







📢 人工智能何以颠覆生物科技行业?| 摩根士丹利观点
https://weibo.com/ttarticle/p/show?id=2309404826722167292124
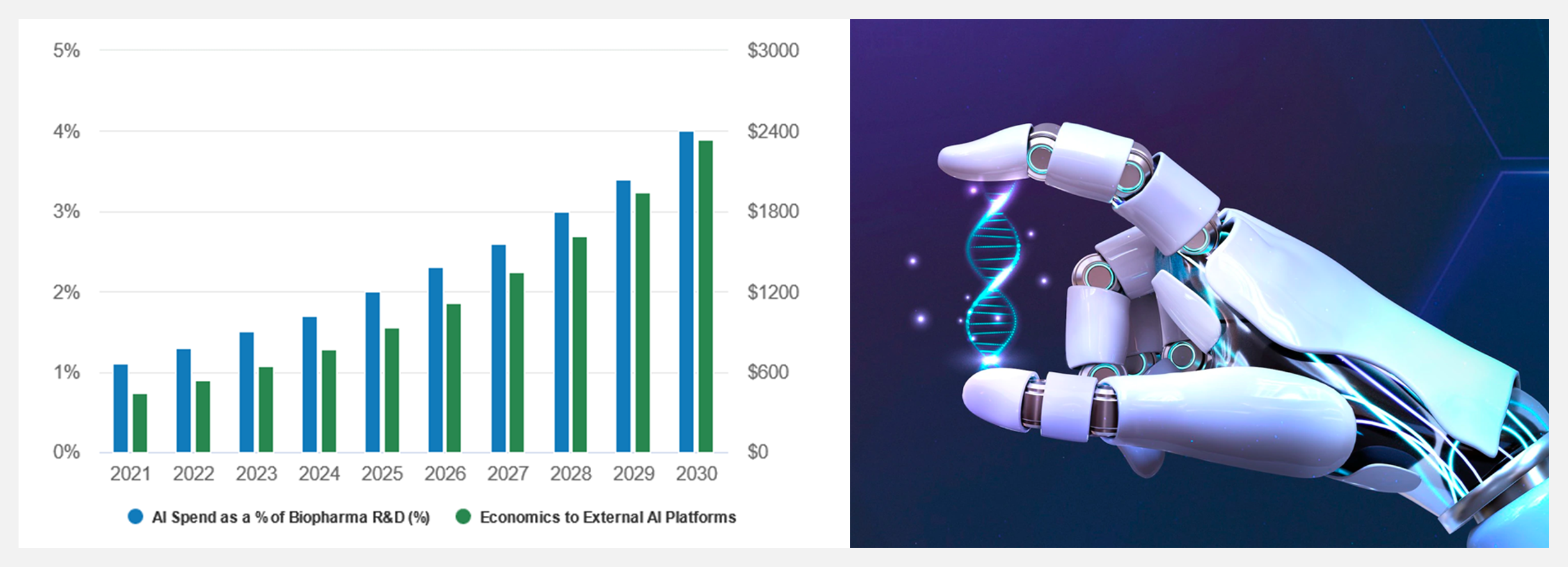
生物科技公司将人工智能和机器学习应用于药物开发,或将在未来10年研发出数十种款新药,开拓价值高达500亿美元的市场。
对生物科技公司而言,新药的传统研发过程就是不断的高成本试错。但在人工智能的帮助下,新一批药物研发平台帮助制药公司利用大量数据集来快速识别患者反应标志物,并以更经济实惠、且快速有效的方式研发针对性的药物靶标。
摩根士丹利研究部分析师预计,未来两年,人工智能药物试验数据驱动下,生物制药行业将迎来拐点。人工智能药物开发机构与大型生物制药公司之间加强合作,将为行业带来不小变化。假设在生物制药研发预算内每年适度增加人工智能投资,人工智能药物开发平台将通过合作带来显著的收入增长。(来源:公司数据、摩根士丹利研究部)
工具&框架
🚧 『AutoCorrect』文案自动纠正或检查建议工具
https://github.com/huacnlee/autocorrect
https://huacnlee.github.io/autocorrect/
AutoCorrect是基于 Rust 编写的 CLI 工具,用于自动纠正或检查并建议文案,给 CJK(中文、日语、韩语)与英文混写的场景,补充正确的空格,纠正单词,同时尝试以安全的方式自动纠正标点符号等等。

类似 ESlint、Rubocop、Gofmt 等工具,AutoCorrect 可以用于 CI 环境,它提供 Lint 功能,能便捷的检测出项目中有问题的文案,起到统一规范的作用。AutoCorrect 支持各种类型源代码文件,能自动识别文件名,并准确找到字符串、注释做自动纠正。
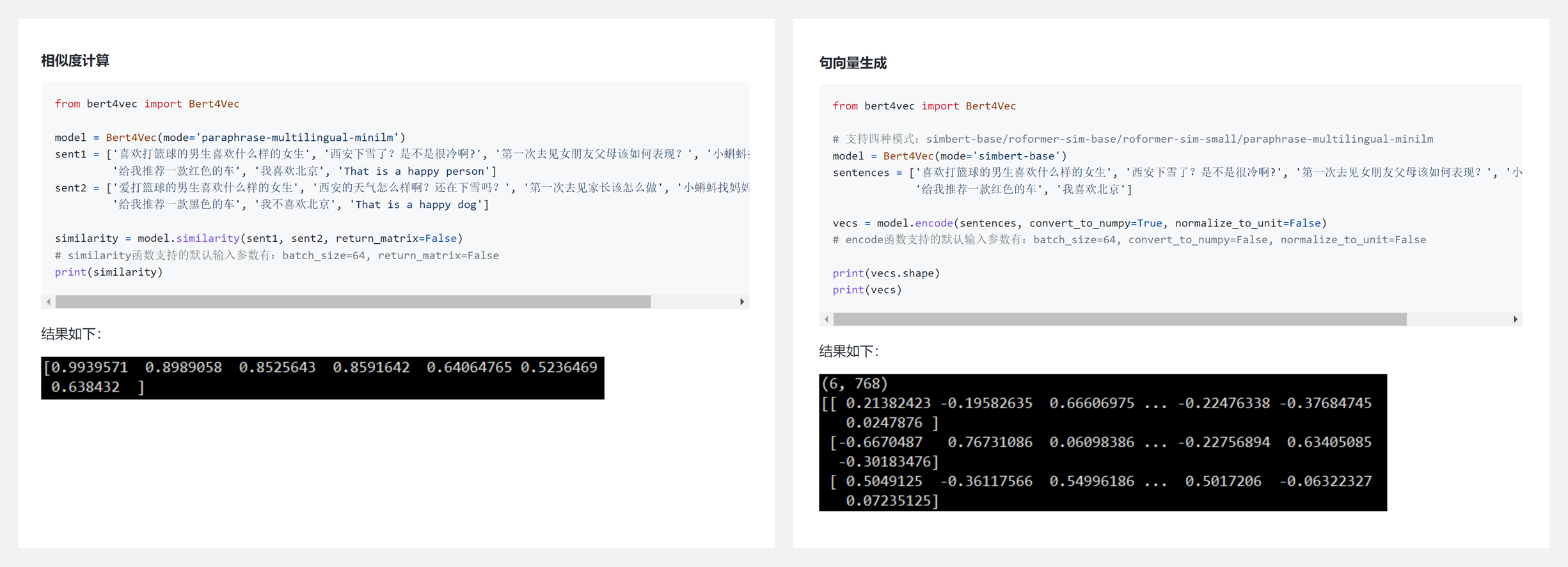
🚧 『bert4vec』基于预训练的句向量生成工具(Python)
https://github.com/zejunwang1/bert4vec
bert4vec 是一个基于预训练的句向量生成工具,目前支持加载的句向量预训练模型包括 SimBERT、RoFormer-Sim 和 paraphrase-multilingual-MiniLM-L12-v2。
