







文章目录
- 一、Selenium
- 二、Splash
- 1. 基本安装
- 2. Splash API 调用
- 3. Splash Lua 脚本
- 4. Splash 对象属性
- 5. Splash 对象方法
- 1) go
- 2) wait
- 3) jsfunc
- 4) evaljs
- 5) runjs
- 6) autoload
- 7) call_later
- 8) http_get
- 9) http_post
- 10) set_content
- 10) html
- 11) png
- 12) jpeg
- 13) har
- 14) url
- 15) get_cookies
- 15) add_cookie
- 16) clear_cookies
- 17) get_viewport_size
- 18) set_viewport_size
- 19) set_viewport_full
- 20) set_user_agent
- 21) set_custom_headers()
- 22) select
- 23) select_all()
- 24) mouse_click
- 6. Splash 负载均衡配置
- 三、Playwright
JavaScript 动态渲染的页面不止 Ajax 一种,例如,有些页面的分页部分是由 JavaScript 生成,而非原始的 HTML 代码,这其中并不包含 Ajax 请求;而有些 Ajax 获取的数据,但是其中包含了许多的加密参数,在难以直接找出规律的情况下,很难直接通过分析 Ajax 爬取数据;
为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也就是可见即可爬。这样我们就不用再去管网页内部的 JavaScript 用了什么算法渲染页面,不用管网页后台的 Ajax 接口到底有哪些参数。
一、Selenium
1. 基本安装
通常来说,我们需要配合 Chrome 浏览器使用 Selenium,所以我们还需要额外安装下 ChromeDriver 和 Chrome 浏览器。
- ChromeDriver 的安装 | 静觅 (cuiqingcai.com)
- Selenium 的安装 | 静觅 (cuiqingcai.com)
- Selenium
- Selenium with Python中文翻译文档 — Selenium-Python中文文档 2 documentation (selenium-python-zh.readthedocs.io)
安装完毕后,我们需要安装 Selenium 库来使用 python 操作;
pip install selenium
2. 基本使用
准备工作做好之后,首先来大体看一下 Selenium 有一些怎样的功能。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
运行代码后发现,会自动弹出一个 Chrome 浏览器。浏览器首先会跳转到百度,然后在搜索框中输入 Python,接着跳转到搜索结果页,如图所示。
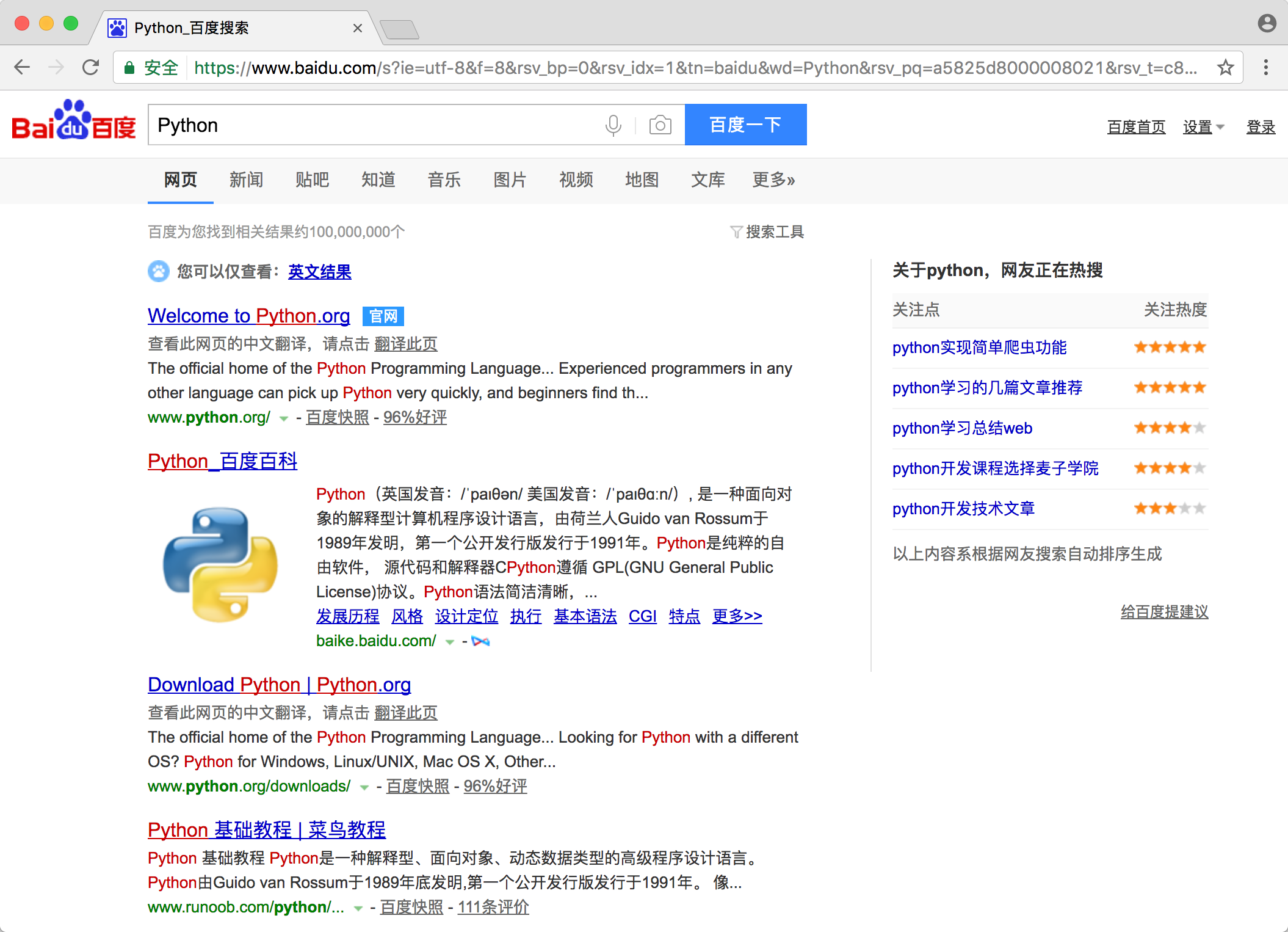
此时在控制台的输出结果如下:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=Python&rsv_pq=c94d0df9000a72d0&rsv_t=07099xvun1ZmC0bf6eQvygJ43IUTTUOl5FCJVPgwG2YREs70GplJjH2F%2BCQ&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=87&rsv_sug4=87
[{'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598', 'domain': '.baidu.com', 'path': '/', 'httpOnly': False, 'name': 'BDORZ', 'expiry': 1491688071.707553}, {'secure': False, 'value': '22473_1441_21084_17001', 'domain': '.baidu.com', 'path': '/', 'httpOnly': False, 'name': 'H_PS_PSSID'}, {'secure': False, 'value': '12883875381399993259_00_0_I_R_2_0303_C02F_N_I_I_0', 'domain': '.www.baidu.com', 'path': '/', 'httpOnly': False, 'name': '__bsi', 'expiry': 1491601676.69722}]
<!DOCTYPE html><!--STATUS OK-->...</html>
源代码过长,在此省略。可以看到,我们得到的当前 URL、Cookies 和源代码都是浏览器中的真实内容。
所以说,如果用 Selenium 来驱动浏览器加载网页的话,就可以直接拿到 JavaScript 渲染的结果了,不用担心使用的是什么加密系统。
下面来详细了解一下 Selenium 的用法。
3. 声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。另外,也支持无界面浏览器 PhantomJS。
此外,我们可以用如下方式初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
这样就完成了浏览器对象的初始化并将其赋值为 browser 对象。接下来,我们要做的就是调用 browser 对象,让其执行各个动作以模拟浏览器操作。
4. 访问页面
我们可以用 get() 方法来请求网页,参数传入链接 URL 即可。比如,这里用 get() 方法访问淘宝,然后打印出源代码,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
运行后发现,弹出了 Chrome 浏览器并且自动访问了淘宝,然后控制台输出了淘宝页面的源代码,随后浏览器关闭。
通过这几行简单的代码,我们可以实现浏览器的驱动并获取网页源码,非常便捷。
5. 查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
单个节点
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码,如图所示。
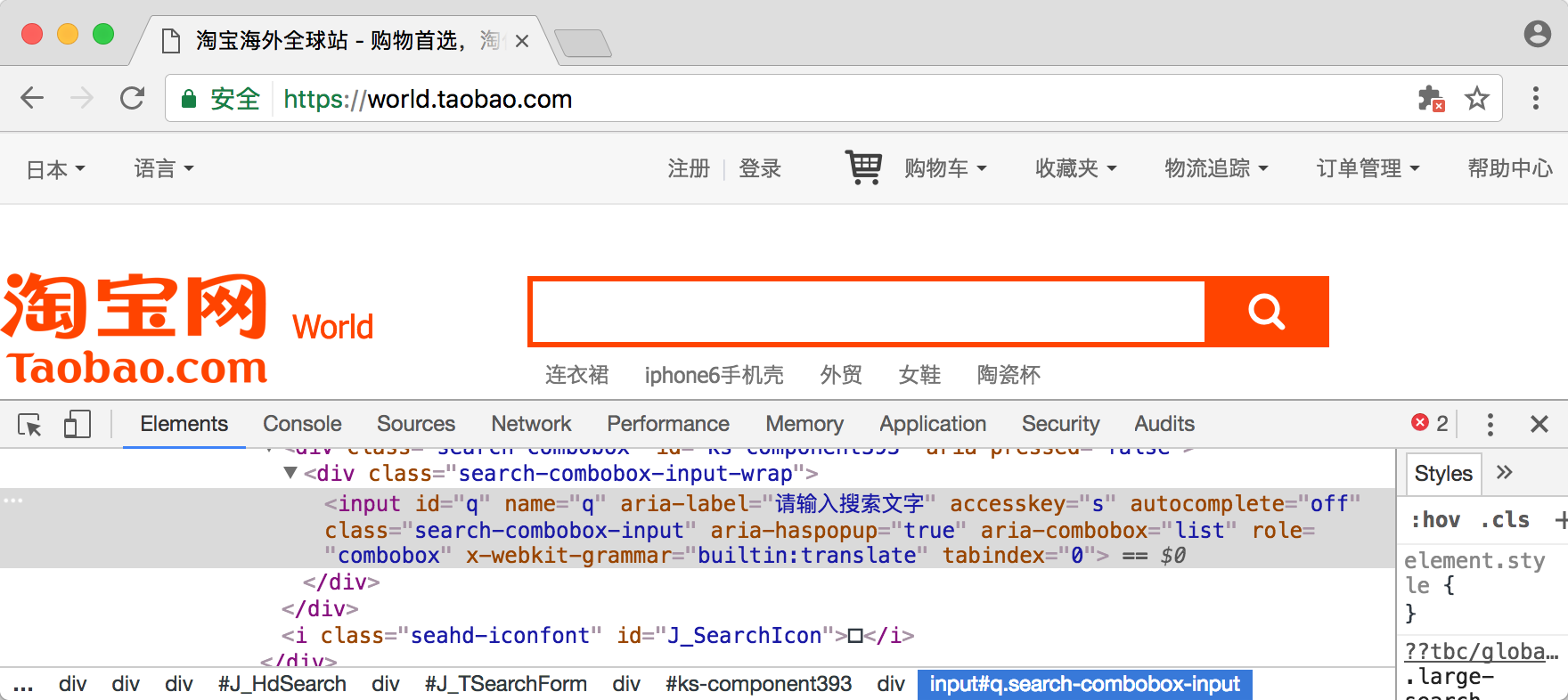
可以发现,它的 id 是 q,name 也是 q。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。比如,find_element_by_name() 是根据 name 值获取,find_element_by_id() 是根据 id 获取。另外,还有根据 XPath、CSS 选择器等获取的方式。
我们用代码实现一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)
browser.close()
这里我们使用 3 种方式获取输入框,分别是根据 ID、CSS 选择器和 XPath 获取,它们返回的结果完全一致。运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.5649563096161541-1")>
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.5649563096161541-1")>
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.5649563096161541-1")>
可以看到,这 3 个节点都是 WebElement 类型,是完全一致的。
这里列出所有获取单个节点的方法:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
另外,Selenium 还提供了通用方法 find_element(),它需要传入两个参数:查找方式 By 和值。实际上,它就是 find_element_by_id() 这种方法的通用函数版本,比如 find_element_by_id(id) 就等价于 find_element(By.ID, id),二者得到的结果完全一致。
我们用代码实现一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()
实际上,这种查找方式的功能和上面列举的查找函数完全一致,不过参数更加灵活。
多个节点
如果查找的目标在网页中只有一个,那么完全可以用 find_element() 方法。但如果有多个节点,再用 find_element() 方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用 find_elements() 这样的方法。注意,在这个方法的名称中,element 多了一个 s,注意区分。
就可以这样来实现:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()
运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-1")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-2")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-3")>...<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-16")>]
这里简化了输出结果,中间部分省略。
可以看到,得到的内容变成了列表类型,列表中的每个节点都是 WebElement 类型。
也就是说,如果我们用 find_element() 方法,只能获取匹配的第一个节点,结果是 WebElement 类型。如果用 find_elements() 方法,则结果是列表类型,列表中的每个节点是 WebElement 类型。
这里列出所有获取多个节点的方法:
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
当然,我们也可以直接用 find_elements() 方法来选择,这时可以这样写:
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
结果是完全一致的。
6. 节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()
这里首先驱动浏览器打开淘宝,然后用 find_element_by_id() 方法获取输入框,然后用 send_keys() 方法输入 iPhone 文字,等待一秒后用 clear() 方法清空输入框,再次调用 send_keys() 方法输入 iPad 文字,之后再用 find_element_by_class_name() 方法获取搜索按钮,最后调用 click() 方法完成搜索动作。
更多的操作可以参见官方文档的交互动作介绍:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement。
7. 动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明 ActionChains 对象并将其赋值为 actions 变量,然后通过调用 actions 变量的 drag_and_drop() 方法,再调用 perform() 方法执行动作,此时就完成了拖曳操作

更多的动作链操作可以参考官方文档的动作链介绍:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains。
8. 执行 JavaScript
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
这里就利用 execute_script() 方法将进度条下拉到最底部,然后弹出 alert 提示框。
所以说有了这个方法,基本上 API 没有提供的所有功能都可以用执行 JavaScript 的方式来实现了。
9. 获取节点信息
前面说过,通过 page_source 属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery 等)来提取信息了。
不过,既然 Selenium 已经提供了选择节点的方法,返回的是 WebElement 类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
获取属性
我们可以使用 get_attribute() 方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
运行之后,程序便会驱动浏览器打开知乎页面,然后获取知乎的 logo 节点,最后打印出它的 class。
控制台的输出结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="e08c0f28d7f44d75ccd50df6bb676104", element="0.7236390660048155-1")>
zu-top-link-logo
通过 get_attribute() 方法,然后传入想要获取的属性名,就可以得到它的值了。
获取文本值
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于 Beautiful Soup 的 get_text() 方法、pyquery 的 text() 方法,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)
这里依然先打开知乎页面,然后获取 “提问” 按钮这个节点,再将其文本值打印出来。
控制台的输出结果如下:
提问
获取 ID、位置、标签名、大小
另外,WebElement 节点还有一些其他属性,比如 id 属性可以获取节点 id,location 属性可以获取该节点在页面中的相对位置,tag_name 属性可以获取标签名称,size 属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)
这里首先获得 “提问” 按钮这个节点,然后调用其 id、location、tag_name、size 属性来获取对应的属性值。
10. 切换 Frame
