






一、HBase简介
1.1 定义
-- 1. HBase是什么?
1. 分布式
2. 可扩展
3. 支持海量数据的存储
4. NoSQL的数据库。
-- 2. 说明:
a、NoSQL: Not only SQL,不仅仅是一个数据库
b、是基于谷歌的三篇论文之bigtable生成的。
c、HBase:理解为Hadoop base
-- 3. 大数据框架:
a、数据的存储:hdfs / hive / hbase
b、数据的传输:flume / sqoop
c、数据的计算:tez / mr / spark / flink
-- 4. 和传统数据库的差别:
传统数据库的结构:数据库 --> 表 --> 行和列
HBase的结构 : namespace(命名空间) --> table --> 列族 --> 行和列 --> orgion --> store
HBase可以理解为多维的map,嵌套的map结构。
1.2 HBase数据模型
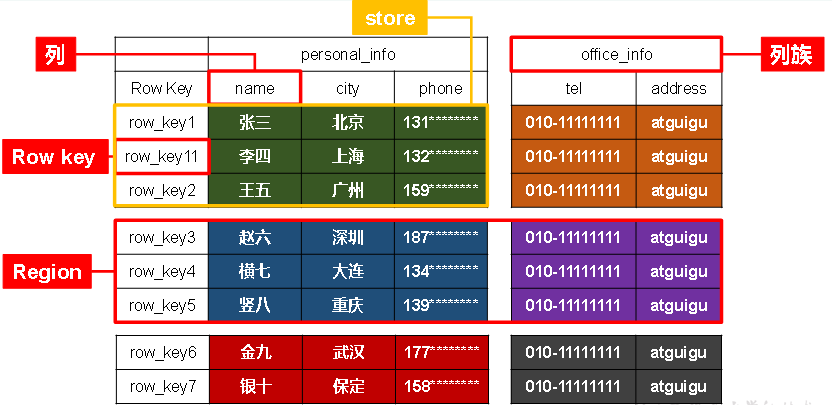
1.2.1 HBase逻辑结构
1.2.2 HBase的物理结构
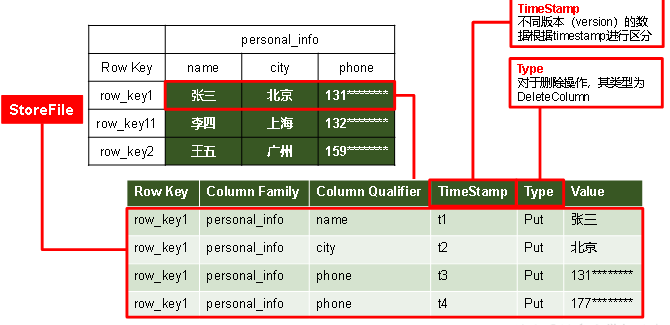
1.2.3 数据模型
--1. HBase表的几个概念
1. 'namespace':命名空间,类似mysql的数据库,在HBase中默认有两个namespace:default/HBase
2. '列族' :
3. 'column' :列,在使用时,格式为:'列族名:列名'
4. 'row' :行,在HBase中,行是逻辑概念上的,在物理内存中,同一行的数据很可能不在一起的。
"那么我们通过什么参数来判断两个数据是不是属于同一行呢"?
就是下面的rowkey,rowkey相同,就表示是同一行的数据。
5. 'rowKey' :行的标签,唯一定位行的标识
6. 'region' :区域,表示多行数据,在HBase中,一个table默认是一个region
7. 'store' :在同一个region中,列族的个数 = store的个数,store有两种:memstore/storefile
8. 'timeStemp':时间戳,表示数据执行的时间,每执行一次操作就会生成一个版本。
9. 'table' :表,可以理解为多维的map,在创建表的时候,只需要声明表名和列族就可以.
"非常适用于非结构化数据,不需要指定数据的格式"
10. 'cell' : 单元格,在表中的同一个位置'某一行的某一列位置',会有多个cell,相同的位置每修改一次,就会生成一个cell。
由{rowkey,列族:列名,time stamp},进行唯一标识。
-- 2. HBase集群的几个概念
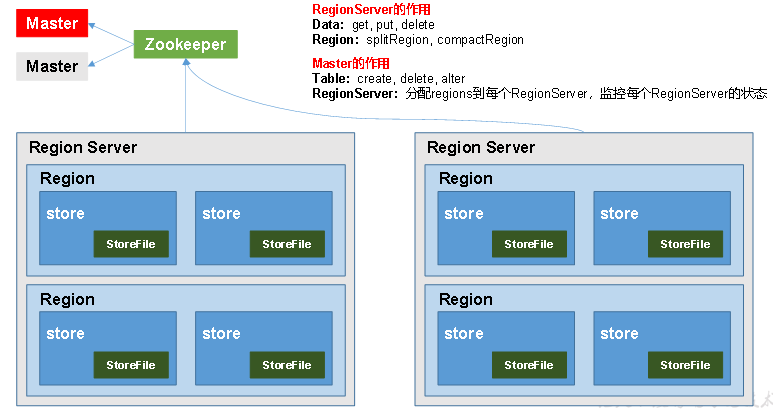
1. 'master':可以理解为hadoop的NM,专门负责管理小弟'regionServer',实现类为:Hmaster
2. 'regionServer':可以理解为hadoop的DM,专门负责管理region中的数据,还有两个组件:WAL'可理解为NM的内存区域的元数
据'和balckcache,至于具体是干嘛的,后面写操作的时候讲,实现类为:HRegionServer
3. 'meta' : 元数据,zookeeper有它的地址,某一个regionServer保存着这个数据。主要有table和region所在的位置。
4. 'zookeeper':① master的高可用 ② RegionServer的监控 ③ Region的元数据管理。
-- 3. 说明:
在底层存储时,数据按照rowkey的字典顺序从小到大进行排列。
二、 HBase的安装
2.1 部署zookeeper和Hadoop
2.2 解压HBase到指定的位置
[atguigu@hadoop105 software]$ tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module
2.3 配置环境变量
[atguigu@hadoop105 ~]$ sudo vim /etc/profile.d/my_env.sh
- 添加
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.0.5
export PATH=$PATH:$HBASE_HOME/bin
2.4 配置HBase的文件
- 修改HBase对应的配置文件
#export HBASE_MANAGES_ZK=true
修改至:
export HBASE_MANAGES_ZK=false
- hbase-site.xml增加如下配置内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop105:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop105,hadoop106,hadoop107</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
- 配置regionservers
hadoop105
hadoop106
hadoop107
2.5 分发HBase
[atguigu@hadoop105 module]$ xsync hbase-2.0.5
2.6 启动HBase
先启动hadoop集群,再启动zk,然后启动HBase
- 单点启动
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
-daemon是指后台启动。
- 群起
[atguigu@hadoop105 hbase-2.0.5]$ start-hbase.sh
-- 说明:
a、会启动当前节点的master
b、在所有节点启动regionServer
c、Hmaster和regionServer都是一个进程。
2.7 查看HBase的页面
网址:hadoop105:16010
2.8 master的高可用(可选)
- 关闭HBase的集群
stop-hbase.sh
- 在conf目录下创建backup-masters文件
touch conf/backup-masters
- 在backup-masters文件中配置高可用HMaster节点
echo hadoop106 > conf/backup-masters
- 将整个conf目录scp到其他节点
xsync conf
三、 HBase的操作
3.1 基本操作
- 进入hbase的客户端
[atguigu@hadoop105 conf]$ hbase shell
- 查看所有namespace中所有的表
hbase(main):001:0> list
TABLE
test:user #test是一个namespace
user #没有写命名空间的,则默认是default
2 row(s)
Took 0.4410 seconds
=> ["test:user", "user"]
3.2 表的操作
- 创建表
--1.语法: create 'namespace:tablename','列族1','列族2',...
