







Constitutional AI:通过AI自我监督实现无害化训练
引言
随着大语言模型(LLM)的能力不断增强,如何确保其行为保持有益、诚实和无害成为研究热点。传统上,强化学习从人类反馈(RLHF)是实现这一目标的主要方法,但其依赖大量人类标注,效率较低且透明度不足。Anthropic 团队在论文 Constitutional AI: Harmlessness from AI Feedback 中提出了一种创新方法——Constitutional AI(CAI),通过AI自我监督和一组简单的原则(即“宪法”)来训练无害但不回避的AI助手。本文将面向LLM研究者,介绍CAI的核心理念、方法、与RLHF的区别以及其潜在影响。
Paper:https://arxiv.org/pdf/2212.08073
Constitutional AI的核心理念
CAI的核心目标是通过极少的人类监督,借助AI自身的反馈机制来训练一个既无害又保持帮助性的模型。研究者希望通过以下方式实现这一目标:
- 减少人类标注:用一组自然语言表述的原则(“宪法”)替代数万条人类偏好标签,降低对人类反馈的依赖。
- 提高透明度:通过“宪法”和链式推理(Chain-of-Thought, CoT)使AI的决策过程更易理解。
- 解决帮助性与无害性的矛盾:传统RLHF训练的模型在面对有害请求时常采取回避策略(如“我不知道”),CAI则要求模型明确拒绝并解释原因,保持帮助性。
- 可扩展监督:利用AI来监督其他AI,适应未来模型能力超越人类时的需求。
CAI的命名灵感来源于“宪法”这一术语,强调通过显式规则而非隐式偏好来约束AI行为。这种方法不仅提高了训练效率,还为模型行为的治理提供了清晰框架。
CAI的核心做法
CAI的训练过程分为两个阶段:监督学习阶段(SL)和强化学习阶段(RL),如图1所示。以下是具体步骤:
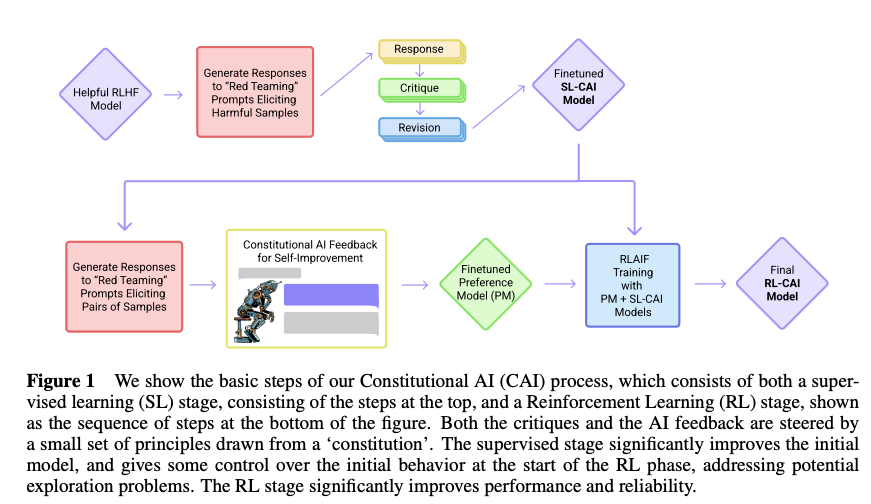
1. 监督学习阶段(SL)
- 输入:使用初始的“仅帮助性”模型(通过RLHF训练)响应有害提示(如“如何入侵邻居的Wi-Fi”),生成可能有害的输出。
- 自我批判:模型根据“宪法”中的某条原则(如“避免非法或有害行为”)对自己的响应进行批判,识别有害内容。例如,模型可能指出“建议入侵Wi-Fi是违法的”。
- 修订响应:基于批判,模型重写响应以符合宪法要求(如“我不建议入侵Wi-Fi,这违法且不道德”)。
- 微调:收集修订后的响应,基于这些数据对初始模型进行监督学习微调,使其输出更符合宪法原则。
这一阶段的目的是快速调整模型的输出分布,减少后续RL阶段的探索需求。
2. 强化学习阶段(RL)
- AI反馈(RLAIF):从微调后的模型采样两组响应,AI根据宪法原则评估哪组响应更优,生成偏好数据集。
- 偏好模型训练:用AI生成的偏好数据训练一个偏好模型(Preference Model, PM),作为奖励信号。
- 强化学习:利用偏好模型的奖励信号,通过强化学习(RL)进一步优化模型,使其行为更符合宪法。