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。示例如下:
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
控制台输出:
NO LOGO
<selenium.webdriver.remote.webelement.WebElement (session="4bb8ac03ced4ecbdefef03ffdc0e4ccd", element="0.13792611320464965-2")>
RUNOOB.COM
这里还是以前面演示动作链操作的网页为实例,首先通过 switch_to.frame() 方法切换到子 Frame 里面,然后尝试获取子 Frame 里的 logo 节点(这是不能找到的),如果找不到的话,就会抛出 NoSuchElementException 异常,异常被捕捉之后,就会输出 NO LOGO。接下来,重新切换回父级 Frame,然后再次重新获取节点,发现此时可以成功获取了。
所以,当页面中包含子 Frame 时,如果想获取子 Frame 中的节点,需要先调用 switch_to.frame() 方法切换到对应的 Frame,然后再进行操作。
11. 延时等待
在 Selenium 中,get() 方法会在网页框架加载结束后结束执行,此时如果获取 page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待
当使用隐式等待执行测试的时候,如果 Selenium 没有在 DOM 中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
在这里我们用 implicitly_wait() 方法实现了隐式等待。
显式等待
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
这里首先引入 WebDriverWait 这个对象,指定最长等待时间,然后调用它的 until() 方法,传入要等待条件 expected_conditions。比如,这里传入了 presence_of_element_located 这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是 ID 为 q 的节点搜索框。
这样可以做到的效果就是,在 10 秒内如果 ID 为 q 的节点(即搜索框)成功加载出来,就返回该节点;如果超过 10 秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为 element_to_be_clickable,也就是可点击,所以查找按钮时查找 CSS 选择器为 .btn-search 的按钮,如果 10 秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过 10 秒还不可点击,也就是没有加载出来,就抛出异常。
运行代码,在网速较佳的情况下是可以成功加载出来的。
控制台的输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="07dd2fbc2d5b1ce40e82b9754aba8fa8", element="0.5642646294074107-1")>
<selenium.webdriver.remote.webelement.WebElement (session="07dd2fbc2d5b1ce40e82b9754aba8fa8", element="0.5642646294074107-2")>
可以看到,控制台成功输出了两个节点,它们都是 WebElement 类型。
如果网络有问题,10 秒内没有成功加载,那就抛出 TimeoutException 异常,此时控制台的输出如下:
TimeoutException Traceback (most recent call last)
<ipython-input-4-f3d73973b223> in <module>()
7 browser.get('https://www.taobao.com/')
8 wait = WebDriverWait(browser, 10)
----> 9 input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
关于等待条件,其实还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出,传入定位元组,如 (By.ID, ‘p’) |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it frame | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在 DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回 True,否则返回 False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回 True,否则返回 False |
| alert_is_present | 是否出现 Alert |
| 更多详细的等待条件的参数及用法介绍可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions。 |
12. 前进后退
平常使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
这里我们连续访问 3 个页面,然后调用 back() 方法回到第二个页面,接下来再调用 forward() 方法又可以前进到第三个页面。
13. Cookies
使用 Selenium,还可以方便地对 Cookies 进行操作,例如获取、添加、删除 Cookies 等。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
首先,我们访问了知乎。加载完成后,浏览器实际上已经生成 Cookies 了。接着,调用 get_cookies() 方法获取所有的 Cookies。然后,我们添加一个 Cookie,这里传入一个字典,有 name、domain 和 value 等内容。接下来,再次获取所有的 Cookies。可以发现,结果就多了这一项新加的 Cookie。最后,调用 delete_all_cookies() 方法删除所有的 Cookies。再重新获取,发现结果就为空了。
控制台的输出如下:
[{'secure': False, 'value': '"NGM0ZTM5NDAwMWEyNDQwNDk5ODlkZWY3OTkxY2I0NDY=|1491604091|236e34290a6f407bfbb517888849ea509ac366d0"', 'domain': '.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'l_cap_id', 'expiry': 1494196091.403418}]
[{'secure': False, 'value': 'germey', 'domain': '.www.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'name'}, {'secure': False, 'value': '"NGM0ZTM5NDAwMWEyNDQwNDk5ODlkZWY3OTkxY2I0NDY=|1491604091|236e34290a6f407bfbb517888849ea509ac366d0"', 'domain': '.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'l_cap_id', 'expiry': 1494196091.403418}]
[]
通过以上方法来操作 Cookies 还是非常方便的。
14. 选项卡管理
在访问网页的时候,会开启一个个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://python.org')
控制台输出如下:
['CDwindow-4f58e3a7-7167-4587-bedf-9cd8c867f435', 'CDwindow-6e05f076-6d77-453a-a36c-32baacc447df']
首先访问了百度,然后调用了 execute_script() 方法,这里传入 window.open() 这个 JavaScript 语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用 window_handles 属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用 switch_to_window() 方法即可,其中参数是选项卡的代号。这里我们将第二个选项卡代号传入,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用 switch_to_window() 方法,再执行其他操作即可。
15. 异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用 try except 语句来捕获各种异常。
首先,演示一下节点未找到的异常,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.find_element_by_id('hello')
这里首先打开百度页面,然后尝试选择一个并不存在的节点,此时就会遇到异常。
运行之后控制台的输出如下:
NoSuchElementException Traceback (most recent call last)
<ipython-input-23-978945848a1b> in <module>()
3 browser = webdriver.Chrome()
4 browser.get('https://www.baidu.com')
----> 5 browser.find_element_by_id('hello')
可以看到,这里抛出了 NoSuchElementException 异常,这通常是节点未找到的异常。为了防止程序遇到异常而中断,我们需要捕获这些异常,示例如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
这里我们使用 try except 来捕获各类异常。比如,我们对 find_element_by_id() 查找节点的方法捕获 NoSuchElementException 异常,这样一旦出现这样的错误,就进行异常处理,程序也不会中断了。
控制台的输出如下:
No Element
关于更多的异常类,可以参考官方文档::http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions。
16. 反屏蔽
现在有很多网站添加了对 Selenium 的检测,防止一些爬虫的恶意爬取,如果检测到有人使用 Selenium 打开浏览器,就直接屏蔽。
在大多数情况下,检测的基本原理是检测当前浏览器窗口下的 window.navigator 对象中是否包含 webdriver 属性,因为在正常使用浏览器时,这个属性应该是 undefined,一旦使用 Selenium,就会给 window.navigator 设置 webdriver 属性,很多网站通过 Javascript 语句判断是否存在 webdriver 属性,如果存在就直接屏蔽;
在这里我们使用 execute_script 调用 Javascript 语句 Object.defineProperty(navigator, "webdriver", {get :()=> undefined}) 将 webdriver 置空是不行的;
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(chrome_options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": "Object.defineProperty(navigator, 'webdriver',{get: () => undefined})"
})
往往这样还不够,我们可以使用 mitmproxy 来执行;
mitmproxy 是一款开源的抓包工具,支持 SSL 的 HTTP 代理,它可以用于调试 HTTP 通信,发起中间人攻击等,还可以配合自定义 python 脚本使用,不同于 fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发
- mitmproxy - 交互式 HTTPS 代理 — mitmproxy - an interactive HTTPS proxy
- mitmproxy使用详解 - 尘世风 - 博客园 (cnblogs.com)
- mitmproxy/mitmproxy: An interactive TLS-capable intercepting HTTP proxy for penetration testers and software developers. (github.com)
- 抓包工具mitmproxy环境配置使用(一) (qq.com)
- 抓包工具mitmproxy | mitmweb基本用法(二)-CSDN博客
17. 无头模式
在无头模式下,网站运行时不会弹出窗口,从而减少了干扰,还减少了一些资源(图片)的加载,所以无头模式在一定程度上节省了资源的加载时间和网络带宽;
from selenium import webdriver
from selenium.webdriver import ChromeOptions
# 添加无头模式
options = ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
# 截图
browser = set_window_size(1333, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('preview.png')
18. Pyppeteer,异步 Selenium
Attention: This repo is unmaintained and has been outside of minor changes for a long time. Please consider playwright-python as an alternative.
