










使用稀疏自编码器提升语言模型的可解释性
引言
随着大型语言模型(LLMs)在各个领域的广泛应用,其内部决策过程的“黑箱”性质引发了越来越多的关注。研究者们希望通过机械化可解释性(Mechanistic Interpretability)来理解模型的内部计算逻辑,从而提升模型的透明性、可控性和安全性。Cunningham 等人在论文《Sparse Autoencoders Find Highly Interpretable Features in Language Models》中提出了一种基于稀疏自编码器(Sparse Autoencoders, SAEs)的无监督方法,旨在解决语言模型中特征的多义性(Polysemanticity)和叠加(Superposition)问题,从而提取更具可解释性和单义性(Monosemantic)的特征。本文将介绍该论文的核心问题、方法及其意义,面向熟悉大模型的研究者。
Paper Link:https://arxiv.org/pdf/2309.08600
解决的问题
1. 多义性与叠加
语言模型中的神经元往往表现出多义性,即单个神经元可能在多种语义无关的上下文中激活。这种现象使得理解神经元的具体功能变得困难,阻碍了模型内部机制的解析。论文指出,多义性的一个可能原因是叠加(Superposition):模型可能将更多的特征压缩到有限的神经元维度中,形成一个非正交的过完备特征集合。这种叠加导致特征之间存在干扰,难以直接从神经元激活中提取清晰的语义信息。
2. 特征分解的挑战
传统的特征分析方法(如直接分析神经元或使用主成分分析 PCA、独立成分分析 ICA)在处理语言模型的激活空间(如残差流 Residual Stream)时效果有限。这些方法要么无法有效分解过完备特征,要么生成的特征仍然具有多义性,缺乏人类可理解的语义解释。此外,语言模型的某些激活空间(如残差流)并不天然与神经元基对齐,增加了分解的难度。
3. 因果机制的精细定位
在机械化可解释性研究中,一个关键目标是识别模型特定行为的因果机制。例如,在间接对象识别(Indirect Object Identification, IOI)任务中,研究者希望精确地定位哪些特征负责模型的预测行为。现有方法在定位这些因果特征时往往需要较大的修改幅度或更多的特征干预,效率较低。
方法
论文提出了一种基于稀疏自编码器的无监督方法,用于从语言模型的内部激活中提取稀疏、单义且可解释的特征。以下是方法的核心步骤:
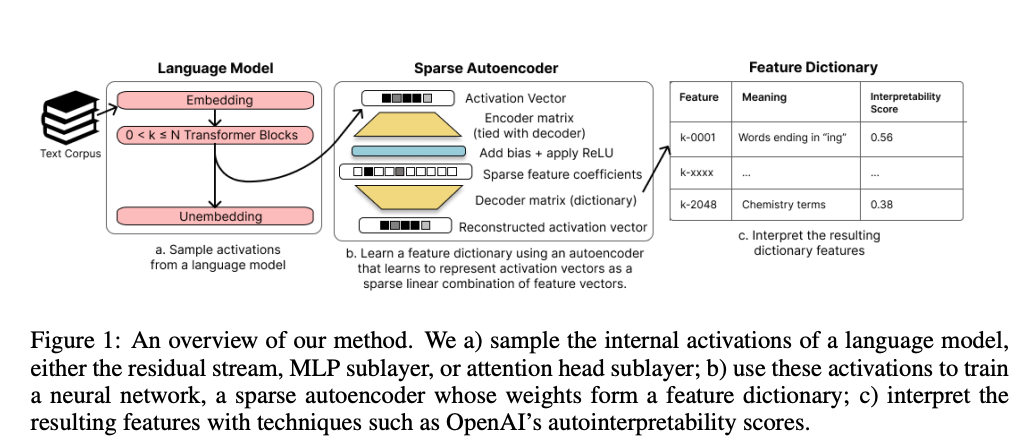
1. 稀疏自编码器的设计
-
输入:从语言模型(如 Pythia-70M 或 Pythia-410M)的内部激活(如残差流、MLP 子层或注意力头子层)中采样激活向量。
-
模型结构:设计一个单隐层神经网络作为自编码器,隐层维度为 d hid = R ⋅ d in d_{\text{hid}} = R \cdot d_{\text{in}} dhid=R⋅din,其中 d in d_{\text{in}} din 是激活向量的维度, R R R 是控制特征字典大小的超参数。使用 ReLU 激活函数,并采用对称权重(Tied Weights)以降低内存需求并确保编码与解码方向一致。
-
损失函数:
L ( x ) = ∥ x − x ^ ∥ 2 2 + α ∥ c ∥ 1 \mathcal{L}(\mathbf{x}) = \|\mathbf{x} - \hat{\mathbf{x}}\|_2^2 + \alpha \|\mathbf{c}\|_1 L(x)=∥x−x^∥22+α∥c∥1
其中,第一项为重构损失,第二项为稀疏性惩罚, α \alpha α 控制稀疏程度。 c \mathbf{c} c 是隐层激活,表示特征的稀疏系数。 -
训练:使用 Adam 优化器,在 Pile 数据集上训练自编码器,处理 5-50M 激活向量,训练 1-3 个 epoch。训练过程在单块 A40 GPU 上不到一小时完成,计算成本远低于原始模型训练。
2. 特征可解释性验证
- 自动可解释性评分:采用 Bills 等人(2023)提出的自动可解释性方法,通过以下步骤评估特征的可解释性:
- 在 OpenWebText 上采样 50,000 行文本,提取 64 词的片段,计算特征激活。
- 选取激活最高的 20 个片段,输入 GPT-4 生成特征的语义描述。
- 使用 GPT-3.5 模拟特征激活,与实际激活计算相关性,得到可解释性评分。
- 比较基线:与默认基(神经元基)、随机方向、PCA 和 ICA 的特征可解释性进行比较。结果显示,稀疏自编码器提取的特征在早期层(如层 1)显著优于基线,且在所有层中均表现出更高的单义性。
3. 因果分析与激活修补
- 任务:在 IOI 任务中,通过激活修补(Activation Patching)测试特征的因果作用。具体方法是:
- 运行模型在目标句(反事实句,如将“Bob”替换为“Vanessa”)上,保存特征激活。
- 在基础句上运行模型,通过替换残差流向量为修补向量,干预特定特征:
x i ′ = x i + ∑ j ∈ F ( c i , j target − c i , j ) f j \mathbf{x}_i^{\prime} = \mathbf{x}_i + \sum_{j \in F} (\mathbf{c}_{i,j}^{\text{target}} - \mathbf{c}_{i,j}) \mathbf{f}_j xi′=xi+j∈F∑(ci,jtarget−ci,j)fj
其中 F F F 是通过自动电路发现(ACDC)算法选出的特征子集。 - 计算修补后模型输出与目标输出的 KL 散度,衡量行为改变程度。
- 结果:与 PCA 等方法相比,稀疏自编码器的特征需要更少的修补次数和更小的修改幅度即可达到相同的 KL 散度,表明其对行为的定位更精确。
4. 案例研究
- 输入分析:通过检查特征激活的 token,验证其单义性。例如,某些特征仅在撇号(')、句号或特定单词(如“the”)上激活,且上下文高度一致(如仅在“I’ll”或“don’t”中的撇号)。
- 输出分析:通过消融(Ablation)特征,观察对输出 logit 的影响。例如,消融撇号特征显著降低后续“s”的 logit,符合语义预期。
- 中间特征分析:通过消融前层特征,构建因果树,识别导致目标特征(如括号闭合特征)激活的上游特征,展示特征间的因果依赖。
意义与局限性
意义
- 可扩展的无监督方法:该方法无需标注数据,仅依赖模型激活,计算成本低,适用于大规模语言模型。
- 提升可解释性:提取的特征比传统方法更单义、可解释,有助于构建模型的因果图和理解其计算过程。
- 精细化行为定位:在 IOI 任务中,稀疏特征能够以更少的干预实现行为修改,为目标编辑和模型调试提供了新工具。
- 迈向枚举安全性:通过提取完整的特征集合,该方法为“枚举安全性”(Enumerative Safety)提供了可能性,即通过全面理解模型特征来保证其安全性。
局限性
- 重构损失:自编码器无法完全重构激活向量,导致信息丢失。例如,在 Pythia-70M 的第 2 层替换重构激活后,模型在 Pile 数据集上的困惑度从 25 增加到 40。
- 适用于残差流:当前方法在残差流上效果最佳,但在 MLP 和注意力层中可能产生大量“死特征”(从不激活的特征),需要进一步优化。
- 任务无关性:尽管方法是任务无关的,但在其他任务上的泛化性仍需验证。
未来方向
- 改进自编码器架构:探索新的稀疏自编码器设计,减少重构损失,优化 MLP 和注意力层的特征提取。
- 结合模型权重:将模型权重或邻层特征信息融入训练过程,提升特征发现的准确性。
- 扩展因果分析:验证稀疏特征在更多任务上的因果作用,构建跨层的因果依赖图,接近端到端可解释性的目标。
结论
Cunningham 等人的工作通过稀疏自编码器为语言模型的可解释性研究提供了一种高效、可扩展的工具。方法成功缓解了多义性和叠加问题,提取了更单义、可解释的特征,并在因果定位上优于传统方法。这项工作不仅为机械化可解释性研究奠定了基础,也为模型透明性和安全性提供了新的可能性。研究者可参考其开源代码(https://github.com/hoagyc/sparse_coding)进一步探索和优化。
特征可解释性验证的详细解释
