







高效部署MoE大语言模型:专家剪枝与动态跳跃的突破
随着大语言模型(LLM)在自然语言处理领域的广泛应用,Mixture-of-Experts (MoE) 架构因其高效的参数利用率和高性能而备受关注。然而,MoE 模型庞大的参数量(例如 Mixtral 8x7B 的 47B 参数)使其在实际部署中面临内存和计算资源的巨大挑战。近期发表在《Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics》上的论文《Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models》提出了一种创新的专家级稀疏化方法,通过后训练专家剪枝(Expert Pruning)和动态专家跳跃(Dynamic Expert Skipping),显著降低了 MoE 模型的内存占用并提升了推理速度,同时保持了较高的性能。本文将为 MoE 研究者详细介绍该论文的核心方法与贡献。
Paper:https://aclanthology.org/2024.acl-long.334.pdf
论文背景与动机
MoE 模型通过为每个输入 token 选择性地激活 top-k 个专家(例如 Mixtral 8x7B 中的 top-2),在推理时仅使用部分参数(13B 活跃参数),从而实现比传统密集模型(如 LLaMA-2 70B)更高的性能。然而,其静态参数(尤其是专家网络,占总参数的 96%)仍需大量存储和内存资源。例如,加载 Mixtral 8x7B 模型(bf16 格式)需要至少两块 A100-80G GPU。此外,专家之间的贡献不均(部分专家在特定任务中作用较小)为优化提供了可能性。传统权重剪枝方法(如 Wanda 和 SparseGPT)虽能减少参数量,但依赖特定硬件支持(如 FPGA),难以实现即插即用的部署。
针对这些挑战,论文首次提出了一种硬件友好的、基于后训练的专家级稀疏化方法,通过专家剪枝和动态跳跃,优化 MoE 模型的部署效率,适用于通用任务和特定领域任务。
核心方法
论文提出了两种主要技术:后训练专家剪枝和动态专家跳跃,以下逐一解析。
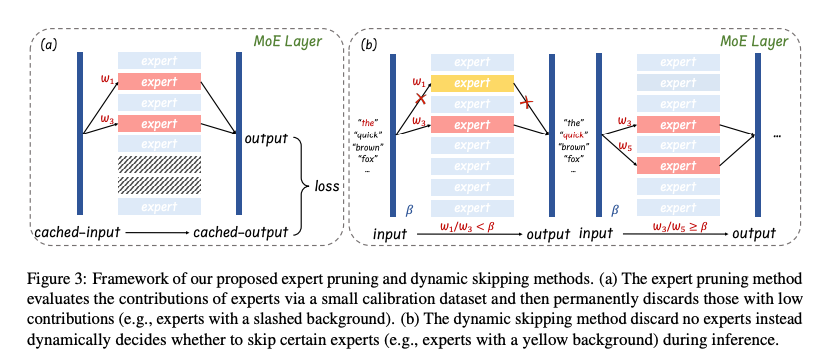
1. 后训练专家剪枝(Post-training Expert Pruning)
专家剪枝旨在通过永久移除不重要的专家来减少模型参数量,从而降低内存需求。方法分为通用任务剪枝和领域特定任务剪枝两种场景,具体流程如下:
-
通用任务剪枝:
- 校准数据集:使用预训练数据集 C4(Raffel et al., 2019)作为校准数据,捕获专家在通用任务上的贡献。
- 层级剪枝:对每个 MoE 层,缓存输入-输出 token 对,枚举保留 r 个专家的组合(例如从 8 个专家剪枝到 6 或 4 个)。
- 优化目标:最小化原始 MoE 层输出
F
(
x
)
\mathcal{F}(\boldsymbol{x})
F(x) 与剪枝后输出
F
′
(
x
,
C
)
\mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C})
F′(x,C) 的 Frobenius 范数(重构损失),即:
min C ∥ F ′ ( x , C ) − F ( x ) ∥ F , s.t. C ⊆ { expert 0 , … , expert n − 1 } , ∣ C ∣ = r \min_{\mathbf{C}} \left\|\mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) - \mathcal{F}(\boldsymbol{x})\right\|_F, \quad \text{s.t.} \quad \mathbf{C} \subseteq \{\text{expert}_0, \ldots, \text{expert}_{n-1}\}, |\mathbf{C}|=r Cmin∥F′(x,C)−F(x)∥F,s.t.C⊆{expert0,…,expertn−1},∣C∣=r - 实现:通过启发式搜索选择重构损失最小的专家子集,保留重要专家,移除其余专家。
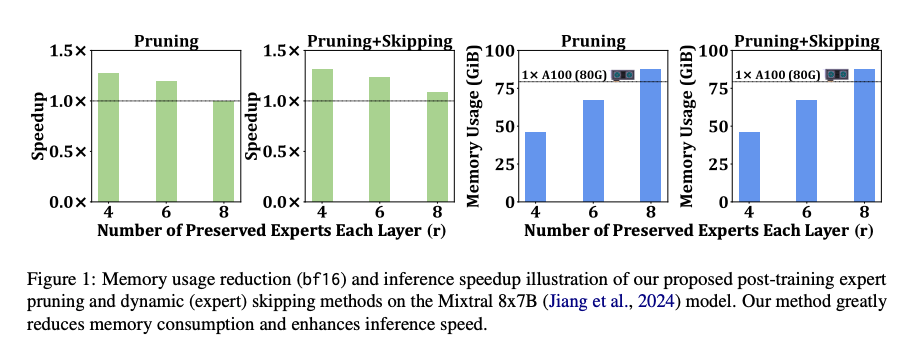
- 结果:以 Mixtral 8x7B 为例,剪枝 2 个专家(r=6)后,模型可在单块 80G GPU 上部署,内存占用从 89,926MB 降至 68,383MB,推理速度提升 1.2 倍;剪枝 4 个专家(r=4)后,内存降至 46,879MB,速度提升 1.27 倍,性能损失仅约 2.9 点(通用任务)。
-
领域特定任务剪枝:
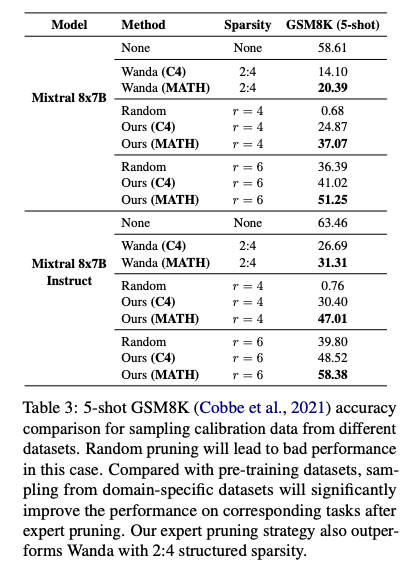
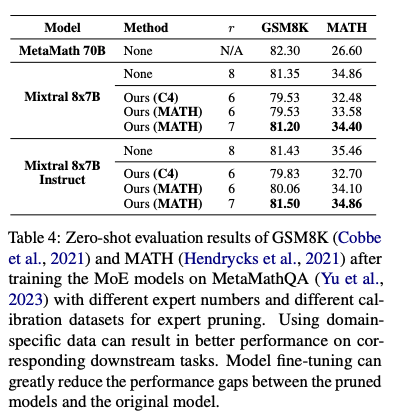
- 问题:通用任务剪枝在领域特定任务(如数学推理)上性能下降明显。例如,使用 C4 剪枝的模型在 GSM8K 数据集上的 5-shot 准确率从 58.61 降至 41.02。
- 解决方案:针对特定领域(如数学),使用领域相关数据集(如 MATH 数据集)作为校准数据,专注于保留对目标任务贡献最大的专家。
- 结果:以 MATH 数据集校准的模型在 GSM8K 上的 5-shot 准确率提升至 51.25(r=6),显著优于 C4 剪枝(41.02)和随机剪枝(36.39)。通过进一步微调(如在 MetaMathQA 数据集上),性能差距可缩小至 1.6 点。
2. 动态专家跳跃(Dynamic Expert Skipping)
动态专家跳跃通过在推理时动态减少活跃专家数量,进一步提升推理速度,而不永久移除专家。方法如下:
- 跳跃机制:在 top-k 专家选择中(例如 k=2),根据路由权重 w e 0 , w e 1 w_{e_0}, w_{e_1} we0,we1(假设 w e 0 ≥ w e 1 w_{e_0} \geq w_{e_1} we0≥we1),当次要专家的权重较小( w e 1 < β w e 0 w_{e_1} < \beta w_{e_0} we1<βwe0)时,跳过该专家,仅使用主专家处理 token。
- 超参数 β \beta β:通过校准数据集计算 w e 1 w e 0 \frac{w_{e_1}}{w_{e_0}} we0we1 的中位数,逐层设置 β \beta β,确保约 50% 的情况下跳过次要专家。
- 实现:动态跳跃无需修改模型结构,可与专家剪枝无缝结合,且不增加内存需求。
- 结果:在 Mixtral 8x7B Instruct 模型上,动态跳跃单独使用可带来 1.08 倍推理加速;结合 r=6 剪枝,推理速度提升至 1.27 倍,性能仅下降 1.41 点;结合 r=4 剪枝,速度提升至 1.33 倍,性能下降 3.65 点。