注意:此存储库未维护,并且长期以来一直没有进行细微更改。请考虑playwright-python作为替代方案。
二、Splash
Splash 是一个含有 HTTP API 的轻量级浏览器,可以提供 JavaScript 的渲染服务,其可以异步处理多个网页的渲染过程,获得渲染后的页面源代码或截图;通过 Lua 脚本执行特定的 JavaScript 脚本控制页面的渲染过程,并以 HAR(HTTP Archive) 的格式呈现出来;
1. 基本安装
这里推荐使用 docker 安装 splash;
- Splash 的安装 | 静觅 (cuiqingcai.com)
- scrapinghub/splash: Lightweight, scriptable browser as a service with an HTTP API (github.com)
- Splash - A javascript rendering service — Splash 3.5 documentation
安装完毕后确认能否在本地端口上运行,这里设置 8050 端口进行测试;
2. Splash API 调用
Splash 中使用的脚本语言是 Lua,Lua 脚本是在 Splash 页面里面测试运行的,我们需要使用 python 编写 Lua 脚本然后传送到 Splash 中进行运行进而得到我们想要的结果,这里 Splash 提供了一些 HTTP API 接口方便我们构建 URL 进行调用;
1) render.html
此接口用于获取 JavaScript 渲染的页面的 HTML 代码,接口地址就是 Splash 的运行地址加此接口名称,例如:http://localhost:8050/render.html,我们可以用 curl 来测试一下:
curl http://localhost:8050/render.html?url=https://www.baidu.com
我们给此接口传递了一个 url 参数指定渲染的 URL,返回结果即页面渲染后的源代码。
如果用 Python 实现的话,代码如下:
import requests
url = 'http://localhost:8050/render.html?url=https://www.baidu.com'
response = requests.get(url)
print(response.text)
这样就可以成功输出百度页面渲染后的源代码了。
另外,此接口还可以指定其他参数,比如通过 wait 指定等待秒数。如果要确保页面完全加载出来,可以增加等待时间,例如:
import requests
url = 'http://localhost:8050/render.html?url=https://www.taobao.com&wait=5'
response = requests.get(url)
print(response.text)
如果增加了此等待时间后,得到响应的时间就会相应变长,如在这里我们会等待大约 5 秒多钟即可获取 JavaScript 渲染后的淘宝页面源代码。
另外此接口还支持代理设置、图片加载设置、Headers 设置、请求方法设置,具体的用法可以参见官方文档:https://splash.readthedocs.io/en/stable/api.html#render-html。
2) render.png
此接口可以获取网页截图,其参数比 render.html 多了几个,比如通过 width 和 height 来控制宽高,它返回的是 PNG 格式的图片二进制数据。示例如下:
curl http://localhost:8050/render.png?url=https://www.taobao.com&wait=5&width=1000&height=700
在这里我们还传入了 width 和 height 来放缩页面大小为 1000x700 像素。
如果用 Python 实现,我们可以将返回的二进制数据保存为 PNG 格式的图片,实现如下:
import requests
url = 'http://localhost:8050/render.png?url=https://www.jd.com&wait=5&width=1000&height=700'
response = requests.get(url)
with open('taobao.png', 'wb') as f:
f.write(response.content)
得到的图片如图所示:
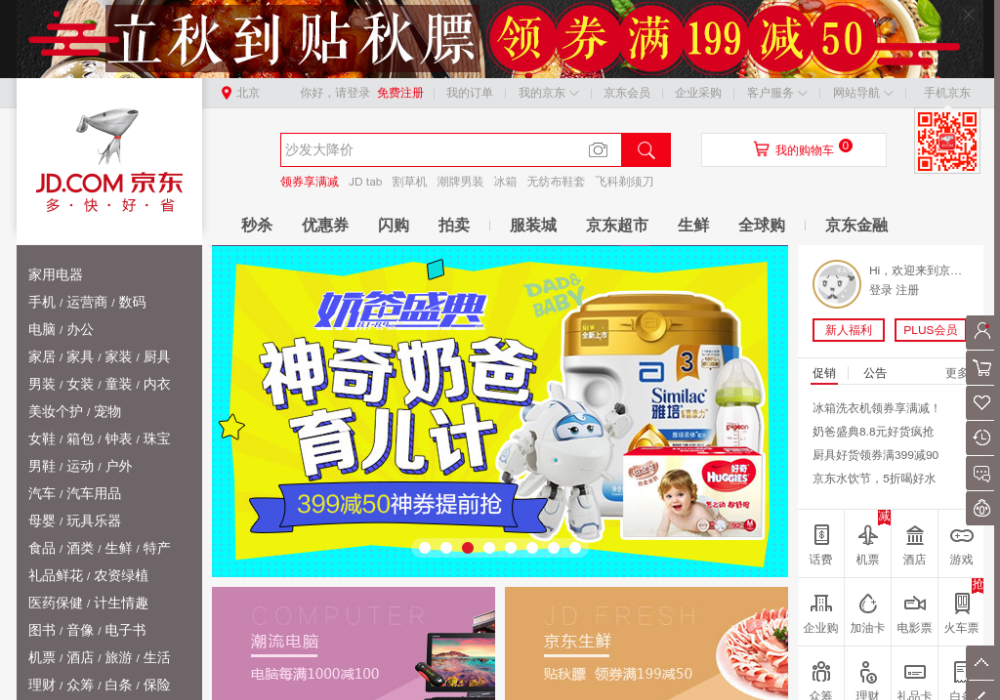
这样我们就成功获取了京东首页渲染完成后的页面截图,详细的参数设置可以参考官网文档 https://splash.readthedocs.io/en/stable/api.html#render-png。
3) render.jpeg
此接口和 render.png 类似,不过它返回的是 JPEG 格式的图片二进制数据。
另外此接口相比 render.png 还多了一个参数 quality,可以用来设置图片质量。
4) render.har
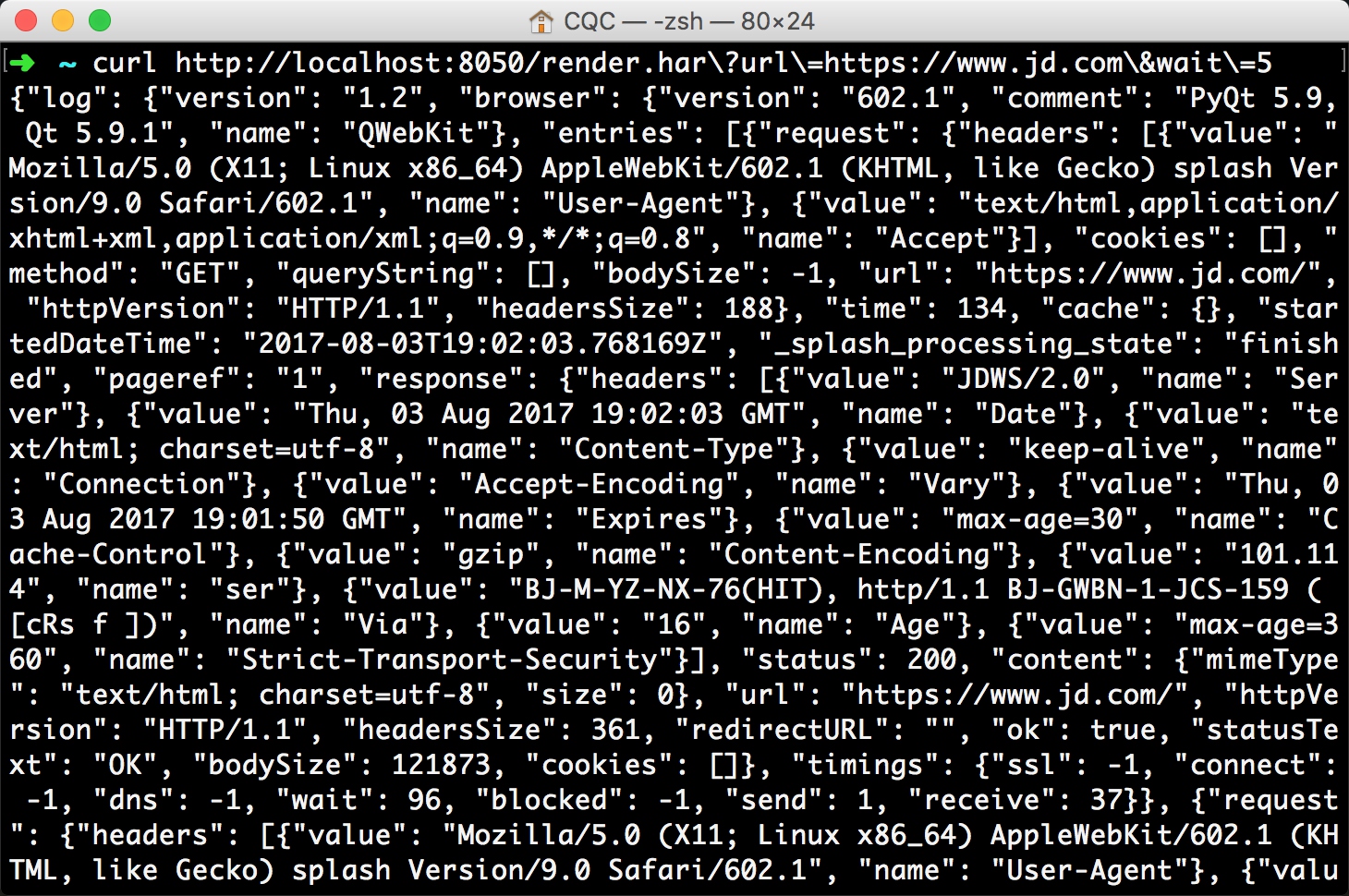
此接口用于获取页面加载的 HAR 数据,示例如下:
curl http://localhost:8050/render.har?url=https://www.jd.com&wait=5
返回结果非常多,是一个 Json 格式的数据,里面包含了页面加载过程中的 HAR 数据。
结果如图所示:
5) render.json
此接口包含了前面接口的所有功能,返回结果是 Json 格式,示例如下:
curl http://localhost:8050/render.json?url=https://httpbin.org
结果如下:
{"title": "httpbin(1): HTTP Client Testing Service", "url": "https://httpbin.org/", "requestedUrl": "https://httpbin.org/", "geometry": [0, 0, 1024, 768]}
可以看到,这里以 JSON 形式返回了相应的请求数据。
我们可以通过传入不同参数控制其返回结果。比如,传入 html=1,返回结果即会增加源代码数据;传入 png=1,返回结果即会增加页面 PNG 截图数据;传入 har=1,则会获得页面 HAR 数据。例如:
curl http://localhost:8050/render.json?url=https://httpbin.org&html=1&har=1
这样返回的 Json 结果便会包含网页源代码和 HAR 数据。
还有更多参数设置可以参考官方文档:https://splash.readthedocs.io/en/stable/api.html#render-json。
6) execute
此接口才是最为强大的接口。前面说了很多 Splash Lua 脚本的操作,用此接口便可实现与 Lua 脚本的对接。
前面的 render.html 和 render.png 等接口对于一般的 JavaScript 渲染页面是足够了,但是如果要实现一些交互操作的话,它们还是无能为力,这里就需要使用 execute 接口了。
我们先实现一个最简单的脚本,直接返回数据:
function main(splash)
return 'hello'
end
然后将此脚本转化为 URL 编码后的字符串,拼接到 execute 接口后面,示例如下:
curl http://localhost:8050/execute?lua_source=function+main%28splash%29%0D%0A++return+%27hello%27%0D%0Aend
运行结果:
hello
这里我们通过 lua_source 参数传递了转码后的 Lua 脚本,通过 execute 接口获取了最终脚本的执行结果。
这里我们更加关心的肯定是如何用 Python 来实现,上例用 Python 实现的话,代码如下:
import requests
from urllib.parse import quote
lua = '''
function main(splash)
return 'hello'
end
'''
url = 'http://localhost:8050/execute?lua_source=' + quote(lua)
response = requests.get(url)
print(response.text)
运行结果:
hello
这里我们用 Python 中的三引号将 Lua 脚本包括起来,然后用 urllib.parse 模块里的 quote() 方法将脚本进行 URL 转码,随后构造了 Splash 请求 URL,将其作为 lua_source 参数传递,这样运行结果就会显示 Lua 脚本执行后的结果。
我们再通过实例看一下:
import requests
from urllib.parse import quote
lua = '''
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return {html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end
'''
url = 'http://localhost:8050/execute?lua_source=' + quote(lua)
response = requests.get(url)
print(response.text)
运行结果:
{"url": "http://httpbin.org/get", "status": 200, "html": "{\n \"args\": {}, \n \"headers\": {\n \"Accept-Encoding\": \"gzip, deflate\", \n \"Accept-Language\": \"en,*\", \n \"Connection\": \"close\", \n \"Host\": \"httpbin.org\", \n \"User-Agent\": \"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1\"\n }, \n \"origin\": \"60.207.237.85\", \n \"url\": \"http://httpbin.org/get\"\n}\n"}
可以看到,返回结果是 JSON 形式,我们成功获取了请求的 URL、状态码和网页源代码。
如此一来,我们之前所说的 Lua 脚本均可以用此方式与 Python 进行对接,所有网页的动态渲染、模拟点击、表单提交、页面滑动、延时等待后的一些结果均可以自由控制,获取页面源码和截图也都不在话下。
到现在为止,我们可以用 Python 和 Splash 实现 JavaScript 渲染的页面的抓取了。除了 Selenium,本节所说的 Splash 同样可以做到非常强大的渲染功能,同时它也不需要浏览器即可渲染,使用非常方便。
3. Splash Lua 脚本
Splash 可以通过 Lua 脚本执行一系列渲染操作,这样我们就可以用 Splash 来模拟类似 Chrome、PhantomJS 的操作了。
首先,我们来了解一下 Splash Lua 脚本的入口和执行方式。
1) 入口及返回值
首先,来看一个基本实例:
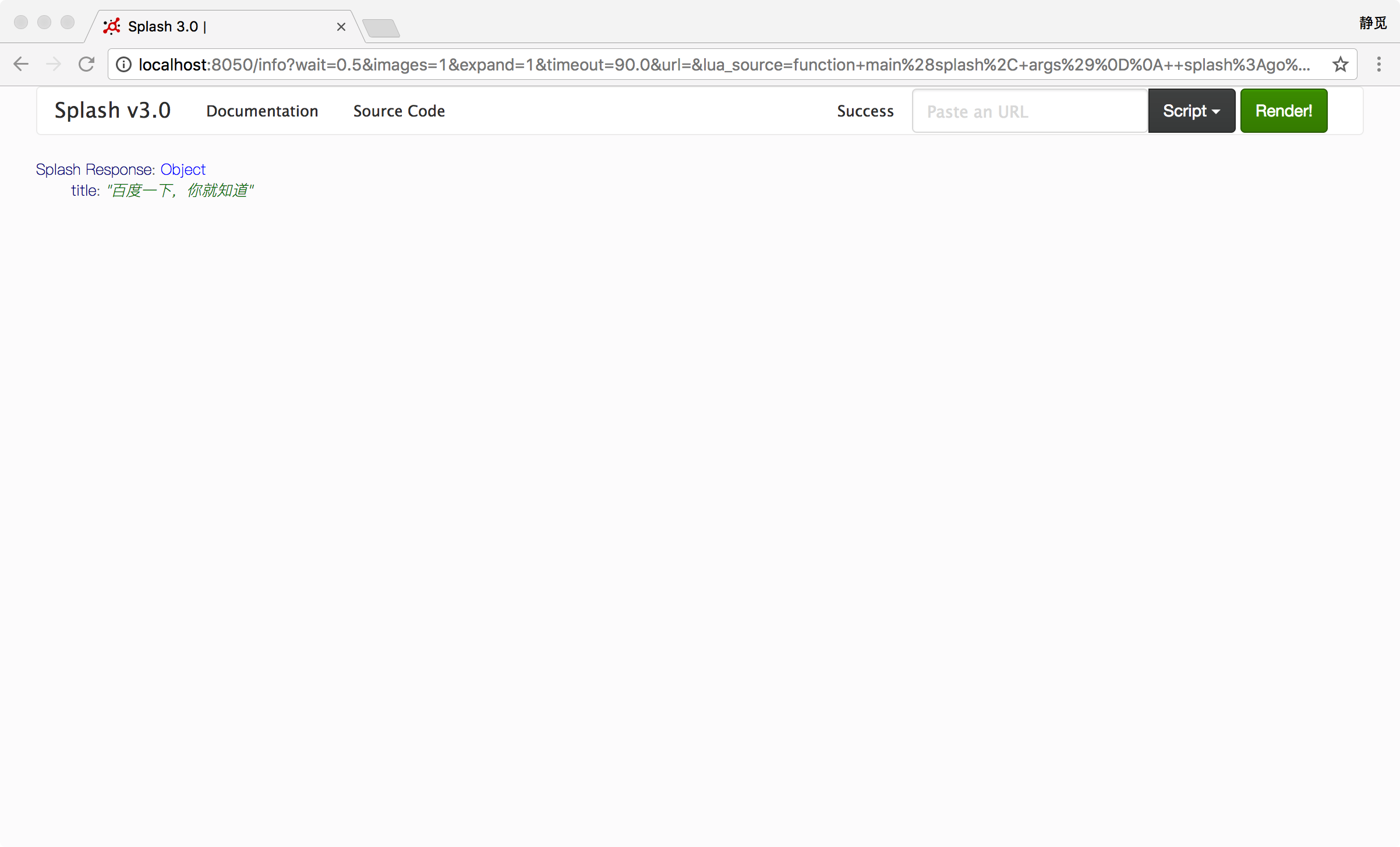
function main(splash, args)
splash:go("http://www.baidu.com")
splash:wait(0.5)
local title = splash:evaljs("document.title")