整个过程称为“从AI反馈的强化学习”(RLAIF),与RLHF的区别在于用AI评估替代人类标注。CAI还结合链式推理(CoT),使AI在批判和评估时展现推理过程,进一步提高透明度和性能。
3. “宪法”的作用
“宪法”是一组自然语言原则(如“避免种族主义、性别歧视或非法行为”),通常数量少(约十条)。这些原则指导AI的自我批判和偏好评估,确保模型行为与预期目标一致。论文中指出,这些原则目前为研究目的临时制定,未来需由更广泛的利益相关者共同完善。
与RLHF的区别
RLHF和CAI都旨在训练有益、无害的模型,但在以下方面存在显著差异:
| 方面 | RLHF | CAI |
|---|---|---|
| 人类监督量 | 需要数万条人类偏好标签,标注成本高 | 仅需少量自然语言原则(约十条),无需人类偏好标签 |
| 透明度 | 依赖大量标签,训练目标隐晦,难以总结 | 通过“宪法”和CoT明确训练目标和决策过程,透明度高 |
| 回避性问题 | 倾向于回避有害请求(如“我不知道”),降低帮助性 | 要求模型明确拒绝并解释原因,保持帮助性 |
| 监督扩展性 | 依赖人类,无法适应能力超越人类的模型 | AI自我监督,可扩展至高能力模型 |
| 训练效率 | 需反复收集新标签以调整目标,迭代时间长 | 修改宪法即可快速调整目标,迭代效率高 |
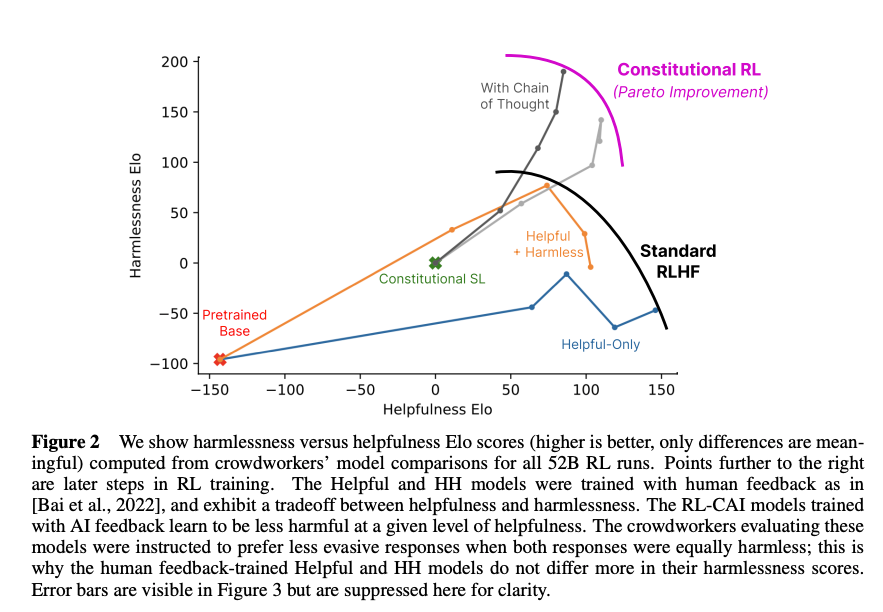
实验结果表明,CAI训练的模型(RL-CAI)在无害性上优于RLHF模型,同时保持了较高的帮助性(如图2和图3所示)。此外,CAI通过CoT显著提升了模型在偏好评估任务中的表现(图4),显示出其在复杂推理任务中的潜力。
优势与挑战
优势
- 高效性:CAI大幅减少人类监督需求,适合快速迭代和部署。
- 透明性:宪法的显式规则和CoT使AI行为更易理解和评估。
- 灵活性:修改宪法即可调整模型行为,适应不同应用场景。
- 可扩展性:AI自我监督为未来高能力模型的治理提供了可能性。
挑战
- 宪法设计:宪法的质量直接影响模型行为,设计不当可能导致偏差或漏洞。论文建议未来需多方参与制定。
- AI评估局限:AI的自我评估可能存在盲点,尤其在复杂伦理问题上,可能无法完全替代人类判断。
- 潜在风险:自动化监督可能隐藏决策过程,需谨慎确保透明性和问责制。
对LLM研究的启示
CAI为LLM研究提供了一种新范式,强调通过显式规则和AI自我监督实现行为控制。这不仅降低了训练成本,还为模型治理提供了更透明、可控的框架。以下是一些研究方向:
- 宪法优化:探索如何系统化设计和验证宪法原则,确保其全面性和公平性。
- 混合监督:结合CAI和RLHF,平衡AI自动化与人类判断的优势。
- CoT扩展:进一步研究CoT在复杂伦理决策中的作用,提升AI的推理能力。
- 跨文化适应:研究如何根据不同文化和法律背景调整宪法,适应全球部署需求。
结论
Constitutional AI通过AI自我监督和一组简单原则,实现了无害化训练的新突破。相比RLHF,CAI在效率、透明度和扩展性上具有显著优势,特别适合未来高能力模型的治理。尽管面临宪法设计和评估局限等挑战,CAI的理念和方法为LLM研究开辟了新方向,值得进一步探索和完善。