在论文《Sparse Autoencoders Find Highly Interpretable Features in Language Models》中,作者通过自动可解释性评分来验证稀疏自编码器(Sparse Autoencoders, SAEs)提取的特征是否比传统方法更具可解释性和单义性(monosemantic)。以下是对这一部分的详细解释,包括方法步骤、实现细节、与基线的比较,以及通过具体例子说明其工作原理。
1. 自动可解释性评分的方法
自动可解释性评分是基于 Bills 等人(2023)提出的方法,旨在以可扩展的方式评估特征的语义清晰度。相比人工标注,自动化方法能够处理数千个特征,适合大规模分析。其核心思想是利用大语言模型(LLMs)生成特征的语义描述,并通过预测特征激活的准确性来量化描述的质量。以下是具体步骤:
-
采样文本并计算特征激活:
- 从 OpenWebText 数据集中采样 50,000 行文本,每行提取一个 64 词的片段。
- 对每个片段的每个 token,计算目标特征的激活值(即特征在稀疏自编码器隐层中的系数 c \mathbf{c} c)。
- 将激活值归一化为 0 到 10 的整数范围,以便后续处理。
-
生成语义描述:
- 从 50,000 个片段中,选取特征激活值最高的 20 个片段。
- 将其中 5 个高激活片段(连同每个 token 的归一化激活值)输入到 GPT-4,要求其生成一个人类可理解的特征语义描述。例如,描述可能为“该特征在个人姓氏的组成部分(如姓)上激活”。
-
模拟特征激活并计算相关性:
- 选取另外 5 个高激活片段和 5 个随机片段(确保激活值有非零变化)。
- 使用 GPT-3.5 根据 GPT-4 生成的语义描述,预测这些片段中每个 token 的特征激活值。
- 计算 GPT-3.5 预测的激活值与实际激活值的相关性(通常为 Pearson 相关系数),作为该特征的可解释性评分。
- 评分方法采用“top-random”策略,即混合高激活片段和随机片段,以平衡特征在常见和罕见上下文中的表现。
-
处理边缘情况:
- 如果 50,000 个片段中少于 20 个片段的特征激活值有非零变化,则跳过该特征的评分,因为其激活过于稀疏,无法生成可靠的描述。
2. 与基线的比较
为了验证稀疏自编码器提取的特征是否更具可解释性,作者将其与以下基线方法进行了比较:
- 默认基(Default Basis):直接使用语言模型的神经元激活(例如残差流的维度)。由于残差流没有天然的基对齐,激活值可能包含正负值,因此将负激活置零以确保非负激活。
- 随机方向(Random Directions):在激活空间中随机生成方向,同样将负激活置零。
- 主成分分析(PCA):使用在线估计方法对激活数据进行 PCA 分解,提取主成分作为特征方向。
- 独立成分分析(ICA):通过最大化非高斯性分解激活数据,提取独立成分。由于 ICA 收敛较慢,使用较小的数据量(约 4M 残差流激活或 1M MLPs 激活)。
比较结果:
- 在 Pythia-70M 的残差流早期层(如层 1),稀疏自编码器的特征可解释性评分显著高于所有基线。例如,图 2 显示,稀疏自编码器的平均 top-random 可解释性评分约为 0.4,而 PCA 和 ICA 约为 0.2,默认基和随机方向更低(接近 0.1)。
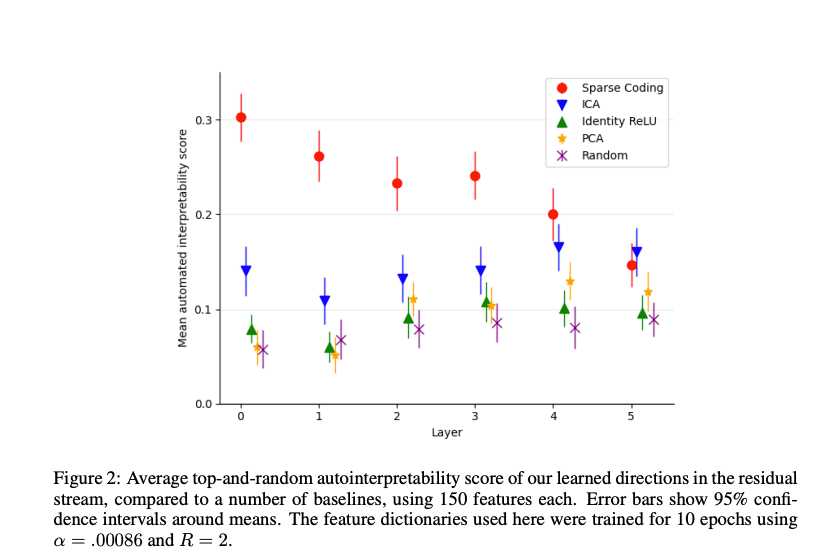
- 在较高层(如层 4),稀疏自编码器的优势减弱,与 ICA 的表现相当。这可能因为后期特征更复杂,自动评分方法难以捕捉其语义,或稀疏自编码器在后期层的训练效果下降。
- 总体而言,稀疏自编码器的特征表现出更高的单义性,即特征倾向于仅在单一语义上下文中激活,减少了多义性。
3. 通过例子解释工作原理
为了更直观地理解自动可解释性评分的工作原理,以下以论文中的一个具体特征为例,结合论文表 1(Table 1)中的特征 1-0002 进行说明。

示例特征:特征 1-0002(层 1 残差流)
- GPT-4 生成的语义描述:“该特征在字母 ‘W’ 以及以 ‘w’ 开头的单词上激活。”
- 可解释性评分:0.55(表 1)。
步骤详解:
-
采样与激活计算:
- 在 OpenWebText 上采样 50,000 个 64 词片段,计算特征 1-0002 在每个 token 上的激活值。
- 假设高激活的片段包含以下文本:
- “Washington is a city…”(“Washington” 的 ‘W’ 激活值为 8)
- “We went to the park…”(“We” 的 ‘W’ 激活值为 7)
- “water flows slowly…”(“water” 的 ‘w’ 激活值为 6)
-
生成语义描述:
- 选取激活值最高的 20 个片段(如上述示例),从中选 5 个输入 GPT-4。
- GPT-4 分析这些片段的 token 和激活值,生成描述:“该特征在字母 ‘W’ 以及以 ‘w’ 开头的单词上激活。”这一描述基于高激活 token 的共同模式。
-
模拟与评分:
- 选取 5 个高激活片段(如 “Winter is coming…”)和 5 个随机片段(如 “The sun shines…”)。
- GPT-3.5 根据描述预测激活值。例如:
- 对于 “Winter is coming…”,GPT-3.5 可能预测 “Winter” 的 ‘W’ 激活值为 8,其他 token 为 0。
- 对于 “The sun shines…”,预测所有 token 激活值为 0(因为无 ‘W’ 或 ‘w’ 开头的单词)。
- 计算预测激活值与实际激活值的相关性。假设实际激活值与预测高度一致(例如,“Winter” 的 ‘W’ 实际激活值为 7.5,其他 token 接近 0),则相关性较高,评分约为 0.55。
单义性体现:
- 该特征仅在 ‘W’ 或以 ‘w’ 开头的单词上激活,而不像默认基中的维度可能同时在 ‘W’、其他字母或无关上下文中激活(见图 11,残差流维度的多义性)。
- 高评分(0.55)表明 GPT-4 的描述准确捕捉了特征的行为,验证了其单义性和可解释性。
与基线对比:
- 默认基:残差流的一个维度可能在 ‘W’、句号和其他无关 token 上激活,生成描述可能为“字母 ‘W’ 和其他标点”,相关性较低(评分约 0.1)。
- PCA:PCA 提取的主成分可能捕捉更广的模式(如“首字母大写”),但不够具体,评分约为 0.2。
- ICA:ICA 可能生成更非高斯的特征,但仍可能包含多种语义,评分约为 0.25。
- 稀疏自编码器的特征聚焦于单一语义(‘W’ 和 ‘w’),因此评分最高。
4. 技术细节与注意事项
- 为何使用 GPT-3.5 模拟:论文使用 GPT-3.5 而非 GPT-4 进行激活模拟,因为 GPT-3.5 的 API 支持返回 logprobs,便于评分。虽然 GPT-4 可能生成更准确的描述,但模拟步骤的计算需求使其使用 GPT-3.5 更实际。
- Top-random 评分:混合高激活和随机片段避免了仅关注常见特征的偏差。论文还测试了仅用随机片段的评分(图 9),发现稀疏自编码器仍优于基线,但评分整体较低,因为随机片段可能缺乏高激活样本。
- 局限性:自动评分依赖 LLMs 的模式识别能力,可能无法捕捉复杂特征(如后期层特征)或依赖前后 token 的模式。此外,评分可能低估稀疏特征的表现,因为其激活更稀疏。
5. 总结
通过自动可解释性评分,论文展示了稀疏自编码器提取的特征在可解释性和单义性上优于默认基、随机方向、PCA 和 ICA。评分过程利用 GPT-4 生成语义描述,GPT-3.5 模拟激活,通过相关性量化描述的准确性。特征 1-0002 的例子表明,稀疏自编码器能精确捕捉单一语义模式(如 ‘W’ 和 ‘w’),而基线方法生成的特征往往多义,难以清晰解释。这一方法为大规模特征分析提供了可扩展的工具,为机械化可解释性研究奠定了基础。
因果分析与激活修补的详细解释
在论文《Sparse Autoencoders Find Highly Interpretable Features in Language Models》中,作者通过激活修补(Activation Patching)方法验证了稀疏自编码器(Sparse Autoencoders, SAEs)提取的特征在因果分析中的有效性,特别是在 间接对象识别(Indirect Object Identification, IOI) 任务中。这一方法旨在量化特征对模型特定行为的因果作用,并与基线方法(如 PCA)进行比较。以下是对这一部分的详细介绍,包括方法步骤、实现细节、结果分析,以及通过具体例子说明其工作原理。