return {title=title}
end
我们将代码粘贴到刚才我们所打开的:http://localhost:8050/ 的代码编辑区域,然后点击 Render me! 按钮来测试一下。
我们看到它返回了网页的标题,如图 7-8 所示。这里我们通过 evaljs 方法传入 JavaScript 脚本,而 document.title 的执行结果就是返回网页标题,执行完毕后将其赋值给一个 title 变量,随后将其返回。
注意,我们在这里定义的方法名称叫作 main 。这个名称必须是固定的,Splash 会默认调用这个方法。
该方法的返回值既可以是字典形式,也可以是字符串形式,最后都会转化为 Splash HTTP Response,例如:
function main(splash)
return {hello="world!"}
end
这样即返回了一个字典形式的内容。
function main(splash)
return 'hello'
end
这样即返回了一个字符串形式的内容,同样是可以的。
2) 异步处理
Splash 支持异步处理,但是这里并没有显式指明回调方法,其回调的跳转是在 Splash 内部完成的。示例如下:
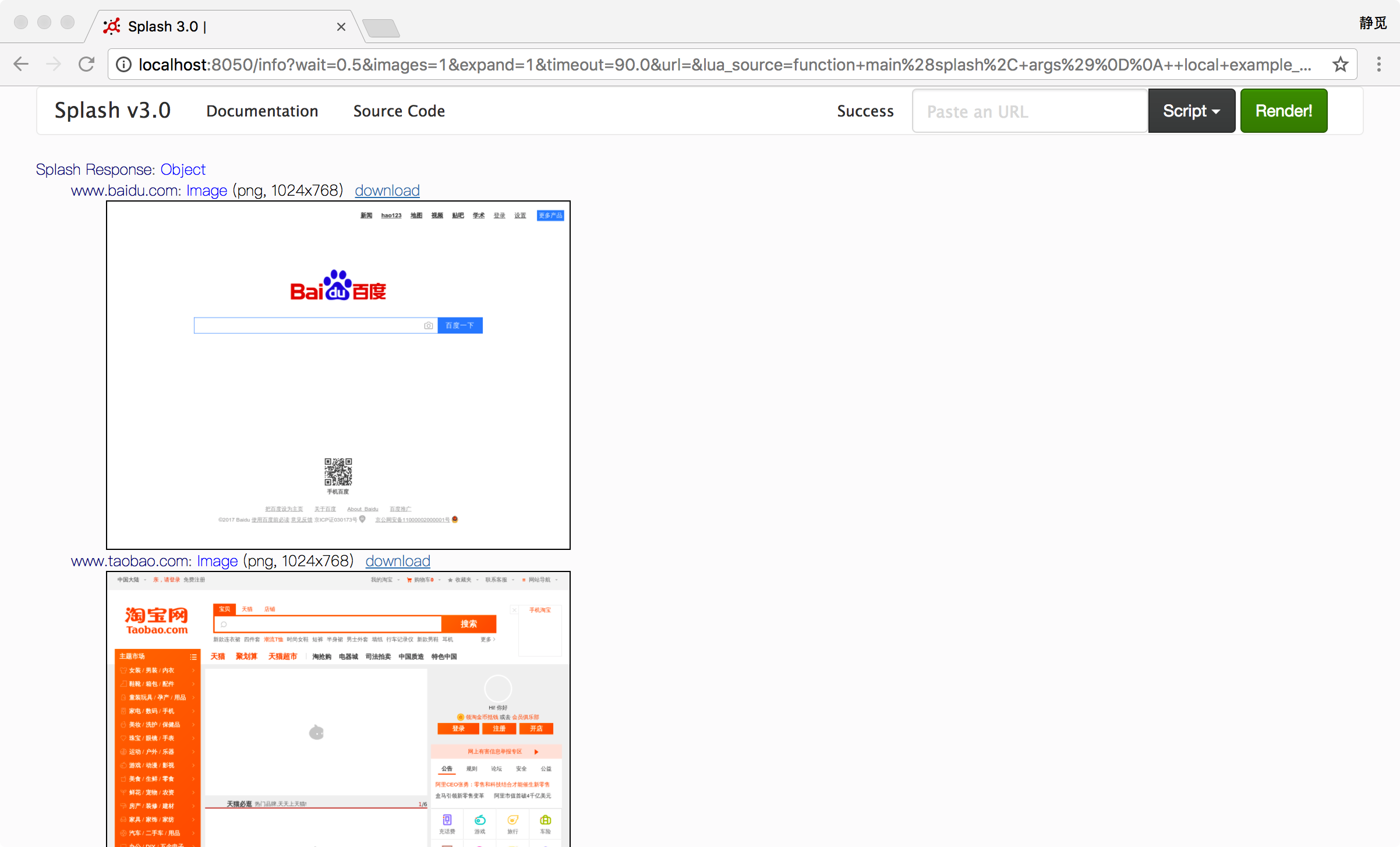
function main(splash, args)
local example_urls = {"www.baidu.com", "www.taobao.com", "www.zhihu.com"}
local urls = args.urls or example_urls
local results = {}
for index, url in ipairs(urls) do
local ok, reason = splash:go("http://" .. url)
if ok then
splash:wait(2)
results[url] = splash:png()
end
end
return results
end
运行后的返回结果是 3 个站点的截图,如图所示:
在脚本内调用的 wait 方法类似于 Python 中的 sleep 方法,其参数为等待的秒数。当 Splash 执行到此方法时,它会转而去处理其他任务,然后在指定的时间过后再回来继续处理。
这里值得注意的是,Lua 脚本中的字符串拼接和 Python 不同,它使用的是… 操作符,而不是 +。如果有必要,可以简单了解一下 Lua 脚本的语法,详见 http://www.runoob.com/lua/lua-basic-syntax.html。
另外,这里做了加载时的异常检测。go 方法会返回加载页面的结果状态,如果页面出现 4xx 或 5xx 状态码,ok 变量就为空,就不会返回加载后的图片。
4. Splash 对象属性
我们注意到,前面例子中 main 方法的第一个参数是 splash,这个对象非常重要,它类似于 Selenium 中的 WebDriver 对象,我们可以调用它的一些属性和方法来控制加载过程。接下来,先看下它的属性。
1) args
该属性可以获取加载时配置的参数,比如 URL,如果为 GET 请求,它还可以获取 GET 请求参数;如果为 POST 请求,它可以获取表单提交的数据。Splash 也支持使用第二个参数直接作为 args,例如:
function main(splash, args)
local url = args.url
end
这里第二个参数 args 就相当于 splash.args 属性,以上代码等价于:
function main(splash)
local url = splash.args.url
end
2) js_enabled
这个属性是 Splash 的 JavaScript 执行开关,可以将其配置为 true 或 false 来控制是否执行 JavaScript 代码,默认为 true。例如,这里禁止执行 JavaScript 代码:
function main(splash, args)
splash:go("https://www.baidu.com")
splash.js_enabled = false
local title = splash:evaljs("document.title")
return {title=title}
end
接着我们重新调用了 evaljs 方法执行 JavaScript 代码,此时运行结果就会抛出异常:
{
"error": 400,
"type": "ScriptError",
"info": {
"type": "JS_ERROR",
"js_error_message": null,
"source": "[string \"function main(splash, args)\r...\"]",
"message": "[string \"function main(splash, args)\r...\"]:4: unknown JS error: None",
"line_number": 4,
"error": "unknown JS error: None",
"splash_method": "evaljs"
},
"description": "Error happened while executing Lua script"
}
不过一般来说我们不用设置此属性开关,默认开启即可。
3) resource_timeout
此属性可以设置加载的超时时间,单位是秒。如果设置为 0 或 nil(类似 Python 中的 None),代表不检测超时。示例如下:
function main(splash)
splash.resource_timeout = 0.1
assert(splash:go('https://www.taobao.com'))
return splash:png()
end
例如,这里将超时时间设置为 0.1 秒。如果在 0.1 秒之内没有得到响应,就会抛出异常,错误如下:
{
"error": 400,
"type": "ScriptError",
"info": {
"error": "network5",
"type": "LUA_ERROR",
"line_number": 3,
"source": "[string \"function main(splash)\r...\"]",
"message": "Lua error: [string \"function main(splash)\r...\"]:3: network5"
},
"description": "Error happened while executing Lua script"
}
此属性适合在网页加载速度较慢的情况下设置。如果超过了某个时间无响应,则直接抛出异常并忽略即可。
4) images_enabled
此属性可以设置图片是否加载,默认情况下是加载的。禁用该属性后,可以节省网络流量并提高网页加载速度。但是需要注意的是,禁用图片加载可能会影响 JavaScript 渲染。因为禁用图片之后,它的外层 DOM 节点的高度会受影响,进而影响 DOM 节点的位置。因此,如果 JavaScript 对图片节点有操作的话,其执行就会受到影响。
另外值得注意的是,Splash 使用了缓存。如果一开始加载出来了网页图片,然后禁用了图片加载,再重新加载页面,之前加载好的图片可能还会显示出来,这时直接重启 Splash 即可。
禁用图片加载的示例如下:
function main(splash, args)
splash.images_enabled = false
assert(splash:go('https://www.jd.com'))
return {png=splash:png()}
end
这样返回的页面截图就不会带有任何图片,加载速度也会快很多。
5) plugins_enabled
此属性可以控制浏览器插件(如 Flash 插件)是否开启。默认情况下,此属性是 false,表示不开启。可以使用如下代码控制其开启和关闭:
splash.plugins_enabled = true/false
6) scroll_position
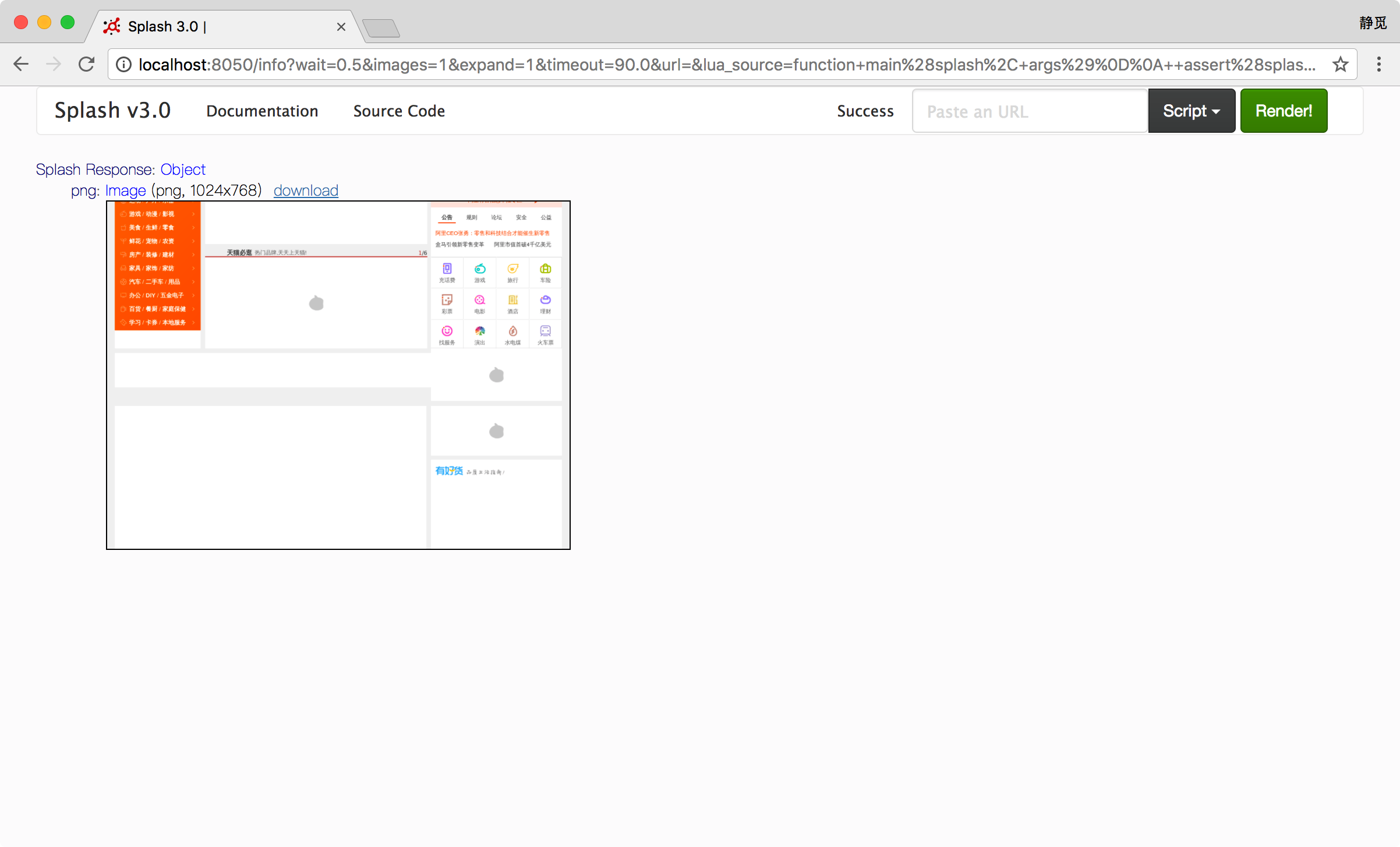
通过设置此属性,我们可以控制页面上下或左右滚动。这是一个比较常用的属性,示例如下:
function main(splash, args)
assert(splash:go('https://www.taobao.com'))
splash.scroll_position = {y=400}
return {png=splash:png()}
end
这样我们就可以控制页面向下滚动 400 像素值,结果如图所示。
如果要让页面左右滚动,可以传入 x 参数,代码如下:
splash.scroll_position = {x=100, y=200}
5. Splash 对象方法
除了前面介绍的属性外,Splash 对象还有如下方法。
1) go
该方法用来请求某个链接,而且它可以模拟 GET 和 POST 请求,同时支持传入请求头、表单等数据,其用法如下:
ok, reason = splash:go{url, baseurl=nil, headers=nil, http_method="GET", body=nil, formdata=nil}
参数说明如下:
- url,即请求的 URL。
- baseurl,可选参数,默认为空,资源加载相对路径。
- headers,可选参数,默认为空,请求的 Headers。
- http_method,可选参数,默认为 GET,同时支持 POST。
- body,可选参数,默认为空,POST 的时候的表单数据,使用的 Content-type 为 application/json。
- formdata,可选参数,默认为空,POST 的时候表单数据,使用的 Content-type 为 application/x-www-form-urlencoded。
该方法的返回结果是结果 ok 和原因 reason 的组合,如果 ok 为空,代表网页加载出现了错误,此时 reason 变量中包含了错误的原因,否则证明页面加载成功。示例如下:
function main(splash, args)
local ok, reason = splash:go{"http://httpbin.org/post", http_method="POST", body="name=Germey"}
if ok then
return splash:html()
end
end
这里我们模拟了一个 POST 请求,并传入了 POST 的表单数据,如果成功,则返回页面的源代码。
运行结果如下:
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{"args": {},
"data": "","files": {},"form": {"name":"Germey"},"headers": {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Encoding":"gzip, deflate","Accept-Language":"en,*","Connection":"close","Content-Length":"11","Content-Type":"application/x-www-form-urlencoded","Host":"httpbin.org","Origin":"null","User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1"},"json": null,"origin":"60.207.237.85","url":"http://httpbin.org/post"