如果是namespace是default,则可以省略
--2.实例1:hbase(main):002:0> create 'test','info','info1'
实例2:hbase(main):004:0> create 'test:lianzp','info'
- 添加数据
-- 1. 语法: put 'tablename','rowkey','列族1:列名','value'
说明:shell操作每次只能添加一个值
-- 2. 实例: hbase(main):008:0> put 'user','1001','info1:age',20
- 全局扫描数据
-- 1. 语法: scan 'tablename'
-- 2. 实例: hbase(main):009:0> scan 'user'
-- 3. 打印结果:#如下是显示了4行数据,实际上数据在表中属于3行
ROW COLUMN+CELL
1000 column=info2:sex, timestamp=1592894945017, value=woman
1001 column=info1:age, timestamp=1592911858092, value=20
1001 column=info1:name, timestamp=1592894905511, value=lianzp
1003 column=info1:age, timestamp=1592894925226, value=50
- 扫描指定行的数据
-- 1. 语法:scan 'tablename',{STARTROW=>'rowkey',STOPROW=>'rowkey'}
-- 2. 说明:
a、区间为左闭右开
b、如果STARTROW没有写,则表示开始的rowkey为负无穷,即没有下限,只有上限
如果STOPROW没有写,则表示结束的rowkey为正无穷,即没有上限,只有下限
-- 3. 实例:hbase(main):012:0> scan 'user',{STARTROW=>'1000',STOPROW=>'1003'}
hbase(main):014:0> scan 'user',{STARTROW=>'1000'}
hbase(main):015:0> scan 'user',{STOPROW=>'1001'}
-- 4. 结果:
ROW COLUMN+CELL
1000 column=info2:sex, timestamp=1592894945017, value=woman
1001 column=info1:age, timestamp=1592911858092, value=20
1001 column=info1:name, timestamp=1592894905511, value=lianzp
2 row(s)
- 获取某一行的数据
-- 1. 语法: get 'tablename','rowkey'
-- 2. 实例: get 'user','1001'
- 获取某一行指定列的数据
-- 1. 语法: get 'tablename','rowkey','列族1:列名'
-- 2. 实例: get 'user','1001','info1:age'
- 获取行的数量
-- 1. 语法: count 'tablename'
-- 2. 实例: hbase(main):001:0> count 'user'
- 查询表的结构
-- 1. 语法: describe 'tablename'
-- 2. 实例: hbase(main):002:0> describe 'user'

- 删除某一行某一列的值
-- 1. 语法: delete 'tablename','rowkey','列族1:列名'
-- 2. 实例: hbase(main):002:0> hbase(main):005:0> delete 'user','1001','info1:age'
-- 3. 说明:
a、一个位置默认保留一个版本,如果一个位置被多次修改时,删除当前的数据,再进行查询时,在未flush的情况下,上一个版本的数据
可以被查询出来。
b、此处的删除并不是真正的删除,只是给这个删除的数据打上了一个标记,只有当落盘flush的时候,才会真正的被清理掉。
10 . 删除某一行的全部数据
-- 1. 语法: deleteall 'tablename','rowkey'
-- 2. 实例: hbase(main):020:0> deleteall 'user','1001'
- 清除表数据
-- 1. 语法: truncate 'tablename'
-- 2. 实例:hbase(main):020:0> truncate 'user'
-- 3. 说明:
a、在执行的过程中,首先会自动disable 'user'
b、然后再清空表数据,truncate 'user'
-- 4. 打印结果
Truncating 'user' table (it may take a while):
Disabling table...
Truncating table...