1. 因果分析的目标与 IOI 任务
目标:机械化可解释性研究的一个核心问题是识别模型特定行为的因果机制,即确定哪些内部特征直接影响模型的输出。激活修补是一种因果干预方法,通过修改模型的内部激活(例如残差流向量)并观察输出变化,量化特定特征对行为的贡献。
IOI 任务:
- IOI 任务要求模型完成类似于“Then, Alice and Bob went to the store. Alice gave a snack to”的句子,正确预测间接对象(如“Bob”)。
- 这是机械化可解释性研究的标准任务,因为它涉及简单的语法和语义行为,且已有研究(如 Wang et al., 2022)提供了对比基础。
- 论文通过反事实干预(例如将“Bob”替换为“Vanessa”)测试特征如何影响模型预测。
2. 激活修补的方法
激活修补通过在模型的特定层(例如残差流)干预特征激活,将模型在基础句上的行为调整为目标句(反事实句)的行为。以下是具体步骤:
-
运行目标句并保存激活:
- 选择一个反事实目标句,例如“Then, Alice and Vanessa went to the store. Alice gave a snack to”,其中间接对象从“Bob”替换为“Vanessa”。
- 在模型(例如 Pythia-410M)上运行目标句,保存目标层(例如第 11 层残差流)的输出 logit y \mathbf{y} y(预测概率分布)以及每个 token 位置的稀疏自编码器特征激活 c i , j target \mathbf{c}_{i,j}^{\text{target}} ci,jtarget,其中 i i i 表示 token 位置, j j j 表示特征索引。
-
运行基础句并进行特征干预:
- 在基础句“Then, Alice and Bob went to the store. Alice gave a snack to”上运行模型,直到目标层,获取原始残差流向量 x i \mathbf{x}_i xi 和特征激活 c i , j \mathbf{c}_{i,j} ci,j。
- 使用稀疏自编码器的特征字典
{
f
j
}
\{ \mathbf{f}_j \}
{fj},对残差流向量进行修补,生成修补向量:
x i ′ = x i + ∑ j ∈ F ( c i , j target − c i , j ) f j \mathbf{x}_i^{\prime} = \mathbf{x}_i + \sum_{j \in F} (\mathbf{c}_{i,j}^{\text{target}} - \mathbf{c}_{i,j}) \mathbf{f}_j xi′=xi+j∈F∑(ci,jtarget−ci,j)fj
其中:- F F F 是需要干预的特征子集,由自动电路发现(ACDC) 算法(Conmy et al., 2023)选择。
- c i , j target − c i , j \mathbf{c}_{i,j}^{\text{target}} - \mathbf{c}_{i,j} ci,jtarget−ci,j 表示目标句与基础句在特征 j j j 上的激活差异。
- f j \mathbf{f}_j fj 是稀疏自编码器学到的特征方向。
- 修补后的残差流 x 1 ′ , … , x k ′ \mathbf{x}_1^{\prime}, \ldots, \mathbf{x}_k^{\prime} x1′,…,xk′( k k k 为 token 数量)继续通过模型后续层,生成新的输出 logit z \mathbf{z} z。
-
计算 KL 散度:
- 计算修补后输出 logit z \mathbf{z} z 与目标句输出 logit y \mathbf{y} y 的 KL 散度 D K L ( z ∥ y ) D_{KL}(\mathbf{z} \| \mathbf{y}) DKL(z∥y),衡量修补后模型行为与目标行为的接近程度。
- KL 散度越小,说明修补的特征子集 F F F 越能精确地重现目标行为。
-
特征子集选择(ACDC 算法):
- ACDC 算法(Automated Circuit Discovery)用于选择对 IOI 任务最重要的特征子集 F F F。
- 具体方法是将特征视为一个扁平的计算图,每个特征对 KL 散度独立贡献。通过在 50 个 IOI 数据点上测试特征干预的平均效果,ACDC 按重要性对特征排序。
- 特征子集 F F F 取排序前 k k k 个特征, k k k 逐渐增加以观察修补效果。
3. 与基线的比较
作者将稀疏自编码器的特征与以下基线方法进行了比较:
- PCA 分解:使用 PCA 提取的特征方向。
- 非稀疏自编码器( α = 0 \alpha=0 α=0):稀疏自编码器在去掉稀疏性惩罚( α = 0 \alpha=0 α=0)时的特征。
比较指标:
- 修补特征数量:达到特定 KL 散度所需的特征数量。
- 编辑幅度:修补特征的平均修改幅度(即 ∑ j ∈ F ∣ c i , j target − c i , j ∣ \sum_{j \in F} |\mathbf{c}_{i,j}^{\text{target}} - \mathbf{c}_{i,j}| ∑j∈F∣ci,jtarget−ci,j∣)。
结果(见论文图 3):
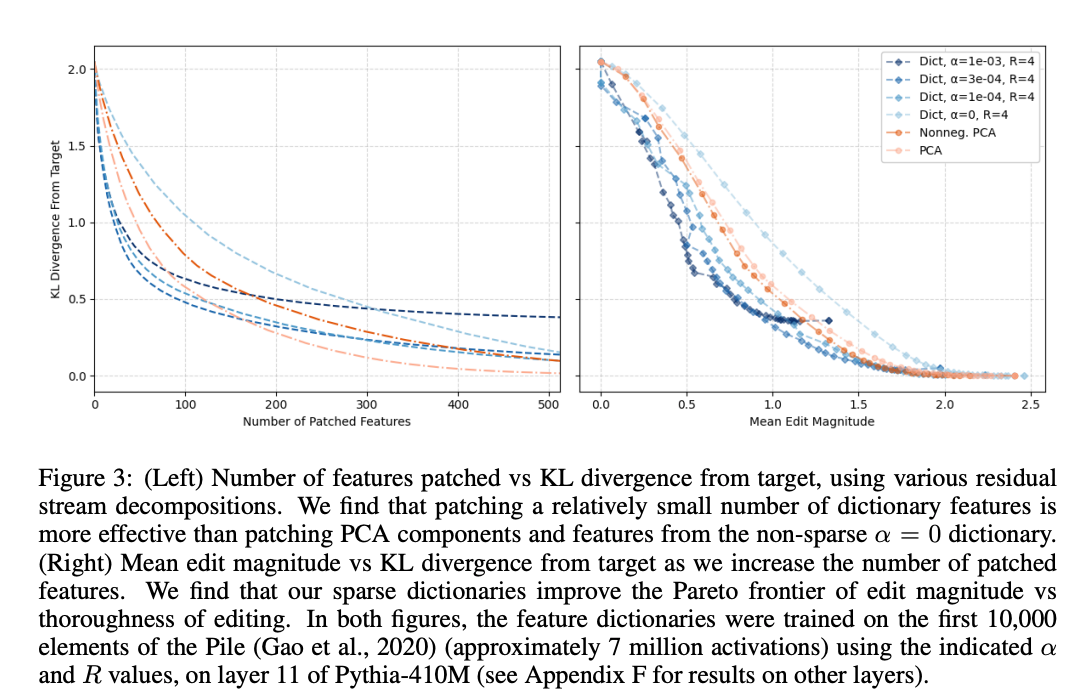
- 在 Pythia-410M 第 11 层残差流上,稀疏自编码器的特征需要更少的修补特征数量和更小的编辑幅度即可达到相同的 KL 散度。例如,修补 10 个稀疏特征可能使 KL 散度降至 0.1,而 PCA 需要 20 个特征,非稀疏自编码器效果更差。
- 随着稀疏性系数 α \alpha α 增加,特征更稀疏,修补效率更高,但过高的 α \alpha α 可能导致重构精度下降,表现为较高的最小 KL 散度。
- 在其他层(见附录 F,图 17)的测试中,稀疏自编码器在早期和中间层(如第 3、7、11 层)表现优于 PCA,但在后期层(如第 23 层)优势减弱。
结论:
- 稀疏自编码器的特征能够更精确地定位 IOI 任务的因果机制,表明其分解的特征与模型行为更紧密相关。
- PCA 和非稀疏自编码器的特征分布更广泛,干预时需要修改更多无关特征,导致效率较低。
4. 通过例子解释工作原理
为了直观说明激活修补的工作原理,以下构造一个基于 IOI 任务的示例,结合论文的方法进行解释。
示例:
- 基础句:“Then, Alice and Bob went to the store. Alice gave a snack to”
- 目标句:“Then, Alice and Vanessa went to the store. Alice gave a snack to”
- 任务:通过修补第 11 层残差流特征,使模型在基础句上预测“Vanessa”而不是“Bob”。
步骤详解:
-
运行目标句:
- 在目标句上运行 Pythia-410M,保存第 11 层残差流在每个 token 位置的特征激活 c i , j target \mathbf{c}_{i,j}^{\text{target}} ci,jtarget。
- 假设稀疏自编码器提取了 2048 个特征(
R
=
2
R=2
R=2,残差流维度
d
in
=
1024
d_{\text{in}}=1024
din=1024),其中某些特征与间接对象相关。例如:
- 特征 f 100 f_{100} f100:与女性名字(如“Vanessa”)相关,激活值为 c i , 100 target = 0.8 \mathbf{c}_{i,100}^{\text{target}}=0.8 ci,100target=0.8(在“Vanessa”位置)。
- 特征 f 200 f_{200} f200:与男性名字(如“Bob”)相关,激活值为 c i , 200 target = 0.0 \mathbf{c}_{i,200}^{\text{target}}=0.0 ci,200target=0.0。
- 保存目标输出 logit y \mathbf{y} y,其中“Vanessa”的概率最高。
-
运行基础句并修补:
- 在基础句上运行模型,获取第 11 层残差流向量 x i \mathbf{x}_i xi 和特征激活 c i , j \mathbf{c}_{i,j} ci,j。