}
</pre></body></html>
可以看到,我们成功实现了 POST 请求并发送了表单数据。
2) wait
此方法可以控制页面等待时间,使用方法如下:
ok, reason = splash:wait{time, cancel_on_redirect=false, cancel_on_error=true}
参数说明如下:
- time,等待的秒数。
- cancel_on_redirect,可选参数,默认 False,如果发生了重定向就停止等待,并返回重定向结果。
- cancel_on_error,可选参数,默认 False,如果发生了加载错误就停止等待。
返回结果同样是结果 ok 和原因 reason 的组合。
我们用一个实例感受一下:
function main(splash)
splash:go("https://www.taobao.com")
splash:wait(2)
return {html=splash:html()}
end
如上代码可以实现访问淘宝并等待 2 秒,随后返回页面源代码的功能。
3) jsfunc
此方法可以直接调用 JavaScript 定义的方法,但是所调用的方法需要用双中括号包围,这相当于实现了 JavaScript 方法到 Lua 脚本的转换。示例如下:
function main(splash, args)
local get_div_count = splash:jsfunc([[function () {
var body = document.body;
var divs = body.getElementsByTagName('div');
return divs.length;
}
]])
splash:go("https://www.baidu.com")
return ("There are % s DIVs"):format(get_div_count())
end
运行结果:
There are 21 DIVs
首先,我们声明了一个 JavaScript 定义的方法,然后在页面加载成功后调用了此方法计算出了页面中 div 节点的个数。
关于 JavaScript 到 Lua 脚本的更多转换细节,可以参考官方文档:https://splash.readthedocs.io/en/stable/scripting-ref.html#splash-jsfunc。
4) evaljs
此方法可以执行 JavaScript 代码并返回最后一条 JavaScript 语句的返回结果,使用方法如下:
result = splash:evaljs(js)
比如,可以用下面的代码来获取页面标题:
local title = splash:evaljs("document.title")
5) runjs
此方法可以执行 JavaScript 代码,它与 evaljs 方法的功能类似,但是更偏向于执行某些动作或声明某些方法。例如:
function main(splash, args)
splash:go("https://www.baidu.com")
splash:runjs("foo = function() {return 'bar'}")
local result = splash:evaljs("foo()")
return result
end
这里我们用 runjs 方法先声明了一个 JavaScript 定义的方法,然后通过 evaljs 方法来调用得到的结果。
运行结果如下:
bar
6) autoload
此方法可以设置每个页面访问时自动加载的对象,使用方法如下:
ok, reason = splash:autoload{source_or_url, source=nil, url=nil}
参数说明如下:
- source_or_url,JavaScript 代码或者 JavaScript 库链接。
- source,JavaScript 代码。
- url,JavaScript 库链接
但是此方法只负责加载 JavaScript 代码或库,不执行任何操作。如果要执行操作,可以调用 evaljs 或 runjs 方法。示例如下:
function main(splash, args)
splash:autoload([[function get_document_title(){return document.title;}
]])
splash:go("https://www.baidu.com")
return splash:evaljs("get_document_title()")
end
这里我们调用 autoload 方法声明了一个 JavaScript 方法,然后通过 evaljs 方法来执行此 JavaScript 方法。
运行结果如下:
百度一下,你就知道
另外,我们也可以使用 autoload 方法加载某些方法库,如 jQuery,示例如下:
function main(splash, args)
assert(splash:autoload("https://code.jquery.com/jquery-2.1.3.min.js"))
assert(splash:go("https://www.taobao.com"))
local version = splash:evaljs("$.fn.jquery")
return 'JQuery version: ' .. version
end
运行结果如下:
JQuery version: 2.1.3
7) call_later
此方法可以通过设置定时任务和延迟时间来实现任务延时执行,并且可以在执行前通过 cancel 方法重新执行定时任务。示例如下:
function main(splash, args)
local snapshots = {}
local timer = splash:call_later(function()
snapshots["a"] = splash:png()
splash:wait(1.0)
snapshots["b"] = splash:png()
end, 0.2)
splash:go("https://www.taobao.com")
splash:wait(3.0)
return snapshots
end
这里我们设置了一个定时任务,0.2 秒的时候获取网页截图,然后等待 1 秒,1.2 秒时再次获取网页截图,访问的页面是淘宝,最后将截图结果返回。运行结果如图所示。
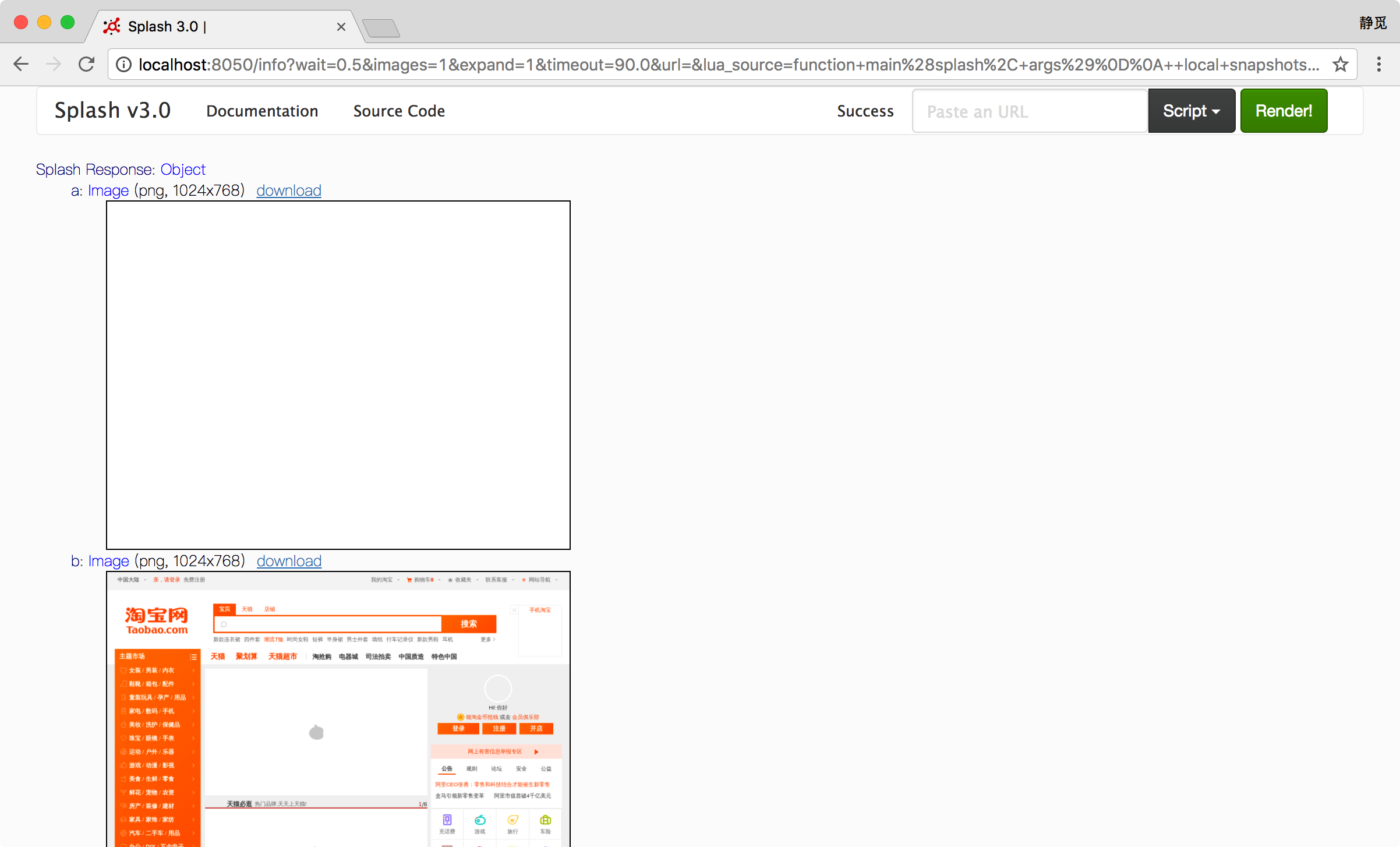
可以发现,第一次截图时网页还没有加载出来,截图为空,第二次网页便加载成功了。
8) http_get
此方法可以模拟发送 HTTP 的 GET 请求,使用方法如下:
response = splash:http_get{url, headers=nil, follow_redirects=true}
参数说明如下:
- url,请求 URL。
- headers,可选参数,默认为空,请求的 Headers。
- follow_redirects,可选参数,默认为 True,是否启动自动重定向。
示例如下:
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return {html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end
运行结果如下:
Splash Response: Object
html: String (length 355)
{"args": {},
"headers": {
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
status: 200
url: "http://httpbin.org/get"
9) http_post
和 http_get 方法类似,此方法是模拟发送一个 POST 请求,不过多了一个参数 body,使用方法如下:
response = splash:http_post{url, headers=nil, follow_redirects=true, body=nil}
参数说明如下:
- url,请求 URL。
- headers,可选参数,默认为空,请求的 Headers。
- follow_redirects,可选参数,默认为 True,是否启动自动重定向。
- body,可选参数,默认为空,即表单数据。
示例如下:
function main(splash, args)
local treat = require("treat")
local json = require("json")
local response = splash:http_post{"http://httpbin.org/post",
body=json.encode({name="Germey"}),
headers={["content-type"]="application/json"}
}
return {html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end
运行结果:
Splash Response: Object
html: String (length 533)
{"args": {},
"data": "{\"name\": \"Germey\"}",
"files": {},
"form": {},
"headers": {
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Content-Length": "18",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1"
},
"json": {"name": "Germey"},
"origin": "60.207.237.85",
"url": "http://httpbin.org/post"
}
status: 200
url: "http://httpbin.org/post"
可以看到在这里我们成功模拟提交了 POST 请求并发送了表单数据。
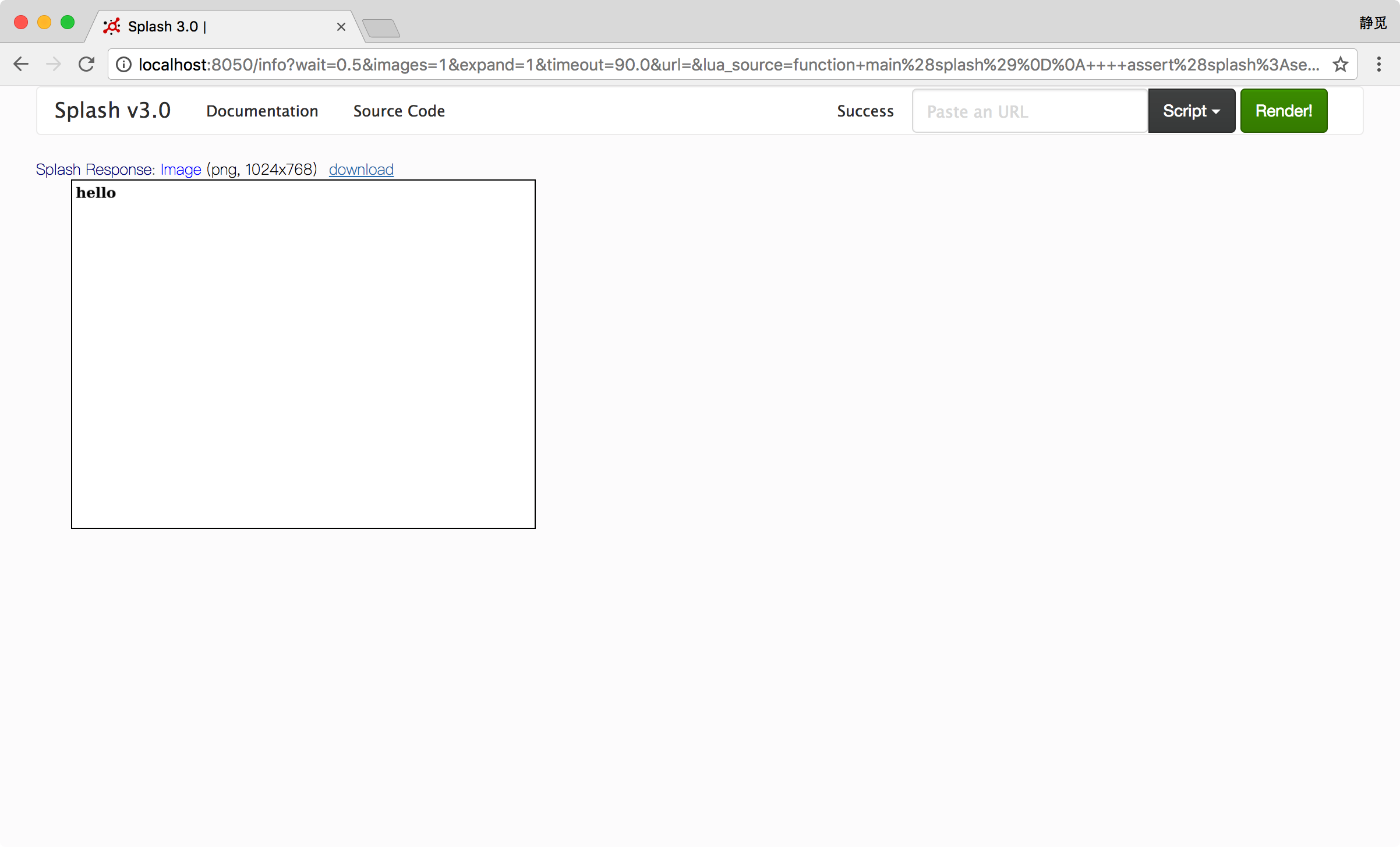
10) set_content
此方法可以用来设置页面的内容,示例如下:
function main(splash)
assert(splash:set_content("<html><body><h1>hello</h1></body></html>"))
return splash:png()
end
运行结果如图所示:
10) html
此方法可以用来获取网页的源代码,它是非常简单又常用的方法,示例如下:
function main(splash, args)
splash:go("https://httpbin.org/get")
return splash:html()
end
运行结果:
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1"
},
"origin": "60.207.237.85",
"url": "https://httpbin.org/get"
}
</pre></body></html>
11) png
此方法可以用来获取 PNG 格式的网页截图,示例如下:
function main(splash, args)
splash:go("https://www.taobao.com")
return splash:png()
end
12) jpeg
此方法可以用来获取 JPEG 格式的网页截图,示例如下:
function main(splash, args)
splash:go("https://www.taobao.com")