实验结果与分析
论文在 Mixtral 8x7B 和 Mixtral 8x7B Instruct 模型上进行了广泛实验,验证了方法的有效性。以下是关键结果:
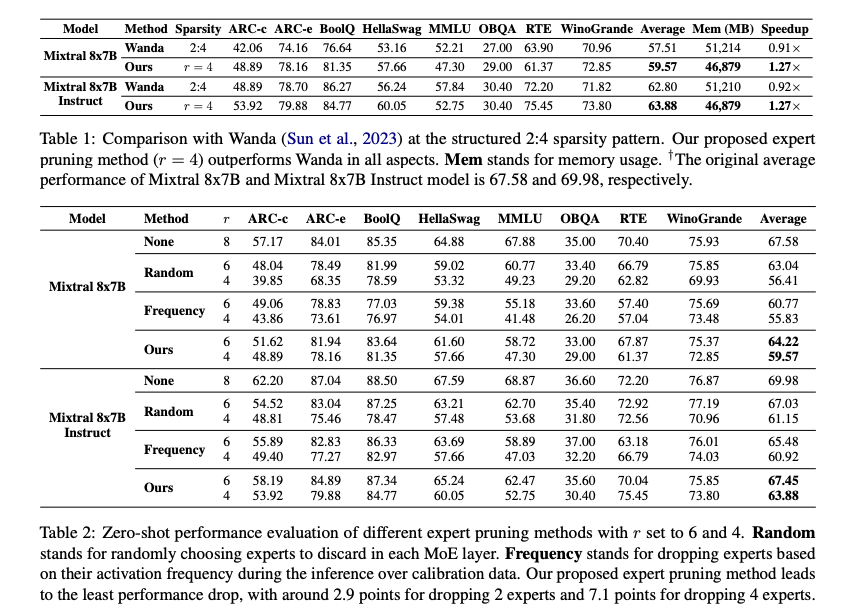
- 通用任务性能(表 1、表 2):
- 与 Wanda(2:4 结构化稀疏)相比,r=4 剪枝在 8 个零-shot 任务上的平均准确率更高(63.88 vs. 62.80,Instruct 模型),且无需专用硬件,推理速度提升 1.27 倍。
- 相比随机剪枝和基于激活频率的剪枝,论文方法在性能保留上表现最佳(r=6 仅下降 2.9 点,r=4 下降 7.1 点)。
- 领域特定任务性能(表 3、表 4):
- 使用 MATH 数据集校准显著提升数学任务性能(例如,r=6 时 GSM8K 准确率从 41.02 提升至 51.25)。
- 微调后,r=7 模型在 GSM8K 上的准确率甚至超过原始 8 专家模型(81.50 vs. 81.43),表明专家数量并非性能的唯一决定因素。
-
推理速度与内存(表 5、表 9):
- 专家剪枝将内存需求从 89,926MB 降至 46,879MB(r=4),推理速度提升最高达 1.33 倍。
- 动态跳跃进一步提升速度,尤其在 r=6 时,结合跳跃的模型达到与 r=4 相同的加速效果,但性能更高。
-
附加分析:
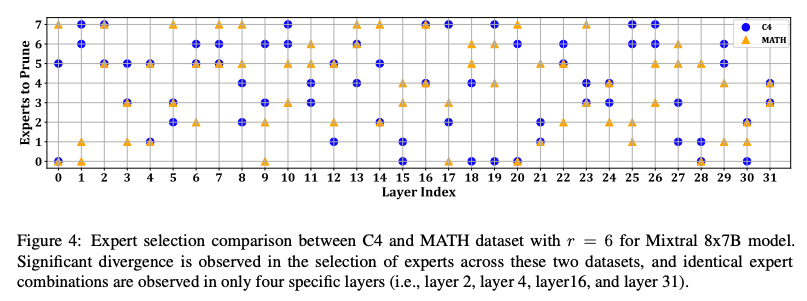
- 专家选择倾向(图 4、图 5):C4 和 MATH 数据集的专家选择分布差异显著,仅在 4 层上重叠,凸显领域特定剪枝的必要性。
- 校准数据集大小(表 7):使用 64 或 128 个序列(2048 token/序列)即可获得稳定性能,表明方法对校准数据量较为鲁棒。
- 层级 vs. 渐进剪枝(表 6):高剪枝率(如 r=4)下,层级剪枝优于渐进剪枝,避免了过拟合小校准数据集的风险。
主要贡献
- 首创专家级稀疏化:论文首次提出针对 MoE 大语言模型的专家级后训练剪枝和动态跳跃方法,填补了decoder-only MoE模型高效部署的空白。
- 硬件友好性:无需专用硬件支持,方法可直接通过现有框架(如 Huggingface Transformers)部署,降低了实际应用的门槛。
- 通用与领域特定优化:通过灵活的校准数据集选择(C4 或 MATH),方法同时支持通用任务和领域特定任务,展现了广泛适用性。
- 显著的效率提升:在 Mixtral 8x7B 上,方法将内存需求减半,推理速度提升至 1.33 倍,性能损失可控(通用任务约 2.9-7.1 点,领域任务经微调后仅 1.6 点)。
- 开源承诺:代码将在 GitHub(https://github.com/Lucky-Lance/Expert_Sparsity)公开,促进社区进一步研究与验证。
局限性与未来方向
尽管方法取得了显著成果,但仍有一些局限性:
- 枚举复杂度:当前方法通过枚举专家组合进行剪枝,适合 4 或 8 专家的模型,但当专家数量增加(如 32)时,计算成本将显著上升。
- 实验范围:实验主要基于 Mixtral 8x7B 模型,未来需在更多 MoE 模型上验证方法的通用性。
- 性能权衡:尽管微调可缓解性能损失,但后训练剪枝仍会导致一定性能下降,需进一步优化。
未来研究可探索以下方向:
- 开发更高效的专家选择算法(如基于梯度的剪枝),降低枚举复杂度。
