







ShortGPT:揭示大型语言模型的层冗余与高效压缩
作为一名研究Transformer架构的学者,你可能已经注意到大型语言模型(LLMs)在性能提升的同时,参数规模也急剧膨胀,动辄达到数十亿甚至万亿级别。这不仅对计算资源提出了巨大挑战,也推动了模型压缩技术的发展。近期,来自Baichuan Inc.和ISCAS的研究团队发表了一篇题为《ShortGPT: Layers in Large Language Models are More Redundant Than You Expect》的论文,提出了一个新颖的视角:LLMs的层级冗余远超预期,并基于此开发了一种简单而高效的层剪枝方法——ShortGPT。本文将为熟悉Transformer的研究者介绍这篇论文的核心贡献,并深入解释其关键数学公式。
论文核心贡献
-
揭示层级冗余的现象
论文通过实验和理论分析,揭示了LLMs(尤其是基于预归一化pre-norm的Transformer架构)在层级上存在显著冗余。研究发现,某些层的输入与输出高度相似,对模型整体功能贡献较小。特别是在预归一化配置下,深层变换的作用被进一步弱化。这种冗余不仅限于Transformer架构,还在非Transformer模型(如Mamba和RWKV)中得到了验证,表明层级冗余可能是现代LLMs的普遍特性。 -
提出Block Influence(BI)指标
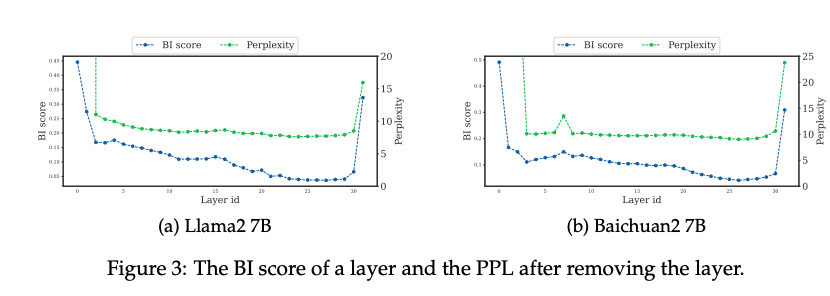
为了量化每层的贡献,论文引入了一个新颖的指标——Block Influence(BI)。BI通过计算层输入与输出的余弦相似度,衡量层对隐藏状态的变换程度。BI得分低的层被认为是冗余层,可以被移除。实验表明,BI指标与层的重要性高度相关,优于其他指标(如顺序、反序或相对幅度)。 -
开发ShortGPT剪枝方法
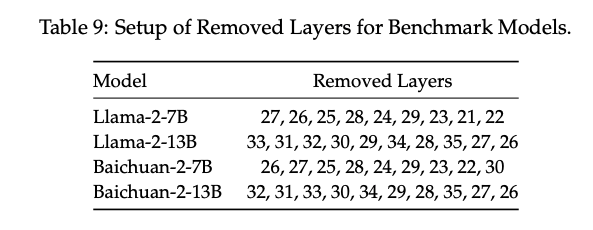
基于BI指标,论文提出了一种简单直接的剪枝方法——ShortGPT,通过移除BI得分较低的层来压缩模型。实验表明,ShortGPT能够在减少约25%参数的同时,保留约90%的性能。例如,在LLaMA 2-13B模型上,移除10层(占总层数的25%)后,MMLU基准性能仅从55.0降至52.2,优于其他复杂剪枝方法(如LLM-Pruner和SliceGPT)。
-
与量化方法的正交性
ShortGPT不仅在性能上表现出色,还与量化方法(如GPTQ)正交,可以结合使用进一步降低计算开销。实验显示,在量化后的LLaMA 2-7B模型上应用ShortGPT,模型性能和吞吐量均得到显著优化。 -
后训练恢复性能
为缓解层移除带来的性能损失,论文探索了后训练策略,包括用轻量级多层感知机(MLP)替换被移除的层并进行重新训练。这种方法有效恢复了部分性能,进一步提升了ShortGPT的实用性。
数学公式解析
论文的核心理论分析围绕预归一化(pre-norm)如何导致层输入与输出高相似度展开,并通过数学推导解释了层冗余的成因。以下是关键公式的详细解析:
Block Influence(BI)公式
BI指标用于衡量第 ( i i i) 层的重要性,定义如下:
B I i = 1 − E X , t X i , t T X i + 1 , t ∥ X i , t ∥ 2 ∥ X i + 1 , t ∥ 2 \mathrm{BI}_i = 1 - \mathbb{E}_{X, t} \frac{X_{i, t}^T X_{i+1, t}}{\|X_{i, t}\|_2 \|X_{i+1, t}\|_2} BIi=1−EX,t∥Xi,t∥2∥Xi+1,t∥2Xi,tTXi+1,t
-
解释:
- ( X i , t X_{i, t} Xi,t) 表示第 ( i i i) 层在时间步 ( t t t) 的隐藏状态(即层的输入)。
- ( X i + 1 , t X_{i+1, t} Xi+1,t) 表示第 ( i i i) 层输出(即第 ( i + 1 i+1 i+1) 层的输入)。