return splash:jpeg()
end
13) har
此方法可以用来获取页面加载过程描述,示例如下:
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:har()
end
运行结果如图所示:
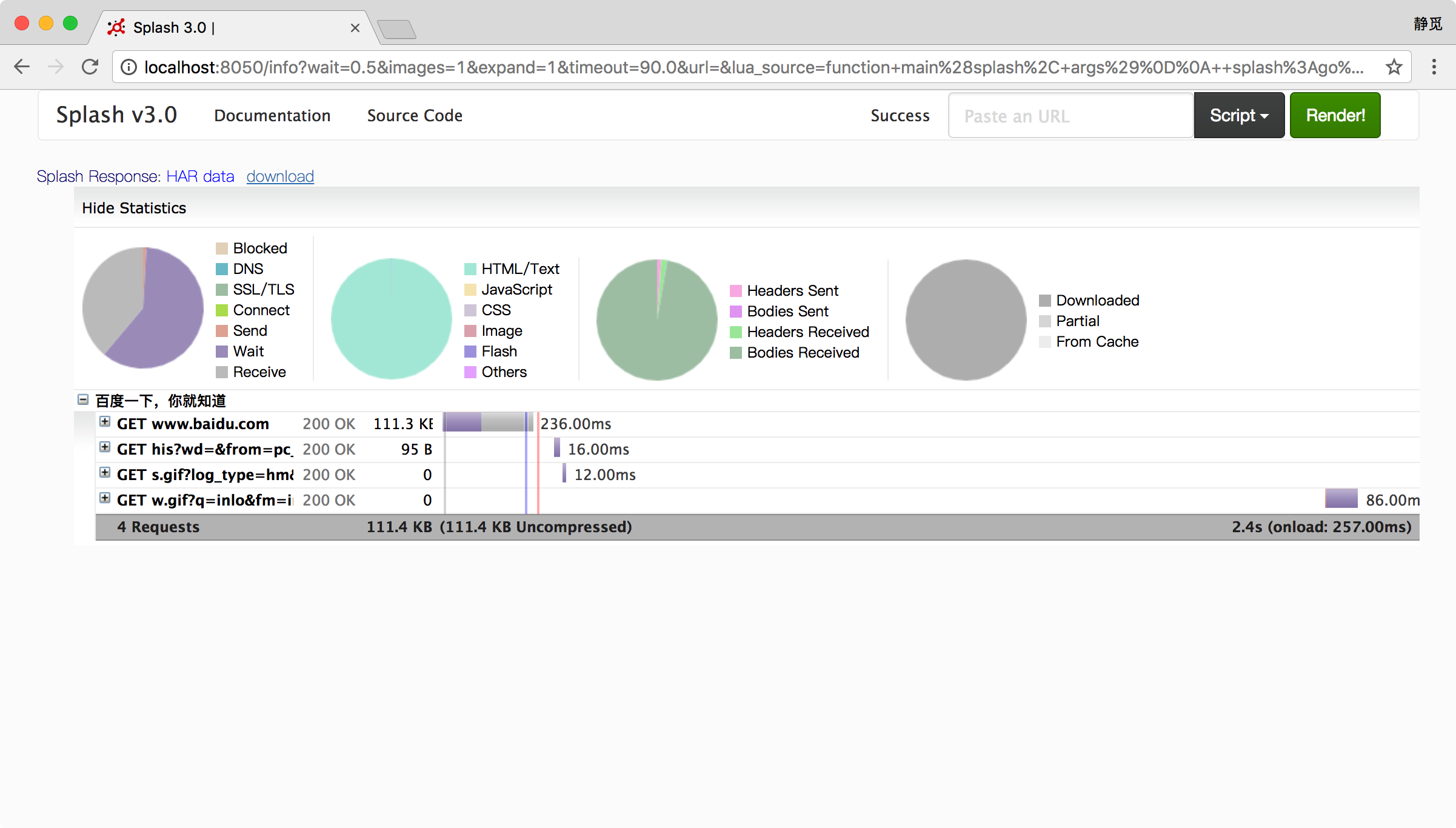
在这里显示了页面加载过程中的每个请求记录详情。
14) url
此方法可以获取当前正在访问的 URL,示例如下:
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:url()
end
运行结果如下:
https://www.baidu.com/
15) get_cookies
此方法可以获取当前页面的 Cookies,示例如下:
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:get_cookies()
end
运行结果如下:
Splash Response: Array[2]
0: Object
domain: ".baidu.com"
expires: "2085-08-21T20:13:23Z"
httpOnly: false
name: "BAIDUID"
path: "/"
secure: false
value: "C1263A470B02DEF45593B062451C9722:FG=1"
1: Object
domain: ".baidu.com"
expires: "2085-08-21T20:13:23Z"
httpOnly: false
name: "BIDUPSID"
path: "/"
secure: false
value: "C1263A470B02DEF45593B062451C9722"
15) add_cookie
此方法可以为当前页面添加 Cookies,用法如下:
cookies = splash:add_cookie{name, value, path=nil, domain=nil, expires=nil, httpOnly=nil, secure=nil}
方法的各个参数代表了 Cookie 的各个属性。
示例如下:
function main(splash)
splash:add_cookie{"sessionid", "237465ghgfsd", "/", domain="http://example.com"}
splash:go("http://example.com/")
return splash:html()
end
16) clear_cookies
此方法可以清除所有的 Cookies,示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
splash:clear_cookies()
return splash:get_cookies()
end
在这里我们清除了所有的 Cookies,然后再调用 get_cookies() 并将结果返回。
运行结果:
Splash Response: Array[0]
可以看到 Cookies 被全部清空,没有任何结果。
17) get_viewport_size
此方法可以获取当前浏览器页面的大小,即宽高,示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
return splash:get_viewport_size()
end
运行结果:
Splash Response: Array[2]
0: 1024
1: 768
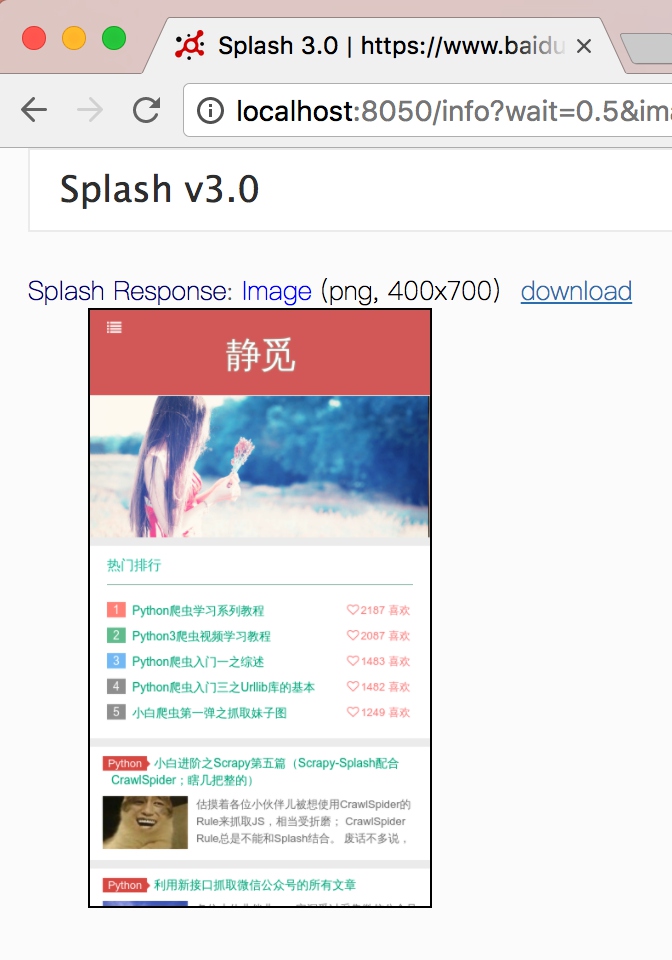
18) set_viewport_size
此方法可以设置当前浏览器页面的大小,即宽高,用法如下:
splash:set_viewport_size(width, height)
例如这里我们访问一个宽度自适应的页面,示例如下:
function main(splash)
splash:set_viewport_size(400, 700)
assert(splash:go("http://cuiqingcai.com"))
return splash:png()
end
运行结果如图所示:
19) set_viewport_full
此方法可以设置浏览器全屏显示,示例如下:
function main(splash)
splash:set_viewport_full()
assert(splash:go("http://cuiqingcai.com"))
return splash:png()
end
20) set_user_agent
此方法可以设置浏览器的 User-Agent,示例如下:
function main(splash)
splash:set_user_agent('Splash')
splash:go("http://httpbin.org/get")
return splash:html()
end
在这里我们将浏览器的 User-Agent 设置为 Splash,运行结果如下:
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Splash"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
</pre></body></html>
可以看到此处 User-Agent 被成功设置。
21) set_custom_headers()
此方法可以设置请求的 Headers,示例如下:
function main(splash)
splash:set_custom_headers({["User-Agent"] = "Splash",
["Site"] = "Splash",
})
splash:go("http://httpbin.org/get")
return splash:html()
end
在这里我们设置了 Headers 中的 User-Agent 和 Site 属性,运行结果:
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en,*",
"Connection": "close",
"Host": "httpbin.org",
"Site": "Splash",
"User-Agent": "Splash"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
</pre></body></html>
可以看到结果的 Headers 中两个字段被成功设置。
22) select
该方法可以选中符合条件的第一个节点,如果有多个节点符合条件,则只会返回一个,其参数是 CSS 选择器。示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('Splash')
splash:wait(3)
return splash:png()
end
这里我们首先访问了百度,然后选中了搜索框,随后调用了 send_text() 方法填写了文本,然后返回网页截图。
结果如图所示,可以看到,我们成功填写了输入框。
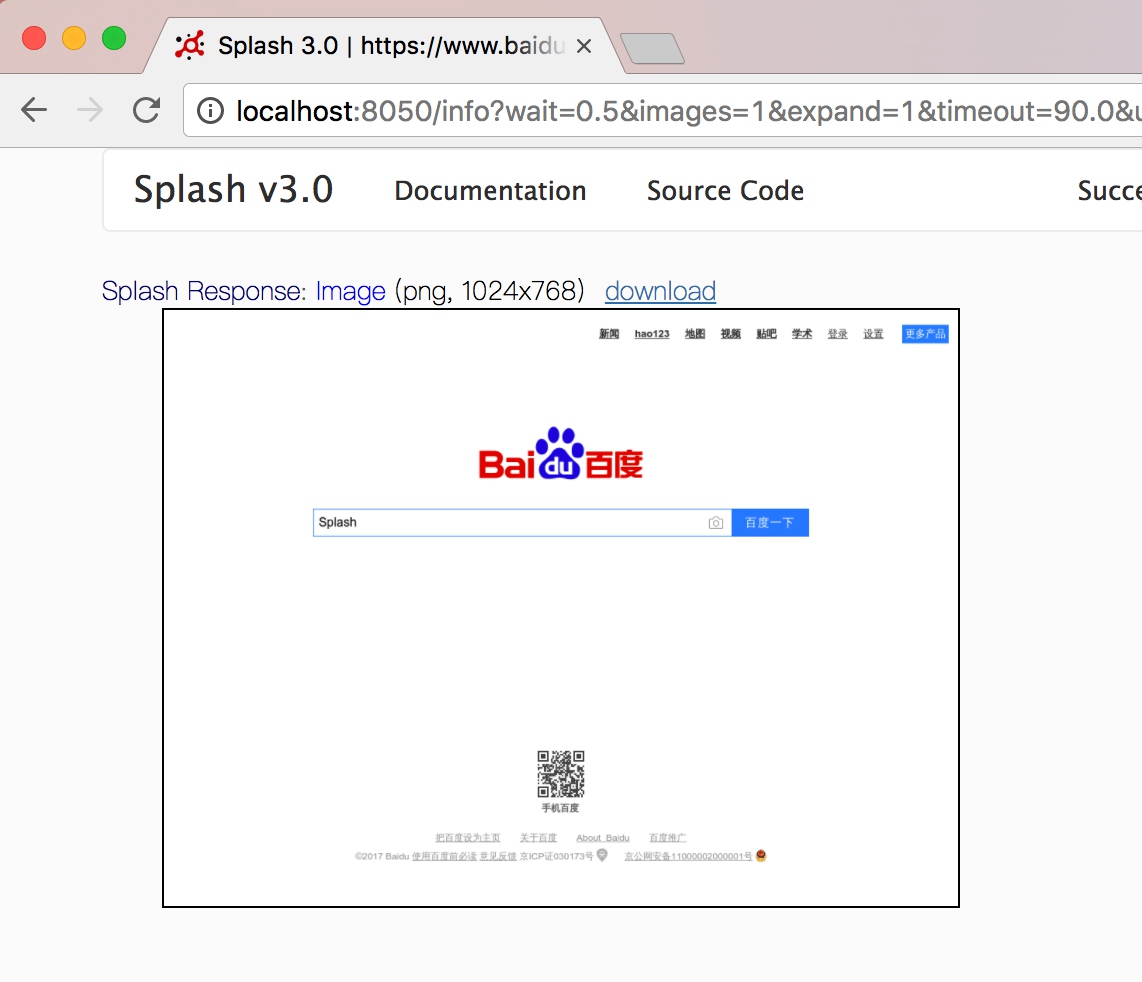
可以看到我们成功填写了输入框。
23) select_all()
此方法可以选中所有的符合条件的节点,其参数是 CSS 选择器。示例如下:
function main(splash)
local treat = require('treat')
assert(splash:go("http://quotes.toscrape.com/"))
assert(splash:wait(0.5))
local texts = splash:select_all('.quote .text')
local results = {}
for index, text in ipairs(texts) do
results[index] = text.node.innerHTML
end
return treat.as_array(results)
end
这里我们通过 CSS 选择器选中了节点的正文内容,随后遍历了所有节点,将其中的文本获取下来。
运行结果如下:
Splash Response: Array[10]
0: "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"
1: "“It is our choices, Harry, that show what we truly are, far more than our abilities.”"
2: “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”
3: "“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"
4: "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"
5: "“Try not to become a man of success. Rather become a man of value.”"
6: "“It is better to be hated for what you are than to be loved for what you are not.”"
7: "“I have not failed. I've just found 10,000 ways that won't work.”"
8: "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"
9: "“A day without sunshine is like, you know, night.”"
可以发现我们成功将 10 个节点的正文内容获取了下来。
24) mouse_click
此方法可以模拟鼠标点击操作,传入的参数为坐标值 x、y,也可以直接选中某个节点直接调用此方法,示例如下:
function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('Splash')
submit = splash:select('#su')
submit:mouse_click()
splash:wait(3)
return splash:png()
end
在这里我们首先选中了页面的输入框,输入了文本,然后选中了提交按钮,调用了 mouse_click() 方法提交查询,然后页面等待三秒,返回截图,结果如图所示:
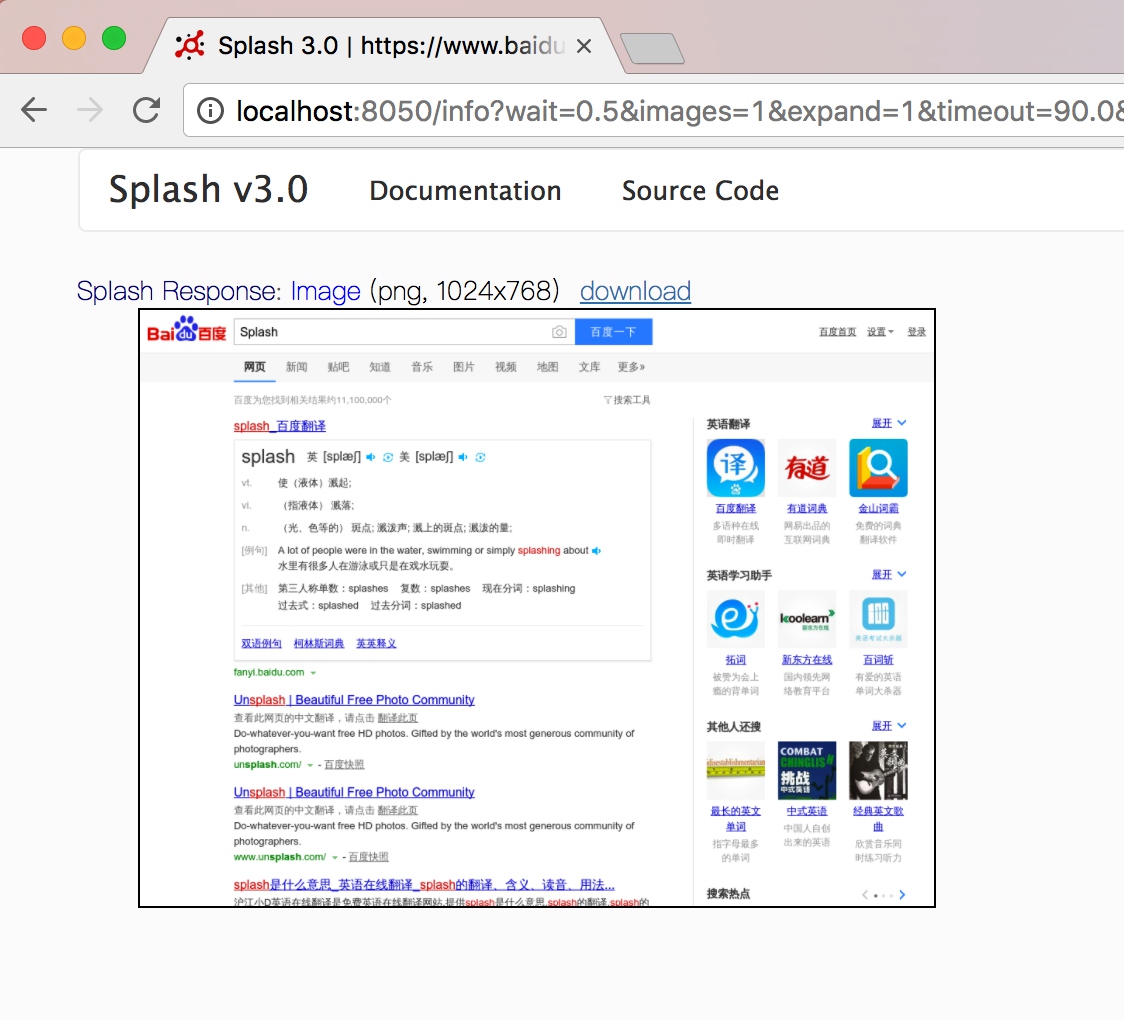
可以看到在这里我们成功获取了查询后的页面内容,模拟了百度搜索操作。
以上我们介绍了 Splash 的常用 API 操作,还有一些 API 在这不再一一介绍,更加详细和权威的说明可以参见官方文档:https://splash.readthedocs.io/en/stable/scripting-ref.html,此页面介绍了 splash 对象的所有 API 操作,另外还有针对于页面元素的 API 操作,链接为:https://splash.readthedocs.io/en/stable/scripting-element-object.html。
6. Splash 负载均衡配置
用 Splash 做页面抓取时,如果爬取的量非常大,任务非常多,用一个 Splash 服务来处理的话,未免压力太大了,此时可以考虑搭建一个负载均衡器来把压力分散到各个服务器上。这相当于多台机器多个服务共同参与任务的处理,可以减小单个 Splash 服务的压力。