Took 1.5164 seconds
- 删除表
-- 1. 语法: drop 'tablename'
-- 2. 实例: hbase(main):020:0> drop 'user'
-- 3. 说明:
如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first
a、在删除表时,需要手动将表设置为:disable 'tablename'
b、然后再删除,drop 'tablename'
- 多版本
-- 1.设置多版本
alter 'student' ,{NAME => 'info',VERSIONS => 3}
-- 2.查询多版本
get 'student','1001',{COLUMN => 'info:age' ,VERSIONS => 3 }
3.3 namespace操作
- 创建namespace
hbase(main):037:0> create_namespace 'lianzp'
- 查询namespace
hbase(main):039:0> list_namespace
- 创建自定的namespace的表
hbase(main):042:0> create 'lianzp:test','info'
- 查询指定namespace的所有表
hbase(main):044:0> list_namespace_tables 'lianzp'
- 删除namespace
hbase(main):049:0> drop_namespace 'lianzp'
-- 说明:在删除namespace之前,需要先删除namespace的表,删除表时,需要先将表置于不可用的状态。
四、HBase进阶
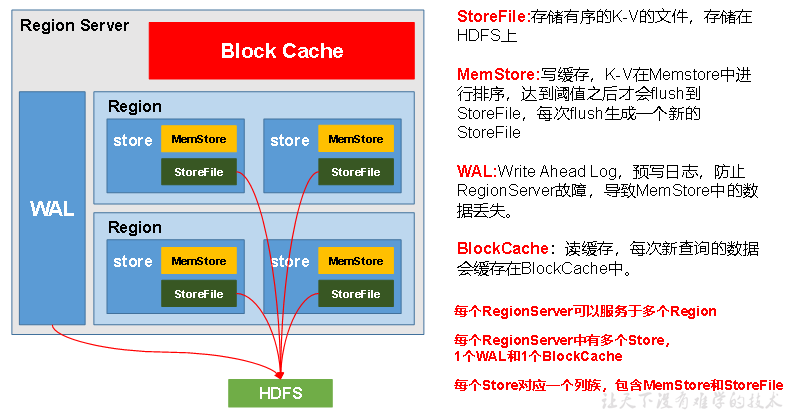
4.1 Region Server的架构
--1. 说明:
a、1个Region Server = 1个WAL + 1个 Block Cache + N个regoin
b、1个Region = 1个MemStore + N个StoreFile
-- 2. Region Server
a、是一个进程,是HBase分布式的一个节点。
-- 3. WAL
a、预防日志,存储在hdfs上,向RegionServer发送请求时,首先会经过WAL,将具体的操作保存下来,然后再进行具体的操作;
b、作用:当regionServer出现故障时,因为WAL保留了具体的操作,所以数据不会丢失。
-- 4. Block Cache
a、读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询
-- 5. Region
a、是一张表中的多行数据,默认是一个Region。
-- 6. Store
a、对应一张表中的列族的个数。
b、有两种,分别是MemStore 和StoreFile
-- 7. memstore
a、数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile
-- 8. StoreFile
a、StoreFile以Hfile的形式存储在HDFS上
b、数据在每个StoreFile中都是有序的
4.2 写流程
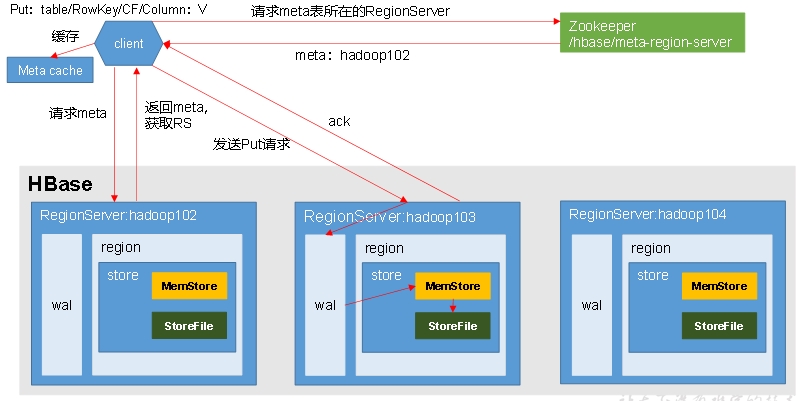
--1. 具体流程:
1. Client先访问zookeeper,请求hbase:meta元数据位于哪个Region Server中。
2. zookeeper返回hbase:meta所在的Region Server地址
3. client访问对应的Region Server,请求hbase:meta元数据信息
4. Region Server返回meta元数据信息
5. client根据写请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。
并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
6. 与目标Region Server进行通讯;
7. 将数据顺序写入(追加)到WAL;
8. WAL将数据写入对应的MemStore,数据会在MemStore进行排序;
9. 完成写数据操作以后,向客户端发送ack;
10. 等达到MemStore的刷写时机后,将数据刷写到HFile。
-- 2. hbase:meta包含哪些信息呢?
命令:scan ‘hbase:meta’
a、rowkey: test,,1592911245995.c42a3b247c7ed78f071
1) test:namespace,命名空间
2) ,,:startkey endkey,起止的rowkey
3) 1592911245995:time stamp ,时间戳
4) .c42a3b247c7ed78f071:前面3个参数的MD5值。
b、column=info:regioninfo : region的信息,
value={ENCODED => c42a3b247c7ed78f071f60721bad78ad, NAME => 'test,,
f60721bad78ad.1592911245995.c42a3b247c7ed78f071f60721bad78ad.', STARTKEY => '', ENDKEY => ''}
c、column=info:seqnumDuringOpen :序列号,value=\x00\x00\x00\x00\x00\x00\x00\x02
d、column=info:server : 该region所在的server,value=hadoop106:16020
e、column=info:serverstartcode : 该region所在的server创建的时间戳,value=1592887276902
f、column=info:sn : value=hadoop106,16020,1592887276902
g、column=info:state :该region的状态,value=OPEN

4.3 MemStore flush时机
-- MemStore刷写时机:
如下一共有4种刷写实时机,任何一个时机点到达后均会进行刷写,刷写分为:
a、刷写:memStore向storeFile中写数据。
b、阻止写:阻止客户端往region中写数据。
-- 时机1:region级别,刷写方式:当前region中所有memstore都刷写
a、'刷写':当某个memstroe的大小达到了'hbase.hregion.memstore.flush.size'(默认值128M),
时,该region中所有memstore都会刷写。
'每一个region有多个store,一个store包含了一个memStore和多个storeFile'
