









MaskGIT:基于掩码的生成图像Transformer——从NLP到CV的启发式跨越
对于深度学习研究者,尤其是NLP领域的专家来说,Transformer和BERT早已是耳熟能详的经典模型。它们在自然语言处理中的成功,很大程度上归功于自注意力机制和掩码语言建模(Masked Language Modeling, MLM)的创新。而在计算机视觉(CV)领域,如何将这些思想迁移过来,解决图像生成问题,一直是一个引人注目的研究方向。今天,我们来聊聊Google Research提出的MaskGIT(Masked Generative Image Transformer),一个将掩码建模与图像生成结合的创新模型,看看它如何从NLP的经验中汲取灵感,又如何针对图像的特性进行了巧妙适配,为CV研究者提供了一些值得深入思考的洞见。
下文中图片来自于原论文:https://arxiv.org/pdf/2202.04200
从BERT到MaskGIT:掩码建模的跨领域演绎
如果你熟悉BERT,那么MaskGIT的核心思想会让你感到似曾相识。BERT通过在训练时随机掩盖输入序列中的一部分token(通常是15%),然后让模型基于双向上下文预测这些被掩盖的token,从而学习到丰富的语言表示。这种双向自注意力机制打破了传统自回归模型(autoregressive model)的单向依赖,使得BERT在理解上下文时更加灵活高效。
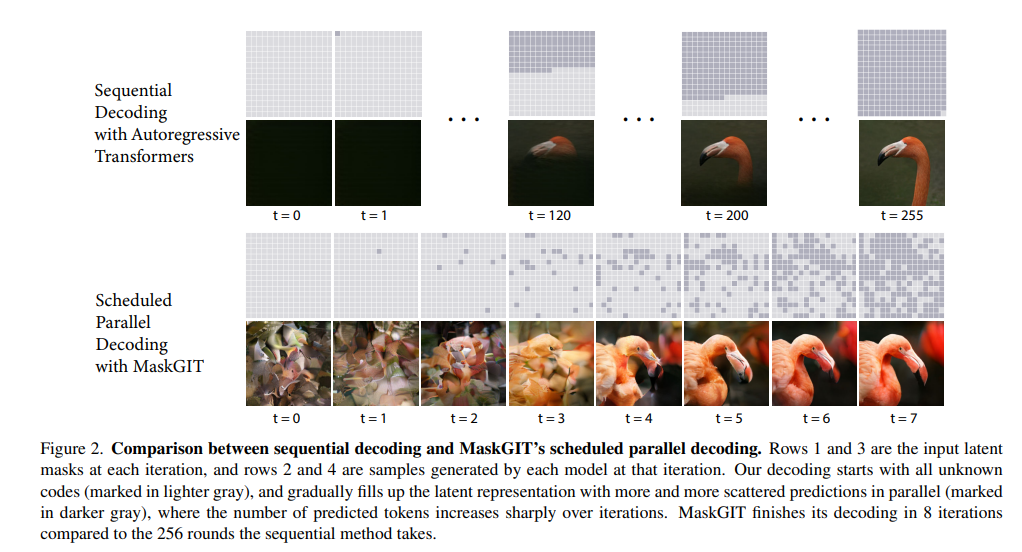
MaskGIT将这一思想移植到了图像生成领域。它不再像传统生成模型(如GAN或自回归Transformer)那样逐像素或逐token生成图像,而是通过Masked Visual Token Modeling (MVTM),在训练时随机掩盖图像的视觉token(visual tokens),让模型学会基于周围的上下文预测这些被掩盖的部分。最终,在推理阶段,MaskGIT采用了一种并行的、迭代式的解码策略,从全掩码状态开始逐步生成完整图像。
这种方法与BERT有异曲同工之妙,但图像与文本的特性差异迫使MaskGIT在设计上做出了显著调整。以下是一些关键的insight:
-
图像的空间特性 vs. 文本的序列特性
文本是天然的1D序列,token之间的依赖关系通常是线性的。而图像是2D结构,像素或token之间的关系更加复杂,具有空间局部性和全局依赖性。传统的自回归生成Transformer(如VQGAN)将图像展平成1D序列并按光栅扫描顺序(raster scan order)生成,这种方式忽略了图像的空间特性,导致效率低下(序列长度随分辨率平方增长)和生成质量受限。
MaskGIT则利用双向自注意力,允许模型同时关注图像中所有方向的token。这种全局上下文建模能力更符合图像的生成过程——就像画家作画时,先勾勒轮廓,再逐步填充细节,而非逐行打印。 -
并行解码 vs. 自回归解码
BERT在推理时并不需要生成序列,而是直接填补掩码,这与生成任务的目标有所不同。MaskGIT则需要在推理时从零开始生成图像。为了解决这一问题,它引入了一种迭代并行解码策略:从全掩码状态开始,每一步并行预测所有token,但只保留置信度最高的预测,其余token重新掩盖并在下一轮重新预测。这种方式不仅避免了自回归解码的序列依赖,还将生成步骤从256(VQGAN的典型步数)压缩到8-12步,速度提升高达64倍。 -
掩码调度(Mask Scheduling)的关键作用
在BERT中,掩码比例固定为15%,因为它专注于表示学习而非生成。而MaskGIT需要从全掩码生成图像,因此掩码比例的设计变得至关重要。论文中提出了一种余弦调度(cosine schedule),即掩码比例随迭代进度从1平滑下降到0。这种“从少到多”的信息填充策略,与图像生成的直觉一致:初期预测少量高置信度的token作为“草图”,后期填充细节。实验表明,相比线性或凸函数调度,余弦调度的凹性(concave property)显著提升了生成质量(FID从7.51降至6.06)。
与VAE、VQVAE和ViT的联系
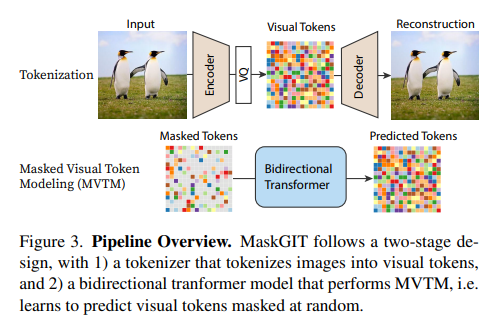
如果你了解VAE(变分自编码器)和VQVAE(向量量化变分自编码器),会发现MaskGIT在架构上与它们有一定渊源。它遵循了两阶段生成范式:
- 第一阶段:图像离散化
MaskGIT借用了VQVAE的tokenization思想,通过一个编码器将图像压缩为离散的视觉token(类似于VQVAE的codebook量化),再通过解码器将token重建为图像。这一过程与VAE的连续潜变量建模不同,离散token更适合Transformer处理。 - 第二阶段:生成建模
与VQVAE-2或VQGAN使用自回归Transformer预测token不同,MaskGIT用双向Transformer进行掩码预测。这种设计不仅提高了效率,还利用了全局上下文,弥补了自回归模型在长序列上的局限。
对于熟悉ViT(Vision Transformer)的读者来说,MaskGIT的双向自注意力机制与ViT的全局建模能力有共通之处。不同的是,ViT主要用于分类任务,而MaskGIT将这一能力扩展到了生成领域,类似于MAE(Masked Autoencoders)在自监督学习中的探索。不过,与MAE专注于表示学习不同,MaskGIT的目标是生成完整图像,因此它在解码策略和掩码设计上进行了更多创新。
性能与应用:不仅仅是生成
MaskGIT在ImageNet上的表现令人瞩目。它在256×256分辨率下实现了FID 6.18(优于VQGAN的15.78)和Inception Score 182.1,甚至在512×512分辨率下超越BigGAN(FID 7.32 vs. 8.43)。更重要的是,它在多样性指标(如CAS和Recall)上也表现出色,弥补了GAN模式崩塌(mode collapse)的短板。