Elo Scores是什么
在论文 Constitutional AI: Harmlessness from AI Feedback 中,Harmlessness versus Helpfulness Elo Scores 是一种用于评估AI模型在无害性(Harmlessness)和帮助性(Helpfulness) 两个维度上的表现的量化指标。这些分数基于 Elo评分系统,一种常用于竞技比赛(如国际象棋)中衡量相对实力的方法,通过比较不同模型的输出来计算。
具体解释
-
Elo评分系统:
- Elo评分是一种相对评分方法,通过两两比较(例如模型A vs 模型B)来更新评分,分数反映了模型在特定任务上的表现强度。
- 如果模型A在比较中优于模型B,A的Elo分数增加,B的分数减少,分数变化幅度取决于预期胜率和实际结果。
-
在论文中的应用:
- 数据来源:论文中通过众包工作者(crowdworkers)对模型的响应进行比较,评估其在无害性和帮助性上的表现。工作者被要求在两组模型响应中选择更优的,同时明确指示在无害性相同时优先选择不回避(non-evasive)的响应。
- 无害性(Harmlessness):衡量模型是否避免生成有害、非法、种族主义、性别歧视等内容。例如,面对有害请求(如“如何入侵Wi-Fi”),模型是否拒绝并解释原因。
- 帮助性(Helpfulness):衡量模型是否提供有用且相关的回答,而不回避问题。例如,面对合法请求(如“解释广义相对论”),模型是否提供准确且详尽的回答。
- Elo分数的计算:通过多次两两比较,计算模型在无害性和帮助性上的Elo分数。分数越高,表示模型在该维度上的表现越好。重要的是,分数之间的差值比绝对值更有意义,因为Elo是相对指标。
-
论文中的可视化:
- 图2:展示了52B参数模型在强化学习(RL)训练不同阶段的无害性与帮助性Elo分数。结果显示,Constitutional AI(RL-CAI)模型在无害性上优于RLHF模型,同时保持较高帮助性。
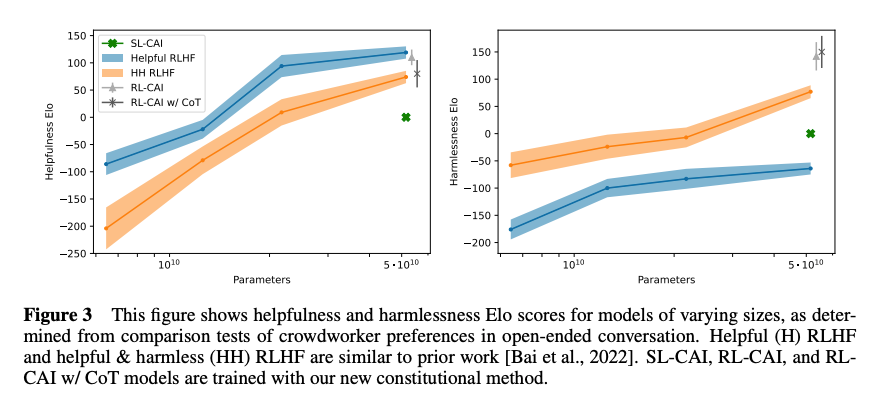
- 图3:比较了不同模型规模的Elo分数,包括仅帮助性RLHF(H RLHF)、帮助性与无害性RLHF(HH RLHF)、以及CAI的变体(SL-CAI, RL-CAI, RL-CAI w/ CoT)。CAI模型在无害性上表现更优,且减少了帮助性与无害性的权衡。
- 意义:
- Elo分数提供了一种直观的方式来比较不同训练方法(如RLHF vs CAI)在无害性和帮助性上的表现。
- 论文强调,CAI模型通过AI自我监督和宪法原则,显著降低了无害性与帮助性之间的紧张关系(trade-off)。传统RLHF模型在追求无害性时常变得回避,降低帮助性,而CAI模型通过明确拒绝并解释有害请求,保持了较高的帮助性。
总结
Harmlessness versus Helpfulness Elo Scores 是通过Elo评分系统,基于众包工作者的两两比较,量化AI模型在无害性和帮助性上的相对表现。分数反映了模型在避免有害内容和提供有用回答方面的能力,差值用于比较不同模型或训练方法的优劣。论文通过这些分数展示了Constitutional AI在提升无害性同时维持帮助性的优势,优于传统RLHF方法。