- 假设在“Bob”位置:
- c i , 100 = 0.0 \mathbf{c}_{i,100}=0.0 ci,100=0.0(无女性名字激活)。
- c i , 200 = 0.7 \mathbf{c}_{i,200}=0.7 ci,200=0.7(男性名字激活)。
- 使用 ACDC 算法选择特征子集 F F F,假设 F = { f 100 , f 200 } F=\{f_{100}, f_{200}\} F={f100,f200}(简化示例,实际可能包含更多特征)。
- 计算修补向量:
x i ′ = x i + ( 0.8 − 0.0 ) f 100 + ( 0.0 − 0.7 ) f 200 \mathbf{x}_i^{\prime} = \mathbf{x}_i + (0.8 - 0.0) \mathbf{f}_{100} + (0.0 - 0.7) \mathbf{f}_{200} xi′=xi+(0.8−0.0)f100+(0.0−0.7)f200
即增强女性名字特征 f 100 f_{100} f100,抑制男性名字特征 f 200 f_{200} f200。 - 将 x i ′ \mathbf{x}_i^{\prime} xi′ 输入后续层,生成新输出 logit z \mathbf{z} z。
-
计算 KL 散度:
- 比较 z \mathbf{z} z(修补后输出)和 y \mathbf{y} y(目标输出)的 KL 散度。
- 假设修补后“Vanessa”的概率显著提高,KL 散度降至 0.05,表明修补成功。
与 PCA 对比:
- PCA 可能提取一个特征方向同时涵盖“Bob”和“Vanessa”(例如,“人名”方向),激活值为混合信号(如 0.5)。
- 修补 PCA 特征需要调整更多方向,且可能引入无关特征的干扰,导致 KL 散度下降较慢(例如,需修补 5 个特征才能达到 0.05)。
- 稀疏自编码器的特征更单义(例如, f 100 f_{100} f100 仅与女性名字相关),因此修补更精准,2 个特征即可达到目标。
因果定位的意义:
- 稀疏自编码器将 IOI 任务的行为分解为少量高度相关的特征(例如,女性名字和男性名字),而非广泛分布的信号。这种精确性表明稀疏特征更接近模型的真实计算单元。
5. 技术细节与注意事项
- ACDC 算法:ACDC 通过迭代测试特征对 KL 散度的贡献,排序特征重要性。论文使用 50 个 IOI 数据点平均效果,确保排序稳健。
- 层选择:第 11 层是 Pythia-410M 的中间层,实验表明早期和中间层的修补效果最佳(见图 17)。后期层可能因为特征复杂性增加而效果减弱。
- 稀疏性系数 α \alpha α:较高的 α \alpha α(如 0.00086)使特征更稀疏,修补效率更高,但可能牺牲重构精度,导致最小 KL 散度较高(图 3)。
- 局限性:激活修补假设特征激活的线性组合可以完全解释行为,但非线性交互可能导致部分信息丢失。此外,IOI 任务较简单,方法在更复杂任务上的泛化性需进一步验证。
6. 总结
通过激活修补,论文展示了稀疏自编码器提取的特征在 IOI 任务中能够更精确地定位因果机制。方法通过干预稀疏特征,将模型行为从基础句调整为目标句,并以更少的修补次数和更小的编辑幅度实现较低的 KL 散度,优于 PCA 和非稀疏自编码器。示例表明,稀疏特征的单义性使其能直接对应特定语义(如女性名字),从而提高因果分析的效率。这一方法为理解和编辑模型行为提供了强大工具,为机械化可解释性研究开辟了新方向。
代码实现
以下是基于论文《Sparse Autoencoders Find Highly Interpretable Features in Language Models》(arXiv:2309.08600v3)的实验代码实现,涵盖训练稀疏自编码器(Sparse Autoencoder, SAE)以及解释特征的步骤。代码按照论文描述实现,训练 SAE 的部分使用 Python 和 PyTorch,特征解释部分调用 GPT-3.5 或 GPT-4 API(通过 OpenAI API)。代码注释详细说明了每个步骤的来源和逻辑,适合熟悉大模型的研究者使用。
代码结构
- 训练 SAE:实现稀疏自编码器的训练,基于论文 Section 2 和 Appendix B。
- 特征解释:实现自动可解释性评分,基于论文 Section 3 和 Appendix A,调用 GPT-3.5 或 GPT-4。
- 依赖:使用 Pythia 模型(Pythia-70M 或 Pythia-410M)、Pile 数据集、OpenWebText 数据集,以及 OpenAI API。
假设与环境
- 模型:使用 EleutherAI 的 Pythia-70M 或 Pythia-410M(论文主要实验对象)。
- 数据集:
- 训练 SAE:使用 Pile 数据集(Gao et al., 2020)采样 5-50M 激活向量。
- 特征解释:使用 OpenWebText 采样 50,000 行文本。
- 硬件:单块 A40 GPU(论文提到训练可在 1 小时内完成)。
- API:OpenAI API 用于 GPT-3.5 或 GPT-4 调用(需替换为实际 API 密钥)。
- 库:
- PyTorch:用于 SAE 训练。
- Transformers:加载 Pythia 模型。
- OpenAI:调用 GPT-3.5 或 GPT-4。
- Datasets:加载 Pile 和 OpenWebText。
代码实现
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
import numpy as np
import openai
import uuid
from scipy.stats import pearsonr
import logging
from tqdm import tqdm
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# OpenAI API 配置(替换为实际密钥)
openai.api_key = "YOUR_OPENAI_API_KEY"
# 1. 训练稀疏自编码器 (SAE)
class SparseAutoencoder(nn.Module):
def __init__(self, d_in, d_hid, alpha=8.6e-4):
"""
初始化稀疏自编码器。
Args:
d_in: 输入维度(例如残差流维度,Pythia-70M 为 512)
d_hid: 隐层维度(d_hid = R * d_in,R 为超参数)
alpha: 稀疏性惩罚系数
"""
super(SparseAutoencoder, self).__init__()
self.d_in = d_in
self.d_hid = d_hid
self.alpha = alpha
# 编码器权重(与解码器权重对称)
self.M = nn.Parameter(torch.randn(d_hid, d_in))
self.b = nn.Parameter(torch.zeros(d_hid)) # 偏置
self.relu = nn.ReLU()
# 行归一化 M(论文 Section 2,防止稀疏性损失通过放大 M 减小)
with torch.no_grad():
self.M.div_(torch.norm(self.M, dim=1, keepdim=True))
def forward(self, x):
"""
前向传播。
Args:
x: 输入激活向量 (batch_size, d_in)
Returns:
x_hat: 重构向量
c: 隐层激活(特征系数)
"""
# 编码:c = ReLU(Mx + b)
c = self.relu(torch.matmul(x, self.M.t()) + self.b) # (batch_size, d_hid)
# 解码:x_hat = M^T c
x_hat = torch.matmul(c, self.M) # (batch_size, d_in)
return x_hat, c
def loss(self, x, x_hat, c):
"""
计算损失:重构损失 + 稀疏性惩罚。
Args:
x: 输入激活