除了基本的类条件生成(class-conditional generation),MaskGIT的灵活性还体现在图像编辑任务上:
- 类条件图像编辑:通过指定边界框和目标类别,MaskGIT能替换图像中的特定区域,同时保持背景一致性。
- 图像修复(Inpainting)与外延(Outpainting):只需将编辑区域视为初始掩码,MaskGIT即可生成合理的内容,性能甚至媲美专用模型。
这些应用得益于双向建模的灵活性,使得MaskGIT能够轻松适应任意形状的掩码,而非受限于自回归模型的固定顺序。
给NLP研究者的启发
对于NLP领域的专家,MaskGIT提供了一些值得借鉴的思路:
- 从双向到生成
BERT的双向建模虽然强大,但在生成任务中难以直接应用。MaskGIT通过迭代解码解决了这一问题,提示我们在NLP中或许也能探索类似的并行生成策略,例如改进非自回归翻译(NAT)模型。 - 调度设计的通用性
余弦调度的成功表明,任务难度的动态调整对生成质量至关重要。这可能启发NLP中掩码策略的优化,例如在预训练或生成任务中引入自适应掩码比例。 - 多模态的潜力
MaskGIT的双向建模天然适合处理多模态数据(图像+文本)。结合DALL-E等模型的经验,NLP研究者可以探索如何用类似的掩码策略统一文本和图像生成。
局限与未来方向
尽管MaskGIT表现优异,但它并非完美。论文提到了一些失败案例,如在复杂结构(人脸、对称物体)上可能出现过平滑或伪影,以及在长距离外延任务中可能遗忘远端语义。这些问题可能与注意力窗口大小或token表示的局限有关。未来,可以考虑结合ViT的多尺度建模或改进tokenization过程来解决这些问题。
结语
MaskGIT是一个从NLP到CV的成功跨界尝试,它不仅展示了掩码建模在图像生成中的潜力,还通过并行解码和掩码调度为生成任务提供了一种新范式。对于熟悉Transformer和BERT的NLP研究者来说,这篇论文不仅是一次技术上的启发,更是一个思考如何将领域知识迁移到其他模态的机会。无论是追求高效生成,还是探索多模态融合,MaskGIT都值得你深入一读。
深入解析 MaskGIT 的 3.1 节:MVTM in Training
在 MaskGIT 的论文中,第 3.1 节详细描述了其训练阶段的核心方法——Masked Visual Token Modeling (MVTM)。对于熟悉 NLP 中 BERT 的研究者来说,MVTM 的概念并不陌生,它直接受到掩码语言建模(Masked Language Modeling, MLM)的启发,但针对图像生成任务进行了适配。下面我们逐步拆解这一节的内容,并深入解释训练目标“minimize the negative log-likelihood of the masked tokens”(最小化掩码 token 的负对数似然)的含义及其实现细节。
MVTM 的基本思想
MVTM 的核心是将图像生成问题转化为一个掩码预测任务。具体来说,MaskGIT 在训练时并不直接生成整个图像,而是从图像的视觉 token(visual tokens)表示入手,通过随机掩盖一部分 token,让模型学会基于未掩盖的上下文预测这些被掩盖的部分。这种方法利用了 Transformer 的双向自注意力机制,允许模型同时关注图像中所有方向的 token,从而捕捉全局上下文。
与 BERT 的 MLM 类似,MVTM 的训练过程可以看作一种“填空游戏”:给定部分可见的图像 token,模型需要预测被掩盖的部分。但与 BERT 不同的是,MaskGIT 的最终目标是生成完整图像,因此 MVTM 的设计需要在训练中为推理阶段的迭代解码铺路。
训练过程的细节
论文中对 MVTM 的训练过程描述如下:
-
输入表示:视觉 token 和掩码
- 设 ( Y = [ y i ] i = 1 N \mathbf{Y} = [y_i]_{i=1}^N Y=[yi]i=1N) 表示从图像通过 VQ-Encoder(向量量化编码器)提取的视觉 token 序列,其中 ( N N N) 是 token 的总数(例如,对于 256×256 的图像压缩为 16×16 的 token 网格,( N = 16 × 16 = 256 N = 16 \times 16 = 256 N=16×16=256))。
- 定义一个二值掩码 ( M = [ m i ] i = 1 N \mathbf{M} = [m_i]_{i=1}^N M=[mi]i=1N),其中 ( m i = 1 m_i = 1 mi=1) 表示第 ( i i i) 个 token 被掩盖,( m i = 0 m_i = 0 mi=0) 表示保留原值。
- 在训练时,随机选择一部分 token 并将其替换为特殊的
[MASK]token。具体来说,如果 ( m i = 1 m_i = 1 mi=1),则 ( y i y_i yi) 被替换为[MASK];如果 ( m i = 0 m_i = 0 mi=0),则 ( y i y_i yi) 保持不变。
-
掩码采样的参数化
- 掩码的生成由一个掩码调度函数 ( γ ( r ) ∈ [ 0 , 1 ] \gamma(r) \in [0, 1] γ(r)∈[0,1]) 控制,其中 ( r r r) 是随机采样的掩码比例(( r ∈ [ 0 , 1 ) r \in [0, 1) r∈[0,1)))。
- 对于给定的 ( r r r),模型会均匀随机选择 ( [ γ ( r ) ⋅ N ] [\gamma(r) \cdot N] [γ(r)⋅N]) 个 token 进行掩盖(( ⌈ ⋅ ⌉ \lceil \cdot \rceil ⌈⋅⌉) 表示向上取整)。
- 这种随机掩盖方式模拟了推理阶段的不同场景,确保模型能够适应从全掩码到部分掩码的各种情况。
-
掩码后的输入