- 将专家剪枝与权重剪枝、参数量化结合,进一步提升效率。
- 在更多 MoE 模型和任务上验证方法的通用性与可扩展性。
总结
该论文通过专家剪枝和动态跳跃,为 MoE 大语言模型的高效部署提供了创新解决方案。其硬件友好的特性、灵活的校准策略以及显著的内存与速度优化,使其在 MoE 研究领域具有重要意义。对于希望在资源受限环境下部署 MoE 模型的研究者,这篇论文提供了宝贵的思路与实践参考。期待未来基于此工作的进一步优化,推动 MoE 模型在实际应用中的广泛落地。
细节
1. 缓存输入-输出对的细节
在后训练专家剪枝过程中,缓存输入-输出 token 对是为了评估每个专家在 MoE 层中的贡献。具体来说,缓存的过程如下:
-
输入-输出对的含义:
- 对于每个 MoE 层(例如 Mixtral 8x7B 模型的某个 Transformer 层中的 MoE 层),输入是一个 token 的表示向量 x \boldsymbol{x} x,输出是该 MoE 层对该 token 的处理结果 F ( x ) \mathcal{F}(\boldsymbol{x}) F(x)。
- MoE 层通常由一个路由器(Router)和多个专家(Experts)组成。路由器根据输入 token
x
\boldsymbol{x}
x 计算路由权重
w
=
Softmax
(
l
)
\boldsymbol{w} = \text{Softmax}(\boldsymbol{l})
w=Softmax(l),选择 top-k 个专家(例如 k=2),然后输出为这些专家输出的加权和:
F ( x ) = ∑ j = 0 k − 1 w ~ e j ⋅ E e j ( x ) , \mathcal{F}(\boldsymbol{x}) = \sum_{j=0}^{k-1} \tilde{w}_{e_j} \cdot \mathcal{E}_{e_j}(\boldsymbol{x}), F(x)=j=0∑k−1w~ej⋅Eej(x),
其中 w ~ e j \tilde{w}_{e_j} w~ej 是归一化的路由权重, E e j ( x ) \mathcal{E}_{e_j}(\boldsymbol{x}) Eej(x) 是第 e j e_j ej 个专家对输入 x \boldsymbol{x} x 的输出。
-
是否记录每个 token 经过哪些专家:
- 是的,在缓存过程中,模型会对校准数据集(例如 C4)中的每个 token 进行前向传播,记录每个 MoE 层的输入 x \boldsymbol{x} x 和输出 F ( x ) \mathcal{F}(\boldsymbol{x}) F(x)。
- 具体到每个 token 和每个专家,缓存的并不是直接记录“token 经过哪些专家”,而是记录整个 MoE 层的输入 x \boldsymbol{x} x 和最终输出 F ( x ) \mathcal{F}(\boldsymbol{x}) F(x),以及路由器选择的 top-k 专家索引及其对应的路由权重 w \boldsymbol{w} w。这些信息足以在后续枚举中重新计算任意专家子集的输出 F ′ ( x , C ) \mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) F′(x,C),无需再次运行整个专家网络。