- ( X i , t T X i + 1 , t ∥ X i , t ∥ 2 ∥ X i + 1 , t ∥ 2 \frac{X_{i, t}^T X_{i+1, t}}{\|X_{i, t}\|_2 \|X_{i+1, t}\|_2} ∥Xi,t∥2∥Xi+1,t∥2Xi,tTXi+1,t) 计算输入与输出的余弦相似度,值越接近1,表示两者越相似,层的变换作用越小。
- ( E X , t \mathbb{E}_{X, t} EX,t) 表示对输入样本 ( X X X) 和时间步 ( t t t) 的期望,考虑了多个样本的平均表现。
- ( 1 − 相似度 1 - \text{相似度} 1−相似度) 将相似度转化为“变换程度”,因此BI值越低,说明层的作用越小,越可能是冗余层。
-
意义:
BI通过量化隐藏状态的变换程度,提供了一个直观的层重要性评估标准。实验表明,BI得分与移除层后模型性能下降(PPL升高)的程度呈正相关,验证了其有效性。
预归一化导致高相似度的理论推导
论文在附录A中通过数学推导解释了预归一化(以RMSNorm为例)为何导致深层输入与输出高相似度。核心推导如下:
-
隐藏状态的模增长
根据Xiong等人(2020)的引理,在预归一化Transformer初始化时,第 ( L L L) 层隐藏状态 ( x L x_L xL) 的模满足:( 1 + L 2 ) d ≤ E ( ∥ x L ∥ 2 2 ) ≤ ( 1 + M 2 ) d \left(1 + \frac{L}{2}\right)d \leq \mathbb{E}(\|x_L\|_2^2) \leq \left(1 + \frac{M}{2}\right)d (1+2L)d≤E(∥xL∥22)≤(1+2M)d
其中 ( d d d) 是隐藏状态维度,( M M M) 是模型参数的某一常数。假设 ( x L x_L xL) 的每个分量均值为0,可得:
∥ x L ∥ = Θ ( L ) \|x_L\| = \Theta(\sqrt{L}) ∥xL∥=Θ(L)
这表明随着层数 ( L L L) 增加,隐藏状态的模逐渐增大。
-
层变换的相对贡献
假设第 ( L + 1 L+1 L+1) 层的隐藏状态为:x L + 1 = x L + f L ( x L , θ L ) x_{L+1} = x_L + f_L(x_L, \theta_L) xL+1=xL+fL(xL,θL)
其中 ( f L ( x L , θ L ) f_L(x_L, \theta_L) fL(xL,θL)) 表示注意力或MLP操作,( θ L \theta_L θL) 为可学习参数。论文证明,对于注意力机制,( f L f_L fL) 的模为常数级别:
∥ f L ( x L , θ L ) ∥ = O ( 1 ) \|f_L(x_L, \theta_L)\| = O(1) ∥fL(xL,θL)∥=O(1)
以注意力为例:
f L ( x L , θ L ) = ( softmax ( Q T K ) X L ∥ X L ∥ ⋅ v rms ) W v W q f_L(x_L, \theta_L) = \left(\text{softmax}(Q^T K) \frac{X_L}{\|X_L\|} \cdot v_{\text{rms}}\right) W_v W_q fL(xL,θL)=(softmax(QTK)∥XL∥XL⋅vrms)WvWq
其模为:
∥ f L ∥ = O ( ∥ v rms ∥ ∥ W v ∥ ∥ W q ∥ ) = O ( 1 ) \|f_L\| = O(\|v_{\text{rms}}\| \|W_v\| \|W_q\|) = O(1) ∥fL∥=O(∥vrms∥∥Wv∥∥Wq∥)=O(1)
表明 ( f L f_L fL) 的贡献不随层数 ( L L L) 增长。
-
余弦相似度计算