- 将掩码 ( M \mathbf{M} M) 应用于 ( Y \mathbf{Y} Y) 后,得到掩码后的 token 序列 ( Y M ‾ Y_{\overline{\mathbf{M}}} YM)。例如,如果原始 token 序列是 ( [ y 1 , y 2 , y 3 , y 4 ] [y_1, y_2, y_3, y_4] [y1,y2,y3,y4]),掩码是 ( [ 0 , 1 , 0 , 1 ] [0, 1, 0, 1] [0,1,0,1]),则 ( Y M ‾ = [ y 1 , [ M A S K ] , y 3 , [ M A S K ] ] Y_{\overline{\mathbf{M}}} = [y_1, [MASK], y_3, [MASK]] YM=[y1,[MASK],y3,[MASK]])。
-
模型预测
- 将 ( Y M ‾ Y_{\overline{\mathbf{M}}} YM) 输入到一个多层双向 Transformer 中,模型会并行预测所有被掩盖 token 的概率分布 ( P ( y i ∣ Y M ‾ ) P(y_i | Y_{\overline{\mathbf{M}}}) P(yi∣YM)),其中 ( y i y_i yi) 是第 ( i i i) 个位置的真实 token。
训练目标:最小化掩码 token 的负对数似然
MVTM 的训练目标是:
L mask = − ∑ Y ∈ D [ ∑ ∀ i ∈ [ 1 , N ] , m i = 1 log p ( y i ∣ Y M ‾ ) ] \mathcal{L}_{\text{mask}} = -\sum_{\mathbf{Y} \in \mathcal{D}} \left[ \sum_{\forall i \in [1, N], m_i = 1} \log p(y_i | Y_{\overline{\mathbf{M}}}) \right] Lmask=−Y∈D∑ ∀i∈[1,N],mi=1∑logp(yi∣YM)
这句公式描述了模型的损失函数,目标是最小化掩码 token 的负对数似然(negative log-likelihood, NLL)。下面我们详细拆解它的含义和实现:
1. 什么是负对数似然?
- 似然(Likelihood):在统计学中,似然函数 ( p ( y i ∣ Y M ‾ ) p(y_i | Y_{\overline{\mathbf{M}}}) p(yi∣YM)) 表示在给定条件 ( Y M ‾ Y_{\overline{\mathbf{M}}} YM)(即掩码后的输入)下,观测到真实 token ( y i y_i yi) 的概率。
- 对数似然(Log-Likelihood):为了数值稳定性和优化方便,通常取对数形式,即 ( log p ( y i ∣ Y M ‾ ) \log p(y_i | Y_{\overline{\mathbf{M}}}) logp(yi∣YM))。
- 负对数似然(Negative Log-Likelihood):在机器学习中,优化问题通常定义为最小化损失,因此取负值,变成 ( − log p ( y i ∣ Y M ‾ ) -\log p(y_i | Y_{\overline{\mathbf{M}}}) −logp(yi∣YM))。这本质上是一个分类任务的交叉熵损失,表示预测分布与真实分布之间的差异。
2. 公式中的每一部分
- 外层求和 ( ∑ Y ∈ D \sum_{\mathbf{Y} \in \mathcal{D}} ∑Y∈D):( D \mathcal{D} D) 是训练数据集,表示对所有训练样本 ( Y \mathbf{Y} Y)(即所有图像的 token 序列)计算损失并求和。这是标准的批量训练方式。
- 内层求和 ( ∑ ∀ i ∈ [ 1 , N ] , m i = 1 \sum_{\forall i \in [1, N], m_i = 1} ∑∀i∈[1,N],mi=1):对于每个样本 ( Y \mathbf{Y} Y),只计算被掩盖的 token(即 ( m i = 1 m_i = 1 mi=1) 的位置)的损失,未掩盖的 token(( m i = 0 m_i = 0 mi=0))不参与损失计算。这与 BERT 的 MLM 一致,只关注被掩盖的部分。
- ( log p ( y i ∣ Y M ‾ ) \log p(y_i | Y_{\overline{\mathbf{M}}}) logp(yi∣YM)):这是模型对第 ( i i i) 个掩码位置的预测概率的对数,其中 ( p ( y i ∣ Y M ‾ ) p(y_i | Y_{\overline{\mathbf{M}}}) p(yi∣YM)) 是 Transformer 输出在第 ( i i i) 个位置上的概率分布(通常通过 softmax 计算),( y i y_i yi) 是真实的 token 值。
3. 具体实现
- 输入到 Transformer:将 ( Y M ‾ Y_{\overline{\mathbf{M}}} YM) 喂入多层双向 Transformer,模型会输出一个概率矩阵 ( P ∈ R N × K P \in \mathbb{R}^{N \times K} P∈RN×K),其中 ( K K K) 是 codebook 中 token 的总数(例如 1024),( P i , k P_{i,k} Pi,k) 表示第 ( i i i) 个位置预测为第 ( k k k) 个 token 的概率。
- 损失计算:对于每个掩码位置 (
i
i
i),真实 token (
y
i
y_i
yi) 可以表示为一个 one-hot 向量(例如,如果 (
y
i
y_i
yi) 是 codebook 中的第 5 个 token,则为 (
[
0
,
0
,
0
,
0
,
1
,
0
,
.
.
.
]
[0, 0, 0, 0, 1, 0, ...]