b、'阻止写':当memstore的大小达到了'hbase.hregion.memstore.flush.size(默认值128M)
* hbase.hregion.memstore.block.multiplier(默认值4)'
时512MB,会阻止继续往该memstore写数据。
-- 时机2: regionServer级别,刷写方式:按照所有memstore的数据大小顺序(由大到小)依次进行刷写
a、'刷写':当regionserver中memstore的总大小达到
'java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)
*hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)',
即 0.38 * JVM堆内存
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。
直到region server中所有memstore的总大小减小到上述值以下。
b、'阻止写':当region server中memstore的总大小达到'java_heapsize*hbase.regionserver.global.memstore.size'
(默认值0.4)时,会阻止继续往所有的memstore写数据。
-- 时机3:时间级别:刷写方式:默认1H进行刷写
a、'刷写':到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置
'hbase.regionserver.optionalcacheflushinterval(默认1小时)。'
-- 时机4:关闭hbase时,刷写方式:进行刷写
a、'刷写':关闭hbase即进行刷写。
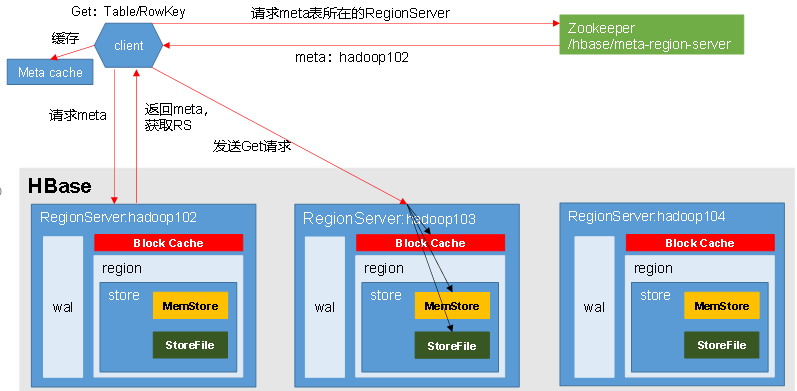
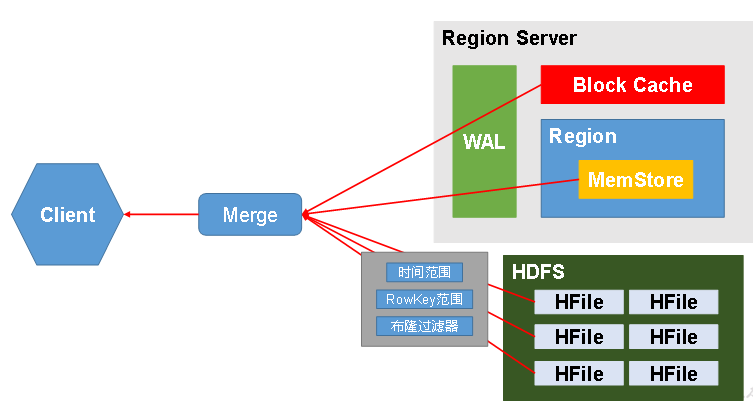
4.4 读流程
-- 整体的流程和写的流程大致一致,主要的区别在于:
1. 读的位置有很多位置
a、block cache
b、memStore
c、StoreFile
2. 不同的位置,均会有数据,但是数据的版本可能不一样,所以当客户端读取多个版本数据时,可能每个位置都需要读取。
3. 读取到每个位置的数据以后,然后进行merge,将数据进行合并,最后发送给客户端。
4. 客户端每次读取到的数据最后会缓存到block cache中,缓冲内存的大小'默认大小为64kb'
4.5 StoreFile Compaction
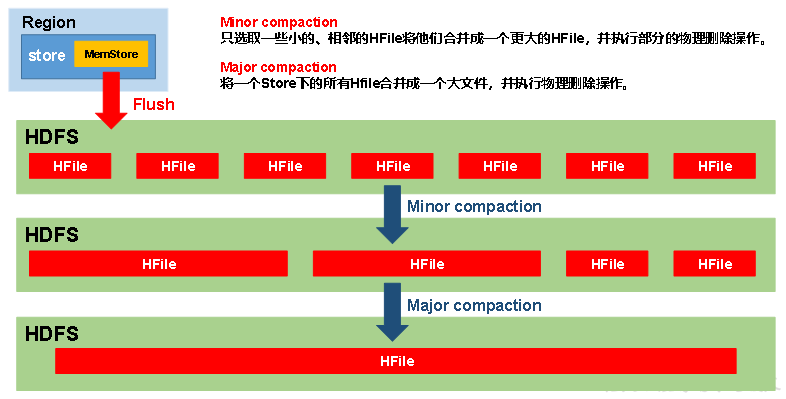
--1. StoreFile文件合并的原因
1. memstore每次刷写都会生成一个新的HFile。--小文件
2. 同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中
3. 为了减少HFile的个数
4. 清理掉过期和删除的数据
--2. 说明:
a、什么是过期的数据?
table中每一个位置有保留的版本数,同一位置进行多次数据修改时,就会有多个版本,在flush之前,数据不会丢失,在落盘时,只会
保留对应版本数量的最新的数据,超过版本数量的数据就属于过期数据。
b、什么是删除的数据?
使用delete删除数据时,数据并不是真正的删除,而是给数据打一个标识,当落盘时,这些数据就会被过滤和删除。
--3. 合并分类:
a、Minor Compaction,小合并,临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。默认是3个文件
b、Major Compaction,大合并,将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
4.6 多版本
#创建一个列族的版本数为2
create 't1' ,{NAME=>'f1,VERSIONS=>2}
#获取两个2个版本
get 't1','1002',{CLOUMN => 'f1:age',VERSIONS => 2}
4.7 Region Split
--1. Region基本介绍
1. 默认一个Table,只有一个Region
2. 随着数据的不断写入,Region会自动进行拆分,'如果设定了region分区的规则,那么这个默认切分规则不会有效'
3. 拆分以后,HMaster有可能会将某个Region转移到其他的Region Server,涉及到数据的迁移,IO
--2. Region切分的时机
'情况1':0.94版本之前
当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该Region就会进行拆分。
'情况2':0.94版本之后
2.当1个region中的某个Store下所有StoreFile的总大小超过Min(initialSize*R^3 ,hbase.hregion.max.filesize),该Region就会进行拆分。其中initialSize的默认值为2*hbase.hregion.memstore.flush.size,R为当前Region Server中属于该Table的Region个数
-- 10G以前,按照取最小值进行切分,10G以后,就每10G切分一次。
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。
'情况3':Hbase 2.0
如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size('默认是128M')分裂,否则按照
hbase.hregion.max.filesize('默认是10G')分裂
4.8 一些命令
--1. 刷写: flush 'tableName'
--2. 防止退出hbase客户端:q
--3. 大合并:major_compact 'tableName'
--4. 小合并:compact 'tableName'
--5. scan查询的时候:scan 'student',{COLUMNS => 'info:age:toLong'}
ROW COLUMN+CELL 1002 column=info:age, timestamp=1593192755078, value=10
五 、 HBase API
--1.DML(Data Manipulation Language)数据操纵语言:使用conn进行操作
适用范围:对数据库中的数据进行一些简单操作,如insert,delete,update,select等.
--2.DDL(Data Definition Language)数据定义语言:使用admin对象进行操作
适用范围:对数据库中的某些对象(例如,database,table)进行管理,如Create,Alter和Drop.