计算第 ( L L L) 层输入与输出的余弦相似度:cos similarity ( x L + 1 , x L ) = x L + 1 ⋅ x L ∥ x L + 1 ∥ ∥ x L ∥ = ∥ x L ∥ 2 + f L ( x L , θ L ) ⋅ x L ∥ x L + 1 ∥ ∥ x L ∥ \cos \text{similarity}(x_{L+1}, x_L) = \frac{x_{L+1} \cdot x_L}{\|x_{L+1}\| \|x_L\|} = \frac{\|x_L\|^2 + f_L(x_L, \theta_L) \cdot x_L}{\|x_{L+1}\| \|x_L\|} cossimilarity(xL+1,xL)=∥xL+1∥∥xL∥xL+1⋅xL=∥xL+1∥∥xL∥∥xL∥2+fL(xL,θL)⋅xL
分母近似为:
∥ x L + 1 ∥ = ∥ x L + f L ∥ ≈ ∥ x L ∥ ( 因 ∥ f L ∥ ≪ ∥ x L ∥ ) \|x_{L+1}\| = \|x_L + f_L\| \approx \|x_L\| \quad (\text{因} \|f_L\| \ll \|x_L\|) ∥xL+1∥=∥xL+fL∥≈∥xL∥(因∥fL∥≪∥xL∥)
因此:
cos similarity ≥ ∥ x L ∥ 2 ∥ x L + 1 ∥ ∥ x L ∥ − ∥ f L ∥ ∥ x L ∥ ∥ x L + 1 ∥ ∥ x L ∥ = ∥ x L ∥ ∥ x L + 1 ∥ − ∥ f L ∥ ∥ x L + 1 ∥ \cos \text{similarity} \geq \frac{\|x_L\|^2}{\|x_{L+1}\| \|x_L\|} - \frac{\|f_L\| \|x_L\|}{\|x_{L+1}\| \|x_L\|} = \frac{\|x_L\|}{\|x_{L+1}\|} - \frac{\|f_L\|}{\|x_{L+1}\|} cossimilarity≥∥xL+1∥∥xL∥∥xL∥2−∥xL+1∥∥xL∥∥fL∥∥xL∥=∥xL+1∥∥xL∥−∥xL+1∥∥fL∥
代入 ( ∥ x L ∥ = Θ ( L ) \|x_L\| = \Theta(\sqrt{L}) ∥xL∥=Θ(L)) 和 ( ∥ f L ∥ = O ( 1 ) \|f_L\| = O(1) ∥fL∥=O(1)),得到:
cos similarity = Θ ( L L + 1 ) − O ( 1 L + 1 ) \cos \text{similarity} = \Theta\left(\sqrt{\frac{L}{L+1}}\right) - O\left(\sqrt{\frac{1}{L+1}}\right) cossimilarity=Θ(L+1L)−O(L+11)
当 ( L L L) 很大时,( L L + 1 → 1 \sqrt{\frac{L}{L+1}} \to 1 L+1L→1),第二项趋于0,说明深层的输入与输出余弦相似度接近1,变换作用微弱。
- 意义:
该推导表明,预归一化使深层变换的作用被“稀释”,导致层输出与输入高度相似。这种高相似度是层冗余的理论基础,支持了移除深层的可行性。
实验亮点
- 跨模型验证:ShortGPT在LLaMA 2(7B和13B)、Baichuan2(7B和13B)以及非Transformer模型(Mamba-2.8B和RWKV-7B)上均表现出色,证明了方法的通用性。
- 性能与效率兼得:在LLaMA 2-7B-GPTQ模型上,移除27.1%的层后,MMLU性能仅下降约2%,而吞吐量提升19%。
- 后训练优化:通过替换为轻量级MLP并重新训练,ShortGPT在保持低参数量的同时,进一步缩小了性能差距。
局限性与未来方向
尽管ShortGPT表现优异,但论文指出其对多选任务的泛化能力影响较大,具体原因尚未完全阐明。此外,RWKV模型的冗余程度低于Mamba和Transformer,提示不同架构的冗余特性需要进一步探索。未来研究可以结合ShortGPT与其他压缩技术(如稀疏化)或优化训练流程,设计更高效的LLMs。
总结
《ShortGPT》通过揭示LLMs的层级冗余,提出了一种简单而强大的剪枝方法,为Transformer研究者提供了新的压缩视角。其BI指标和数学推导清晰地解释了冗余的来源,而实验结果则展示了方法的高效性和普适性。对于关注模型压缩和高效推理的研究者来说,这篇论文无疑值得深入阅读和实践。
BI解释
为什么 ( X i , t X_{i, t} Xi,t) 是矩阵,而不是向量?