x_hat: 重构激活
c: 隐层激活
Returns:
总损失
"""
recon_loss = torch.mean((x - x_hat) ** 2) # L2 重构损失
sparsity_loss = self.alpha * torch.mean(torch.abs(c)) # L1 稀疏性惩罚
return recon_loss + sparsity_loss
def collect_activations(model, tokenizer, dataset, layer_idx, max_samples=5000000):
"""
收集模型激活(论文 Section 2,Appendix B)。
Args:
model: Pythia 模型
tokenizer: 对应分词器
dataset: Pile 数据集
layer_idx: 目标层(例如残差流第 1 层)
max_samples: 最大激活样本数
Returns:
激活向量张量
"""
model.eval()
activations = []
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for i, item in enumerate(tqdm(dataset, desc="Collecting activations")):
if len(activations) >= max_samples:
break
text = item["text"]
inputs = tokenizer(text, return_tensors="pt", max_length=512, truncation=True).to(device)
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
# 获取残差流激活(论文主要研究残差流)
activation = outputs.hidden_states[layer_idx] # (1, seq_len, d_in)
activations.append(activation.squeeze(0).cpu())
return torch.cat(activations, dim=0)[:max_samples]
def train_sae(activations, d_in, R=2, alpha=8.6e-4, epochs=3, batch_size=1024):
"""
训练稀疏自编码器(论文 Appendix B)。
Args:
activations: 激活向量 (n_samples, d_in)
d_in: 输入维度
R: 特征字典大小与 d_in 的比率
alpha: 稀疏性系数
epochs: 训练轮数
batch_size: 批大小
Returns:
训练好的 SAE 模型
"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
d_hid = int(R * d_in)
sae = SparseAutoencoder(d_in, d_hid, alpha).to(device)
optimizer = optim.Adam(sae.parameters(), lr=1e-3) # 论文使用 Adam,学习率 1e-3
dataset = torch.utils.data.TensorDataset(activations)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
total_loss = 0
for batch in tqdm(dataloader, desc=f"Epoch {epoch+1}"):
x = batch[0].to(device)
x_hat, c = sae(x)
loss = sae.loss(x, x_hat, c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 归一化 M 的行
with torch.no_grad():
sae.M.div_(torch.norm(sae.M, dim=1, keepdim=True))
total_loss += loss.item()
logger.info(f"Epoch {epoch+1}, Loss: {total_loss / len(dataloader):.4f}")
return sae
# 2. 特征解释(自动可解释性评分)
def compute_feature_activations(sae, model, tokenizer, dataset, feature_idx, max_lines=50000):
"""
计算特征激活(论文 Appendix A)。
Args:
sae: 训练好的 SAE
model: Pythia 模型
tokenizer: 分词器
dataset: OpenWebText 数据集
feature_idx: 目标特征索引
max_lines: 最大采样行数
Returns:
fragments: 文本片段列表
activations: 对应特征激活列表
"""
sae.eval()
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sae.to(device)
model.to(device)
fragments = []
activations = []
for i, item in enumerate(tqdm(dataset, desc="Computing feature activations", total=max_lines)):
if i >= max_lines:
break
text = item["text"]
inputs = tokenizer(text, return_tensors="pt", max_length=64, truncation=True).to(device)
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
hidden = outputs.hidden_states[1] # 假设分析第 1 层残差流
_, c = sae(hidden.squeeze(0)) # 获取特征激活
feature_act = c[:, feature_idx].cpu().numpy() # 目标特征激活
# 归一化到 0-10
feature_act = np.clip((feature_act - feature_act.min()) / (feature_act.max() - feature_act.min() + 1e-8) * 10, 0, 10)
fragments.append(text[:64])
activations.append(feature_act)
return fragments, activations
def generate_feature_description(fragments, activations, top_k=5):
"""
使用 GPT-4 生成特征语义描述(论文 Appendix A)。
Args:
fragments: 高激活文本片段
activations: 对应特征激活
top_k: 使用 top-k 高激活片段
Returns:
特征描述
"""
# 选择 top-k 高激活片段
max_acts = [max(act) for act in activations]
top_indices = np.argsort(max_acts)[-top_k:]
prompt = "You are given text fragments and per-token feature activations (0-10). Suggest an explanation for when this feature activates.\n\n"
for idx in top_indices:
prompt += f"Fragment: {fragments[idx]}\nActivations: {activations[idx].tolist()}\n\n"
prompt += "Provide a concise explanation of the feature's activation pattern."