- 例如,对于 Mixtral 8x7B 的 32(假设) 个 Transformer 层,每一层有一个 MoE 层(包含 8 个专家),缓存会为每个 token 记录:
- 输入向量 x \boldsymbol{x} x。
- MoE 层的输出 F ( x ) \mathcal{F}(\boldsymbol{x}) F(x)。
- 路由器选择的 top-2 专家索引(例如 e 0 , e 1 e_0, e_1 e0,e1)及其权重 w e 0 , w e 1 w_{e_0}, w_{e_1} we0,we1。
-
缓存的实现:
- 校准数据集(如 C4)被分成 128 个序列,每个序列包含 2048 个 token(见论文第 4.1 节)。对于每个 token,模型执行前向传播,缓存上述信息。
- 缓存数据存储的是每个 MoE 层的输入-输出对,而不是每个专家的单独输出。这是因为专家的输出可以通过缓存的 x \boldsymbol{x} x 和路由权重重新计算,从而避免存储所有专家的输出,节省内存。
2. 枚举过程
枚举是指在每个 MoE 层中,系统地尝试保留不同专家子集(大小为 r r r,例如 r = 6 r=6 r=6 或 r = 4 r=4 r=4),以找到重构损失最小的专家组合。具体过程如下:
-
枚举的目标:
- 对于一个 MoE 层,假设有 n n n 个专家(Mixtral 8x7B 中 n = 8 n=8 n=8),目标是保留 r r r 个专家(例如 r = 6 r=6 r=6 或 r = 4 r=4 r=4),移除 n − r n-r n−r 个专家。
- 枚举所有可能的专家子集
C
\mathbf{C}
C,其中
∣
C
∣
=
r
|\mathbf{C}|=r
∣C∣=r,即从
n
n
n 个专家中选择
r
r
r 个的组合。组合数量为:
( n r ) = n ! r ! ( n − r ) ! . \binom{n}{r} = \frac{n!}{r!(n-r)!}. (rn)=r!(n−r)!n!.- 当 n = 8 , r = 6 n=8, r=6 n=8,r=6 时,组合数为 ( 8 6 ) = 28 \binom{8}{6} = 28 (68)=28。
- 当 n = 8 , r = 4 n=8, r=4 n=8,r=4 时,组合数为 ( 8 4 ) = 70 \binom{8}{4} = 70 (48)=70。
-
枚举的具体步骤:
- 对于每个 MoE 层,基于缓存的输入-输出对,针对每个可能的专家子集
C
\mathbf{C}
C:
- 重新计算输出:使用缓存的输入 x \boldsymbol{x} x 和路由权重 w \boldsymbol{w} w,仅激活子集 C \mathbf{C} C 中的专家,计算剪枝后的 MoE 层输出 F ′ ( x , C ) \mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) F′(x,C)。这需要重新运行子集 C \mathbf{C} C 中的专家网络 E e j ( x ) \mathcal{E}_{e_j}(\boldsymbol{x}) Eej(x),并按原始路由权重(仅保留 C \mathbf{C} C 中专家的权重)加权求和。
- 计算重构损失:计算原始输出
F
(
x
)
\mathcal{F}(\boldsymbol{x})
F(x) 和剪枝后输出
F
′
(
x
,
C
)
\mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C})
F′(x,C) 的 Frobenius 范数:
∥ F ′ ( x , C ) − F ( x ) ∥ F . \left\|\mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) - \mathcal{F}(\boldsymbol{x})\right\|_F. ∥F′(x,C)−F(x)∥F.
通常对校准数据集中的所有 token 取平均损失。 - 选择最优子集:记录所有子集 C \mathbf{C} C 的重构损失,选择损失最小的子集作为保留的专家组合。
- 层级独立性:每个 MoE 层独立进行枚举,不考虑其他层的剪枝结果(层级剪枝,Layer-wise Pruning)。这与渐进剪枝(Progressive Pruning)不同,后者会基于前一层的结果调整后续层的剪枝(见论文表 6)。
- 对于每个 MoE 层,基于缓存的输入-输出对,针对每个可能的专家子集
C
\mathbf{C}
C:
-
计算成本:
- 枚举的复杂度与组合数 ( n r ) \binom{n}{r} (rn) 和校准数据集大小相关。对于 Mixtral 8x7B, n = 8 n=8 n=8,枚举 28(r=6)或 70(r=4)个组合是可行的。论文提到剪枝 r=6 耗时约 30 分钟,r=4 耗时约 90 分钟(见第 4.1 节)。
- 但当专家数量增加(例如 n = 32 n=32 n=32),组合数将急剧上升(例如 ( 32 16 ) ≈ 6.01 × 1 0 8 \binom{32}{16} \approx 6.01 \times 10^8 (1632)≈6.01×108),枚举变得不可行,论文在局限性中提到这一点(第 5 节)。
-
启发式搜索:
- 论文提到使用“启发式搜索”(Heuristic Search)选择最优子集,但未详细描述可能的优化策略。推测可能包括:
- 预先基于路由权重或激活频率过滤掉明显不重要的专家,减少枚举范围。
- 分阶段枚举,先粗略筛选子集,再精调损失计算。
- 这些优化在实际实现中可能通过代码进一步明确(论文承诺代码将在 https://github.com/Lucky-Lance/Expert_Sparsity 公开)。
- 论文提到使用“启发式搜索”(Heuristic Search)选择最优子集,但未详细描述可能的优化策略。推测可能包括:
3. 优化目标是否需要训练
优化目标是否需要训练?答案是不需要。
-
后训练剪枝的定义:
- 论文明确指出,专家剪枝是后训练(Post-training) 方法,不涉及任何参数更新或训练过程(见第 3.2 节)。优化目标 min C ∥ F ′ ( x , C ) − F ( x ) ∥ F \min_{\mathbf{C}} \left\|\mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) - \mathcal{F}(\boldsymbol{x})\right\|_F minC∥F′(x,C)−F(x)∥F 仅通过比较原始输出和剪枝后输出的重构损失来选择最优专家子集 C \mathbf{C} C。
- 具体来说:
- 缓存输入-输出对后,模型参数保持固定。