在论文中,( X i , t X_{i, t} Xi,t) 被描述为“第 ( i i i) 层在时间步 ( t t t) 的隐藏状态(即层的输入)”,并且公式中提到 ( X i , t T X i + 1 , t X_{i, t}^T X_{i+1, t} Xi,tTXi+1,t)。你可能会疑惑:语言模型的输入通常是一个序列,每个时间步的隐藏状态不应该是一个向量吗?为什么这里看起来像是矩阵操作?
解答:
在实际的 Transformer 模型实现中,隐藏状态 ( X i , t X_{i, t} Xi,t) 并不是单个时间步的向量,而是整个序列在第 ( i i i) 层的隐藏状态矩阵。让我逐步解释:
-
Transformer 的输入和隐藏状态表示:
- 在 Transformer 模型中,输入是一个序列(例如一个句子),假设序列长度为 ( T T T)(即有 ( T T T) 个 token),每个 token 的嵌入维度为 ( d d d)。因此,输入层的输出(经过嵌入和位置编码后)是一个矩阵 ( X ∈ R T × d X \in \mathbb{R}^{T \times d} X∈RT×d),其中每一行 ( X t ∈ R d X_t \in \mathbb{R}^d Xt∈Rd) 是第 ( t t t) 个 token 的嵌入向量。
- 每一层 Transformer 的输入和输出也是一个矩阵,形状同样为 ( T × d T \times d T×d)。第 ( I I I) 层的输入是 ( X i ∈ R T × d X_i \in \mathbb{R}^{T \times d} Xi∈RT×d),输出是 ( X i + 1 ∈ R T × d X_{i+1} \in \mathbb{R}^{T \times d} Xi+1∈RT×d)。这里的 ( X i , t X_{i, t} Xi,t) 表示矩阵 ( X i X_i Xi) 的第 ( t t t) 行,也就是第 ( i i i) 层、第 ( t t t) 个 token 的隐藏状态向量,形状为 ( 1 × d 1 \times d 1×d)。
-
为什么公式中 ( X i , t X_{i, t} Xi,t) 是向量,但计算时涉及矩阵?:
- 公式中的 ( X i , t X_{i, t} Xi,t) 确实是第 ( t t t) 个 token 的隐藏状态向量(维度为 ( d d d)),但为了高效计算,实际操作中通常会一次性处理整个序列的隐藏状态矩阵 ( X i X_i Xi)。因此,论文中提到的“( X i , t T X i + 1 , t X_{i, t}^T X_{i+1, t} Xi,tTXi+1,t)”实际上是对每一行(每个 token)计算余弦相似度,然后通过期望 ( E X , t \mathbb{E}_{X, t} EX,t) 取平均。
- 具体来说,( X i , t T X i + 1 , t ∥ X i , t ∥ 2 ∥ X i + 1 , t ∥ 2 \frac{X_{i, t}^T X_{i+1, t}}{\|X_{i, t}\|_2 \|X_{i+1, t}\|_2} ∥Xi,t∥2∥Xi+1,t∥2Xi,tTXi+1,t) 是第 ( t t t) 个 token 在第 ( i i i) 层输入和输出之间的余弦相似度。( E X , t \mathbb{E}_{X, t} EX,t) 表示对所有样本 ( X X X) 和所有时间步 ( t t t)(即序列中的所有 token)取平均。
-
矩阵化的计算:
- 在实际实现中,为了高效计算 BI,我们通常不会单独对每个 (
X
i
,
t
X_{i, t}
Xi,t) 和 (
X
i
+
1
,
t
X_{i+1, t}
Xi+1,t) 计算余弦相似度,而是对整个矩阵 (
X
i
X_i
Xi) 和 (
X
i
+
1
X_{i+1}
Xi+1) 进行批量操作:
- ( X i T X i + 1 ∈ R T × T X_i^T X_{i+1} \in \mathbb{R}^{T \times T} XiTXi+1∈RT×T) 计算的是所有 token 对之间的点积。
- 但我们只关心同一 token 的相似度(即 ( X i , t X_{i, t} Xi,t) 和 ( X i + 1 , t X_{i+1, t} Xi+1,t)),所以只取对角线的值。
