









LANA:基于神经架构搜索的延迟感知网络加速技术
引言
在深度学习领域,神经网络的高计算复杂性往往使其在资源受限的设备上难以部署。如何在保持模型精度的同时显著降低延迟和计算成本,是一个关键的研究方向。2022年ECCV会议上发表的论文《LANA: Latency Aware Network Acceleration》提出了一种新颖的网络加速框架——LANA(Latency-Aware Network Acceleration),通过结合神经架构搜索(NAS)和整数线性优化(ILP),实现高效的模型压缩和加速。本文将详细介绍LANA的贡献,深入解析其数学公式,并探讨其对深度学习研究者的启发。
Paper:https://arxiv.org/abs/2107.10624
https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136720136.pdf(笔者参考的是这个版本)
LANA的核心贡献
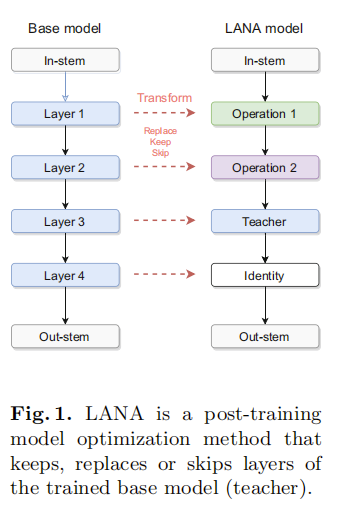
LANA是一种硬件感知的网络加速框架,旨在通过替换预训练网络(称为教师模型)中的低效操作,生成满足特定延迟预算的高效学生模型。其主要贡献可以总结为以下几点:
- 两阶段加速框架:
- 候选操作预训练阶段:通过逐层特征图蒸馏(layer-wise feature map distillation),为网络的每一层预训练大量候选操作(高达197种),以模仿教师模型的输出。
- 操作选择阶段:利用整数线性优化(ILP)快速搜索最佳操作组合,构建满足延迟约束的高效网络架构。
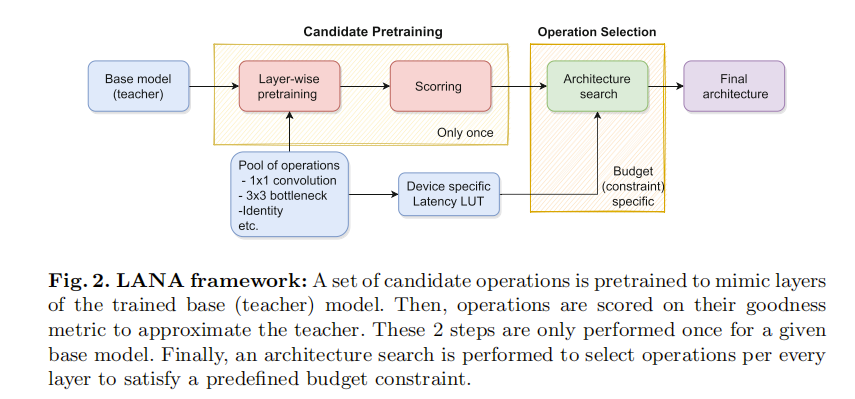
-
高效的搜索算法:
- LANA将架构搜索问题转化为整数线性优化问题,显著降低了搜索成本(从GPU天到CPU秒级)。
- 支持大规模搜索空间( O ( 1 0 100 ) O(10^{100}) O(10100)),远超传统NAS方法,同时保证搜索结果的高质量。
-
逐层加速的灵活性:
- 与传统的基于块(block-wise)的NAS方法不同,LANA在逐层粒度上操作,允许更精细的架构调整,减少搜索约束,提高模型表达能力。
-
广泛的实验验证:
- LANA在EfficientNetV1、EfficientNetV2和ResNet50等流行架构上实现了显著的加速效果(最高5倍),同时精度损失极小(甚至在某些场景下提升高达3%)。
- 提供了对操作选择和最终架构的深入分析,揭示了高效操作的模式(如早期层使用密集卷积、尾部层保留教师操作)。
-
单次加速(Single-Shot)模式:
- LANA支持无需预训练的单次加速模式,仅通过跳跃连接(identity operation)实现快速网络压缩,适用于资源极其受限的场景。
LANA的数学原理与公式解析
LANA的核心在于将复杂的神经架构搜索问题简化为可高效求解的整数线性优化问题。以下是对其关键数学公式的详细解析。
1. 问题建模
LANA的目标是给定一个预训练的教师网络 T ( x ) = t N ∘ t N − 1 ∘ … ∘ t 1 ( x ) \mathcal{T}(x) = t_N \circ t_{N-1} \circ \ldots \circ t_1(x) T(x)=tN∘tN−1∘…∘t1(x),通过替换其中的操作 t i t_i ti 为更高效的候选操作 s i j s_{i j} sij,生成满足延迟预算 B \mathcal{B} B 的学生网络 S ( x ; Z , W ) \mathcal{S}(x; \mathbf{Z}, \mathbf{W}) S(x;Z,W)。其中:
- x x x 为输入张量。
- t i t_i ti 表示教师网络第 i i i 层的操作。
- s i j s_{i j} sij 表示第 i i i 层的第 j j j 个候选操作,共有 M M M 个候选操作(论文中 M = 197 M=197 M=197)。
- W = { w i j } \mathbf{W} = \{w_{i j}\} W={wij} 为候选操作的参数。
- Z = { z i } \mathbf{Z} = \{\mathbf{z}_i\} Z={zi} 为操作选择变量, z i ∈ { 0 , 1 } M \mathbf{z}_i \in \{0,1\}^M zi∈{0,1}M 是一个one-hot向量,表示第 i i i 层选择的操作。
传统NAS问题可以形式化为双层优化问题,目标是最小化学生网络的损失函数,同时满足预算约束:
min Z min W ∑ ( x , y ) ∈ X t r L ( S ( x ; Z , W ) , y ) , s.t. ∑ i = 1 N b i T z i ⩽ B , 1 T z i = 1 ∀ i ∈ [ 1.. N ] , \begin{aligned} & \min_{\mathbf{Z}} \min_{\mathbf{W}} \sum_{(x, y) \in X_{tr}} \mathcal{L}(\mathcal{S}(x; \mathbf{Z}, \mathbf{W}), y), \\ & \text{s.t.} \quad \sum_{i=1}^N \mathbf{b}_i^T \mathbf{z}_i \leqslant \mathcal{B}, \quad \mathbf{1}^T \mathbf{z}_i = 1 \quad \forall i \in [1..N], \end{aligned} ZminWmin(x,y)∈Xtr∑L(S(x;Z,W),y),s.t.i=1∑NbiTzi⩽B,1Tzi=1∀i∈[1..N],
- 目标函数: L ( S ( x ; Z , W ) , y ) \mathcal{L}(\mathcal{S}(x; \mathbf{Z}, \mathbf{W}), y) L(S(x;Z,W),y) 表示学生网络在训练数据 ( x , y ) (x, y) (x,y) 上的损失。
- 预算约束: ∑ i = 1 N b i T z i ⩽ B \sum_{i=1}^N \mathbf{b}_i^T \mathbf{z}_i \leqslant \mathcal{B} ∑i=1NbiTzi⩽B 确保总延迟(或参数量、FLOPs等)不超过预算 B \mathcal{B} B,其中 b i ∈ R + M \mathbf{b}_i \in \mathbb{R}_{+}^M bi∈R+M 是第 i i i 层各候选操作的成本向量。
- 选择约束: 1 T z i = 1 \mathbf{1}^T \mathbf{z}_i = 1 1Tzi=1 保证每层仅选择一个操作。
此优化问题是一个NP-hard的组合优化问题,状态空间大小为 M N M^N MN(例如, 19 7 46 ≈ 1 0 100 197^{46} \approx 10^{100} 19746≈10100),传统NAS方法(如进化搜索或强化学习)计算成本极高。
2. 候选操作预训练
LANA通过逐层特征图蒸馏预训练候选操作,使其模仿教师操作的输出。预训练的优化目标为:
min W ∑ x ∈ X t r ∑ i , j N , M ∥ t i ( x i − 1 ) − s i j ( x i − 1 ; w i j ) ∥ 2 2 , \min_{\mathbf{W}} \sum_{x \in X_{tr}} \sum_{i, j}^{N, M} \left\| t_i(x_{i-1}) - s_{i j}(x_{i-1}; w_{i j}) \right\|_2^2, Wminx∈Xtr∑i,j∑N,M∥ti(xi−1)−sij(xi−1;wij)∥22,
- x i − 1 = t i − 1 ∘ t i − 2 ∘ … ∘ t 1 ( x ) x_{i-1} = t_{i-1} \circ t_{i-2} \circ \ldots \circ t_1(x) xi−1=ti−1∘ti−2∘…∘t1(x) 是教师网络第 i − 1 i-1 i−1 层的输出。
- ∥ t i ( x i − 1 ) − s i j ( x i − 1 ; w i j ) ∥ 2 2 \left\| t_i(x_{i-1}) - s_{i j}(x_{i-1}; w_{i j}) \right\|_2^2 ∥ti(xi−1)−sij(xi−1;wij)∥22 是均方误差(MSE),衡量候选操作 s i j s_{i j} sij 与教师操作 t i t_i ti 输出之间的差异。
优点:
- 该优化问题可分解为 N × M N \times M N×M 个独立的子问题,允许并行训练所有候选操作。
- 每个子问题仅需拟合单层输出,训练成本低(通常仅需1个epoch)。
- 通过在同一前向传播中复用教师层的特征,预训练时间近似为 O ( M ) O(M) O(M) 次全网络训练。
3. 操作选择与整数线性优化
LANA假设学生网络的损失可以近似为教师网络损失加上各层操作变化的线性组合:
∑ X t r L ( S ( x ; Z ) , y ) ≈ ∑ X t r L ( T ( x ) , y ) + ∑ i = 1 N a i T z i , \sum_{X_{tr}} \mathcal{L}(\mathcal{S}(x; \mathbf{Z}), y) \approx \sum_{X_{tr}} \mathcal{L}(\mathcal{T}(x), y) + \sum_{i=1}^N \mathbf{a}_i^T \mathbf{z}_i, Xtr∑L(S(x;Z),y)≈Xtr∑L(T(x),y)+i=1∑NaiTzi,
- ∑ X t r L ( T ( x ) , y ) \sum_{X_{tr}} \mathcal{L}(\mathcal{T}(x), y) ∑XtrL(T(x),y) 是教师网络的训练损失(常数)。
- a i ∈ R M \mathbf{a}_i \in \mathbb{R}^M ai∈RM 是第 i i i 层各候选操作的得分向量,表示替换操作后损失的变化。
- a i T z i \mathbf{a}_i^T \mathbf{z}_i aiTzi 计算第 i i i 层选择操作的损失增量。