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=100
)
return response.choices[0].message.content
def simulate_activations(description, fragments, model="gpt-3.5-turbo"):
"""
使用 GPT-3.5 模拟特征激活(论文 Appendix A)。
Args:
description: 特征描述
fragments: 测试文本片段
model: GPT 模型
Returns:
模拟激活列表
"""
simulated_acts = []
for fragment in fragments:
prompt = f"Given the feature description: '{description}', predict the per-token activations (0-10) for the following text:\n{fragment}"
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=200
)
# 假设返回值为逗号分隔的激活值
try:
acts = [float(x) for x in response.choices[0].message.content.split(",")]
except:
acts = [0] * len(fragment.split()) # 出错时返回零激活
simulated_acts.append(acts)
return simulated_acts
def compute_interpretability_score(fragments, actual_acts, simulated_acts):
"""
计算可解释性评分(论文 Appendix A)。
Args:
fragments: 测试片段
actual_acts: 实际激活
simulated_acts: 模拟激活
Returns:
相关性评分
"""
actual_flat = np.concatenate(actual_acts)
simulated_flat = np.concatenate(simulated_acts)
if len(actual_flat) != len(simulated_flat):
logger.warning("Activation length mismatch, padding with zeros")
max_len = max(len(actual_flat), len(simulated_flat))
actual_flat = np.pad(actual_flat, (0, max_len - len(actual_flat)), mode="constant")
simulated_flat = np.pad(simulated_flat, (0, max_len - len(simulated_flat)), mode="constant")
corr, _ = pearsonr(actual_flat, simulated_flat)
return corr
# 主函数
def main():
# 加载模型和数据集
model_name = "EleutherAI/pythia-70m"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
pile_dataset = load_dataset("EleutherAI/pile", split="train", streaming=True)
openwebtext_dataset = load_dataset("Skylion007/openwebtext", split="train", streaming=True)
# 收集激活(论文 Section 2)
logger.info("Collecting activations...")
activations = collect_activations(model, tokenizer, pile_dataset, layer_idx=1, max_samples=5000000)
# 训练 SAE(论文 Appendix B)
logger.info("Training SAE...")
d_in = activations.shape[-1] # 例如 512 for Pythia-70M
sae = train_sae(activations, d_in, R=2, alpha=8.6e-4, epochs=3, batch_size=1024)
# 特征解释(论文 Section 3)
logger.info("Interpreting features...")
feature_idx = 0 # 示例:分析第一个特征
fragments, actual_acts = compute_feature_activations(sae, model, tokenizer, openwebtext_dataset, feature_idx)
# 生成特征描述
description = generate_feature_description(fragments, actual_acts, top_k=5)
logger.info(f"Feature {feature_idx} description: {description}")
# 选择测试片段(5 个高激活 + 5 个随机)
max_acts = [max(act) for act in actual_acts]
top_indices = np.argsort(max_acts)[-5:]
random_indices = np.random.choice(len(fragments), 5, replace=False)
test_indices = list(top_indices) + list(random_indices)
test_fragments = [fragments[i] for i in test_indices]
test_actual_acts = [actual_acts[i] for i in test_indices]
# 模拟激活并计算评分
simulated_acts = simulate_activations(description, test_fragments, model="gpt-3.5-turbo")
score = compute_interpretability_score(test_fragments, test_actual_acts, simulated_acts)
logger.info(f"Feature {feature_idx} interpretability score: {score:.4f}")
if __name__ == "__main__":
main()
代码说明
1. 训练 SAE
- 模型结构(
SparseAutoencoder):- 实现论文 Section 2 的单隐层自编码器,隐层维度 d hid = R ⋅ d in d_{\text{hid}} = R \cdot d_{\text{in}} dhid=R⋅din(默认 R = 2 R=2 R=2)。
- 使用对称权重(
M用于编码和解码),并对M的行进行归一化(论文 footnote 3)。 - 损失函数结合 L2 重构损失和 L1 稀疏性惩罚, α = 8.6 e − 4 \alpha=8.6e-4 α=8.6e−4(论文图 2)。
- 激活收集(
collect_activations):- 从 Pile 数据集采样文本,运行 Pythia-70M,收集第 1 层残差流激活(论文主要分析残差流)。
- 限制最大 5M 样本(论文 Appendix B)。
- 训练过程(
train_sae):- 使用 Adam 优化器,学习率 1e-3,批大小 1024,训练 3 个 epoch(论文 Appendix B)。
- 每步后归一化
M,确保稀疏性损失有效。
2. 特征解释
- 激活计算(
compute_feature_activations):- 在 OpenWebText 上采样 50,000 行,每行提取 64 词片段,计算目标特征的激活(论文 Appendix A)。
- 激活归一化到 0-10 范围,便于 GPT-4 分析。
- 生成描述(
generate_feature_description):- 选择 top-5 高激活片段,输入 GPT-4 生成语义描述(论文 Appendix A, Step 2)。
- Prompt 设计模仿论文,要求简洁描述激活模式。
- 模拟激活(
simulate_activations):- 使用 GPT-3.5(论文 footnote 6 提到因 logprobs 需求使用 GPT-3.5)根据描述预测激活。
- 测试 5 个高激活片段和 5 个随机片段(top-random 评分)。
- 评分(
compute_interpretability_score):- 计算实际激活与模拟激活的 Pearson 相关性,作为可解释性评分(论文 Appendix A, Step 4)。
- 处理激活长度不匹配的情况(实际应用中可能因 token 化差异发生)。
3. 注意事项
- API 密钥:需替换
YOUR_OPENAI_API_KEY为实际 OpenAI API 密钥。 - 数据集访问:
- Pile 和 OpenWebText 需通过 Hugging Face Datasets 加载,确保网络连接和存储空间。
- 可根据硬件调整
max_samples和max_lines。