5.1 环境准备
- 添加依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.0.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.5</version>
</dependency>
5.2 DDL
package com.atguigui.lianzp
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, TableName}
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-24 9:59:55
*/
object HBase_DDL {
// 1. 获取zookeeper的连接
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "hadoop105,hadoop106,hadoop107")
val conn: Connection = ConnectionFactory.createConnection(conf)
// 2. 获取hbase的对象
val admin: Admin = conn.getAdmin
def main(args: Array[String]): Unit = {
val result: Boolean = tableExists("user")
// println(result)
// createTable("emp","cf1","cf2")
// deleteTable("user")
// val bool: Boolean = nsExists("lianzp")
// println(bool)
createNS("lianzp")
connclose()
}
def createNS (namespace:String) ={
if (!nsExists(namespace)){
val ns: NamespaceDescriptor.Builder = NamespaceDescriptor.create(namespace)
admin.createNamespace(ns.build())
println(s"namespace:{$namespace}创建成功")
}else {
println(s"namespace:{$namespace}已存在,创建失败")
}
}
def nsExists(namespace : String) ={
// 获取当前所有的namespace的描述,是一个数组
val nss: Array[NamespaceDescriptor] = admin.listNamespaceDescriptors()
// 进行格式转换,获取namespace的名字,然后确定namespace是否存在
nss.map(_.getName).contains(namespace)
}
def deleteTable (table : String) ={
// 获取当前表
val tn: TableName = TableName.valueOf(table)
if (tableExists(table)){
// 删除表,首先需要将表置于不可用的状态才能进行删除
admin.disableTable(tn)
admin.deleteTable(tn)
println(s"{$table}表删除成功")
}else {
println(s"{$table}表不存在,删除失败")
}
}
/**
* 判断表是否存在
*
* @param name
* @return
*/
def tableExists(name: String) = {
val tableName: TableName = TableName.valueOf(name)
val bool: Boolean = admin.tableExists(tableName)
bool
}
/**
* 创建表
* @param tableName
* @param columns
*/
def createTable (tableName :String , columns: String*) ={
//TableDescriptor desc
val tn: TableName = TableName.valueOf(tableName)
val tb: TableDescriptorBuilder = TableDescriptorBuilder.newBuilder(tn)
if (!tableExists(tableName)) {
columns.foreach(cf => {
val descriptor: ColumnFamilyDescriptor = ColumnFamilyDescriptorBuilder
.newBuilder(Bytes.toBytes(cf))
.build()
tb.setColumnFamily(descriptor)
})
admin.createTable(tb.build())
println(s"{$tableName}表创建成功")
}else {
println(s"当前的表{$tableName}已存在")
}
}
def connclose() = {
// 4. 关闭对象
admin.close()
// 5. 关闭连接
conn.close()
}
}
5.3 DML
package com.atguigui.lianzp
import java.util
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{Cell, CellUtil, HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-24 14:16:48
*/
object HBase_DML {
// 1. 获取连接
private var conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "hadoop105,hadoop106,hadoop107")
private val conn: Connection = ConnectionFactory.createConnection(conf)
// 2. 创建hbase的master的对象
private val admin: Admin = conn.getAdmin
def main(args: Array[String]): Unit = {
// 1. 增加数据
// putData("test", "1002", "info", "age", "2")
// 2. 扫描数据
// scanData("test")
// 3. 删除数据
deleteData("test","1001","info","name")
// 4. 获取数据
// getData("test", "1002", "info", "age")
closeConn
}
/**
* 删除数据
*
* @param tableName
* @param rowKey
* @param columnFamily
* @param column
*/
def deleteData(tableName: String, rowKey: String, columnFamily: String, column: String) = {
// 1. 获取表
// 封装表
val tn: TableName = TableName.valueOf(tableName)
// 获取表
val table: Table = conn.getTable(tn)
// 2. 判断表是否存在
if (tableExists(tableName)) {
// 封装一个delete
val delete = new Delete(Bytes.toBytes(rowKey))
val dl: Delete = delete.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column))
// 对表进行删除
table.delete(dl)
}
}
def scanData(tableName: String) = {
// 1. 获取表
val tn: TableName = TableName.valueOf(tableName)
val table: Table = conn.getTable(tn)
// 2.判断表是否存在
if (tableExists(tableName)) {
// 获取一个scan对象
val scan = new Scan()
// 获取表的全局扫描
val scanner: ResultScanner = table.getScanner(scan)
// 这个是用来在java的集合和scala的集合之间互转 (隐式转换)
import scala.collection.JavaConversions._
// 使用迭代器,获取所有数据的集合
val results: util.Iterator[Result] = scanner.iterator()
// 遍历每一行的数据
for (result <- results) {
// 获取每一行数据中所有的单元格
val cells: util.List[Cell] = result.listCells()
if (cells != null) {
// 遍历所有的单元格,只能获取最新的版本
for (cell <- cells) {
println(
s"""
|rowKey= ${Bytes.toString(CellUtil.cloneRow(cell))}
|columnFamily = ${Bytes.toString(CellUtil.cloneFamily(cell))}
|column = ${Bytes.toString(CellUtil.cloneQualifier(cell))}
|value = ${Bytes.toString(CellUtil.cloneValue(cell))}
""".stripMargin)
println("=======================================")
}
}
}
}
}
def getData(tableName: String, rowKey: String, columnFamily: String, column: String) = {
// 1. 获取表
val tn: TableName = TableName.valueOf(tableName)
val table: Table = conn.getTable(tn)
// 2. 判断表是否存在,如果存在则进行查询,如果不存在,则直接退出方法,并提示client查询的表不存在
if (tableExists(tableName)) {
val get = new Get(Bytes.toBytes(rowKey))
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column))