得分向量 a i \mathbf{a}_i ai 的计算方法是将每个候选操作逐一插入教师网络,测量在小规模标记数据集上的损失变化。这种线性近似类似于损失函数在教师网络附近的泰勒展开,简化了非线性优化问题。
基于此,LANA将搜索问题形式化为整数线性规划(ILP):
min Z ( k ) ∑ i = 1 N a i T z i ( k ) , s.t. ∑ i = 1 N b i T z i ( k ) ⩽ B , 1 T z i ( k ) = 1 ∀ i , ∑ i = 1 N z i ( k ) T z i ( k ′ ) ⩽ O , ∀ k ′ < k , \begin{aligned} & \min_{\mathbf{Z}^{(k)}} \sum_{i=1}^N \mathbf{a}_i^T \mathbf{z}_i^{(k)}, \\ & \text{s.t.} \quad \sum_{i=1}^N \mathbf{b}_i^T \mathbf{z}_i^{(k)} \leqslant \mathcal{B}, \quad \mathbf{1}^T \mathbf{z}_i^{(k)} = 1 \quad \forall i, \\ & \quad \sum_{i=1}^N \mathbf{z}_i^{(k)^T} \mathbf{z}_i^{(k')} \leqslant \mathcal{O}, \quad \forall k' < k, \end{aligned} Z(k)mini=1∑NaiTzi(k),s.t.i=1∑NbiTzi(k)⩽B,1Tzi(k)=1∀i,i=1∑Nzi(k)Tzi(k′)⩽O,∀k′<k,
- 目标:最小化损失增量 ∑ i = 1 N a i T z i ( k ) \sum_{i=1}^N \mathbf{a}_i^T \mathbf{z}_i^{(k)} ∑i=1NaiTzi(k)。
- 预算约束: ∑ i = 1 N b i T z i ( k ) ⩽ B \sum_{i=1}^N \mathbf{b}_i^T \mathbf{z}_i^{(k)} \leqslant \mathcal{B} ∑i=1NbiTzi(k)⩽B 确保总成本不超过预算。
- 选择约束: 1 T z i ( k ) = 1 \mathbf{1}^T \mathbf{z}_i^{(k)} = 1 1Tzi(k)=1 保证每层选择一个操作。
- 重叠约束: ∑ i = 1 N z i ( k ) T z i ( k ′ ) ⩽ O \sum_{i=1}^N \mathbf{z}_i^{(k)^T} \mathbf{z}_i^{(k')} \leqslant \mathcal{O} ∑i=1Nzi(k)Tzi(k′)⩽O 限制不同解之间的操作重叠(论文中 O = 0.7 N \mathcal{O} = 0.7N O=0.7N),以生成 K K K 个多样化的候选架构。
求解:
- LANA使用PuLP Python库求解ILP,首个解的计算时间通常小于1秒,即使在 K ≈ 100 K \approx 100 K≈100 时也保持高效。
- 生成的 K K K 个候选架构在小规模训练集(ImageNet的6k张图像)上评估,选择损失最低的架构进行微调。
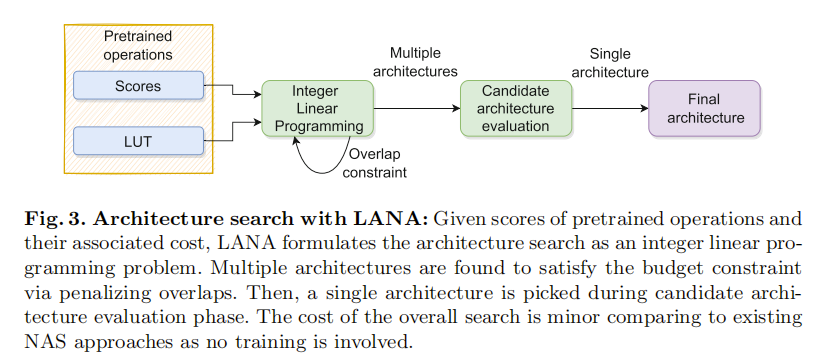
4. 微调阶段
选定最佳架构后,LANA对其进行100个epoch的微调,优化目标结合原始损失和教师-学生蒸馏损失。这种方式确保学生模型在高效架构下尽可能恢复教师模型的性能。
实验结果与分析
LANA在EfficientNetV1、EfficientNetV2和ResNet50上的实验展示了其优越性:
-
加速效果:
- EfficientNetV1-B6:3.6倍加速,精度仅下降0.34%;1.8倍加速,精度下降0.11%。
- EfficientNetV1-B2:2.4倍加速,无精度损失。
- ResNet50:1.5倍加速,精度下降0.14%。
-
精度提升:
- 在压缩大模型到小模型延迟水平时,LANA实现了0.18%至3.0%的精度提升。
-
搜索效率:
- LANA的ILP搜索比传统NAS方法(如SNAS、E-NAS)快821倍,同时精度高0.43%。
-
逐层 vs. 逐块:
- 逐层蒸馏相比逐块蒸馏在教师模仿测试中精度更高(表4),因为逐层监督为早期层提供了更强的指导。
-
搜索空间大小:
- 表6显示,搜索空间从 O ( 1 0 7 ) O(10^7) O(107)(仅2个操作)扩展到 O ( 1 0 100 ) O(10^{100}) O(10100)(197个操作)时,精度显著提升,验证了大搜索空间的优势。
-
架构洞察:
- LANA倾向于在网络早期使用密集卷积替换深度可分离卷积,在尾部保留教师操作。
- 自动发现EfficientNetV2的设计选择(如降低扩展因子、移除挤压-激励模块)。
- 视觉变换器块(ViT)未被选择,可能因预训练不足。
对深度学习研究者的启发
-
逐层优化的潜力:
- LANA展示了逐层粒度的NAS在灵活性和效率上的优势。研究者可以探索更细粒度的操作替换策略,结合通道剪枝或量化进一步优化。
-
高效搜索算法:
- ILP的成功表明,线性近似在特定场景下可大幅降低NAS的计算成本。研究者可尝试将类似方法应用于其他优化问题,如超参数搜索或混合精度量化。
-
预训练与微调的平衡:
- LANA的预训练仅需1个epoch即可提供强初始化,提示研究者在设计加速框架时优先考虑轻量级预训练策略。
-
硬件感知优化的重要性:
- LANA通过硬件特定的延迟查找表(LUT)实现跨硬件优化,提醒研究者在模型设计中充分考虑目标硬件特性。
-
局限性与未来方向:
- LANA的学生模型精度受教师模型限制,未来可探索联合优化教师和学生模型的方法。
- 层输出维度固定限制了架构灵活性,研究者可尝试引入维度适配机制。
- 预训练阶段可考虑错误传播,改进得分度量以捕捉层间交互。
结论
LANA通过创新的两阶段框架和整数线性优化,显著提升了神经网络加速的效率和效果。其逐层操作、超大搜索空间支持以及快速搜索能力,为深度学习研究者提供了宝贵的参考。无论是在边缘设备部署还是数据中心优化,LANA都展示了硬件感知网络加速的巨大潜力。未来,结合更复杂的预训练策略和灵活的架构设计,LANA有望进一步推动高效深度学习模型的发展。
LANA两阶段加速框架详细介绍
以下是对LANA(Latency-Aware Network Acceleration)两阶段加速框架的详细介绍,包括候选操作预训练阶段和操作选择阶段的原理、实现方式以及伪代码。我们将深入解析每个阶段的细节,并为深度学习研究者提供清晰的解释。所有内容均用中文表述,代码以Python风格呈现,基于论文《LANA: Latency Aware Network Acceleration》的描述。
LANA是一种硬件感知的网络加速框架,旨在通过替换预训练教师网络中的低效操作,生成满足延迟预算的高效学生网络。其核心创新在于两阶段设计:
- 候选操作预训练阶段:通过逐层特征图蒸馏,为每一层预训练大量候选操作,使其尽可能模仿教师模型对应层的输出。
- 操作选择阶段:利用整数线性优化(ILP)从预训练操作池中快速选择最佳操作组合,构建高效网络架构。
以下逐一详细介绍这两部分,包括原理、数学公式、实现思路和伪代码。
1. 候选操作预训练阶段
原理
在这一阶段,LANA的目标是为教师网络的每一层生成一组高效的候选操作,这些操作通过逐层特征图蒸馏(layer-wise feature map distillation)预训练,以模仿教师模型对应层的输出。教师网络被表示为 T ( x ) = t N ∘ t N − 1 ∘ … ∘ t 1 ( x ) \mathcal{T}(x) = t_N \circ t_{N-1} \circ \ldots \circ t_1(x) T(x)=tN∘tN−1∘…∘t1(x),其中 t i t_i ti 是第 i i i 层的操作, x x x 是输入张量。
- 候选操作池:为每一层 i i i 定义 M M M 个候选操作 { s i j } j = 1 M \{s_{i j}\}_{j=1}^M {sij}j=1M(论文中 M = 197 M=197 M=197),包括经典残差块、倒残差块、密集卷积块等。所有候选操作必须与教师操作 t i t_i ti 的输入输出张量维度一致。
- 预训练目标:通过最小化均方误差(MSE),使候选操作 s i j s_{i j} sij 的输出接近教师操作 t i t_i ti 的输出。优化问题形式化为:
min W ∑ x ∈ X t r ∑ i , j N , M ∥ t i ( x i − 1 ) − s i j ( x i − 1 ; w i j ) ∥ 2 2 , \min_{\mathbf{W}} \sum_{x \in X_{tr}} \sum_{i, j}^{N, M} \left\| t_i(x_{i-1}) - s_{i j}(x_{i-1}; w_{i j}) \right\|_2^2, Wminx∈Xtr∑i,j∑N,M∥ti(xi−1)−sij(xi−1;wij)∥22,
其中:
-
X t r X_{tr} Xtr 是训练数据集。
-
x i − 1 = t i − 1 ∘ t i − 2 ∘ … ∘ t 1 ( x ) x_{i-1} = t_{i-1} \circ t_{i-2} \circ \ldots \circ t_1(x) xi−1=ti−1∘ti−2∘…∘t1(x) 是教师网络第 i − 1 i-1 i−1 层的输出。
-
w i j w_{i j} wij 是候选操作 s i j s_{i j} sij 的参数。
-
∥ ⋅ ∥ 2 2 \left\| \cdot \right\|_2^2 ∥⋅∥22 表示均方误差,衡量输出差异。
-
并行性:该优化问题可分解为 N × M N \times M N×M 个独立子问题,每个子问题优化一个候选操作的参数 w i j w_{i j} wij。这允许并行训练所有候选操作。
-
效率优化:为减少计算开销,LANA在同一前向传播中复用教师网络的中间特征,仅需 O ( M ) O(M) O(M) 次全网络训练(通常1个epoch)即可完成预训练。