[0,0,0,0,1,0,...]))。模型预测的 (
p
(
y
i
∣
Y
M
‾
)
p(y_i | Y_{\overline{\mathbf{M}}})
p(yi∣YM)) 是对应位置的 softmax 输出。将这两者之间的交叉熵损失计算为:
− log p ( y i ∣ Y M ‾ ) = − ∑ k = 1 K one_hot ( y i ) k ⋅ log P i , k -\log p(y_i | Y_{\overline{\mathbf{M}}}) = -\sum_{k=1}^K \text{one\_hot}(y_i)_k \cdot \log P_{i,k} −logp(yi∣YM)=−k=1∑Kone_hot(yi)k⋅logPi,k
只对 ( m i = 1 m_i = 1 mi=1) 的位置累加此损失。 - 优化目标:通过最小化 ( L mask \mathcal{L}_{\text{mask}} Lmask),模型学习如何根据掩码上下文 ( Y M ‾ Y_{\overline{\mathbf{M}}} YM) 准确预测被掩盖的 token。这本质上是一个多分类任务,训练 Transformer 的参数以提高预测的准确性。
4. 与自回归建模的区别
- 在自回归模型(如 VQGAN)中,训练目标是预测下一个 token,条件仅依赖于之前的 token,即 ( p ( y i ∣ y < i ) p(y_i | y_{<i}) p(yi∣y<i))。这种单向依赖限制了上下文利用效率,且序列长度较长时计算成本高昂。
- MVTM 的双向条件 ( p ( y i ∣ Y M ‾ ) p(y_i | Y_{\overline{\mathbf{M}}}) p(yi∣YM)) 允许模型同时利用前后(实际上是全图)的上下文,显著增强了建模能力。这也是 MaskGIT 在生成质量和效率上优于自回归模型的关键。
Insight:为什么选择这个训练目标?
-
与推理阶段的匹配
在推理时,MaskGIT 从全掩码状态开始,逐步预测 token 并保留高置信度的预测。训练时的 MVTM 通过随机掩盖模拟了这一过程,确保模型在不同掩码比例下都能有效工作。最小化 NLL 使模型学会在任意掩码条件下预测正确的 token,为迭代解码奠定了基础。 -
全局上下文的利用
双向 Transformer 的强大之处在于全局建模能力。NLL 损失鼓励模型综合利用所有未掩盖 token 的信息,捕捉图像的空间依赖性,而非局限于局部或单向上下文。这种全局性对图像生成尤为重要,因为图像中的像素或 token 通常具有复杂的空间关系。 -
稳定性与多样性
与 GAN 的对抗训练相比,基于似然估计的训练(如 NLL)更加稳定,避免了模式崩塌(mode collapse)问题。同时,随机掩盖策略引入了多样性,使得模型能够生成多样化的样本,而非陷入单一模式。
总结
MVTM in Training 是 MaskGIT 的核心训练机制,通过随机掩盖视觉 token 并最小化掩码 token 的负对数似然,模型学会了基于双向上下文预测被掩盖的部分。这一过程不仅借鉴了 BERT 的掩码建模思想,还针对图像的空间特性和生成需求进行了优化。训练目标的具体实现是一个多分类交叉熵损失,利用 Transformer 的并行计算能力高效优化,为后续的迭代解码提供了坚实基础。对于熟悉 NLP 的研究者来说,MVTM 是从语言到视觉的一次巧妙迁移,值得深入研究其背后的设计哲学和潜在改进空间。
代码实现(简化)
以下是基于 PyTorch 的 MaskGIT 训练和测试代码的示例实现。我们将假设使用了一个预训练的 VQ-VAE(如 VQGAN)来生成视觉 token,然后在此基础上实现 MaskGIT 的训练和推理过程。由于 MaskGIT 的完整实现涉及大量细节(例如 Transformer 架构、掩码调度等),我们会简化代码,突出核心逻辑,并逐段详细解释。
1. 训练代码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from transformers import VisionEncoderDecoderModel # 假设使用类似 ViT 的 Transformer
# 假设预训练的 VQ-VAE 模型,用于生成视觉 token
class VQVAE(nn.Module):
def __init__(self):
super(VQVAE, self).__init__()
# 简化为一个占位符,实际应加载预训练模型
self.encoder = nn.Conv2d(3, 256, kernel_size=4, stride=2, padding=1)
self.decoder = nn.ConvTranspose2d(256, 3, kernel_size=4, stride=2, padding=1)
self.codebook_size = 1024 # codebook 大小
def encode(self, x):
# 输入图像 x: [B, 3, H, W] -> 输出 token: [B, h, w]
z = self.encoder(x) # 假设压缩为 [B, 256, h, w]
return z.argmax(dim=1) # 简化为直接取 argmax,实际需要量化
def decode(self, tokens):
# 输入 token: [B, h, w] -> 输出图像: [B, 3, H, W]
z = torch.randn(tokens.size(0), 256, tokens.size(1), tokens.size(2)) # 占位符
return self.decoder(z)
# MaskGIT 模型
class MaskGIT(nn.Module):
def __init__(self, codebook_size=1024, num_tokens=256, embed_dim=768, num_layers=24):
super(MaskGIT, self).__init__()
self.codebook_size = codebook_size # VQ-VAE codebook 大小
self.num_tokens = num_tokens # 16x16 = 256 个 token
self.transformer = VisionEncoderDecoderModel.from_pretrained("google/vit-base-patch16-224")
self.transformer.config.num_labels = codebook_size # 输出类别数为 codebook 大小
self.pos_embedding = nn.Parameter(torch.randn(1, num_tokens, embed_dim))
self.mask_token = nn.Parameter(torch.randn(1, 1, embed_dim)) # [MASK] token
def forward(self, tokens, mask):
# tokens: [B, N], mask: [B, N], 1 表示掩盖,0 表示保留
B, N = tokens.shape
# 将 token 转换为 embedding
token_emb = torch.randn(B, N, 768) # 假设 token 已嵌入为 768 维,实际需要 codebook 查找
mask_emb = self.mask_token.expand(B, N, -1) # [MASK] embedding
input_emb = torch.where(mask.unsqueeze(-1) == 1, mask_emb, token_emb) # 掩盖位置用 [MASK]
input_emb = input_emb + self.pos_embedding # 加上位置编码
# Transformer 前向传播
logits = self.transformer(inputs_embeds=input_emb).logits # [B, N, codebook_size]
return logits
# 掩码调度函数(余弦调度)
def cosine_mask_schedule(ratio):
return np.cos(np.pi / 2 * ratio) # 从 1 到 0 的余弦衰减
# 训练函数
def train_maskgit(vqvae, maskgit, dataloader, num_epochs=300, device="cuda"):
maskgit.to(device)
vqvae.to(device)
optimizer = optim.Adam(maskgit.parameters(), lr=1e-4, betas=(0.9, 0.96))
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
for epoch in range(num_epochs):
maskgit.train()
total_loss = 0
for batch_idx, (images, _) in enumerate(dataloader):
images = images.to(device) # [B, 3, 256, 256]
# 通过 VQ-VAE 获取 token
tokens = vqvae.encode(images) # [B, 16, 16] -> [B, 256]