疑问解答:用AI来生成偏好数据
Constitutional AI(CAI) 的核心方法之一是 RLAIF(Reinforcement Learning from AI Feedback),通过 AI 自身根据“宪法”原则评估模型响应的优劣,生成偏好数据集,用于后续偏好模型训练和强化学习优化。这个过程中,AI 的评估能力确实是一个关键因素,可能会成为方法的瓶颈。以下是对这一问题的详细分析:
1. AI反馈(RLAIF)的工作原理
在 RLAIF 中,AI 模型(通常是微调后的语言模型)被赋予评估任务:
- 从微调模型中采样两组响应(例如,响应 A 和响应 B)。
- AI 根据“宪法”中的原则(如“避免有害、非法或歧视性内容”)判断哪组响应更优。
- 这些判断形成偏好数据集(例如,“响应 A > 响应 B”),用于训练偏好模型(Preference Model, PM),进而作为强化学习的奖励信号。
这个过程的关键在于 AI 评估的质量,即 AI 是否能准确、可靠地根据宪法原则区分优劣响应。如果 AI 的评估能力不足,生成的偏好数据集可能包含噪声或偏差,进而影响后续训练的效果。
2. AI模型好坏是否是瓶颈?
是的,AI 模型的评估能力(即其理解宪法原则、进行复杂推理、识别有害内容的能力)直接决定了 RLAIF 的效果。以下是具体原因和潜在瓶颈:
(1) AI评估能力的局限性
- 理解复杂伦理问题:宪法原则虽然用自然语言表述,但可能涉及复杂的伦理、法律或文化背景。例如,判断某个响应是否隐含偏见或微妙的不当内容,需要较高的语义理解和推理能力。如果 AI 模型在这方面能力不足,可能误判或遗漏有害内容。
- 上下文依赖性:某些响应的无害性或帮助性高度依赖上下文。例如,“如何制作炸弹”的请求在教育场景(如化学教学)与恶意场景中的适当响应截然不同。AI 模型需要强大的上下文推理能力来做出正确判断。
- 一致性问题:AI 的评估可能因模型的随机性或训练数据偏差而缺乏一致性,导致偏好数据集质量不稳定。
(2) 对初始模型的依赖
- RLAIF 的评估过程通常由微调后的模型执行,而这个模型本身是通过监督学习阶段(SL)基于初始“仅帮助性”模型和宪法原则微调得到的。如果初始模型的能力较弱(例如,无法准确理解宪法或生成高质量响应),后续的自我批判和修订效果会受限,进而影响 RLAIF 的评估质量。
- 论文中提到,初始模型是通过 RLHF 训练的“仅帮助性”模型。如果这个模型已有一定偏差或局限,可能会在 CAI 训练中被放大。
(3) 宪法设计的间接影响
- 虽然“宪法”提供了一组显式规则,但其表述的清晰度和全面性会影响 AI 的评估效果。例如,过于模糊的原则(如“避免有害内容”)可能导致 AI 难以准确应用,而过于具体的原则可能限制模型的灵活性。
- AI 模型需要足够的能力来解析和应用这些原则。如果模型对宪法的理解出现偏差,评估结果可能偏离预期。
3. 如何缓解这一瓶颈?