- 归一化项 ( ∥ X i , t ∥ 2 ∥ X i + 1 , t ∥ 2 \|X_{i, t}\|_2 \|X_{i+1, t}\|_2 ∥Xi,t∥2∥Xi+1,t∥2) 也是对每一行分别计算模长后相乘。
- 最后,通过平均操作(( E X , t \mathbb{E}_{X, t} EX,t)),得到整个序列的平均余弦相似度。
- 在实际实现中,为了高效计算 BI,我们通常不会单独对每个 (
X
i
,
t
X_{i, t}
Xi,t) 和 (
X
i
+
1
,
t
X_{i+1, t}
Xi+1,t) 计算余弦相似度,而是对整个矩阵 (
X
i
X_i
Xi) 和 (
X
i
+
1
X_{i+1}
Xi+1) 进行批量操作:
总结:
( X i , t X_{i, t} Xi,t) 在公式中表示第 ( t t t) 个 token 的隐藏状态向量(维度为 ( d d d)),但实际计算时,( X i X_i Xi) 是一个 ( T × d T \times d T×d) 的矩阵,包含整个序列的隐藏状态。公式中的操作是对每个 token 的隐藏状态计算余弦相似度后取平均。
通过一个例子解释 BI 公式的计算
假设我们有一个小型 Transformer 模型,序列长度 ( T = 3 T = 3 T=3)(3 个 token),隐藏状态维度 ( d = 2 d = 2 d=2),我们来计算第 ( i i i) 层的 BI 得分。
假设数据:
-
第 ( i i i) 层的输入矩阵 ( X i X_i Xi)(形状 ( T × d = 3 × 2 T \times d = 3 \times 2 T×d=3×2)):
X i = [ 1 0 0 1 1 1 ] X_i = \begin{bmatrix} 1 & 0 \\ 0 & 1 \\ 1 & 1 \end{bmatrix} Xi= 101011 - 第 1 个 token 的隐藏状态 ( X i , 1 = [ 1 , 0 ] X_{i, 1} = [1, 0] Xi,1=[1,0])
- 第 2 个 token 的隐藏状态 ( X i , 2 = [ 0 , 1 ] X_{i, 2} = [0, 1] Xi,2=[0,1])
- 第 3 个 token 的隐藏状态 ( X i , 3 = [ 1 , 1 ] X_{i, 3} = [1, 1] Xi,3=[1,1])
-
第 ( i i i) 层的输出矩阵 ( X i + 1 X_{i+1} Xi+1)(形状 ( 3 × 2 3 \times 2 3×2)):
X i + 1 = [ 0.9 0.1 0.1 0.9 0.95 0.95 ] X_{i+1} = \begin{bmatrix} 0.9 & 0.1 \\ 0.1 & 0.9 \\ 0.95 & 0.95 \end{bmatrix} Xi+1= 0.90.10.950.10.90.95 - 第 1 个 token 的隐藏状态 ( X i + 1 , 1 = [ 0.9 , 0.1 ] X_{i+1, 1} = [0.9, 0.1] Xi+1,1=[0.9,0.1])
- 第 2 个 token 的隐藏状态 ( X i + 1 , 2 = [ 0.1 , 0.9 ] X_{i+1, 2} = [0.1, 0.9] Xi+1,2=[0.1,0.9])
- 第 3 个 token 的隐藏状态 ( X i + 1 , 3 = [ 0.95 , 0.95 ] X_{i+1, 3} = [0.95, 0.95] Xi+1,3=[0.95,0.95])
步骤 1:计算每个 token 的余弦相似度
余弦相似度的公式为:
CosSim
(
X
i
,
t
,
X
i
+
1
,
t
)
=
X
i
,
t
T
X
i
+
1
,
t
∥
X
i
,
t
∥
2
∥
X
i
+
1
,
t
∥
2
\text{CosSim}(X_{i, t}, X_{i+1, t}) = \frac{X_{i, t}^T X_{i+1, t}}{\|X_{i, t}\|_2 \|X_{i+1, t}\|_2}
CosSim(Xi,t,Xi+1,t)=∥Xi,t∥2∥Xi+1,t∥2Xi,tTXi+1,t