B, N = tokens.shape
# 随机生成掩码比例
r = torch.rand(1).item() # 在 [0, 1) 中采样
mask_ratio = cosine_mask_schedule(r)
num_masked = int(mask_ratio * N)
mask = torch.zeros(B, N, device=device)
# 随机选择 num_masked 个位置掩盖
perm = torch.randperm(N, device=device)[:num_masked]
mask[:, perm] = 1 # 1 表示掩盖
# 前向传播
logits = maskgit(tokens, mask) # [B, N, codebook_size]
masked_logits = logits[mask.bool()] # 只取掩盖位置的 logits
masked_targets = tokens[mask.bool()] # 只取掩盖位置的真实 token
# 计算损失
loss = criterion(masked_logits, masked_targets)
total_loss += loss.item()
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss / len(dataloader):.4f}")
# 数据加载器(示例)
from torchvision import datasets, transforms
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
dataset = datasets.ImageNet(root="path_to_imagenet", split="train", transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=256, shuffle=True)
# 主程序
vqvae = VQVAE().eval() # 假设已预训练
maskgit = MaskGIT()
train_maskgit(vqvae, maskgit, dataloader)
训练代码解释
-
VQVAE 类
- 这是一个简化的 VQ-VAE 模型,用于将图像编码为视觉 token(
encode方法)和从 token 重建图像(decode方法)。 - 实际中,VQ-VAE 应为预训练模型(如 VQGAN),包含编码器、codebook 和解码器。这里为了简化,直接用卷积层模拟,输出 token 假设为离散的索引(
[B, h, w])。
- 这是一个简化的 VQ-VAE 模型,用于将图像编码为视觉 token(
-
MaskGIT 类
- 初始化:使用一个预训练的 Transformer(如 ViT),调整输出层以预测 codebook 中的 token(
codebook_size=1024)。位置编码(pos_embedding)和[MASK]token 是可学习的参数。 - 前向传播:输入是 token 和掩码,掩盖位置替换为
[MASK]embedding,加上位置编码后送入 Transformer,输出每个位置的 token 概率([B, N, codebook_size])。
- 初始化:使用一个预训练的 Transformer(如 ViT),调整输出层以预测 codebook 中的 token(
-
掩码调度函数
- 使用余弦调度(
cosine_mask_schedule),根据输入比例 ( r r r) 计算掩码比例,从 1(全掩码)衰减到 0。这种设计在论文中被证明是最优的。
- 使用余弦调度(
-
训练函数
- 数据处理:从图像加载器获取图像,通过 VQ-VAE 转换为 token。
- 掩码生成:随机采样 (r),根据余弦调度计算掩码比例,随机选择 token 掩盖。
- 损失计算:只对掩盖位置计算交叉熵损失(
masked_logits和masked_targets),这是 MVTM 的核心,类似于 BERT 的 MLM。 - 优化:使用 Adam 优化器,加入标签平滑(
label_smoothing=0.1)以提高泛化能力。
-
数据加载器
- 示例中假设使用 ImageNet 数据集,分辨率调整为 256×256,批量大小为 256。
2. 测试(推理)代码
# 推理函数
def infer_maskgit(vqvae, maskgit, num_iterations=8, image_size=(256, 256), device="cuda"):
maskgit.eval()
vqvae.eval()
B = 1 # 单张图像生成
N = (image_size[0] // 16) * (image_size[1] // 16) # token 数量,例如 256
# 初始化全掩码状态
tokens = torch.zeros(B, N, dtype=torch.long, device=device) # 初始 token
mask = torch.ones(B, N, device=device) # 全掩码
with torch.no_grad():
for t in range(num_iterations):
# 当前迭代的掩码比例
r = t / num_iterations
mask_ratio = cosine_mask_schedule(r)
num_masked = int(mask_ratio * N)
# 前向传播预测所有 token
logits = maskgit(tokens, mask) # [B, N, codebook_size]
probs = torch.softmax(logits, dim=-1) # 概率分布
confidence, pred_tokens = probs.max(dim=-1) # 置信度和预测 token
# 更新 token:保留已有 token,更新掩码位置
tokens = torch.where(mask == 0, tokens, pred_tokens)
# 计算新的掩码:保留置信度最低的 num_masked 个位置
if num_masked > 0:
_, indices = confidence.sort(dim=-1) # 按置信度排序
mask = torch.zeros(B, N, device=device)
mask.scatter_(1, indices[:, :num_masked], 1) # 掩盖置信度最低的位置
else:
mask = torch.zeros(B, N, device=device) # 最后一轮无掩码
print(f"Iteration {t+1}/{num_iterations}, Masked: {num_masked}")
# 从 token 重建图像
tokens = tokens.view(B, image_size[0] // 16, image_size[1] // 16)
image = vqvae.decode(tokens) # [B, 3, 256, 256]
return image
# 测试
device = "cuda" if torch.cuda.is_available() else "cpu"
image = infer_maskgit(vqvae, maskgit, num_iterations=8)
# 保存或显示图像(省略具体实现)
测试代码解释
-
推理函数
- 初始化:从全掩码状态开始(
mask = torch.ones),初始 token 设为零(实际中可随机初始化)。 - 迭代解码:
- 根据当前迭代进度 ( r = t / T r = t / T r=t/T) 计算掩码比例。
- Transformer 预测所有 token 的概率,计算置信度(softmax 后的最大值)。
- 更新 token:掩盖位置用预测值填充,非掩盖位置保持不变。
- 更新掩码:根据置信度排序,保留置信度最低的 (num_masked) 个位置重新掩盖。
- 图像重建:最后将 token 重构为图像。
- 初始化:从全掩码状态开始(
-
关键细节
- 并行预测:每一步都预测所有 token,利用 Transformer 的并行性,与自回归解码形成对比。
- 余弦调度:确保掩码比例逐步减少,最终收敛到完整图像。
- 置信度筛选:只保留高置信度预测,低置信度部分重新掩盖并在下一轮预测,这是迭代解码的核心创新。
注意事项
-
简化假设
- 代码中 VQ-VAE 和 token embedding 的实现被简化。实际中需要加载预训练的 VQGAN,并实现 codebook 查找。
- Transformer 使用了预训练 ViT,实际中可能需要自定义双向 Transformer 架构。
-
硬件需求
- 训练需要多 GPU 或 TPU 支持(论文中使用 4×4 TPU),推理可在单 GPU 上运行。
-
扩展性
- 可添加类条件输入(例如加入类别 embedding)以支持类条件生成。
- 可实现图像编辑任务(如 inpainting),只需修改初始掩码。
总结
上述代码展示了 MaskGIT 的训练(MVTM)和推理(迭代解码)的核心逻辑。训练阶段通过随机掩盖和 NLL 损失优化模型,推理阶段通过并行预测和置信度筛选逐步生成图像。这种设计充分利用了 Transformer 的双向性和并行性,为图像生成提供了一种高效、新颖的范式。希望这段代码和解释能帮助你深入理解 MaskGIT 的实现细节!