实现思路
- 教师网络前向传播:对训练数据 X t r X_{tr} Xtr 进行前向传播,保存每一层 t i t_i ti 的输入 x i − 1 x_{i-1} xi−1 和输出 t i ( x i − 1 ) t_i(x_{i-1}) ti(xi−1)。
- 候选操作初始化:为每层 i i i 初始化 M M M 个候选操作 s i j s_{i j} sij,确保输入输出维度与 t i t_i ti 匹配。
- 逐层蒸馏:对每个候选操作 s i j s_{i j} sij,使用MSE损失优化其参数 w i j w_{i j} wij,使其输出逼近 t i ( x i − 1 ) t_i(x_{i-1}) ti(xi−1)。
- 并行训练:利用多GPU或分布式计算并行优化 N × M N \times M N×M 个子问题。
伪代码
以下是候选操作预训练阶段的伪代码(基于PyTorch风格):
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
# 假设教师网络和候选操作已定义
class TeacherNetwork(nn.Module):
def __init__(self, layers):
super().__init__()
self.layers = nn.ModuleList(layers) # 教师网络的N个层
def forward(self, x):
features = []
for layer in self.layers:
x = layer(x)
features.append(x)
return features
def pretrain_candidate_operations(teacher_net, candidate_ops, train_loader, device):
"""
预训练候选操作
:param teacher_net: 教师网络
:param candidate_ops: 候选操作列表,形状为 [N, M],N为层数,M为每层候选操作数
:param train_loader: 训练数据加载器
:param device: 计算设备
"""
teacher_net.eval()
optimizers = [[torch.optim.Adam(op.parameters(), lr=0.001) for op in ops] for ops in candidate_ops]
mse_loss = nn.MSELoss()
for batch in train_loader:
inputs, _ = batch
inputs = inputs.to(device)
# 获取教师网络每一层的输入和输出
with torch.no_grad():
teacher_features = teacher_net(inputs)
teacher_inputs = [inputs] + teacher_features[:-1] # x_{i-1} for each layer
# 逐层预训练候选操作
for i in range(len(teacher_net.layers)):
teacher_output = teacher_features[i]
teacher_input = teacher_inputs[i]
for j in range(len(candidate_ops[i])):
candidate_op = candidate_ops[i][j].to(device)
optimizer = optimizers[i][j]
# 前向传播
candidate_output = candidate_op(teacher_input)
# 计算MSE损失
loss = mse_loss(candidate_output, teacher_output)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 示例调用
teacher_net = TeacherNetwork([...]) # 教师网络
candidate_ops = [[... for _ in range(M)] for _ in range(N)] # N层,每层M个候选操作
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
pretrain_candidate_operations(teacher_net, candidate_ops, train_loader, device='cuda')
解释
- 高效性:通过逐层蒸馏,LANA将预训练分解为独立子问题,每个子问题仅优化单层输出,降低计算复杂度。复用教师特征进一步减少开销。
- 并行性: N × M N \times M N×M 个子问题可并行执行,适合大规模分布式训练。
- 局限性:MSE损失仅关注单层输出,忽略层间交互,可能导致误差积累。未来可引入全局损失或错误传播机制。
2. 操作选择阶段
原理
