







梯度下降法是一种求取极小值的方法,但其求得的结果只能说是可能为全局最小值,因为还有可能求得的结果是局部最小值,这与初始位置有关。下面用一个例子引入梯度下降法。
从下图中我们能很直观的看出一条紫色的虚线把红点和蓝块分成了两类,如果这时引入一个新的图形(用黑色三角形表示),告诉你这个图形属于这两类中的一类,我们会很自然的把它归到红点所在的那一类中。为什么呢?物以类聚,它和红点都在紫色虚线以下!这是他们共有的特征。
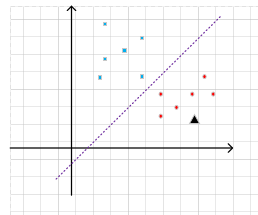
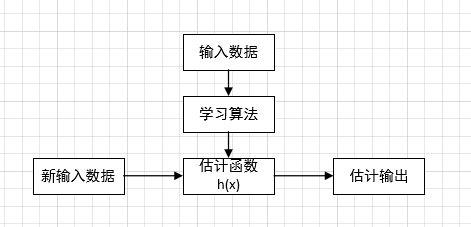
那么如果是计算机,会如何做出判断呢?我们可以编写程序,令紫线下方的区域都属于红点类,紫线上方的区域都属于蓝块类。假设紫线的方程为:y=ax+b。则对于新的输入(x'),计算结果:y'=ax'+b。如果y'>y,则属于蓝块,y'<y,则属于红点。通过这种方法,计算机就能区分蓝块和红点了!但是最重要的是,紫色的线该如何寻找呢?我们先给出机器学习的一个典型过程:
设\[h(x)=\Theta _{0}+\Theta _{1}x\],x为特征,θ为参数。h(x)为函数值。这个h(x)函数是在只有一个特征情况下我们定义的估计函数,是不是很像我们紫色虚线的方程y=ax+b呢?再结合学习过程就能很好的理解了。当有来两个特征时,\[h(x)=\Theta _{0}+\Theta _{1}x_{1}+\Theta _{2}x_{2}\]
,假如我们定义x1=1,则对于两个特征的函数就可以写成:\[h(x)=\sum_{i=0}^{2}\Theta _{i}x_{i}\]
。对于n个特征的估计函数就可以表达为:\[h(x)=\sum_{i=0}^{n}\Theta _{i}x_{i}\]
如果有一些矩阵基础的话我们就能把上面的式子写成矩阵表达式:\[h(x)=\Theta ^{T}X\]
这个估计函数跟θ和x有关,x是输入,而θ是参数。那么我们在求h(x)的时候就要想办法选择一个好的θ,来使我们得出的估计函数h(x)为最好。最好的估计函数h(x)意味着对于一个新的输入数据,给出的估计输出要尽可能的和真正结果相等,也就是说估计输出与真正结果的差值最小:min|h(x)-y|(这里的h(x)是以θ为参数的)。一般来说想让这个值最小,我们会想到用导数的方法,一阶导数为0的值就是最小值。但是求导运算最害怕的就是有绝对值的情况,所以我们可以写成平方的形式:\[(h(x)-y)^{2}\]
我们引入一个函数损失函数J(θ),来表示估计函数的估计能力(J(θ)越大代表估计能力越差):
\[J(\Theta )=\frac{1}{2}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})^{2}\]
这里面1/2是为了求导方便。
到这里我们就完成了铺垫工作了,再理解一下:机器学习的目的是为了求得估计函数h(x),以便对未知输入进行估计。而评价h(x)的好坏是靠损失函数J(θ)决定的。所以我们只要想办法让J(θ)取得最小值就可以了。取得最小值的方法有很多种,比如最小二乘法,这个以后还会说到,不过我们先说梯度下降法。
梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。这里我们把损失函数J(θ)对θ求偏导,然后把当前θ值减去这个偏导数作为θ的新值,这里用“:=”表是赋值语句:
\[\Theta :=\Theta _{i}-\eta \frac{\partial J(\Theta )}{\partial \Theta _{i}}\]
由于偏导公式太难敲,我手写一下:

带入后得出:
\[\Theta :=\Theta _{i}-\eta (h(x)-y)x_{i}\]
其中η表示学习效率,也可以理解成步长。η过小:收敛时间会很长;η过大:可能会越过最小值,进而无法到达。上面的式子是对于一个样本输入的梯度下降算法,对于m个样本输入的梯度下降算法公式为:
\[\Theta :=\Theta _{i}-\eta \sum_{j=1}^{m}(h(x^{(j)})-y^{(j)})x_{i}^{(j)}\]
这个也叫批梯度下降算法,从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度!!所以,这就引入了另外一种方法,随机梯度下降。
for j=1 to m do:\[\Theta :=\Theta _{i}-\eta (h(x^{(j)})-y^{(j)})x_{i}^{(j)}\]
随机梯度下降算法比批梯度下降算法要快!随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