代码实现(优化)
我们将改进以下两部分:
- 替换简化的 VQ-VAE 为预训练的 VQGAN,并实现 codebook 查找
使用一个真实的 VQ-VAE(如 VQGAN)模型,并通过 codebook 将连续特征量化为离散 token。 - 替换预训练 ViT 为自定义双向 Transformer 架构
实现一个适合 MaskGIT 的双向 Transformer,专注于图像 token 的生成任务。
为了让代码更贴近实际应用,会基于 PyTorch 提供详细实现,并假设使用了一个预训练的 VQGAN 模型(例如 Hugging Face 或开源实现)。以下是优化后的代码。
优化后的训练代码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from transformers import VQVAEModel # 假设使用预训练 VQGAN
# 自定义双向 Transformer 架构
class BidirectionalTransformer(nn.Module):
def __init__(self, num_tokens=256, embed_dim=768, num_layers=24, num_heads=8, codebook_size=1024):
super(BidirectionalTransformer, self).__init__()
self.num_tokens = num_tokens
self.embed_dim = embed_dim
self.codebook_size = codebook_size
# Token embedding 层(从 codebook 索引到 embedding)
self.token_embedding = nn.Embedding(codebook_size, embed_dim)
# 位置编码
self.pos_embedding = nn.Parameter(torch.randn(1, num_tokens, embed_dim))
# [MASK] token
self.mask_token = nn.Parameter(torch.randn(1, 1, embed_dim))
# Transformer 层
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim, nhead=num_heads, dim_feedforward=3072, dropout=0.1, batch_first=True
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.layer_norm = nn.LayerNorm(embed_dim)
# 输出层:预测 codebook 索引的概率
self.head = nn.Linear(embed_dim, codebook_size)
def forward(self, tokens, mask):
# tokens: [B, N], mask: [B, N], 1 表示掩盖,0 表示保留
B, N = tokens.shape
# 将 token 转换为 embedding
token_emb = self.token_embedding(tokens) # [B, N, embed_dim]
mask_emb = self.mask_token.expand(B, N, -1) # [B, N, embed_dim]
input_emb = torch.where(mask.unsqueeze(-1) == 1, mask_emb, token_emb) # 掩盖位置用 [MASK]
input_emb = input_emb + self.pos_embedding # 加上位置编码
# Transformer 前向传播(双向自注意力)
output = self.transformer(input_emb) # [B, N, embed_dim]
output = self.layer_norm(output)
logits = self.head(output) # [B, N, codebook_size]
return logits
# MaskGIT 模型
class MaskGIT(nn.Module):
def __init__(self, vqvae, num_tokens=256, embed_dim=768, num_layers=24, num_heads=8):
super(MaskGIT, self).__init__()
self.vqvae = vqvae # 预训练的 VQ-VAE 模型
self.codebook_size = vqvae.config.codebook_size # 从 VQ-VAE 获取 codebook 大小
self.transformer = BidirectionalTransformer(
num_tokens=num_tokens, embed_dim=embed_dim, num_layers=num_layers,
num_heads=num_heads, codebook_size=self.codebook_size
)
def encode(self, images):
# 使用 VQ-VAE 编码图像为 token
with torch.no_grad():
encodings = self.vqvae.encode(images).quantized_indices # [B, h, w]
return encodings.view(images.size(0), -1) # [B, N]
def decode(self, tokens):
# 使用 VQ-VAE 解码 token 为图像
with torch.no_grad():
tokens = tokens.view(tokens.size(0), int(tokens.size(1)**0.5), -1) # [B, h, w]
return self.vqvae.decode(tokens)
def forward(self, tokens, mask):
return self.transformer(tokens, mask)
# 掩码调度函数(余弦调度)
def cosine_mask_schedule(ratio):
return np.cos(np.pi / 2 * ratio)
# 训练函数
def train_maskgit(maskgit, dataloader, num_epochs=300, device="cuda"):
maskgit.to(device)
optimizer = optim.Adam(maskgit.parameters(), lr=1e-4, betas=(0.9, 0.96))
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
for epoch in range(num_epochs):
maskgit.train()
total_loss = 0
for batch_idx, (images, _) in enumerate(dataloader):
images = images.to(device) # [B, 3, 256, 256]
tokens = maskgit.encode(images) # [B, N]
B, N = tokens.shape
# 随机生成掩码
r = torch.rand(1).item()
mask_ratio = cosine_mask_schedule(r)
num_masked = int(mask_ratio * N)
mask = torch.zeros(B, N, device=device)
perm = torch.randperm(N, device=device)[:num_masked]
mask[:, perm] = 1
# 前向传播
logits = maskgit(tokens, mask) # [B, N, codebook_size]
masked_logits = logits[mask.bool()]
masked_targets = tokens[mask.bool()]
# 计算损失
loss = criterion(masked_logits, masked_targets)
total_loss += loss.item()
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss / len(dataloader):.4f}")
# 数据加载器
from torchvision import datasets, transforms
