







在爬取js动态生成的页面时,直接打开页面是获取不到内容的,比如,我在爬取百度手机助手的应用时,就遇到了这样一个问题。在搜索旅游类应用时,返回数据有几页的内容,但是不管你翻到第几页,查看源代码发现都一样,都是第一页内容的源代码。分析原因我觉得可能是这样的:假设百度应用一页内容有八个应用,你把查询提交后他把内容的前8个生成一个html,然后再你翻页时,通过js,ajax等方式替换原来的8个应用,比如你选择第五页时,把返回应用列表的33-40个应用替换原来的1-8的内容。(应该是ajax或者其他表单提交的方式可能性更大,因为纯js不涉及表单提交等后台交互的话,需要在第一次查询时就一次把所有结果返回存储在前端)【个人分析,欢迎指正】
文章思路参考自:http://www.3fwork.com/b401/000595MYM019975/感谢原作者
好了,现在我们目标明确了,找到对应的表达提交(或者js)动作就可以了。这里我们借助谷歌的 开发者工具。我们接下来操作是在谷歌浏览器进行的。
我们从头操作一遍:
1、打开手机助手搜索“旅游”,url: http://shouji.baidu.com/s?wd=旅游
我们得到一个搜索结果:为您搜索到:的应用结果 461 个
这时你可以查看一下源文件。
2、当我们翻一页时 url: http://shouji.baidu.com/s?wd=旅游#page2 发现源文件还是一样的,这便是动态加载造成的,那我们怎么抓后面的界面呢
3、打开谷歌开发者工具:
这时里面没有内容,需要我们加载一次页面: url:http://shouji.baidu.com/s?wd=%E6%97%85%E6%B8%B8#page2
在保持开发者工具如上图的前提下,地址栏输入你要解析的页面url(比如上述url),然后就能看到内容了:
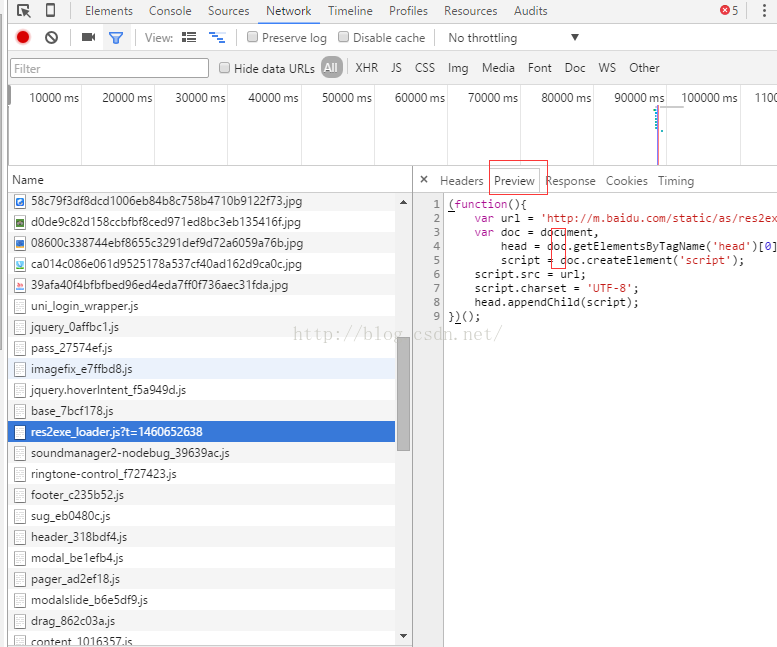
里面有好多东西,需要我们挨个看,但是一会你会发现,真正有价值的东西不是很多。我们最终找到了这个:

这里面的app名字就是我们想要爬取得第二页的app名字,这个就是我们最终想要的内容。
4、在左边那个红框上右键,可以copy链接:http://shouji.baidu.com/s?data_type=app&multi=0&ajax=1&wd=%E6%97%85%E6%B8%B8&page=1&_=1460652637109
打开这个链接我们发现,这个网页的源代码就是我们想要的(其实就是提交了表单)这样是不是很nice!
5、不过这样还不行,我们想要的是一个通用的方法,这个表单提交后面的那个数字该怎么去构造,这里面直接删除就好了,也就是说http://shouji.baidu.com/s?data_type=app&multi=0&ajax=1&wd=%E6%97%85%E6%B8%B8&page=1打开后效果一样,如果有的网站这个是有影响的,你可以多抓几个找规律。
6、通过我们目前的信息,总结一下规律:
http://shouji.baidu.com/s?data_type=app&multi=0&ajax=1&wd=app_type&page=页码
#关于页码,需要解释一下,如果是第n页,页码处填n-1,第一页为0
7、还有可能会出现乱码,需要修改chrome的编码为utf8
这个爬虫的python源码:
#encoding:utf8 # @Author lvpengbin ''' 爬取百度手机助手app_name示例代码,以爬取搜索关键字“旅游”返回结果的第二页为例 url:http://shouji.baidu.com/s?wd=旅游#page2 ''' import sys reload(sys) sys.setdefaultencoding("utf-8") import urllib2 from bs4 import BeautifulSoup url='http://shouji.baidu.com/s?data_type=app&multi=0&ajax=1&wd=%E6%97%85%E6%B8%B8&page=1' req_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0', 'Accept':'*/*', 'Accept-Language':'zh-CN,zh;q=0.8', 'Connection':'close', 'Referer':None #注意如果依然不能抓取的话,这里可以设置抓取网站的host }#这里需要设置header,要不然系统默认的Accept-Language是英语,返回的页面是英文的 req_timeout = 5 req = urllib2.Request(url,None,req_header) resp = urllib2.urlopen(req,None,req_timeout) html = resp.read() soup = BeautifulSoup(html) nodes = soup.find_all("a",onclick="bd_app_dl(this,event);") for node in nodes: print node['data_name'] ''' 输出: 优步 - Uber 蚂蜂窝自由行 飞常准 TripAdvisor 和生活 易到用车 爱城市 智行火车票-12306购票 TripAdvisor 淘在路上旅游 '''















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









