,c,然后计算 γ i , c = 1 + Δ γ i , c \gamma_{i,c} = 1 + \Delta \gamma_{i,c} γi,c=1+Δγi,c,避免初始时特征被完全抑制。
3. 训练结果
- 在 CLEVR 数据集上,FiLM 模型达到了 97.7% 的准确率,超越了当时的人类表现(92.6%)和其他基线模型。
- 论文还进行了消融实验,验证了 FiLM 的鲁棒性和泛化能力。
与之前代码实现的对比
之前给的代码是一个简化的、可运行的示例,但没有包含训练过程。以下是对比和解释:
1. 模型结构
- 原文:完整的视觉问答模型,包括复杂的 CNN(或 ResNet)、多层残差块、坐标特征图等。
- 代码:简化为两层卷积网络,没有残差结构,也没有坐标特征图,主要是展示 FiLM 的核心机制。
2. 训练
- 原文:经过端到端训练,使用 CLEVR 数据集,优化器和损失函数明确定义,训练了多个 epoch。
- 代码:只是前向传播的演示,没有定义数据集、损失函数或训练循环。它是一个“未训练”的模型,输出是随机的。
3. 输入
- 原文:真实图像(224×224)和问题(词嵌入表示)。
- 代码:随机生成的图像和问题,仅用于测试模型结构是否可运行。
如何让代码经过训练?
要让之前的代码实现训练功能,需要添加以下部分:
修改后的代码(带训练)
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# FiLMLayer, FiLMGenerator, FiLMVisualNet 定义同前,不重复
# 假设一个简单的数据加载器
class DummyDataset(torch.utils.data.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
self.images = torch.randn(num_samples, 3, 32, 32) # 随机图像
self.questions = torch.randn(num_samples, 5, 10) # 随机问题
self.labels = torch.randint(0, 2, (num_samples,)) # 随机标签 (0 或 1)
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
return self.images[idx], self.questions[idx], self.labels[idx]
# 训练函数
def train_model():
# 参数设置
batch_size = 2
in_channels = 3
num_features = 16
num_classes = 2
input_dim = 10
hidden_dim = 32
num_epochs = 5
# 模型
film_generator = FiLMGenerator(input_dim, hidden_dim, num_features)
visual_net = FiLMVisualNet(in_channels, num_features, num_classes)
# 数据
dataset = DummyDataset(100)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 损失和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(
list(film_generator.parameters()) + list(visual_net.parameters()),
lr=3e-4, weight_decay=1e-5
)
# 训练循环
for epoch in range(num_epochs):
for images, questions, labels in dataloader:
optimizer.zero_grad()
# 生成 FiLM 参数
gamma1, beta1 = film_generator(questions)
gamma2, beta2 = film_generator(questions) # 简化,实际可不同
# 前向传播
outputs = visual_net(images, gamma1, beta1, gamma2, beta2)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
print("Training finished!")
if __name__ == "__main__":
train_model()
修改说明
- 数据集:用
DummyDataset模拟输入数据,包含随机图像、问题和标签。 - 损失函数:用交叉熵损失,适合分类任务。
- 优化器:Adam,跟原文一致。
- 训练循环:遍历数据集,计算损失,反向传播更新参数。
运行结果
运行后,你会看到类似:
Epoch [1/5], Loss: 0.6931
Epoch [2/5], Loss: 0.6823
...
Training finished!