其中,SimBERT 与 RoFormer-Sim 为苏剑林老师开源的中文句向量表示模型,paraphrase-multilingual-MiniLM-L12-v2 为 sentence-transformers 开放的多语言预训练模型,支持中文句向量生成。
🚧 『AITemplate』将神经网络转换成高性能CUDA/HIP C++代码
https://github.com/facebookincubator/AITemplate
https://facebookincubator.github.io/AITemplate/
AITemplate(AIT)是一个 Python 框架,它将深度神经网络转化为 CUDA(NVIDIA GPU)/HIP(AMD GPU)C++ 代码,以实现极快的推理服务。
AITemplate 具备高性能、统一/开放/灵活的特点:接近 fp16 TensorCore(NVIDIA GPU)/MatrixCore(AMD GPU)在主要模型上的性能,源代码完全开放、乐高式的易扩展高性能基元,并支持新的模型。
🚧 『druid』数据优先的 Rust 原生 UI 设计工具包
https://github.com/linebender/druid
Druid 是一个实验性的 Rust 原生 UI 工具包。它希望给用户提供完美的体验。因此它在性能、丰富的交互调色板、与本地平台的良好互动等部分都做了设计和优化。
🚧 『Hatch』现代可扩展的 Python 项目管理器
Hatch是一个现代的、可扩展的Python项目管理器。它具备标准化的构建系统、强大的环境管理、轻松发布到PyPI或其他资源、可配置的项目生成、反应灵敏的 CLI 等。
博文&分享
👍 『120 Data Science Projects You Can Try with Python』适合学习/练手的120个(Python)数据科学项目
https://python.plainenglish.io/85-data-science-projects-c03c8750599e
数据科学的初学者,如果不在数据集上实现一些案例,就很难完全理解所学到的内容。如果你正在困惑如何开启一些数据科学的实例项目,那么这篇文章刚好适合你!
