









解读2000+多语言基准的经验教训:大模型多语言现象与挑战
作为深度学习研究者,特别是在大语言模型(LLM)领域,我们对模型的多语言能力充满期待。然而,如何公平、准确地评估这些模型在全球多样语言环境下的表现,始终是一个复杂且关键的挑战。近日,阿里国际数字商业团队发表的论文《The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks》通过对2021至2024年间超过2000个多语言基准的系统性分析,揭示了当前多语言评估实践的局限性,并为未来的研究提供了宝贵的指导。本文将面向深度学习研究者,介绍该论文的主要贡献,并提出一些洞察,助力探索大模型的多语言现象与挑战。
Paper Link:https://www.arxiv.org/pdf/2504.15521
论文的主要贡献
该论文从历史(过去)、现状(现在)和未来三个维度,对多语言基准进行了全面剖析,提供了以下几个方面的核心贡献:
1. 大规模多语言基准趋势分析
论文收集并标注了2021至2024年间arXiv cs.CL类别中的370,000篇论文,最终筛选出2024个包含多语言基准的研究,覆盖148个国家。这种大规模分析揭示了多语言基准的几个关键趋势:
- 语言分布不均:尽管刻意排除仅含英语的基准,英语仍是最常见的语言,高资源语言(如中文、西班牙语、法语、德语)占据主导地位,而低资源语言严重不足(见图2)。
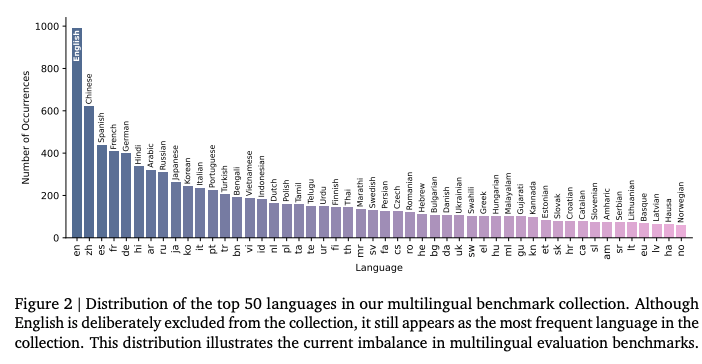
- 任务类型演变:判别任务(如文本分类)占66.5%,生成任务仅占23.5%。自2023年大模型兴起后,问题回答(QA)和机器阅读理解(MRC)任务显著增长,而命名实体识别(NER)呈下降趋势。
- 数据集规模与成本:数据集规模持续扩大,2024年超大型数据集(>100K样本)数量较2021年增长近三倍,总计成本约1100万美元。
- 数据来源:新闻(17%)和社交媒体(13.3%)是主要数据来源,而高价值领域如医疗(4.5%)和法律(3.8%)数据较少。
- 地域与机构:中国、印度、德国、英国和美国(G5国家)主导基准开发,欧洲以学术研究为主,中国和美国则展现出更强的产学合作。
洞察:这种趋势分析为研究者提供了清晰的基准现状图景。对于希望研究多语言现象的学者,关注低资源语言和生成任务可能是突破现有局限的切入点。此外,医疗和法律等领域的基准开发潜力巨大,值得进一步探索。
2. 多语言用户需求与基准对人类判断的关联性
论文通过分析Chatbot Arena和WildChat中的10K条用户指令,揭示了多语言用户的需求:
- 用户兴趣相似性:不同语言用户(英语、中文、法语、德语、西班牙语、俄语)在写作任务(30-45%)、常识推理和编程任务上表现出惊人的一致性,表明用户需求具有跨语言的普遍性。
- 基准与人类判断的差异:通过比较30个大模型在8个多语言基准(XNLI、ARC、HellaSwag等)上的表现与Chatbot Arena的Elo评分(反映人类判断),发现STEM相关任务(如ARC、MGSM)与人类判断高度相关(Spearman’s ρ 0.70-0.85),而传统NLP任务如XQuAD相关性较弱(0.11-0.30)。
- 翻译的局限性:直接翻译英语基准(如MMLU)到其他语言的效果不佳,相关性较低(0.47-0.49)。相比之下,本地化基准(如中文的CMMLU)与人类判断的相关性更高(0.68)。
洞察:用户需求的跨语言一致性提示研究者可以聚焦于通用的核心任务(如写作和推理),但评估时需警惕翻译基准的局限性。开发本地化基准,尤其是针对特定文化和语言的测试集,是提升评估质量的关键。
3. 多语言基准的指导原则与未来研究方向
基于分析,论文提出了有效多语言基准的六大核心特性:准确性、无污染、足够挑战性、实际相关性、语言多样性和文化真实性。同时,提出了五个关键研究方向:
- 自然语言生成(NLG):生成任务评估不足,需开发更多NLG基准。
- 低资源语言:打破高资源语言主导的循环,专注低资源语言的基准设计。
- 本地化基准:设计反映文化和语言细微差别的本地化测试集。
- LLM作为评判者:探索LLM在多语言评估中的潜力,同时解决其偏差问题。
- 高效评估:开发高效的基准方法,如代表性语言-任务子集或自适应测试。
洞察:这些方向为研究者提供了明确的行动指南。特别是NLG和低资源语言的基准开发,不仅能填补现有空白,还可能推动模型在实际场景中的应用。LLM作为评判者的研究则需要平衡其效率与跨语言公平性。
4. 全球协作与实际应用的号召
论文最后呼吁全球研究社区协作开发多语言基准,强调:
- 全球协作:通过国际研究联盟整合资源,避免重复工作。
- 人类对齐:将人类判断纳入基准设计,捕捉语言特有的文化和语用特征。
- 应用导向:开发面向教育、医疗、商业等实际场景的基准,缩小学术与现实的差距。
洞察:这一号召提醒研究者,技术进步需与社会需求对齐。参与全球协作项目,如开源多语言数据集或基准平台,可能加速研究进展并提升影响力。
对深度学习研究者的启发
对于希望研究大模型多语言现象的深度学习学者,这篇论文提供了以下几点启发:
- 聚焦低资源语言的创新:低资源语言的基准开发不仅是技术挑战,也是公平性问题。研究者可以探索如何利用少量数据生成高质量基准,或通过跨语言迁移学习提升低资源语言的评估效果。
- 文化敏感的模型设计:本地化基准的高相关性表明,模型需更好地理解文化背景。研究者可以尝试将文化知识嵌入预训练或微调阶段,例如通过多语言文化数据集进行增强。
- 生成任务的突破:生成任务的评估不足为研究者提供了机会。可以开发针对多语言生成质量的自动化评估指标,或设计基于人类反馈的生成基准。
- 高效与公平的平衡:随着基准规模扩大,高效评估方法(如子集采样)将成为重点。同时,需确保这些方法在低资源语言上的公平性,避免进一步加剧语言不平等。
- 协作与开源:参与开源多语言基准项目(如Hugging Face数据集或NeurIPS基准挑战赛)不仅能加速研究,还能提升学术影响力。
结语
《The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks》通过对多语言基准的系统性分析,揭示了当前评估实践的不足,并为大模型的多语言研究指明了方向。对于深度学习研究者而言,这不仅是一份宝贵的参考资料,更是一个行动的起点。无论是开发本地化基准、探索低资源语言,还是推动全球协作,未来的多语言研究需要我们在技术创新与社会责任之间找到平衡。让我们共同努力,打造更公平、更具实际意义的语言技术!
后记
2025年4月25日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