val result: Result = table.get(get)
import scala.collection.JavaConversions._
val cells: util.List[Cell] = result.listCells()
for (cell <- cells) {
println(
s"""
|columnFamliy = ${Bytes.toString(CellUtil.cloneFamily(cell))}
|column = ${Bytes.toString(CellUtil.cloneQualifier(cell))}
|value = ${Bytes.toString(CellUtil.cloneValue(cell))}
|rowKey = ${Bytes.toString(CellUtil.cloneRow(cell))}
""".stripMargin)
}
} else {
println(s"{$tableName}表不存在")
}
}
/**
* 增加数据
*
* @param tableName
* @param rowKey
* @param columnFamily
* @param column
* @param value
*/
def putData(tableName: String, rowKey: String, columnFamily: String, column: String, value: String) = {
// 1. 获取表
val tn: TableName = TableName.valueOf(tableName)
val table: Table = conn.getTable(tn)
// 2. 判断表是否存在,如果存在,则添加数据,如果不存在,则通知client
if (tableExists(tableName)) {
// 封装插入的数据
val put = new Put(Bytes.toBytes(rowKey))
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value))
// 将数据插入
table.put(put)
// 关闭连接
table.close()
println("插入数据操作执行成功")
} else {
println(s"当前表{$tableName}不存在")
}
}
def tableExists(tableName: String) = {
val tn: TableName = TableName.valueOf(tableName)
admin.tableExists(tn)
}
/**
* 关闭连接
*/
def closeConn = {
// 3. 关闭对象
admin.close()
// 4. 关闭连接
conn.close()
}
}
六、HBase的优化
6.1 预分区
1. 通过预分区的方式,使添加的数据进入指定的region中,提前进行数据分区。
2. 当指定预分区的规则以后,那么默认的region split分区原则则不会有效。
3. 每一个region维护着一个startkey和endkey,新增的数据,根据数据的rowkey判断进入哪个region,比较的方式:按照字典的顺序。
4. 在实际开发中,基本上所有的表都会进行预分区,且经常是第一个或者是最后一个region中是没有数据。
6.1.1 手动设定预分区
hbase> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
6.1.2 生成16进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
6.1.3 按照文件设置预分区
#文件内容
aaaa
bbbb
cccc
dddd
create 'staff3','partition3',SPLITS_FILE => 'splits.txt'
6.1.4 使用API设置
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HbaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的Hbase表
hAdmin.createTable(tableDesc, splitKeys);
6.2 RowKey设计
-- 1. 现状
在hbase中,rowkey是唯一区分数据进入哪个region中,如果region设计合理,那么有可能导致数据冗余和数据倾斜。
-- 2. 设计规则
1. 长度:
a、rowkey理论字节数在10-100字节之间最好,一是可以表述较多的数据内容,其次是数据不会过多;
b、数据长度最好是2的n次幂;
c、rowkey的数据长度最好相同;
2. 散列:
a、对rowkey进行散列,采用md5,hash等方式,以防止数据倾斜;
3. 唯一性:防止rowkey相同。
-- 3. 实现方式:
a、字符串反转。如:
20170524000001转成10000042507102
20170524000002转成20000042507102
b、字符串连接:将本来放进列的数据,放到rowkey中,主要是将经常需要使用到的字段/不发生改变的数据拼接到rowkey中。
如:rowkey:id_name_age
6.3 内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~36G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死
6.4 基础优化
-- 1.Zookeeper会话超时时间
'配置文件':hbase-site.xml
'属性':zookeeper.session.timeout
'解释':默认值为90000毫秒(90s)。当某个RegionServer挂掉,90s之后Master才能察觉到。可适当减小此值,以加快Master响应,可调整至600000毫秒。
--2.设置RPC监听数量
'配置文件':hbase-site.xml
'属性':hbase.regionserver.handler.count
'解释':默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
--3.手动控制Major Compaction
'配置文件':hbase-site.xml
'属性':hbase.hregion.majorcompaction
'解释':默认值:604800000秒(7天), Major Compaction的周期,若关闭自动Major Compaction,可将其设为0
在实际开发中,我们一般设置为0,然后通过azkaban进行调度。
--4.优化HStore文件大小
'配置文件':hbase-site.xml
'属性':hbase.hregion.max.filesize
'解释':默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
--5.优化HBase客户端缓存
'配置文件':hbase-site.xml
'属性':hbase.client.write.buffer
'解释':默认值2097152bytes(2M)用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
--6.指定scan.next扫描HBase所获取的行数
'配置文件':hbase-site.xml
'属性':hbase.client.scanner.caching
'解释':用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
--7.BlockCache占用RegionServer堆内存的比例
'配置文件':hbase-site.xml
'属性':hfile.block.cache.size
'解释':默认0.4,读请求比较多的情况下,可适当调大
--8.MemStore占用RegionServer堆内存的比例
'配置文件':hbase-site.xml
'属性':hbase.regionserver.global.memstore.size
'解释':默认0.4,写请求较多的情况下,可适当调大
七、与Hive的集成
7.1 HBase与Hive的对比
--1. Hive
1. 是一个数据仓库:Hive的本质其实就是相当于将HDFS中已经存储的文件在Mysql中做一个双射关系,以方便使用HQL去管理查询;
2. 用于数据分析、清洗
3. 基于HDFS 、 MapReduce: Hive存储的数据依旧在DataNode上,编写的HQL语句终将转换为MapReduce代码执行;
--2. HBase
1. 是数据库
2. 用于存储结构化和非结构化数据
3. 基于HDFS
4. 延迟低。接入在线业务使用
7.2 HBase 与 Hive集成使用
- 在hive-site.xml中添加zookeeper的属性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop105,hadoop106,hadoop107</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
7.3 案例一
-- 需求:在Hive中创建的表,在HBase中可以查询到。
- 在Hive中创建表同时关联HBase
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
- 在Hive中创建临时中间表,用于load文件中的数据
建立上诉的表,不能直接通过load的方式加载数据,需要通过查询其他表的数据进行插入
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
- 向Hive中间表中load数据
load data local inpath '/opt/module/hive/datas/emp' into table emp;
- 通过insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
insert into table hive_hbase_emp_table select * from emp;
- 查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
-- Hive
hive> select * from hive_hbase_emp_table;
-- HBase
Hbase> scan 'hbase_emp_table'
7.4 案例二
-- 需求:在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表
在案例1的基础上进行完成。
- 在Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
- 关联后就可以使用Hive函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;
八、Phoenix
8.1 Phoenix简介
-- 1. Phoenix是什么?