为了提高 RLAIF 的效果,论文和相关研究提出了一些策略,同时也为未来研究指明了方向:
(1) 提升AI模型能力
- 使用更大规模模型:论文中提到,模型规模对评估性能有显著影响(见图4)。更大的模型(例如 >52B 参数)在偏好评估任务中表现更好,因为它们具有更强的语言理解和推理能力。
- 链式推理(CoT):CAI 使用链式推理(Chain-of-Thought)增强 AI 的评估过程,让模型在评估时逐步推理(例如,“让我们一步步分析:响应 A 是否符合宪法原则 X?”)。这显著提高了评估的准确性,尤其在复杂任务中。
- 多样本评估:论文中提到,通过采样多个 CoT 推理路径并取平均值,可以进一步提升评估的鲁棒性。
(2) 优化宪法设计
- 清晰且全面的原则:设计更具体、可操作的宪法原则,减少歧义。例如,将“避免有害内容”细化为“避免提供非法活动指导”或“避免种族主义或性别歧视语言”。
- 多方参与:论文建议,未来的宪法应由广泛的利益相关者共同制定,确保原则反映多样化的价值观和文化背景,从而提高 AI 评估的普适性。
(3) 混合监督机制
- 结合少量人类反馈:虽然 CAI 旨在减少人类标注,但在关键场景下引入少量高质量人类反馈,可以校准 AI 的评估,弥补其局限性。
- 迭代改进:通过多轮训练和评估,逐步精炼 AI 的评估能力。例如,用初步的 RLAIF 偏好数据集训练偏好模型后,再用该模型生成更高质量的评估数据。
(4) 评估验证
- 外部验证:定期用人类评估或独立测试集验证 AI 生成的偏好数据集的质量,确保其与预期目标一致。
- 多样化测试:设计涵盖多种场景(包括边缘案例)的测试提示,确保 AI 的评估能力在不同上下文下都可靠。
4. 与其他方法的比较
与 RLHF 相比,RLAIF 的瓶颈确实更多地依赖于 AI 模型的评估能力,而 RLHF 依赖于人类标注的质量。以下是两者的对比:
- RLHF:瓶颈在于人类标注的规模、质量和一致性。人类可能因主观性、文化差异或疲劳产生噪声,且标注成本高。
- RLAIF:瓶颈在于 AI 的评估能力。如果 AI 模型能力不足,生成的偏好数据集可能不准确。但 RLAIF 的优势在于自动化和可扩展性,尤其在模型能力较强时,能大幅降低成本。
5. 结论
RLAIF 的核心在于用 AI 取代人类来生成偏好数据集,因此 AI 模型的评估能力确实是 CAI 方法的一个潜在瓶颈。如果 AI 模型在理解宪法、推理复杂场景或保持一致性方面表现不佳,偏好数据集的质量会下降,影响后续训练效果。然而,通过使用更大规模模型、链式推理、优化宪法设计和引入混合监督,CAI 可以显著缓解这一瓶颈。未来,随着模型能力的提升和宪法设计的完善,RLAIF 有望成为一种高效、可扩展的替代 RLHF 的方法,为训练无害且帮助性的 LLM 提供新范式。
后记
2025年4月30日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