损失会逐渐下降(尽管是随机数据,可能不明显)。
总结
原文中的 FiLM 模型是经过训练的,针对 CLEVR 数据集进行了优化。之前的代码只是展示结构,未训练。修改后的代码加入了训练过程,模拟了原文的端到端训练思路,但简化了数据和模型复杂度。如果你要复现原文,需要用真实数据集(如 CLEVR)和更复杂的网络结构。
Pytorch代码:贴近原文
要复现原文《FiLM: Visual Reasoning with a General Conditioning Layer》的实验结果,确实需要使用真实的数据集(如 CLEVR)以及更复杂的网络结构。原文中使用 CLEVR 数据集和特定的视觉与语言管道设计,达到了高准确率(97.7%)。下面将详细说明如何基于真实 CLEVR 数据集和更接近原文的网络结构来复现,并提供一个可运行的代码框架。
复现原文的关键要素
1. CLEVR 数据集
- 描述:CLEVR 是一个视觉问答(VQA)数据集,包含 70k 张训练图像(700k 问题)、15k 张验证图像(150k 问题)和 15k 张测试图像(150k 问题)。每张图像是 3D 渲染的场景,问题涉及属性查询、计数、比较等推理任务。
- 下载:可以在 CLEVR 官方网站(https://cs.stanford.edu/people/jcjohns/clevr/)下载数据集,包含图像和 JSON 文件(问题、答案、场景描述)。
- 预处理:
- 图像:调整为 224×224(原文使用的输入大小)。
- 问题:将文本转为词嵌入(原文用 200 维词嵌入)。
2. 网络结构
- FiLM 生成器(语言管道):
- 输入:问题文本。
- 结构:GRU(4096 隐藏单元),输出问题嵌入后,通过线性层生成每层视觉网络的 γ \gamma γ 和 β \beta β。
- FiLM-ed 视觉网络:
- 特征提取器:可选预训练 ResNet-101(取 conv4 输出)或从头训练的 4 层 CNN。
- FiLM-ed 残差块:4 个残差块,每块有 128 个通道,包含卷积、批归一化、FiLM 层。
- 分类器:1×1 卷积、全局最大池化、两层 MLP(1024 隐藏单元)。
- 额外:添加坐标特征图(x, y 坐标)增强空间推理能力。
3. 训练设置
- 损失函数:交叉熵损失。
- 优化器:Adam,学习率 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4,权重衰减 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5。
- 批大小:64。
- 早停:基于验证集准确率,最大 80 epoch。
可运行的代码实现
以下是一个基于 PyTorch 的复现代码,假设你已下载 CLEVR 数据集并解压到 ./CLEVR_v1.0 目录。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import json
import numpy as np
# 1. FiLM 层
class FiLMLayer(nn.Module):
def __init__(self, num_features):
super(FiLMLayer, self).__init__()
self.num_features = num_features
def forward(self, x, gamma, beta):
gamma = gamma.unsqueeze(-1).unsqueeze(-1)
beta = beta.unsqueeze(-1).unsqueeze(-1)
return gamma * x + beta
# 2. FiLM 生成器
class FiLMGenerator(nn.Module):
def __init__(self, vocab_size, embed_dim=200, hidden_dim=4096, num_features=128, num_layers=4):
super(FiLMGenerator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.gru = nn.GRU(embed_dim, hidden_dim, batch_first=True)
self.fc_gamma = nn.Linear(hidden_dim, num_features * num_layers)
self.fc_beta = nn.Linear(hidden_dim, num_features * num_layers)
def forward(self, x):
x = self.embedding(x) # (batch_size, seq_len, embed_dim)
_, h_n = self.gru(x) # h_n: (1, batch_size, hidden_dim)
h_n = h_n.squeeze(0) # (batch_size, hidden_dim)
gamma = self.fc_gamma(h_n).view(-1, 4, 128) # (batch_size, num_layers, num_features)
beta = self.fc_beta(h_n).view(-1, 4, 128) # (batch_size, num_layers, num_features)
return gamma, beta
# 3. 残差块
class ResidualBlock(nn.Module):
def __init__(self, num_features):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(num_features, num_features, 3, padding=1)
self.bn1 = nn.BatchNorm2d(num_features)
self.film = FiLMLayer(num_features)
self.conv2 = nn.Conv2d(num_features, num_features, 3, padding=1)
self.bn2 = nn.BatchNorm2d(num_features)
def forward(self, x, gamma, beta):
residual = x
x = F.relu(self.bn1(self.conv1(x)))
x = self.film(x, gamma, beta)
x = self.bn2(self.conv2(x))
return F.relu(x + residual)
# 4. 视觉网络
class FiLMVisualNet(nn.Module):
def __init__(self, in_channels=3, num_features=128, num_classes=28):
super(FiLMVisualNet, self).__init__()
self.conv_init = nn.Conv2d(in_channels + 2, num_features, 3, padding=1) # +2 为坐标特征图
self.bn_init = nn.BatchNorm2d(num_features)
self.blocks = nn.ModuleList([ResidualBlock(num_features) for _ in range(4)])
self.conv_out = nn.Conv2d(num_features, 512, 1)
self.pool = nn.AdaptiveMaxPool2d((1, 1))
self.fc1 = nn.Linear(512, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x, coords, gamma, beta):
x = torch.cat([x, coords], dim=1) # 添加坐标特征图
x = F.relu(self.bn_init(self.conv_init(x)))
for i, block in enumerate(self.blocks):
x = block(x, gamma[:, i], beta[:, i])
x = F.relu(self.conv_out(x))