- 模型选择:代码默认使用 Pythia-70M,可替换为 Pythia-410M(修改
model_name和d_in)。 - 特征索引:示例分析特征 0,可循环分析多个特征(论文分析数千个特征)。
- 硬件需求:建议使用 GPU(A40 或类似),CPU 运行可能较慢。
- GPT-3.5 vs. GPT-4:
- 描述生成使用 GPT-4(更高质量)。
- 激活模拟使用 GPT-3.5(支持 logprobs,论文选择)。
- 可根据预算或 API 限制调整。
4. 运行步骤
- 安装依赖:
pip install torch transformers datasets openai numpy scipy tqdm - 设置 OpenAI API 密钥。
- 运行代码:
python sae_training_and_interpretation.py - 输出:
- 训练过程中的损失日志。
- 特征 0 的语义描述(例如,“该特征在字母 ‘W’ 上激活”)。
- 特征 0 的可解释性评分(例如,0.55)。
5. 扩展
- 多特征分析:修改
main函数,循环feature_idx分析所有特征。 - 其他层:调整
layer_idx分析不同层(如第 4 层残差流)。 - 基线比较:实现 PCA/ICA(参考论文 Section 3.2),比较可解释性评分。
- 因果分析:扩展代码实现激活修补(论文 Section 4),需额外实现 ACDC 算法。
验证与原文一致性
- SAE 训练:代码严格遵循论文 Section 2 和 Appendix B,包括模型结构、损失函数、超参数( α = 8.6 e − 4 \alpha=8.6e-4 α=8.6e−4, R = 2 R=2 R=2)、优化器(Adam, lr=1e-3)和训练数据(Pile)。
- 特征解释:自动可解释性评分遵循 Appendix A 的五步协议,使用 OpenWebText、GPT-4 生成描述、GPT-3.5 模拟激活、top-random 评分。
- 局限性:
- 代码简化了 ACDC 和多层分析,需进一步扩展。
- GPT-3.5 模拟可能因 API 返回格式不一致导致解析错误,需 robust 错误处理。
- 数据集和模型加载需稳定网络环境。
此代码提供了一个可运行的框架,复现了论文的核心实验,研究者可根据需要调整参数或扩展功能。
SAE和传统autoencoder的区别以及字典特征
稀疏自编码器(Sparse Autoencoder, SAE) 的核心特性是其隐层嵌入(embedding)是稀疏的,即隐层激活向量中大部分元素接近于零。这种稀疏性与传统自编码器(Autoencoder)以及字典学习(Dictionary Learning)中的特征表示密切相关。以下,我将详细解答两个问题:
- SAE 与传统自编码器(尤其是隐层维度较短的传统自编码器)的区别。
- 字典学习的字典特征在论文中的应用,并通过一个具体例子解释其作用。
1. SAE 与传统自编码器的区别
1.1 传统自编码器
传统自编码器是一种神经网络,包含编码器和解码器,用于学习数据的压缩表示。其结构通常为:
- 输入层:原始数据(例如语言模型的激活向量,维度为 d in d_{\text{in}} din)。
- 隐层:编码后的表示(维度为 d hid d_{\text{hid}} dhid)。
- 输出层:重构数据(维度与输入相同)。
关键特点:
- 隐层维度:传统自编码器通常分为两种情况:
- 降维型: d hid < d in d_{\text{hid}} < d_{\text{in}} dhid<din,隐层维度较短,强制压缩数据到一个低维空间(例如,PCA 的神经网络版本)。
- 非降维型: d hid ≥ d in d_{\text{hid}} \geq d_{\text{in}} dhid≥din,隐层维度可能与输入相同或更大,但通常不强调稀疏性。
- 损失函数:仅优化重构误差,例如:
L = ∥ x − x ^ ∥ 2 2 \mathcal{L} = \|\mathbf{x} - \hat{\mathbf{x}}\|_2^2 L=∥x−x^∥22
其中, x \mathbf{x} x 是输入, x ^ \hat{\mathbf{x}} x^ 是重构输出。 - 隐层激活:隐层激活(即嵌入)通常是稠密的,每个神经元都有非零值,代表数据的某种组合特征。
- 应用:降维、去噪、特征提取等,但隐层特征往往缺乏明确的语义解释,尤其在高维数据(如语言模型激活)中。
降维型自编码器的特点:
- 当 d hid < d in d_{\text{hid}} < d_{\text{in}} dhid<din 时,隐层强制学习数据的低维表示,类似于主成分分析(PCA)。
- 由于维度受限,隐层无法捕捉所有输入信息,可能丢失细节。
- 隐层激活仍然是稠密的,每个维度都参与表示,难以直接对应单一语义。
1.2 稀疏自编码器(SAE)
SAE 是传统自编码器的一种变体,专门设计用于学习稀疏表示。论文《Sparse Autoencoders Find Highly Interpretable Features in Language Models》中的 SAE 具有以下特点:
- 隐层维度:通常是过完备的,即 d hid = R ⋅ d in d_{\text{hid}} = R \cdot d_{\text{in}} dhid=R⋅din,其中 R ≥ 1 R \geq 1 R≥1(论文默认 R = 2 R=2 R=2)。这意味着隐层维度大于或等于输入维度,允许表示更多的特征。
- 稀疏性约束:
- 隐层激活 c \mathbf{c} c(即嵌入)受到稀疏性惩罚,鼓励大部分元素为零。
- 损失函数包括重构损失和 L1 稀疏性惩罚:
L ( x ) = ∥ x − x ^ ∥ 2 2 + α ∥ c ∥ 1 \mathcal{L}(\mathbf{x}) = \|\mathbf{x} - \hat{\mathbf{x}}\|_2^2 + \alpha \|\mathbf{c}\|_1 L(x)=∥x−x^∥22+α∥c∥1
其中, α \alpha α 控制稀疏程度(论文中 α = 8.6 e − 4 \alpha=8.6e-4 α=8.6e−4)。 - 激活函数通常为 ReLU,确保非负激活,进一步促进稀疏性。
- 隐层激活:隐层向量 c \mathbf{c} c 中只有少数维度(特征)有显著非零值,其余为零。这种稀疏性使得每个激活向量仅由少量特征的线性组合表示。
- 应用:SAE 用于分解语言模型激活中的叠加(superposition)特征,提取单义(monosemantic)且可解释的特征。
1.3 SAE 与传统自编码器(隐层维度短)的具体区别
以下从几个关键方面对比 SAE 和传统自编码器(尤其是隐层维度较短的降维型):
| 特性 | 传统自编码器(降维型) | 稀疏自编码器(SAE) |
|---|---|---|
| 隐层维度 | d hid < d in d_{\text{hid}} < d_{\text{in}} dhid<din,维度较短 | d hid ≥ d in d_{\text{hid}} \geq d_{\text{in}} dhid≥din,通常过完备 |
| 隐层激活 | 稠密,每个维度都有非零值 | 稀疏,大部分维度为零,仅少数特征激活 |
| 损失函数 | 仅重构损失(如 L2 范数) | 重构损失 + L1 稀疏性惩罚 |
| 特征表示 | 压缩表示,特征可能是混合语义 | 过完备表示,特征倾向于单义、可解释 |
| 信息保留 | 由于维度受限,可能丢失信息 | 过完备维度允许保留更多信息,但稀疏性可能导致部分损失 |
| 可解释性 | 隐层特征难以直接对应单一语义 | 稀疏特征易于解释,常对应单一语义(如“撇号”) |
| 应用场景 | 降维、去噪、通用特征提取 | 解决叠加问题,提取语言模型的可解释特征 |
核心区别:
- 维度与稀疏性的权衡:
- 传统降维型自编码器通过限制隐层维度( d hid < d in d_{\text{hid}} < d_{\text{in}} dhid<din)实现压缩,但隐层激活是稠密的,特征可能是多种语义的混合(多义性,polysemantic)。
- SAE 通过过完备隐层( d hid ≥ d in d_{\text{hid}} \geq d_{\text{in}} dhid≥din)提供足够多的特征方向,同时用稀疏性约束(L1 惩罚和 ReLU)确保每次激活只涉及少数特征,从而减少多义性,增强单义性。
- 语义清晰度:
- 降维型自编码器的特征由于维度限制,可能捕捉广泛模式(例如,“人名”),但难以细化为具体语义(如“女性名字”)。
- SAE 的稀疏特征倾向于捕捉单一、具体的语义(例如,“字母 ‘W’”或“撇号”),如论文 Table 1 所示。
- 叠加问题:
- 语言模型中的叠加(superposition)意味着模型将多个特征压缩到有限维度中,导致多义性。降维型自编码器无法有效分解这些特征,因为其隐层维度不足以表示过完备特征集。
- SAE 通过过完备隐层和稀疏性,假设输入激活是少量特征的线性组合(论文 Section 2),从而分解叠加特征。
例子:
- 假设输入是语言模型残差流激活(维度 d in = 512 d_{\text{in}}=512 din=512),包含“撇号”和“人名”两种语义特征。
- 传统自编码器(
d
hid
=
100
d_{\text{hid}}=100
dhid=100):
- 隐层压缩到 100 维,所有维度都有非零激活,可能一个维度同时表示“撇号”和“人名”的混合信号。
- 重构效果可能不错,但特征难以解释(多义性)。
- SAE(
d
hid
=
1024
,
R
=
2
d_{\text{hid}}=1024, R=2
dhid=1024,R=2):
- 隐层有 1024 维,但每次激活只有少数维度非零(例如,5 个特征)。