在操作选择阶段,LANA从预训练的候选操作池中选择最佳组合,构建满足延迟预算 B \mathcal{B} B 的高效学生网络。LANA通过整数线性优化(ILP)解决这一组合优化问题,显著降低搜索成本。
- 损失近似:LANA假设学生网络的损失可以近似为教师网络损失加上各层操作变化的线性组合:
∑ X t r L ( S ( x ; Z ) , y ) ≈ ∑ X t r L ( T ( x ) , y ) + ∑ i = 1 N a i T z i , \sum_{X_{tr}} \mathcal{L}(\mathcal{S}(x; \mathbf{Z}), y) \approx \sum_{X_{tr}} \mathcal{L}(\mathcal{T}(x), y) + \sum_{i=1}^N \mathbf{a}_i^T \mathbf{z}_i, Xtr∑L(S(x;Z),y)≈Xtr∑L(T(x),y)+i=1∑NaiTzi,
其中:
- L ( T ( x ) , y ) \mathcal{L}(\mathcal{T}(x), y) L(T(x),y) 是教师网络的训练损失(常数)。
- a i ∈ R M \mathbf{a}_i \in \mathbb{R}^M ai∈RM 是第 i i i 层候选操作的得分向量,表示替换操作后损失的变化。
- z i ∈ { 0 , 1 } M \mathbf{z}_i \in \{0,1\}^M zi∈{0,1}M 是one-hot向量,表示第 i i i 层选择的操作。
得分向量 a i \mathbf{a}_i ai 通过将每个候选操作 s i j s_{i j} sij 插入教师网络,测量在小规模标记数据集上的损失变化来计算。
- ILP公式:LANA将搜索问题形式化为以下整数线性规划问题,生成 K K K 个多样化的候选架构:
min Z ( k ) ∑ i = 1 N a i T z i ( k ) , s.t. ∑ i = 1 N b i T z i ( k ) ⩽ B , 1 T z i ( k ) = 1 ∀ i , ∑ i = 1 N z i ( k ) T z i ( k ′ ) ⩽ O , ∀ k ′ < k , \begin{aligned} & \min_{\mathbf{Z}^{(k)}} \sum_{i=1}^N \mathbf{a}_i^T \mathbf{z}_i^{(k)}, \\ & \text{s.t.} \quad \sum_{i=1}^N \mathbf{b}_i^T \mathbf{z}_i^{(k)} \leqslant \mathcal{B}, \quad \mathbf{1}^T \mathbf{z}_i^{(k)} = 1 \quad \forall i, \\ & \quad \sum_{i=1}^N \mathbf{z}_i^{(k)^T} \mathbf{z}_i^{(k')} \leqslant \mathcal{O}, \quad \forall k' < k, \end{aligned} Z(k)mini=1∑NaiTzi(k),s.t.i=1∑NbiTzi(k)⩽B,1Tzi(k)=1∀i,i=1∑Nzi(k)Tzi(k′)⩽O,∀k′<k,
其中:
-
目标:最小化损失增量 ∑ i = 1 N a i T z i ( k ) \sum_{i=1}^N \mathbf{a}_i^T \mathbf{z}_i^{(k)} ∑i=1NaiTzi(k)。
-
预算约束: ∑ i = 1 N b i T z i ( k ) ⩽ B \sum_{i=1}^N \mathbf{b}_i^T \mathbf{z}_i^{(k)} \leqslant \mathcal{B} ∑i=1NbiTzi(k)⩽B 确保总延迟不超过预算, b i ∈ R + M \mathbf{b}_i \in \mathbb{R}_{+}^M bi∈R+M 是操作成本向量(例如延迟)。
-
选择约束: 1 T z i ( k ) = 1 \mathbf{1}^T \mathbf{z}_i^{(k)} = 1 1Tzi(k)=1 保证每层选择一个操作。
-
重叠约束: ∑ i = 1 N z i ( k ) T z i ( k ′ ) ⩽ O \sum_{i=1}^N \mathbf{z}_i^{(k)^T} \mathbf{z}_i^{(k')} \leqslant \mathcal{O} ∑i=1Nzi(k)Tzi(k′)⩽O 限制不同解之间的操作重叠(论文中 O = 0.7 N \mathcal{O} = 0.7N O=0.7N),以增加架构多样性。
-
求解与评估:
- 使用PuLP库求解ILP,生成 K K K 个候选架构(通常 K ≈ 100 K \approx 100 K≈100)。
- 在小规模训练集(ImageNet的6k张图像)上评估 K K K 个架构,选择损失最低者。
- 对选定架构进行微调(100个epoch),结合原始损失和教师-学生蒸馏损失。
实现思路
- 计算得分向量:对每个候选操作 s i j s_{i j} sij,将其插入教师网络,计算损失变化,生成 a i \mathbf{a}_i ai。