作者在本文中整理了 120 个 Python 数据科学项目,用于练习 Python 编程以及实现数据科学的所有概念:分类、回归、情感分析、文本分析、推荐系统、数据分析、价格预测、神经网络、语言检测、自然语言处理NLP、计算机视觉等等。

👍 『A walk through latent space with Stable Diffusion』生成模型的隐空间速览探索
https://keras.io/examples/generative/random_walks_with_stable_diffusion/
生成图像的模型可以学习视觉世界的『latent manifold (隐空间)』——每个点映射到图像的低维向量空间。那么,映射后图像的隐空间就变成了连续与可插值的,即:
- 在空间上移动一个点,相应的图像只会稍微改变(连续性)。
- 对于空间中的任意两点A和B,划定一条空间内的路径,就可以将A移动到B,路径中的点就是插值点。
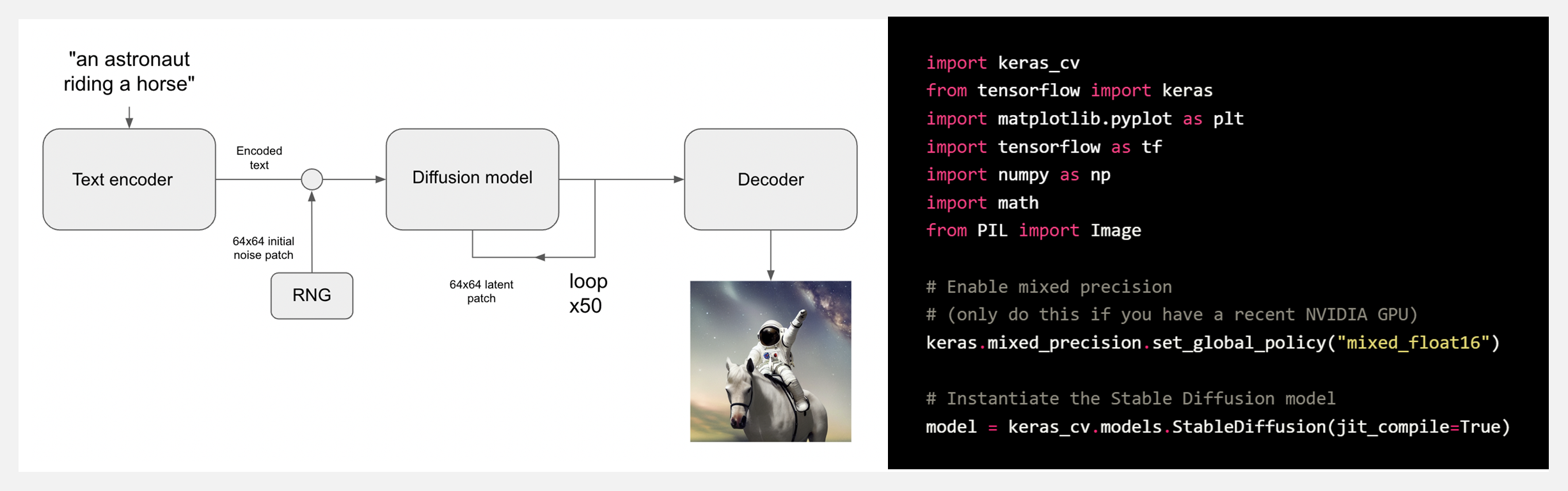
Latent space walking/latent space exploration(隐空间游走/隐空间探索)是对隐空间中的一个点进行采样并逐渐改变潜在表示的过程。它最常见的应用是生成动画。对于高质量的隐表示,就会产生连贯的动画。这些动画可以提供对隐空间特征图的洞察,并改进训练过程。

这份指南展示了如何利用 KerasCV 中的稳定扩散 API,在『稳定扩散的视觉隐空间』以及『文本编码器的隐空间』中,执行快速插值和循环遍历。

数据&资源