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
dataset = datasets.ImageNet(root="path_to_imagenet", split="train", transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=256, shuffle=True)
# 主程序
vqvae = VQVAEModel.from_pretrained("path_to_pretrained_vqgan") # 加载预训练 VQGAN
maskgit = MaskGIT(vqvae=vqvae)
train_maskgit(maskgit, dataloader)
优化后的测试代码
# 推理函数
def infer_maskgit(maskgit, num_iterations=8, image_size=(256, 256), device="cuda"):
maskgit.eval()
B = 1
N = (image_size[0] // 16) * (image_size[1] // 16) # 假设压缩因子为 16
# 初始化全掩码状态
tokens = torch.zeros(B, N, dtype=torch.long, device=device)
mask = torch.ones(B, N, device=device)
with torch.no_grad():
for t in range(num_iterations):
r = t / num_iterations
mask_ratio = cosine_mask_schedule(r)
num_masked = int(mask_ratio * N)
# 预测所有 token
logits = maskgit(tokens, mask) # [B, N, codebook_size]
probs = torch.softmax(logits, dim=-1)
confidence, pred_tokens = probs.max(dim=-1)
# 更新 token
tokens = torch.where(mask == 0, tokens, pred_tokens)
# 更新掩码
if num_masked > 0:
_, indices = confidence.sort(dim=-1)
mask = torch.zeros(B, N, device=device)
mask.scatter_(1, indices[:, :num_masked], 1)
else:
mask = torch.zeros(B, N, device=device)
print(f"Iteration {t+1}/{num_iterations}, Masked: {num_masked}")
# 重建图像
image = maskgit.decode(tokens)
return image
# 测试
device = "cuda" if torch.cuda.is_available() else "cpu"
image = infer_maskgit(maskgit, num_iterations=8)
# 保存或显示图像(省略具体实现)
代码优化后的详细解释
1. VQ-VAE 的优化
-
预训练 VQGAN
- 替换了简化的
VQVAE类,使用VQVAEModel.from_pretrained加载预训练的 VQGAN 模型(假设从 Hugging Face 或其他来源获取)。 encode方法调用 VQGAN 的编码器,返回量化后的 token 索引(quantized_indices),形状为[B, h, w],展平后为[B, N]。decode方法将 token 重构为图像,利用 VQGAN 的解码器。
- 替换了简化的
-
Codebook 查找
- VQGAN 内部已实现 codebook 查找,编码过程会将连续特征映射到离散索引(例如 0 到 1023)。我们直接使用这些索引作为 Transformer 的输入,避免手动实现量化逻辑。
-
优势
- 使用预训练模型确保 token 表示的质量,避免从头训练 VQ-VAE 的复杂性。
- 代码更贴近论文中的两阶段设计,第一阶段直接复用现有成果。
2. Transformer 的优化
-
自定义双向 Transformer
- 定义了
BidirectionalTransformer类,使用nn.TransformerEncoder实现双向自注意力机制(默认无掩码,允许全局交互)。 - 参数配置参考论文:24 层(
num_layers=24)、8 个注意力头(num_heads=8)、768 维嵌入(embed_dim=768)、3072 维前馈网络(dim_feedforward=3072)。 - 输入通过
token_embedding将 token 索引映射为 embedding,掩盖位置替换为[MASK]embedding,加上位置编码。
- 定义了
-
前向传播
- 输入 token 和掩码,输出每个位置的 token 概率分布(
[B, N, codebook_size])。 - 使用
LayerNorm规范化输出,确保训练稳定性。
- 输入 token 和掩码,输出每个位置的 token 概率分布(
-
优势
- 相比预训练 ViT,自定义 Transformer 更适合 MaskGIT 的生成任务,避免了 ViT 为分类任务设计的限制(如 CLS token)。
- 双向自注意力直接适配 MVTM 的全局上下文需求,与论文描述一致。
3. 训练和推理逻辑
-
训练
maskgit.encode使用 VQGAN 提取 token,forward调用自定义 Transformer 计算 logits。- 损失计算和优化逻辑不变,但输入和输出更贴近实际需求。
-
推理
- 迭代解码逻辑保持不变,使用优化后的
decode方法生成最终图像。 - 置信度筛选和掩码更新与论文中的迭代解码一致。
- 迭代解码逻辑保持不变,使用优化后的
4. 注意事项
- 预训练模型路径
- 需要替换
"path_to_pretrained_vqgan"为实际的 VQGAN 模型路径,例如 Hugging Face 的模型 ID 或本地文件。
- 需要替换
- 计算资源
- 训练需要多 GPU 支持,推理可在单 GPU 上运行。
- 扩展性
- 可添加类条件 embedding 或注意力掩码以支持更复杂的任务。
总结
优化后的代码用预训练 VQGAN 替换了简化的 VQ-VAE,实现了真实的 codebook 查找;用自定义的双向 Transformer 替代了 ViT,更贴近 MaskGIT 的设计需求。这些改进使代码更接近论文中的实现,同时保持了可读性和扩展性。
Mask embedding解析
在 MaskGIT 的 BidirectionalTransformer 类中,以下代码片段是前向传播中将输入 token 转换为 embedding 的关键部分:
# 将 token 转换为 embedding
token_emb = self.token_embedding(tokens) # [B, N, embed_dim]
mask_emb = self.mask_token.expand(B, N, -1) # [B, N, embed_dim]
input_emb = torch.where(mask.unsqueeze(-1) == 1, mask_emb, token_emb) # 掩盖位置用 [MASK]
input_emb = input_emb + self.pos_embedding # 加上位置编码
这部分代码实现了 MaskGIT 的掩码机制,并为 Transformer 的输入准备了 embedding。以下是对每一行代码的详细解释,特别是掩码(mask)如何工作以及 embedding 的具体形式。
1. token_emb = self.token_embedding(tokens)
-
输入:
tokens: 一个形状为[B, N]的张量,其中:B是批量大小(batch size),表示同时处理的图像数量。N是 token 序列长度(例如,对于 256×256 图像压缩为 16×16 的 token 网格,( N = 16 × 16 = 256 N = 16 \times 16 = 256 N=16×16=256))。- 每个元素是 VQ-VAE codebook 中的索引(整数),范围为
[0, codebook_size-1](例如 0 到 1023)。
self.token_embedding: 一个nn.Embedding层,定义为nn.Embedding(codebook_size, embed_dim),将离散的 token 索引映射为连续的 embedding 向量。