- 构建ILP问题:使用PuLP定义目标函数、预算约束、选择约束和重叠约束。
- 求解ILP:迭代求解 K K K 次,生成 K K K 个候选架构。
- 候选架构评估:在小规模数据集上评估 K K K 个架构的损失,选择最佳架构。
- 微调:对最佳架构进行全量微调。
伪代码
以下是操作选择阶段的伪代码(基于PuLP和PyTorch):
import torch
import pulp
import torch.nn as nn
from torch.utils.data import DataLoader
def compute_score_vectors(teacher_net, candidate_ops, eval_loader, device):
"""
计算得分向量 a_i
:param teacher_net: 教师网络
:param candidate_ops: 候选操作列表 [N, M]
:param eval_loader: 小规模评估数据加载器
:param device: 计算设备
:return: 得分向量列表 [N, M]
"""
teacher_net.eval()
score_vectors = [[0.0] * M for _ in range(N)]
criterion = nn.CrossEntropyLoss()
for i in range(N):
for j in range(M):
# 复制教师网络并替换第i层为候选操作
modified_net = copy.deepcopy(teacher_net)
modified_net.layers[i] = candidate_ops[i][j].to(device)
total_loss = 0.0
for batch in eval_loader:
inputs, labels = batch
inputs, labels = inputs.to(device), labels.to(device)
outputs = modified_net(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item()
score_vectors[i][j] = total_loss / len(eval_loader)
return score_vectors
def solve_ilp(score_vectors, cost_vectors, budget, N, M, K, overlap_threshold):
"""
使用ILP搜索K个候选架构
:param score_vectors: 得分向量 [N, M]
:param cost_vectors: 成本向量 [N, M](如延迟)
:param budget: 延迟预算
:param N: 层数
:param M: 每层候选操作数
:param K: 候选架构数
:param overlap_threshold: 重叠约束阈值
:return: K个候选架构的Z矩阵
"""
candidate_architectures = []
for k in range(K):
# 定义ILP问题
prob = pulp.LpProblem(f"Architecture_{k}", pulp.LpMinimize)
# 定义变量 z_i,j,k
z = [[pulp.LpVariable(f"z_{i}_{j}_{k}", cat='Binary') for j in range(M)] for i in range(N)]
# 目标函数
prob += pulp.lpSum(score_vectors[i][j] * z[i][j] for i in range(N) for j in range(M))
# 预算约束
prob += pulp.lpSum(cost_vectors[i][j] * z[i][j] for i in range(N) for j in range(M)) <= budget
# 选择约束
for i in range(N):
prob += pulp.lpSum(z[i][j] for j in range(M)) == 1
# 重叠约束
for prev_z in candidate_architectures:
overlap = pulp.lpSum(z[i][j] * prev_z[i][j] for i in range(N) for j in range(M))
prob += overlap <= overlap_threshold * N
# 求解
prob.solve()
# 提取解
z_solution = [[z[i][j].varValue for j in range(M)] for i in range(N)]
candidate_architectures.append(z_solution)
return candidate_architectures