- 可能存在一个特征专门表示“撇号”(如论文 Figure 4),另一个表示“人名”,激活模式清晰,易于解释。
2. 字典学习的字典特征在论文中的应用
2.1 字典学习与字典特征
字典学习(Dictionary Learning) 是一种信号处理方法,旨在将输入数据表示为字典中特征(或基向量)的稀疏线性组合。数学上,假设输入向量
x
i
∈
R
d
\mathbf{x}_i \in \mathbb{R}^d
xi∈Rd 可以表示为:
x
i
=
∑
j
a
i
,
j
g
j
\mathbf{x}_i = \sum_j a_{i,j} \mathbf{g}_j
xi=j∑ai,jgj
其中:
- g j ∈ R d \mathbf{g}_j \in \mathbb{R}^d gj∈Rd 是字典中的特征向量(称为字典特征),组成字典 { g j } j = 1 n hid \{\mathbf{g}_j\}_{j=1}^{n_{\text{hid}}} {gj}j=1nhid。
- a i , j a_{i,j} ai,j 是稀疏系数,大部分为零。
- 字典通常是过完备的,即 n hid > d n_{\text{hid}} > d nhid>d,允许表示更多的特征。
在论文中的应用:
- 论文将语言模型的激活向量(例如残差流激活)视为输入 x i \mathbf{x}_i xi,假设它们是潜在特征 { g j } \{\mathbf{g}_j\} {gj} 的稀疏线性组合(论文 Section 2)。
- SAE 的训练过程等价于稀疏字典学习:
- SAE 的权重矩阵 M ∈ R d hid × d in M \in \mathbb{R}^{d_{\text{hid}} \times d_{\text{in}}} M∈Rdhid×din 的行 { f k } \{\mathbf{f}_k\} {fk} 对应字典特征。
- 隐层激活 c \mathbf{c} c 对应稀疏系数 a i , j a_{i,j} ai,j。
- 前向传播为:
c = ReLU ( M x + b ) , x ^ = M T c = ∑ k = 1 d hid c k f k \mathbf{c} = \text{ReLU}(M \mathbf{x} + \mathbf{b}), \quad \hat{\mathbf{x}} = M^T \mathbf{c} = \sum_{k=1}^{d_{\text{hid}}} c_k \mathbf{f}_k c=ReLU(Mx+b),x^=MTc=k=1∑dhidckfk
其中, x ^ \hat{\mathbf{x}} x^ 是重构向量, f k \mathbf{f}_k fk 是字典特征, c k c_k ck 是稀疏系数。
- 目标:通过训练 SAE,学习一组字典特征 { f k } \{\mathbf{f}_k\} {fk},使得每个 f k \mathbf{f}_k fk 尽可能接近语言模型的真实特征 g j \mathbf{g}_j gj(例如,“撇号”或“人名”),且激活是稀疏的,减少特征间的干扰(论文 Section 2)。
2.2 字典特征的具体作用
- 分解叠加:语言模型可能将多个特征压缩到同一维度(叠加),导致多义性。字典特征通过过完备表示和稀疏激活,将这些特征分开(论文 Section 1)。
- 可解释性:每个字典特征倾向于表示单一语义(单义性),便于人类理解(论文 Section 3)。
- 因果分析:字典特征可用于激活修补,定位模型行为的因果机制(论文 Section 4)。
- 电路发现:通过分析字典特征间的因果关系(例如,前层特征如何激活后层特征),构建模型的计算图(论文 Section 5.3)。
2.3 例子解释
以下通过一个具体例子说明字典特征在论文中的应用,基于论文 Table 1 和 Figure 4 中的“撇号”特征。
场景:
- 输入:Pythia-70M 第 1 层残差流激活向量 x ∈ R 512 \mathbf{x} \in \mathbb{R}^{512} x∈R512,来自文本“Then, Alice’s book was found.”,其中 token “'”(撇号)触发激活。
- SAE 配置:隐层维度 d hid = 1024 d_{\text{hid}}=1024 dhid=1024( R = 2 R=2 R=2),训练后得到字典特征 { f k } k = 1 1024 \{\mathbf{f}_k\}_{k=1}^{1024} {fk}k=11024。
- 目标:分解激活 x \mathbf{x} x 为稀疏的字典特征组合,识别与“撇号”相关的特征。
步骤:
-
激活分解:
- 输入
x
\mathbf{x}
x 通过 SAE,计算隐层激活:
c = ReLU ( M x + b ) \mathbf{c} = \text{ReLU}(M \mathbf{x} + \mathbf{b}) c=ReLU(Mx+b)
假设 c ∈ R 1024 \mathbf{c} \in \mathbb{R}^{1024} c∈R1024 是一个稀疏向量,只有少数维度非零,例如:
c 556 = 0.9 , c 100 = 0.2 , 其他 c k = 0 c_{556} = 0.9, \quad c_{100} = 0.2, \quad \text{其他 } c_k = 0 c556=0.9,c100=0.2,其他 ck=0 - 重构向量为:
x ^ = M T c = 0.9 f 556 + 0.2 f 100 \hat{\mathbf{x}} = M^T \mathbf{c} = 0.9 \mathbf{f}_{556} + 0.2 \mathbf{f}_{100} x^=MTc=0.9f556+0.2f100
其中, f 556 \mathbf{f}_{556} f556 和 f 100 \mathbf{f}_{100} f100 是字典特征。
- 输入
x
\mathbf{x}
x 通过 SAE,计算隐层激活:
-
特征解释:
- 使用自动可解释性评分(论文 Section 3)分析特征
f
556
\mathbf{f}_{556}
f556:
- 收集 OpenWebText 中激活 f 556 \mathbf{f}_{556} f556 的文本片段,发现高激活 token 多为撇号(例如,“Alice’s”, “let’s”)。
- GPT-4 生成描述:“该特征在撇号上激活,尤其是在所有格和缩写中。”
- 评分结果为 0.33(类似 Table 1 的特征 1-0000)。
- 类似地, f 100 \mathbf{f}_{100} f100 可能对应其他语义(例如,“人名”),但激活较低。
- 使用自动可解释性评分(论文 Section 3)分析特征
f
556
\mathbf{f}_{556}
f556:
-
字典特征的作用:
- 单义性: f 556 \mathbf{f}_{556} f556 专门表示“撇号”,不像残差流默认维度可能同时表示撇号和其他标点(论文 Figure 11)。
- 稀疏表示:激活 c \mathbf{c} c 中只有 2 个特征非零,表明 x \mathbf{x} x 主要由“撇号”和少量其他特征组成,减少了多义性干扰。
- 可解释性:通过 GPT-4 描述,研究者可直接理解 f 556 \mathbf{f}_{556} f556 的语义,无需分析复杂的激活模式。
-
因果分析(扩展应用):
- 在 IOI 任务中,假设 f 556 \mathbf{f}_{556} f556 与预测后续 token(如“s”)相关。
- 通过激活修补(论文 Section 4):
x ′ = x + ( c 556 target − c 556 ) f 556 \mathbf{x}' = \mathbf{x} + (c_{556}^{\text{target}} - c_{556}) \mathbf{f}_{556} x′=x+(c556target−c556)f556
调整 f 556 \mathbf{f}_{556} f556 的激活,观察输出 logit 变化。例如,消融 f 556 \mathbf{f}_{556} f556 可能降低“s”的预测概率(论文 Figure 4),验证其因果作用。
与传统自编码器的对比:
- 如果使用降维型自编码器( d hid = 100 d_{\text{hid}}=100 dhid=100),隐层激活可能是稠密的,包含“撇号”、“人名”和其他语义的混合信号,难以分离出 f 556 \mathbf{f}_{556} f556 这样的单义特征。
- SAE 的过完备字典(1024 维)和稀疏激活(仅 f 556 \mathbf{f}_{556} f556 和 f 100 \mathbf{f}_{100} f100 激活)允许精确分解“撇号”特征,提高可解释性和因果分析的精度。
3. 总结
- SAE vs. 传统自编码器:
- 传统自编码器(尤其是降维型)通过压缩隐层维度实现表示,但激活稠密,特征多义,难以解释。
- SAE 通过过完备隐层和稀疏性约束,学习稀疏、单义的特征,适合分解语言模型的叠加特征。
- 字典特征的应用:
- 字典特征 { f k } \{\mathbf{f}_k\} {fk} 是 SAE 学到的基向量,每个特征对应单一语义(如“撇号”)。
- 它们用于分解激活向量(稀疏表示)、解释特征(自动评分)、定位因果机制(激活修补)和构建计算图(电路发现)。
- 例子:
- “撇号”特征 f 556 \mathbf{f}_{556} f556 通过稀疏激活分解残差流向量,GPT-4 描述其语义,激活修补验证其对后续 token 预测的因果作用。
后记
2025年4月23日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