-
对于第 1 个 token (( t = 1 t = 1 t=1)):
- ( X i , 1 = [ 1 , 0 ] X_{i, 1} = [1, 0] Xi,1=[1,0]), ( X i + 1 , 1 = [ 0.9 , 0.1 ] X_{i+1, 1} = [0.9, 0.1] Xi+1,1=[0.9,0.1])
- 点积:( X i , 1 T X i + 1 , 1 = ( 1 ⋅ 0.9 ) + ( 0 ⋅ 0.1 ) = 0.9 X_{i, 1}^T X_{i+1, 1} = (1 \cdot 0.9) + (0 \cdot 0.1) = 0.9 Xi,1TXi+1,1=(1⋅0.9)+(0⋅0.1)=0.9)
- 模长:( ∥ X i , 1 ∥ 2 = 1 2 + 0 2 = 1 \|X_{i, 1}\|_2 = \sqrt{1^2 + 0^2} = 1 ∥Xi,1∥2=12+02=1), ( ∥ X i + 1 , 1 ∥ 2 = 0. 9 2 + 0. 1 2 = 0.81 + 0.01 = 0.82 ≈ 0.905 \|X_{i+1, 1}\|_2 = \sqrt{0.9^2 + 0.1^2} = \sqrt{0.81 + 0.01} = \sqrt{0.82} \approx 0.905 ∥Xi+1,1∥2=0.92+0.12=0.81+0.01=0.82≈0.905)
- 余弦相似度:( 0.9 1 ⋅ 0.905 ≈ 0.995 \frac{0.9}{1 \cdot 0.905} \approx 0.995 1⋅0.9050.9≈0.995)
-
对于第 2 个 token (( t = 2 t = 2 t=2)):
- ( X i , 2 = [ 0 , 1 ] X_{i, 2} = [0, 1] Xi,2=[0,1]), ( X i + 1 , 2 = [ 0.1 , 0.9 ] X_{i+1, 2} = [0.1, 0.9] Xi+1,2=[0.1,0.9])
- 点积:( X i , 2 T X i + 1 , 2 = ( 0 ⋅ 0.1 ) + ( 1 ⋅ 0.9 ) = 0.9 X_{i, 2}^T X_{i+1, 2} = (0 \cdot 0.1) + (1 \cdot 0.9) = 0.9 Xi,2TXi+1,2=(0⋅0.1)+(1⋅0.9)=0.9)
- 模长:( ∥ X i , 2 ∥ 2 = 0 2 + 1 2 = 1 \|X_{i, 2}\|_2 = \sqrt{0^2 + 1^2} = 1 ∥Xi,2∥2=02+12=1), ( ∥ X i + 1 , 2 ∥ 2 = 0. 1 2 + 0. 9 2 = 0.01 + 0.81 = 0.82 ≈ 0.905 \|X_{i+1, 2}\|_2 = \sqrt{0.1^2 + 0.9^2} = \sqrt{0.01 + 0.81} = \sqrt{0.82} \approx 0.905 ∥Xi+1,2∥2=0.12+0.92=0.01+0.81=0.82≈0.905)
- 余弦相似度:( 0.9 1 ⋅ 0.905 ≈ 0.995 \frac{0.9}{1 \cdot 0.905} \approx 0.995 1⋅0.9050.9≈0.995)
-
对于第 3 个 token (( t = 3 t = 3 t=3)):
- ( X i , 3 = [ 1 , 1 ] X_{i, 3} = [1, 1] Xi,3=[1,1]), ( X i + 1 , 3 = [ 0.95 , 0.95 ] X_{i+1, 3} = [0.95, 0.95] Xi+1,3=[0.95,0.95])
- 点积:( X i , 3 T X i + 1 , 3 = ( 1 ⋅ 0.95 ) + ( 1 ⋅ 0.95 ) = 0.95 + 0.95 = 1.9 X_{i, 3}^T X_{i+1, 3} = (1 \cdot 0.95) + (1 \cdot 0.95) = 0.95 + 0.95 = 1.9 Xi,3TXi+1,3=(1⋅0.95)+(1⋅0.95)=0.95+0.95=1.9)