def evaluate_candidate_architectures(teacher_net, candidate_ops, candidate_architectures, eval_loader, device):
"""
评估K个候选架构,选择最佳者
:param teacher_net: 教师网络
:param candidate_ops: 候选操作列表
:param candidate_architectures: K个候选架构的Z矩阵
:param eval_loader: 评估数据加载器
:param device: 计算设备
:return: 最佳架构索引
"""
criterion = nn.CrossEntropyLoss()
best_loss = float('inf')
best_arch_idx = 0
for idx, z in enumerate(candidate_architectures):
# 构建学生网络
student_net = copy.deepcopy(teacher_net)
for i in range(N):
selected_op_idx = z[i].index(1)
student_net.layers[i] = candidate_ops[i][selected_op_idx].to(device)
# 评估
total_loss = 0.0
for batch in eval_loader:
inputs, labels = batch
inputs, labels = inputs.to(device), labels.to(device)
outputs = student_net(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item()
if total_loss < best_loss:
best_loss = total_loss
best_arch_idx = idx
return best_arch_idx
# 示例调用
N, M = 46, 197 # EfficientNet-B6的层数和候选操作数
teacher_net = TeacherNetwork([...])
candidate_ops = [[... for _ in range(M)] for _ in range(N)]
eval_loader = DataLoader(dataset, batch_size=32, shuffle=False)
cost_vectors = [[... for _ in range(M)] for _ in range(N)] # 预计算的延迟成本
budget = 100.0 # 延迟预算
K = 100 # 候选架构数
overlap_threshold = 0.7
score_vectors = compute_score_vectors(teacher_net, candidate_ops, eval_loader, 'cuda')
candidate_architectures = solve_ilp(score_vectors, cost_vectors, budget, N, M, K, overlap_threshold)
best_arch_idx = evaluate_candidate_architectures(teacher_net, candidate_ops, candidate_architectures, eval_loader, 'cuda')
解释
- 线性近似:通过线性损失近似,LANA将复杂的非线性优化简化为ILP问题,大幅降低计算成本。实验表明,该近似与实际损失高度相关(Kendall Tau相关系数0.966)。
- ILP优势:
- 高效性:首个解通常在1秒内完成, K = 100 K=100 K=100 时仍保持高效。
- 可扩展性:支持大规模操作池( M = 197 M=197 M=197)和深层网络( N = 46 N=46 N=46)。
- 多样性:重叠约束确保生成多样化的候选架构,提高找到优质解的概率。
- 评估与微调:小规模评估(6k图像)快速筛选最佳架构,微调进一步恢复精度。
- 局限性:线性近似忽略层间交互,可能导致次优解。未来可引入非线性得分或迭代优化。
总结
LANA的两阶段框架通过逐层特征图蒸馏和整数线性优化,实现了高效的网络加速:
-
候选操作预训练阶段:
- 使用MSE损失逐层预训练候选操作,模仿教师输出。
- 并行训练和特征复用确保高效性。
- 提供强初始化,为后续搜索奠定基础。
-
操作选择阶段:
- 通过线性损失近似和ILP,快速搜索大规模操作池,生成满足延迟预算的架构。
- 支持多样化架构生成和高效评估。
- 微调结合蒸馏损失,最大化精度恢复。
以上伪代码展示了LANA的核心实现逻辑,研究者可基于此进一步优化,例如改进预训练损失、增强得分计算或引入动态预算调整。LANA的逐层粒度和高效搜索为深度学习模型压缩提供了新思路,尤其适用于边缘设备和实时推理场景。
后记
2025年5月8日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