-
操作:
self.token_embedding(tokens)将每个 token 索引转换为一个embed_dim维的向量(例如embed_dim=768)。- 这是通过查找_BOOTSTRAP嵌入了一个查找表(lookup table)完成的,输入索引映射到预训练的 embedding 向量。
-
输出:
token_emb: 形状为[B, N, embed_dim]的张量,表示每个 token 的 embedding。例如,如果B=1,N=256,embed_dim=768,则输出是[1, 256, 768]的张量。
-
解释:
- 这一步将离散的 token(例如
[0, 5, 123, ...])转换为连续的向量表示(例如[[0.1, -0.2, ...], [0.5, 0.3, ...], ...]),为后续的 Transformer 处理准备输入。 - 这些 embedding 是可学习的参数,在训练过程中通过梯度下降优化。
- 这一步将离散的 token(例如
2. mask_emb = self.mask_token.expand(B, N, -1)
-
输入:
self.mask_token: 一个形状为[1, 1, embed_dim]的可学习参数,表示[MASK]token 的 embedding(例如[1, 1, 768]的随机初始化向量)。
-
操作:
.expand(B, N, -1)将self.mask_token扩展为形状[B, N, embed_dim]的张量。-1表示保持最后一维(embed_dim)不变。- 扩展操作不会创建新数据,而是通过广播(broadcasting)重复使用
self.mask_token的值。
-
输出:
mask_emb: 形状为[B, N, embed_dim]的张量,其中每个位置的值都等于self.mask_token的 embedding。例如,如果B=1,N=256, 输出是[1, 256, 768],所有 256 个位置的 embedding 都相同。
-
解释:
- 这一步为所有可能被掩盖的位置准备了一个统一的
[MASK]表示。self.mask_token是一个特殊的 embedding,类似于 BERT 中的[MASK]token,表示未知或待预测的 token。
- 这一步为所有可能被掩盖的位置准备了一个统一的
3. input_emb = torch.where(mask.unsqueeze(-1) == 1, mask_emb, token_emb)
-
输入:
mask: 形状为[B, N]的二值张量,值为 0 或 1。1表示该位置被掩盖,需预测。0表示该位置保留原始 token。
mask.unsqueeze(-1): 将mask从[B, N]扩展为[B, N, 1],在最后一个维度增加一个大小为 1 的轴,以便与[B, N, embed_dim]的张量广播兼容。mask.unsqueeze(-1) == 1: 一个布尔张量,形状为[B, N, 1],值为True(掩盖位置)或False(非掩盖位置)。mask_emb: 形状为[B, N, embed_dim],掩盖位置的 embedding。token_emb: 形状为[B, N, embed_dim],原始 token 的 embedding。
-
操作:
torch.where(condition, x, y): 根据条件选择值。- 如果
mask.unsqueeze(-1) == 1为True(即掩盖位置),选择mask_emb的对应值。 - 否则,选择
token_emb的对应值。
- 如果
- 由于广播机制,
[B, N, 1]的布尔张量会自动扩展为[B, N, embed_dim],对每一维embed_dim应用相同的掩码逻辑。
-
输出:
input_emb: 形状为[B, N, embed_dim]的张量,其中掩盖位置填充了mask_emb的值,非掩盖位置保留token_emb的值。
-
解释:
- 这一步实现了掩码机制的核心逻辑:将输入中的某些 token 替换为
[MASK],以模拟训练时的“填空”任务。 - 例如,如果
tokens = [0, 5, 123],mask = [0, 1, 0]:token_emb = [emb_0, emb_5, emb_123]mask_emb = [mask_emb, mask_emb, mask_emb]input_emb = [emb_0, mask_emb, emb_123]
- 这一步实现了掩码机制的核心逻辑:将输入中的某些 token 替换为
4. input_emb = input_emb + self.pos_embedding
-
输入:
input_emb: 形状为[B, N, embed_dim],经过掩码处理后的 embedding。self.pos_embedding: 形状为[1, N, embed_dim]的可学习参数,表示每个 token 位置的编码。
-
操作:
- 逐元素相加,通过广播将
self.pos_embedding从[1, N, embed_dim]扩展为[B, N, embed_dim]。
- 逐元素相加,通过广播将
-
输出:
input_emb: 形状仍为[B, N, embed_dim],但每个位置的 embedding 现在包含了位置信息。
-
解释:
- Transformer 没有固有的序列顺序感知能力,位置编码通过为每个 token 添加独特的位置信息解决这一问题。
- 在 MaskGIT 中,位置编码尤为重要,因为图像 token 是 2D 网格(例如 16×16)展平后的 1D 序列,位置编码帮助模型捕捉空间关系。
掩码如何工作?
-
掩码的角色:
mask是一个二值张量,控制哪些 token 被替换为[MASK]。- 在训练中,
mask是随机生成的(见train_maskgit中的掩码采样),模拟推理时从全掩码到逐步减少掩码的过程。 - 在推理中,
mask从全 1 开始(全掩码),每轮根据置信度更新(见infer_maskgit)。
-
工作原理:
- 对于
mask=1的位置,input_emb使用mask_emb,表示该位置的 token 需要预测。 - 对于
mask=0的位置,input_emb保留token_emb,表示该位置已知,供上下文使用。 - Transformer 基于
input_emb的全局上下文预测所有位置的 token,但损失只计算掩盖位置(见训练代码中的masked_logits)。
- 对于
Embedding 是怎么样的?
-
形式:
- 每个 embedding 是一个
embed_dim维的浮点向量(例如 768 维),初始随机生成,在训练中优化。 token_emb: 从nn.Embedding查表得到,每个 codebook 索引对应一个独特的向量。mask_emb: 一个固定的向量,所有掩盖位置共享,表示未知状态。pos_embedding: 一个位置相关的向量集,每个 token 位置有一个独特的编码。
- 每个 embedding 是一个
-
例子:
- 假设
tokens = [0, 5],mask = [0, 1],embed_dim = 3:token_emb = [[0.1, -0.2, 0.3], [0.5, 0.4, -0.1]]mask_emb = [[0.0, 0.2, -0.3], [0.0, 0.2, -0.3]]input_emb = [[0.1, -0.2, 0.3], [0.0, 0.2, -0.3]](掩码后)pos_embedding = [[0.01, 0.02, 0.03], [0.04, 0.05, 0.06]]- 最终
input_emb = [[0.11, -0.18, 0.33], [0.04, 0.25, -0.24]]
- 假设
-
意义:
- Embedding 将离散 token 转化为连续表示,供 Transformer 处理。
- 掩码机制通过
[MASK]引入不确定性,训练模型预测能力。 - 位置编码保留空间信息,确保生成符合图像结构。
总结
这段代码通过 token_embedding 和 mask_token 将 token 转换为 embedding,使用 torch.where 实现掩码替换,最后加上 pos_embedding 为 Transformer 提供位置信息。掩码机制模拟了“填空”任务,embedding 则是模型理解和生成的基础表示。这正是 MaskGIT MVTM 的核心所在,与 BERT 的 MLM 有异曲同工之妙,但适配了图像的空间特性。
后记
2025年3月24日18点40分于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