🔥 『DigiFace-1M Dataset』面向人脸识别的百万人脸图像数据集
https://github.com/microsoft/DigiFace1M
https://microsoft.github.io/DigiFace1M/

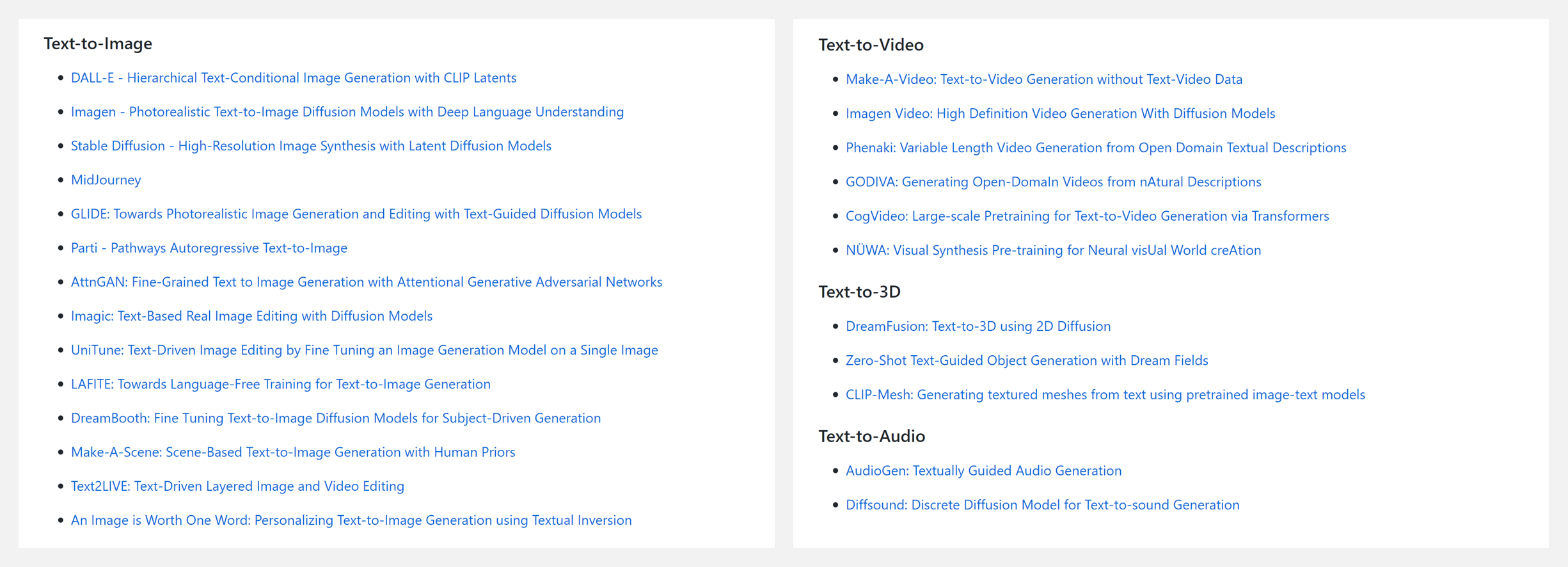
🔥 『Text2All』文本指导生成模型大列表
https://github.com/AvrahamRaviv/Text2All
资源列表包含以下内容:
- Text-to-Image
- Text-to-Video
- Text-to-3D
- Text-to-Audio
- Text-to-Motion
- Text-to-Style
研究&论文
科研进展
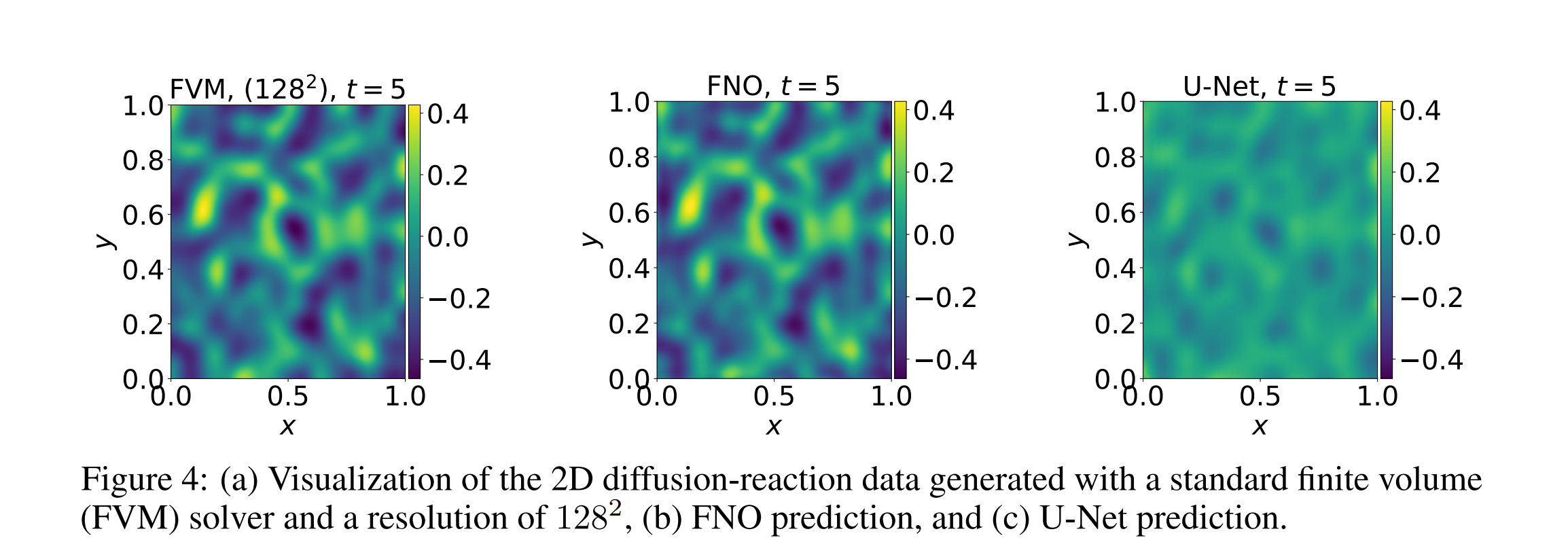
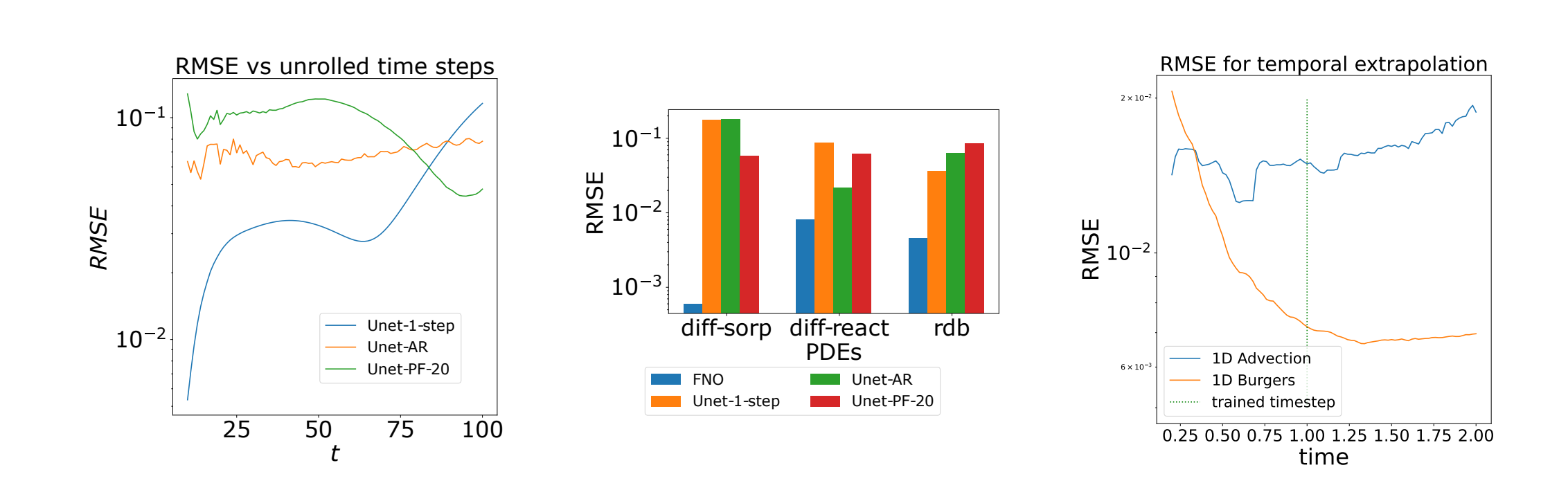
- 2022.10.13 『机器学习』 PDEBENCH: An Extensive Benchmark for Scientific Machine Learning
- 2022.09.29 『图像生成』DreamFusion: Text-to-3D using 2D Diffusion
- 2022.10.13 『目标检测』 Exploring Long-Sequence Masked Autoencoders
⚡ 论文:PDEBENCH: An Extensive Benchmark for Scientific Machine Learning