- 枚举专家子集时,仅重新计算 F ′ ( x , C ) \mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) F′(x,C),不调整专家网络的参数。
- 选择重构损失最小的 C \mathbf{C} C,直接移除不在 C \mathbf{C} C 中的专家,修改模型配置(如 Huggingface Transformers 的配置文件),即可完成剪枝。
-
与训练的区别:
- 训练通常涉及反向传播和参数更新(例如梯度下降),以优化模型在目标任务上的性能。而后训练剪枝仅依赖校准数据评估专家的重要性,无需梯度计算或参数调整。
- 论文中提到的“微调”(Fine-tuning)仅在领域特定任务的实验中用于缓解剪枝后的性能下降(见第 4.2 节,表 4)。微调是在剪枝完成后,对保留的专家网络进行进一步训练(例如在 MetaMathQA 数据集上),但这与剪枝过程本身无关。
-
重构损失的作用:
- 重构损失 ∥ F ′ ( x , C ) − F ( x ) ∥ F \left\|\mathcal{F}^{\prime}(\boldsymbol{x}, \mathbf{C}) - \mathcal{F}(\boldsymbol{x})\right\|_F ∥F′(x,C)−F(x)∥F 是一个评估指标,用于量化剪枝后模型输出的偏离程度,而非训练目标。
- 灵感来源于卷积神经网络的通道剪枝(He et al., 2017),通过最小化输出差异保留最重要的专家,确保剪枝后模型行为尽可能接近原始模型。
4. 补充说明
-
缓存的存储需求:
- 缓存输入-输出对需要存储每个 token 的 x \boldsymbol{x} x、 F ( x ) \mathcal{F}(\boldsymbol{x}) F(x) 和路由权重。假设 Mixtral 8x7B 的隐藏维度为 4096(典型 Transformer 维度),bf16 格式下,每个向量约占 8KB。128 个序列(2048 token/序列)共约 262,144 个 token,每层缓存约 2GB 数据(输入+输出+权重)。对于 32 层,总存储需求可控,但仍需优化以支持更大模型。
-
专家选择倾向:
- 论文图 4 和图 5 显示,不同数据集(C4 vs. MATH)在专家选择上有显著差异,证明了领域特定剪枝的必要性。缓存的路由权重信息帮助分析哪些专家在特定任务中更常被激活。
-
局限性与优化空间:
- 枚举的计算成本限制了方法在大规模专家(例如 32 个)上的适用性。未来可探索基于梯度或重要性分数的剪枝方法,减少枚举需求。
- 缓存过程可进一步优化,例如仅存储部分 token 或使用增量计算。
总结
- 缓存输入-输出对:记录每个 MoE 层的输入 x \boldsymbol{x} x、输出 F ( x ) \mathcal{F}(\boldsymbol{x}) F(x) 和路由权重,不直接存储每个专家的激活情况,而是通过重新计算子集输出评估专家重要性。
- 枚举过程:通过逐层枚举所有可能的 r r r 专家组合,计算重构损失,选择损失最小的子集,复杂度为 ( n r ) \binom{n}{r} (rn)。
- 优化目标无需训练:后训练剪枝仅通过比较重构损失选择专家子集,不涉及参数更新,微调是可选的后续步骤。
后记
2025年5月19日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