可以理解是HBase的开源SQL皮肤,可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。
-- 2. Phoenix中创建的表存储在HBase中。
8.2 Phoenix特点
1. 容易集成:如Spark 、 Hive 、 Pig 、 Flume 、 MAPReduce
2. 操作容易:DML命令以及通过DDL命令来对表进行操作
3. 支持HBase的二级索引创建。
8.3 Phoenix架构
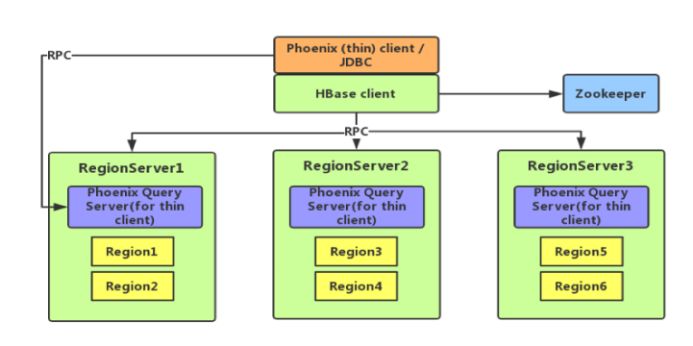
8.4 Phoenix安装
8.4.1 官网地址
http://phoenix.apache.org/
8.4.2 Phoenix部署
- 上传并解压tar包并修改名字
[atguigu@hadoop105 module]$ tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/
[atguigu@hadoop102 module]$ mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix
- 复制server包并拷贝到各个节点的hbase/lib
[atguigu@hadoop102 module]$ cd /opt/module/phoenix/
[atguigu@hadoop102 phoenix]$ cp /opt/module/phoenix/phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
[atguigu@hadoop102 phoenix]$ xsync /opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-server.jar
- 配置环境变量
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
- 重启HBase
[atguigu@hadoop102 ~]$ stop-hbase.sh
[atguigu@hadoop102 ~]$ start-hbase.sh
- 连接Phoenix
[atguigu@hadoop101 phoenix]$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
8.5 Phoenix Shell 操作
--说明:
1、 在Phoenix创建的表,都是存储在hbase中;
2、 Phoenix表的主键,在hbase表中,相当于rowkey,所以在Phoenix建表时,至少设置一个主键,且数据类型最好设置为varchar;
3、 在Phoenix创建表时,表名和字段自动会变成大写,如果想要设置为小写,那么需要使用'双引号';
4、 '单引号'表示字符串;
5、 在HBase创建的表,默认在Phoenix是查询不到的,需要通过映射的方式可以查询。
6、 Phoenix中不支持insert语法,使用了'upsert'代替;
7、 Phoenix的shell操作,很多和sql语法相似,但是也有些语法时不支持的;
8、 Phoenix创建的表,在hbase默认只有一个列族'0';
8.5.1 显示所有表
!table 或 !tables
8.5.2 创建表
create table lianzp (id varchar primary key , age varchar )
- 联合主键
指定多个列的联合作为RowKey
CREATE TABLE IF NOT EXISTS us_population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
8.5.3 插入数据
upsert into student values('1001','zhangsan','beijing');
8.5.4 查询记录
select * from student;
select * from student where id='1001';
8.5.5 删除记录
delete from student where id='1001';
8.5.6 删除表
drop table student;
8.5.7 退出命令行
!quit
8.6 Phoenix与hbase表映射
-- 1. 说明:
a. 在Phoenix创建的表可以在hbase中直接查询到,因为Phoenix创建的表就是在hbase上;
b. 在hbase的表,Phoenix默认不能直接看到,需要使用映射的方式才能看到。
-- 2. 序列化问题:
a、Phoenix数据的序列化器和hbase数据序列化器不一致;
b、Phoenix使用自身的序列化器,而hbase使用的是bytes.toBtes()对数据进行序列化,则导致从Phoenix读取hbase和从hbase读取Phoenix数据时,会出现读出的数据和原表中的数据不一致。现象为:
-- 1). Hbase读取Phoenix表
a、'列名格式问题':列名将Phoenix的字段转换为16进制显示
b、'value格式问题':值类型数据也被转换成了16进制显示
-- 2). Phoenix读取hbase表
a、'列名格式问题':在Phoenix创建的字段和hbase表中的字段一样,但是没有数据
b、'value格式问题':查询的数据和hbase的数据完全不等,描述见下图:
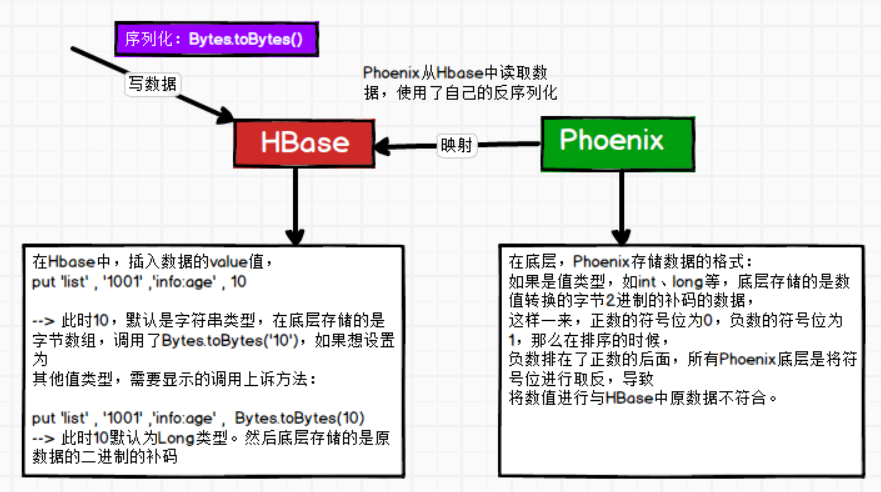
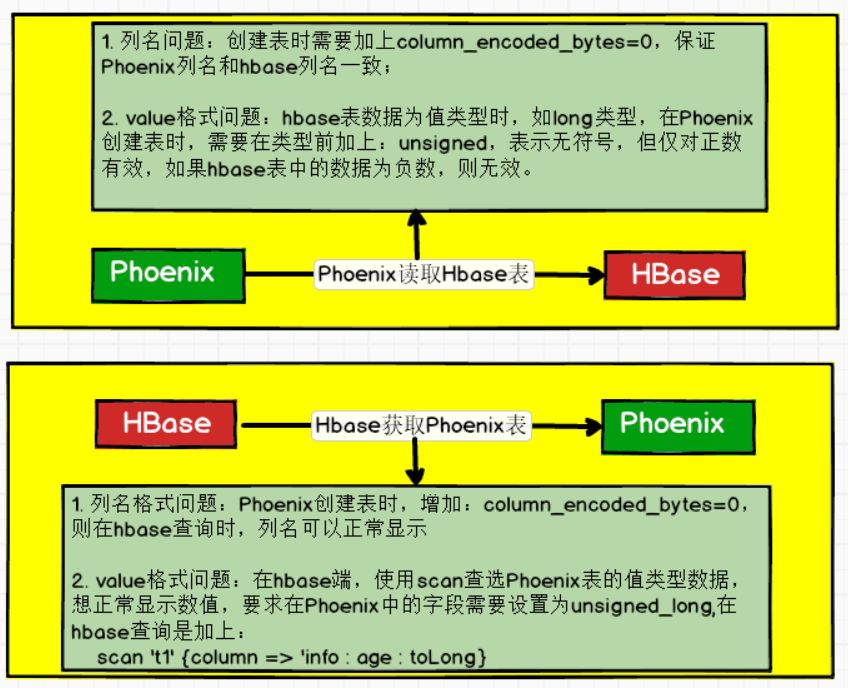
-- 3. 解决方案如下:
8.6.1 Phoenix创建的表
-- 1. 在Phoenix创建的表,在hbase中可以查询到,但是会发现多了每行数据中,会多如下一列数据,'称之为空/虚的keyvalue':
1001 column=0:_0, timestamp=1593071947795, value=x
-- 2. 为什么Phoenix在进行upsert时会添加一个空/虚拟KeyValue?