论文时间:13 Oct 2022
领域任务:Machine Learning, Computer Vision, 机器学习,计算机视觉
论文地址:https://arxiv.org/abs/2210.07182
代码实现:https://github.com/pdebench/pdebench
论文作者:Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Dan MacKinlay, Francesco Alesiani, Dirk Pflüger, Mathias Niepert
论文简介:With those metrics we identify tasks which are challenging for recent ML methods and propose these tasks as future challenges for the community./通过这些指标,我们确定了对最近的ML方法具有挑战性的任务,并提出这些任务作为社区的未来挑战。
论文摘要:近年来,基于机器学习的物理系统建模受到越来越多的关注。尽管取得了一些令人印象深刻的进展,但仍然缺乏易于使用但仍然具有挑战性和代表广泛问题的科学ML的基准。我们介绍了PDEBench,这是一个基于偏微分方程(PDE)的时间依赖性仿真任务的基准套件。PDEBench由代码和数据组成,以经典数值模拟和机器学习基线为基准来衡量新型机器学习模型的性能。我们提出的基准问题集有以下独特的特点。(1) 与现有基准相比,PDE的范围更广,从相对常见的例子到更现实和困难的问题;(2) 与先前的工作相比,有更大的现成数据集,包括在更多的初始和边界条件以及PDE参数下的多次模拟运行;(3) 具有用户友好的API的更可扩展的源代码,用于数据生成和流行机器学习模型(FNO, U-Net, PINN, 基于梯度的反演方法)的基线结果。PDEBench允许研究人员使用标准化的API为自己的目的自由扩展基准,并将新模型的性能与现有基线方法进行比较。我们还提出了新的评估指标,目的是在科学ML的背景下对学习方法有一个更全面的了解。通过这些指标,我们确定了对最近的ML方法具有挑战性的任务,并提出这些任务作为社区的未来挑战。该代码可在 https://github.com/pdebench/PDEBench
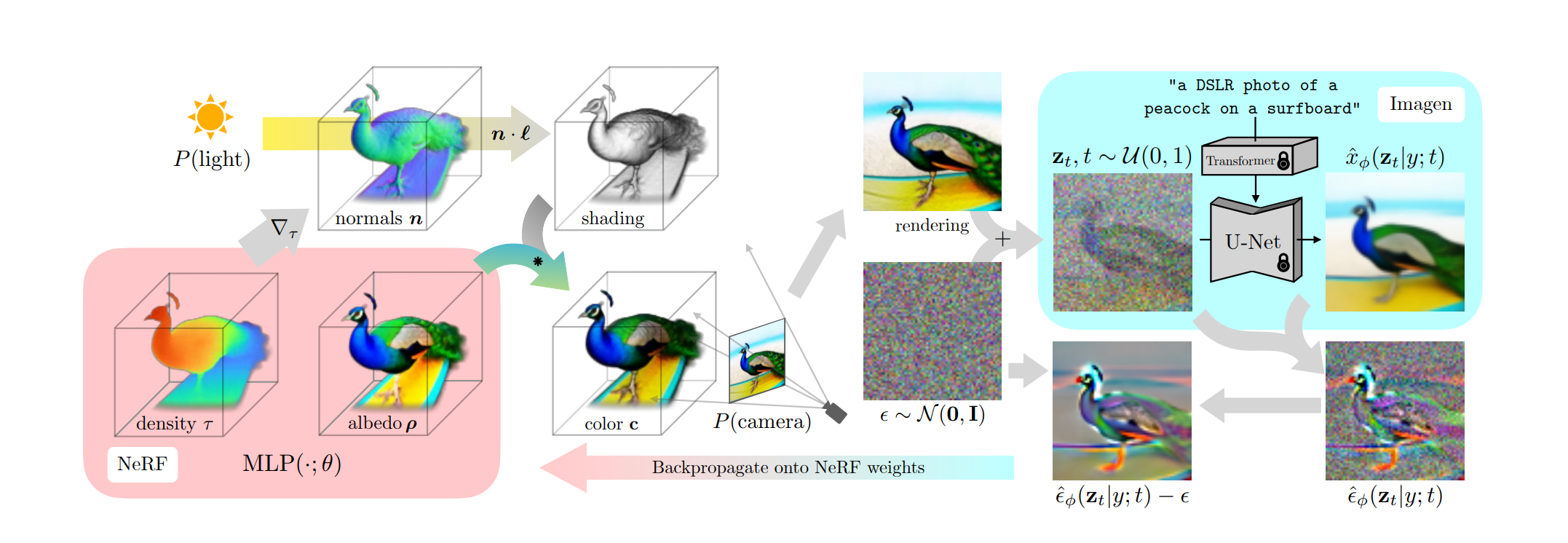
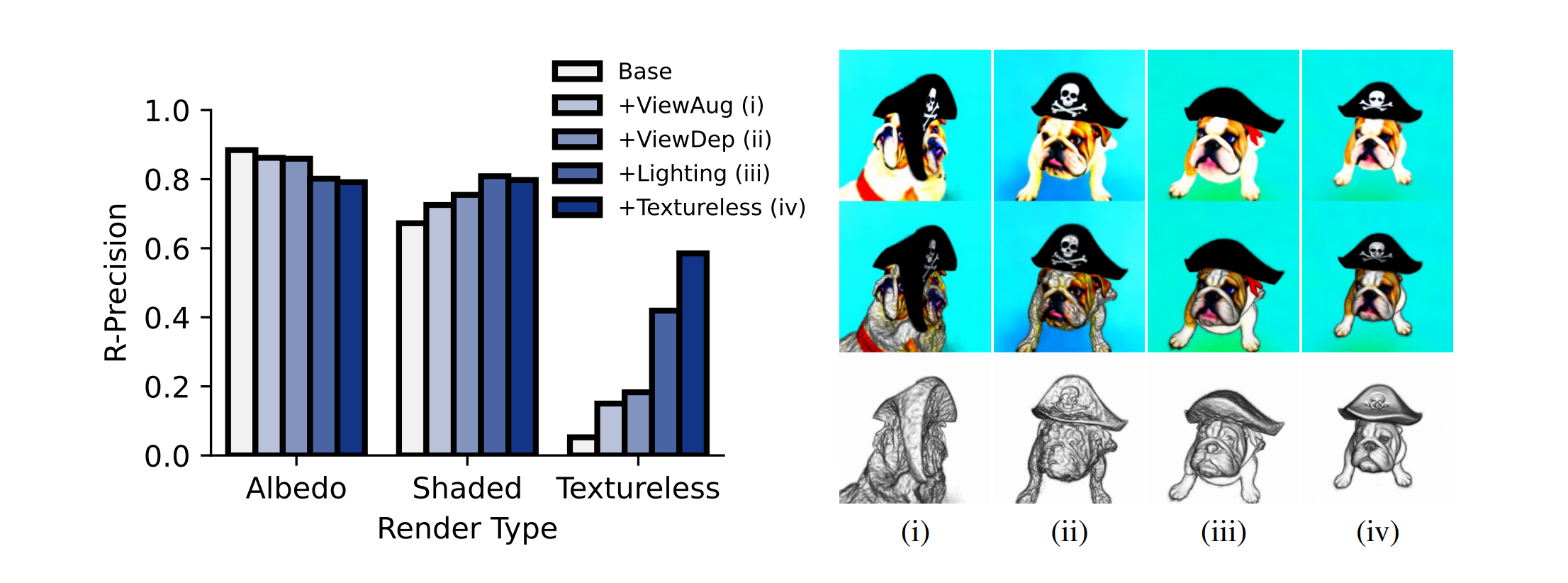
⚡ 论文:DreamFusion: Text-to-3D using 2D Diffusion
论文时间:29 Sep 2022
领域任务:Denoising, Image Generation, 去噪,图像生成
论文地址:https://arxiv.org/abs/2209.14988
代码实现:https://github.com/ashawkey/stable-dreamfusion
论文作者:Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