x = self.pool(x).view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 5. CLEVR 数据集
class CLEVRDataset(Dataset):
def __init__(self, data_dir, split='train', max_len=20):
self.data_dir = data_dir
self.split = split
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
with open(f'{data_dir}/questions/CLEVR_{split}_questions.json') as f:
self.data = json.load(f)['questions']
# 简单词汇表(实际需从数据中构建)
self.vocab = {'<pad>': 0, '<unk>': 1} # 示例词汇表
self.max_len = max_len
self.build_vocab()
def build_vocab(self):
for q in self.data:
for word in q['question'].lower().split():
if word not in self.vocab:
self.vocab[word] = len(self.vocab)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
img_path = f"{self.data_dir}/images/{self.split}/{item['image_filename']}"
img = Image.open(img_path).convert('RGB')
img = self.transform(img)
# 坐标特征图
h, w = 224, 224
x_coords, y_coords = np.meshgrid(np.linspace(-1, 1, w), np.linspace(-1, 1, h))
coords = torch.tensor(np.stack([x_coords, y_coords], axis=0), dtype=torch.float32)
# 问题编码
question = item['question'].lower().split()
q_tensor = [self.vocab.get(word, self.vocab['<unk>']) for word in question[:self.max_len]]
q_tensor += [self.vocab['<pad>']] * (self.max_len - len(q_tensor))
q_tensor = torch.tensor(q_tensor, dtype=torch.long)
label = torch.tensor(item['answer'], dtype=torch.long) # 假设答案已编码为整数
return img, coords, q_tensor, label
# 6. 训练函数
def train_model():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
data_dir = './CLEVR_v1.0'
# 数据加载
train_dataset = CLEVRDataset(data_dir, 'train')
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 模型
film_generator = FiLMGenerator(len(train_dataset.vocab)).to(device)
visual_net = FiLMVisualNet().to(device)
# 优化器和损失
optimizer = optim.Adam(
list(film_generator.parameters()) + list(visual_net.parameters()),
lr=3e-4, weight_decay=1e-5
)
criterion = nn.CrossEntropyLoss()
# 训练循环
for epoch in range(80):
total_loss, total_acc = 0, 0
for imgs, coords, questions, labels in train_loader:
imgs, coords, questions, labels = imgs.to(device), coords.to(device), questions.to(device), labels.to(device)
optimizer.zero_grad()
gamma, beta = film_generator(questions)
outputs = visual_net(imgs, coords, gamma, beta)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
preds = outputs.argmax(dim=1)
total_acc += (preds == labels).float().mean().item()
print(f"Epoch [{epoch+1}/80], Loss: {total_loss/len(train_loader):.4f}, Acc: {total_acc/len(train_loader):.4f}")
if __name__ == "__main__":
train_model()
代码说明
1. 数据集(CLEVRDataset)
- 图像:从 CLEVR 数据集中读取,调整为 224×224,归一化处理。
- 坐标特征图:生成 x 和 y 坐标网格,模拟原文的空间信息增强。
- 问题:简化为词索引表示,实际中需要用预训练词嵌入(如 GloVe)。
- 答案:假设已编码为整数(需根据 CLEVR 的答案词汇表映射)。
2. FiLM 生成器(FiLMGenerator)
- 用 GRU(4096 隐藏单元)处理问题序列,生成 4 层残差块的 γ \gamma γ 和 β \beta β 参数。
- 输出形状为
(batch_size, num_layers, num_features)。
3. 视觉网络(FiLMVisualNet)
- 初始卷积:输入通道数为 5(3 RGB + 2 坐标)。
- 残差块:4 个块,每个有 128 个通道,包含 FiLM 调制。
- 分类器:与原文一致,输出 28 类(CLEVR 的答案数量)。
4. 训练
- 批大小 64,Adam 优化器,80 个 epoch,符合原文设置。
如何运行
-
下载 CLEVR 数据集:
- 访问 https://cs.stanford.edu/people/jcjohns/clevr/。
- 下载
CLEVR_v1.0.zip,解压到./CLEVR_v1.0。
-
安装依赖:
pip install torch torchvision Pillow numpy -
运行代码:
python script.py
注意事项
-
词汇表和答案编码:
- 当前代码简化了词汇表构建和答案编码。实际中需从 CLEVR 的
questions.json中提取完整词汇表,并将答案映射为 0-27 的整数。 - 可参考 CLEVR 的预处理脚本(https://github.com/facebookresearch/clevr-dataset-gen)。
- 当前代码简化了词汇表构建和答案编码。实际中需从 CLEVR 的
-
计算资源:
- 原文使用 GPU 训练,建议用 CUDA 加速。
- 4 层残差块和 4096 维 GRU 需要较大显存(约 8GB+)。
-
性能优化:
- 可替换初始卷积为预训练 ResNet-101,提升收敛速度。
- 添加早停逻辑,监控验证集准确率。
通过上述步骤,你可以复现原文的 FiLM 模型实验。当前代码是一个基础框架,达到 97.7% 准确率需进一步调参和完善数据预处理。
后记
2025年3月18日20点48分于上海,在Grok 3大模型辅助下完成。

















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