在hbase表中,rowkey对应Phoenix表中的主键,如果Phoenix中表只有主键,没有其他列,那么在habse的表中,就只有rowkey,没有列族了。所有通过增加这样一列空的列,确保这行数据即有rowkey,也有列族.
-- 3. 官网说明:

8.6.2 HBase创建的表
-- 1. 在HBase表映射方式有两种:视图映射和表映射
-- 2. 在Phoenix实现映射的方式:
a、创建的表名和hbase的表名相同,注意大小写;
b、创建一个主键,用来接收hbase表中的rowkey;
c、其余的字段,声明方式为:hbase表中的:列族.列名
d、最后需要加上:column_encoded_bytes=0,使的Phoenix反序列器为bytes.toBytes(),与hbase序列化器一致,则Phoenix可以
找到hbase表中的列。
-- 3. 说明:
a、创建时表名和字段名一定要相同;
b、如果创建的字段在hbase表不存在,也是可以的。相当于空列
8.6.2.1 视图映射
-- 1. 创建的视图是只读,只能用来进行查询,无法通过视图对原数据进行修改等操作。
- 在hbase准备数据
create 'lianzp' ,'info','info1'
put 'lianzp','1001','info:name','zs'
- Phoenix端操操作
-- 创建视图
create view "lianzp" (id varchar primary key , "info"."name" varchar , "info1"."address" varchar ) column_encoded_bytes=0;
-- 删除视图
drop view "lianzp";
8.6.2.2 表映射
-- 只需要将将create view 改成create table 即可。
8.7 二级索引
8.7.1 修改配置
- 添加如下配置到HBase的HRegionserver节点的hbase-site.xml
<!-- phoenix regionserver 配置参数-->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
8.7.2 全局二级索引
-- 1. 创建全局索引时,会在HBase中建立一张新表
- 创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);
'如果想查询的字段不是索引字段的话,索引表不会被使用,也就是说不会带来查询速度的提升
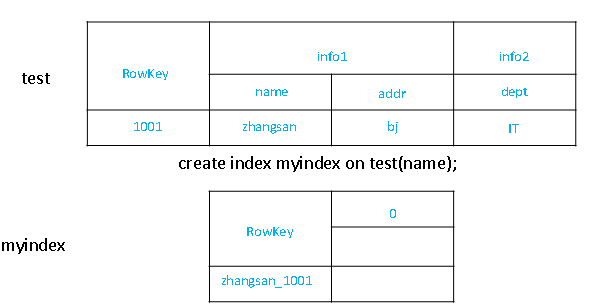
- 创建携带其他字段的全局索引
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
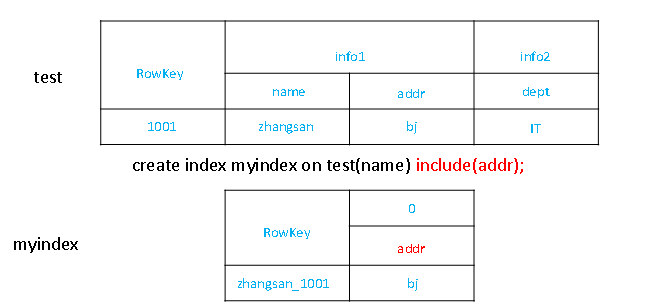
8.7.3 局部二级索引
-- 1. 索引数据和数据表的数据是存放在同一张表中(且是同一个Region)
- 创建局部索引
CREATE LOCAL INDEX my_index ON my_table (my_column);

8.7.4 局部和全局的选择
-- 1. 两种索引的介绍
全局索引:会单独创建一个新的文件,默认是一个region,同时会采用默认的region split的切分规则;
局部索引:在原数据表的插入数据,索引数据和数据表的数据是存放在同一张表中(且是同一个Region)。
-- 2. 在需要创建索引时,我们是选择创建哪种索引呢?
创建索引以后,每次数据的改动都需要更新索引表。
两种索引选择的规则如下:
'情况1':写操作频繁,则选择局部索引,因为数据和索引在同一张表的同一个region中,所以更新索引的数据就不需要跨节点,
避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销;
'情况2': 读操作频繁时,则选择全局索引,因为全局索引中可以直接定位到数据,效率高。
8.8 Phoenix JDBC操作
8.8.1 启动query server
queryserver.py start
8.8.2 创建项目并导入依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-queryserver-client -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
</dependencies>
8.8.3 编写代码
package com.atguigu;
import java.sql.*;
import org.apache.phoenix.queryserver.client.ThinClientUtil;
public class PhoenixTest {
public static void main(String[] args) throws SQLException {
String connectionUrl = ThinClientUtil.getConnectionUrl("hadoop105", 8765);
System.out.println(connectionUrl);
Connection connection = DriverManager.getConnection(connectionUrl);
PreparedStatement preparedStatement = connection.prepareStatement("select * from student");
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + "\t" + resultSet.getString(2));
}
//关闭
connection.close();
}
}















 3669
3669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