- 模长:( ∥ X i , 3 ∥ 2 = 1 2 + 1 2 = 2 ≈ 1.414 \|X_{i, 3}\|_2 = \sqrt{1^2 + 1^2} = \sqrt{2} \approx 1.414 ∥Xi,3∥2=12+12=2≈1.414), ( ∥ X i + 1 , 3 ∥ 2 = 0.9 5 2 + 0.9 5 2 = 2 ⋅ 0.9 5 2 = 2 ⋅ 0.9025 ≈ 1.805 ≈ 1.343 \|X_{i+1, 3}\|_2 = \sqrt{0.95^2 + 0.95^2} = \sqrt{2 \cdot 0.95^2} = \sqrt{2 \cdot 0.9025} \approx \sqrt{1.805} \approx 1.343 ∥Xi+1,3∥2=0.952+0.952=2⋅0.952=2⋅0.9025≈1.805≈1.343)
- 余弦相似度:( 1.9 1.414 ⋅ 1.343 ≈ 1.9 1.899 ≈ 1.0 \frac{1.9}{1.414 \cdot 1.343} \approx \frac{1.9}{1.899} \approx 1.0 1.414⋅1.3431.9≈1.8991.9≈1.0)
步骤 2:计算平均余弦相似度 ( E X , t \mathbb{E}_{X, t} EX,t)
假设我们只有这一个样本 (
X
X
X)(在实际中会遍历多个样本),对所有时间步 (
t
t
t) 取平均:
E
X
,
t
(
X
i
,
t
T
X
i
+
1
,
t
∥
X
i
,
t
∥
2
∥
X
i
+
1
,
t
∥
2
)
=
0.995
+
0.995
+
1.0
3
≈
0.9967
\mathbb{E}_{X, t} \left( \frac{X_{i, t}^T X_{i+1, t}}{\|X_{i, t}\|_2 \|X_{i+1, t}\|_2} \right) = \frac{0.995 + 0.995 + 1.0}{3} \approx 0.9967
EX,t(∥Xi,t∥2∥Xi+1,t∥2Xi,tTXi+1,t)=30.995+0.995+1.0≈0.9967
步骤 3:计算 BI 值
B I i = 1 − E X , t ( X i , t T X i + 1 , t ∥ X i , t ∥ 2 ∥ X i + 1 , t ∥ 2 ) = 1 − 0.9967 = 0.0033 \mathrm{BI}_i = 1 - \mathbb{E}_{X, t} \left( \frac{X_{i, t}^T X_{i+1, t}}{\|X_{i, t}\|_2 \|X_{i+1, t}\|_2} \right) = 1 - 0.9967 = 0.0033 BIi=1−EX,t(∥Xi,t∥2∥Xi+1,t∥2Xi,tTXi+1,t)=1−0.9967=0.0033
解释 BI 值:
- BI 值为 0.0033,非常低,说明第 ( i i i) 层的输入和输出余弦相似度非常高(接近 1),也就是说这一层对隐藏状态的变换很小,几乎没有改变输入。
- 根据论文的假设,BI 值越低,说明该层越可能是冗余的,可以考虑移除。
BI 公式的意义
- 直观理解:BI 衡量的是每一层对隐藏状态的“改造程度”。如果 ( X i , t X_{i, t} Xi,t) 和 ( X i + 1 , t X_{i+1, t} Xi+1,t) 几乎相同(余弦相似度接近 1),那么这一层的作用很小,可能是冗余的。
- 实际应用:论文通过 BI 排序所有层,移除 BI 得分最低的层(即最冗余的层),从而实现模型压缩。
总结
- ( X i , t X_{i, t} Xi,t) 是第 ( i i i) 层、第 ( t t t) 个 token 的隐藏状态向量,但实际计算时 ( X i X_i Xi) 是一个矩阵,包含整个序列的隐藏状态。
- BI 公式的核心是计算每一层输入和输出的平均余弦相似度,BI 值越低,说明该层越冗余。
- 通过例子,我们看到 BI 的计算过程:对每个 token 计算余弦相似度,取平均后用 1 减去,得到层的“变换程度”。
后记
2025年5月12日于上海,在grok 3大模型辅助下完成。

















 5236
5236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