1) 配置 Splash 服务
要搭建 Splash 负载均衡,首先要有多个 Splash 服务。假如这里在 4 台远程主机的 8050 端口上都开启了 Splash 服务,它们的服务地址分别为 41.159.27.223:8050、41.159.27.221:8050、41.159.27.9:8050 和 41.159.117.119:8050,这 4 个服务完全一致,都是通过 Docker 的 Splash 镜像开启的。访问其中任何一个服务时,都可以使用 Splash 服务。
2) 配置负载均衡
接下来,可以选用任意一台带有公网 IP 的主机来配置负载均衡。首先,在这台主机上装好 Nginx,然后修改 Nginx 的配置文件 nginx.conf,添加如下内容:
http {
upstream splash {
least_conn;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
server {
listen 8050;
location / {proxy_pass http://splash;}
}
}
这样我们通过 upstream 字段定义了一个名字叫作 splash 的服务集群配置。其中 least_conn 代表最少链接负载均衡,它适合处理请求处理时间长短不一造成服务器过载的情况。
当然,我们也可以不指定配置,具体如下:
upstream splash {
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
这样默认以轮询策略实现负载均衡,每个服务器的压力相同。此策略适合服务器配置相当、无状态且短平快的服务使用。
另外,我们还可以指定权重,配置如下:
upstream splash {
server 41.159.27.223:8050 weight=4;
server 41.159.27.221:8050 weight=2;
server 41.159.27.9:8050 weight=2;
server 41.159.117.119:8050 weight=1;
}
这里 weight 参数指定各个服务的权重,权重越高,分配到处理的请求越多。假如不同的服务器配置差别比较大的话,可以使用此种配置。
最后,还有一种 IP 散列负载均衡,配置如下:
upstream splash {
ip_hash;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
服务器根据请求客户端的 IP 地址进行散列计算,确保使用同一个服务器响应请求,这种策略适合有状态的服务,比如用户登录后访问某个页面的情形。对于 Splash 来说,不需要应用此设置。
我们可以根据不同的情形选用不同的配置,配置完成后重启一下 Nginx 服务:
sudo nginx -s reload
这样直接访问 Nginx 所在服务器的 8050 端口,即可实现负载均衡了。
3) 配置认证
现在 Splash 是可以公开访问的,如果不想让其公开访问,还可以配置认证,这仍然借助于 Nginx。可以在 server 的 location 字段中添加 auth_basic 和 auth_basic_user_file 字段,具体配置如下:
http {
upstream splash {
least_conn;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
server {
listen 8050;
location / {
proxy_pass http://splash;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}
这里使用的用户名和密码配置放置在 /etc/nginx/conf.d 目录下,我们需要使用 htpasswd 命令创建。例如,创建一个用户名为 admin 的文件,相关命令如下:
htpasswd -c .htpasswd admin
接下来就会提示我们输入密码,输入两次之后,就会生成密码文件,其内容如下:
cat .htpasswd
admin:5ZBxQr0rCqwbc
配置完成之后我们重启一下 Nginx 服务,运行如下命令:
sudo nginx -s reload
这样访问认证就成功配置好了。
4) 测试
最后,我们可以用代码来测试一下负载均衡的配置,看看到底是不是每次请求会切换 IP。利用 http://httpbin.org/get 测试即可,代码实现如下:
import requests
from urllib.parse import quote
import re
lua = '''
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return treat.as_string(response.body)
end
'''
url = 'http://splash:8050/execute?lua_source=' + quote(lua)
response = requests.get(url, auth=('admin', 'admin'))
ip = re.search('(\d+\.\d+\.\d+\.\d+)', response.text).group(1)
print(ip)
这里 URL 中的 splash 字符串请自行替换成自己的 Nginx 服务器 IP。这里我修改了 Hosts,设置了 splash 为 Nginx 服务器 IP。
多次运行代码之后,可以发现每次请求的 IP 都会变化,比如第一次的结果:
41.159.27.223
第二次的结果:
41.159.27.9
这就说明负载均衡已经成功实现了。
本节中,我们成功实现了负载均衡的配置。配置负载均衡后,可以多个 Splash 服务共同合作,减轻单个服务的负载,这还是比较有用的。
三、Playwright
Playwright 是专门为了满足端到端测试的需求而创建的。 Playwright 支持所有现代渲染引擎,包括 Chromium、WebKit 和 Firefox。在 Windows、Linux 和 macOS 上进行本地或 CI 测试,无头测试或使用PC,Mobile 模拟进行测试。
Playwright 库可用作通用浏览器自动化工具,为同步和异步 Python 提供一组强大的 API 来自动化 Web 应用程序。
1. 基本安装
Playwright 支持移动端页面测试,使用设备模拟技术,可以让我们在移动 Web 浏览器中测试响应式的 Web 应用程序;Playwright 支持所有浏览器的无头模式和非无头模式的测试;
Playwright 的安装和配置过程非常简单,首先安装 playwright ,然后浏览器直接可以使用 playwright install 安装;
pip install playwright
playwright install
这时 Playwright 会安装 Chromium,Firefox,WebKit 浏览器并配置一些驱动;
2. 基本使用
Playwright 支持两种编写模式,一种是和 Pyppeteer 一样的异步模式,一种是和 Selenium 一样的同步模式,可以根据实际需要选择不同的模式。
同步模式
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
# headless 默认设置为 True,即无头模式
browser = browser_type.launch(headless=False)
# 使用 context 来创建 new_page 方便管理
# context = browser.new_context()
# page = context.new_page()
# 使用 browser 直接创建 new_page
page = browser.new_page()
page.goto('https://www.baidu.com')
page.screenshot(path=f'screenshot-{browser_type.name}.png')
print(page.title())
browser.close()
browser.close()
首先导入 sync_playwright 方法,该方法的返回值是一个 PlaywrightContextManager 对象,可以理解为一个浏览器上下文管理器,我们将其赋值为 p 变量,PlaywrightContextManager 对象可以调用 chromium,firefox,webkit 创建三种实例,然后可以使用这些实例的 launch 方法返回一个 Browser 对象;
在这里最好使用 context 来创建 page,这样我们可以使用 context.pages 来控制 page;
异步模式
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = await browser_type.launch(headless=False)
page = await browser.new_page()
await page.goto('https://www.baidu.com')
await page.screenshot(path=f'screenshot-{browser_type.name}.png')
print(await page.title())
await browser.close()
asyncio.run(main())
这里得到的效果和 同步模式 得到的效果一致;
3. 代码生成
Playwright 可以录制我们在浏览器中的操作并自动生成代码,这个功能可以通过 Playwright 命令行调用 codegen 实现;

playwright codegen --help 结果如下
Options:
-o, --output <file name> saves the generated script to a file
--target <language> language to generate, one of javascript, playwright-test, python, python-async, python-pytest, csharp, csharp-mstest,
csharp-nunit, java, java-junit (default: "python")
--save-trace <filename> record a trace for the session and save it to a file
--test-id-attribute <attributeName> use the specified attribute to generate data test ID selectors
-b, --browser <browserType> browser to use, one of cr, chromium, ff, firefox, wk, webkit (default: "chromium")
--block-service-workers block service workers
--channel <channel> Chromium distribution channel, "chrome", "chrome-beta", "msedge-dev", etc
--color-scheme <scheme> emulate preferred color scheme, "light" or "dark"
--device <deviceName> emulate device, for example "iPhone 11"
--geolocation <coordinates> specify geolocation coordinates, for example "37.819722,-122.478611"