论文简介:Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss./在一个类似DeepDream的程序中使用这种损失,我们通过梯度下降来优化一个随机初始化的3D模型(一个神经辐射场,或NeRF),从而使其从随机角度的2D渲染达到一个低损失。
论文摘要:最近在文本到图像合成方面的突破是由在数十亿图像-文本对上训练的扩散模型驱动的。将这种方法应用于三维合成需要大规模的标记三维数据集和高效的三维数据去噪架构,而这两者目前都不存在。在这项工作中,我们通过使用预先训练好的二维文本到图像的扩散模型来执行文本到三维的合成,从而规避了这些限制。我们引入了一种基于概率密度蒸馏的损失,使得二维扩散模型可以作为优化参数化图像生成器的先验。在一个类似DeepDream的程序中使用这种损失,我们通过梯度下降法优化一个随机初始化的三维模型(一个神经辐射场,或NeRF),使其从随机角度的二维渲染达到低损失。由此产生的给定文本的三维模型可以从任何角度观看,通过任意的照明重新点亮,或者合成到任何三维环境中。我们的方法不需要3D训练数据,也不需要修改图像扩散模型,这证明了预训练的图像扩散模型作为先验因素的有效性。
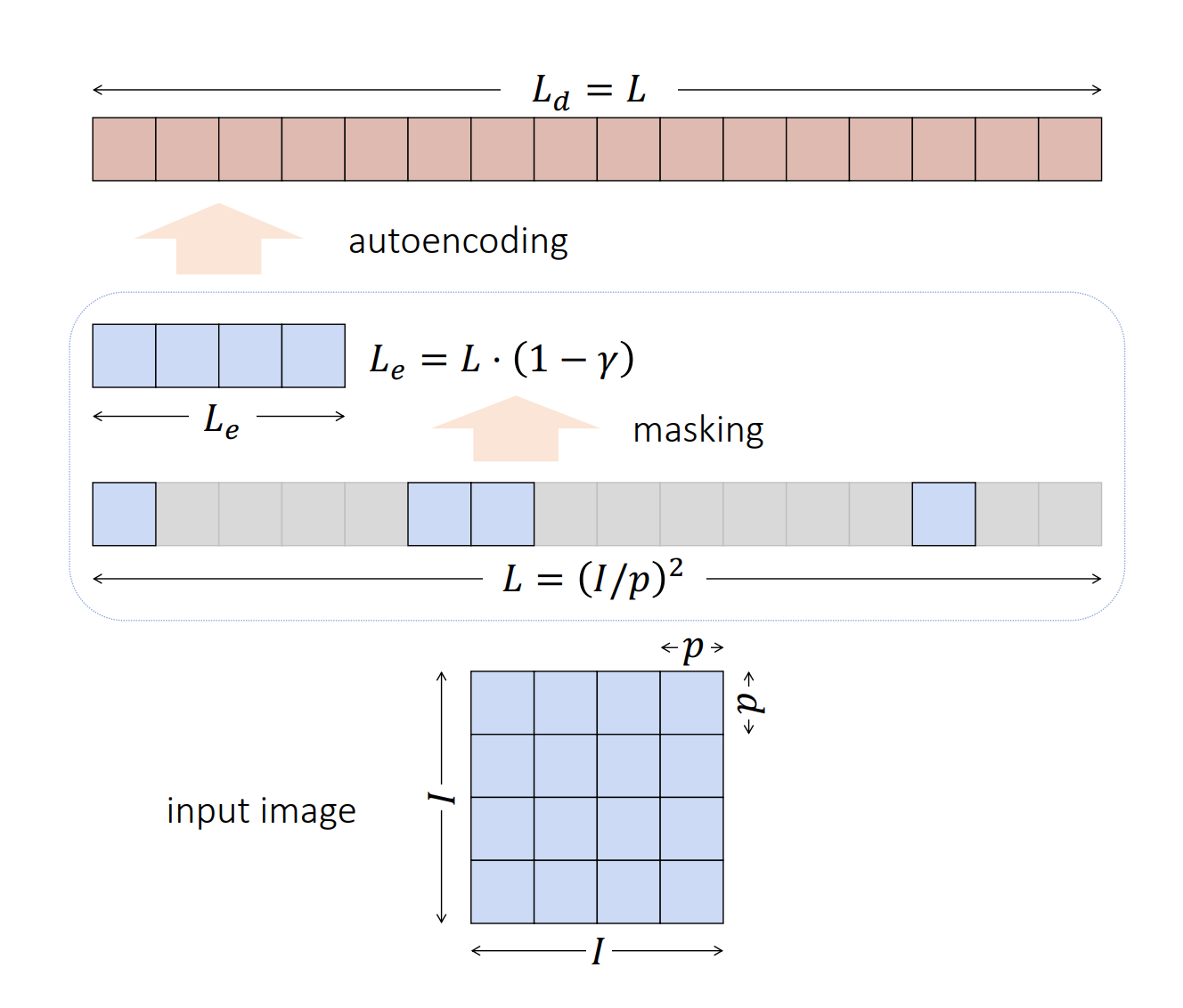
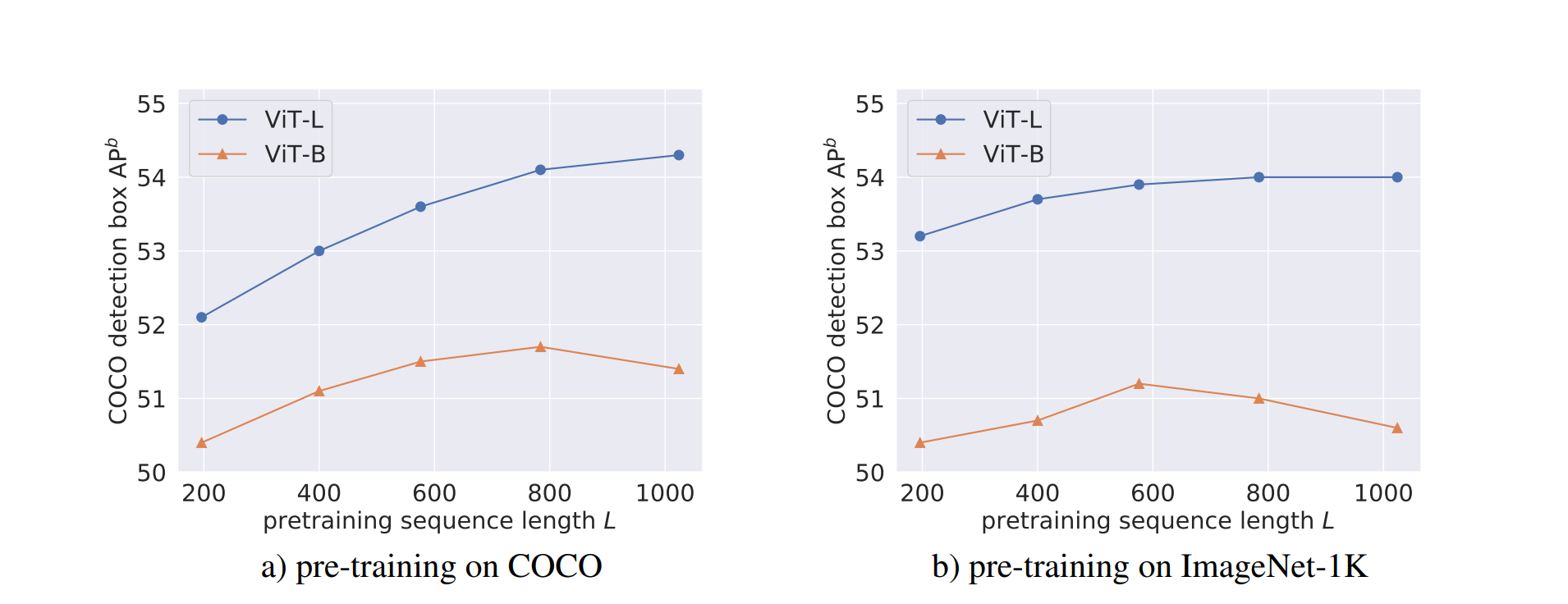
⚡ 论文:Exploring Long-Sequence Masked Autoencoders
论文时间:13 Oct 2022
领域任务:Object Detection, 目标检测
论文地址:https://arxiv.org/abs/2210.07224
代码实现:https://github.com/facebookresearch/long_seq_mae
论文作者:Ronghang Hu, Shoubhik Debnath, Saining Xie, Xinlei Chen
论文简介:Masked Autoencoding (MAE) has emerged as an effective approach for pre-training representations across multiple domains./掩码自动编码(MAE)已成为跨领域预训练表征的有效方法。
论文摘要:遮蔽自动编码(MAE)已经成为跨领域预训练表征的一种有效方法。与自然语言中的离散标记相比,图像自动编码的输入是连续的,并受制于其他规格。我们在预训练阶段系统地研究了每个输入规格,发现序列长度是进一步扩展MAE的一个关键轴。我们的研究导致了一个长序列版本的MAE,对原始配方的变化最小,只是将掩码大小与补丁大小解耦。对于物体检测和语义分割,我们的长序列MAE在所有的实验设置中都显示出一致的收益,在转移过程中没有额外的计算成本。虽然长序列的预训练被认为对检测和分割最有利,但我们也通过保持标准图像大小和只增加序列长度在ImageNet-1K分类上取得了强大的结果。我们希望我们的发现能够为计算机视觉的扩展提供新的见解和途径。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