--ignore-https-errors ignore https errors
--load-storage <filename> load context storage state from the file, previously saved with --save-storage
--lang <language> specify language / locale, for example "en-GB"
--proxy-server <proxy> specify proxy server, for example "http://myproxy:3128" or "socks5://myproxy:8080"
--proxy-bypass <bypass> comma-separated domains to bypass proxy, for example ".com,chromium.org,.domain.com"
--save-har <filename> save HAR file with all network activity at the end
--save-har-glob <glob pattern> filter entries in the HAR by matching url against this glob pattern
--save-storage <filename> save context storage state at the end, for later use with --load-storage
--timezone <time zone> time zone to emulate, for example "Europe/Rome"
--timeout <timeout> timeout for Playwright actions in milliseconds, no timeout by default
--user-agent <ua string> specify user agent string
--viewport-size <size> specify browser viewport size in pixels, for example "1280, 720"
-h, --help display help for command
下面这串代码将启动一个 Firefox 浏览器,使用 异步操作 将结果输出到 script.py 文件中
playwright codegen --target python-async -b firefox -o script.py
4. 支持移动端浏览器
这里模拟打开 iPhone 12 Pro Max 上的 webkit 浏览器,要注意的是需要放入到 new_context 中配置;
import time
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
iphone_12_pro_max = p.devices['iPhone 12 Pro Max']
# iphone_12_pro_max -> {'user_agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Mobile/15E148 Safari/604.1', 'viewport': {'width': 428, 'height': 746}, 'device_scale_factor': 3, 'is_mobile': True, 'has_touch': True, 'default_browser_type': 'webkit'}
browser = p.webkit.launch(headless=False)
context = browser.new_context(
**iphone_12_pro_max,
locale='zh-CN',
geolocation={'longitude': 116.39014, 'latitude': 39.913904},
permissions=['geolocation']
)
page = context.new_page()
page.goto('https://amap.com')
page.wait_for_load_state(state='networkidle')
page.screenshot(path='location-iphone.png')
time.sleep(10)
browser.close()
这里的 wait_for_load_state 方法表示等待页面的某个状态完成,这里我们传入的 state 是 networkidle,也就是网络空闲状态。这意味着这里传入 networkidle 可以标识当前页面初始化和数据加载完成的状态。加载完成后,我们再调用 screenshot 方法来截屏;
wait_for_load_state的三种状态:
'load'- wait for theloadevent to be fired.'domcontentloaded'- wait for theDOMContentLoadedevent to be fired.'networkidle'- DISCOURAGED wait until there are no network connections for at least500ms. Don’t use this method for testing, rely on web assertions to assess readiness instead.
5. 选择器
1) 文本选择
文本选择支持直接使用 text= 这样的语法进行筛选
page.click("text=Log in")
这代表选择并点击文本内容是 Log in 的节点;
2) CSS 选择器搭配 文本值 和 节点关系
在这里我们不仅可以使用普通的 CSS 选择器,还可以搭配 文本值 和 节点关系 进行匹配;
# 点击文本值中包含 Playwright 的字符串的 css 节点
page.click("css选择器:has-text('Playwright')")
# 点击文本值为 Contact us 的 css 节点
page.click("css选择器:text('Contact us')")
# 点击 css1 节点中包含 css2 节点的节点
page.click("css选择器1:has(css选择器2)")
# 点击位于 css 节点右侧的文本值为 Username 的节点
page.click("css选择器:right-of(:text('Username'))")
3) XPath
和 CSS 选择器一样,不过 XPath 需要在开头指定 xpath=字符串
page.click("xpath=//button")
这里选择 button 节点;
6. 常用操作方法
1) 事件监听
我们在创建 page 对象之后,使用 page.on('response', on_response) 执行监听 response 事件;
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
我们可以通过 on_response 方法拦截 Ajax 请求,直接拿到响应结果,即使这个 Ajax 请求中有加密参数;其他事件的监听可以在Page | Playwright Python找到;
2) 获取页面源代码
我们可以在页面加载完毕后,处于网络空闲状态时使用 content 方法获取网页源代码;
page.wait_for_load_state(state='networkidle')
html = page.content()
3) 页面点击
传入的参数必须是 selector,其他参数都是可选的,selector 代表选择器,用来匹配想要点击的节点,如果有多个节点和传入的选择器相匹配,那么只使用第一个 节点;
page.click(selector, click_count, timeout, position, force, **kwargs)
click 方法的内部执行逻辑:
- 找到与 selector 匹配的节点,如果没有找到,就一直等待直到超时,由 timeout 定义超时时间;
- 如果按钮设置了不可点击,就等该按钮变成可点击状态再去点击,除非设置 force 为 true 强制点击;
- 如果页面太长,节点未在当前页面呈现,就会滚动直到呈现出来;
- position 需要传入一个字典,带有 x 和 y 属性,代表点击位置相对节点左上角的偏移量;
4) 文本输入
value 表示文本输入的值,如果没有找到,就一直等待直到超时,由 timeout 定义超时时间;
page.fill(selector, value, **kwargs)
5) 获取节点属性
获取 selector 的 属性 name 的值,如果没有找到,就一直等待直到超时,由 timeout 定义超时时间;
page.get_attribute(selector, name, **kwargs)
6) 获取多个节点
使用 query_selector_all 方法可以获取所有节点,它会返回节点列表,通过遍历得到其中的单个节点后,可以接着调用上面介绍的针对单个节点的方法完成一些操作和获取属性;
elements = page.query_selector_all('选择器')
其中每个节点各对应一个 ElementHandle 对象,可以调用 ElementHandle 对象的 get_attribute 方法获取节点的属性,也可以通过 text_content 方法获取节点的文本;
7) 获取单个节点
使用的方法是 query_selector,如果传入的选择器匹配到多个节点,则只会返回第一个;
element = page.query_selector('选择器')
8) Route:网络劫持
Route | Playwright Python,这个方法可以实现网络劫持和修改操作,例如修改 request 的属性,修改响应结果等;
修改 request 的属性:无法加载图片
from playwright.sync_api import sync_playwright
import re
import time
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/")
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
time.sleep(10)
browser.close()
在这里调用 route 方法,第一个参数通过正则表达式传入了 URL 路径,这里的 re.compile(r"(\.png)|(\.jpg)") 匹配上了所有的 .png 和 .jpg 图片的链接,遇到这样的请求会直接取消;进而无法加载图片
修改响应结果:自定义响应页面
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def modify_response(route, request):
route.fulfill(path="./custom_response.html")
page.route('/', modify_response)
page.goto("https://spa6.scrape.center/")
time.sleep(10)
browser.close()
通过 route 方法,我们可以灵活的控制请求和响应内容;















 3028
3028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









