









前言:
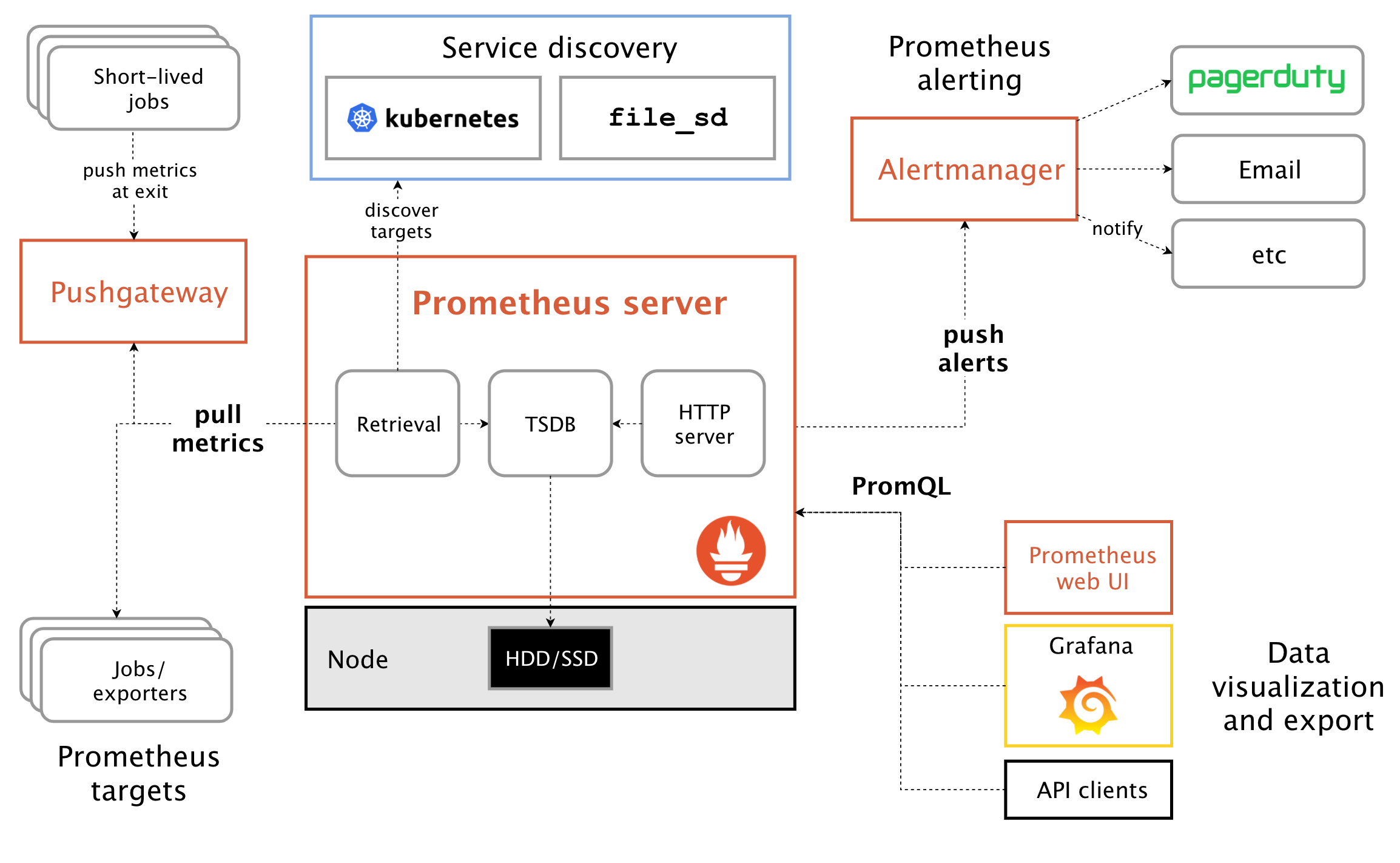
从下面的架构图看出,当prometheus拉取信息时,可以通过配置rules(规则)预警,把符合预警信息的指标push给altermanager,
altermanager然后把这些指标通过邮件,webhook,微信推送(企业)等推送给相关人员。
这就是一个完整的企业监控系统。
altermanager安装:
从prometheus https://prometheus.io/download/ 官网下载 altermanager
比如我是推送企业微信,编辑 alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
templates: # 告警模板
- './template/test.tmpl'
route:
group_by: ['alertname'] # 分组标签
group_wait: 10s #告警等待时间。告警产生后等待10s,如果有同组告警一起发出
group_interval: 10s # 两组告警的间隔时间
repeat_interval: 1m # 重复告警的时间间隔,减少相同邮件的发送频率,此处设计测试为1分钟
#receiver: 'web.hook'
receiver: 'wechat' #设置默认接收者
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
agent_id: '1000242' # 自建应用的agentId
to_user: '@all' # 接收告警消息的人员Id
api_secret: '*************' # 自建应用的secret
corp_id: '********' # 企业ID然后修改prometheus的配置文件 vim prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
#- targets:
- targets: ['localhost:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/prometheus/rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
cd /usr/local/prometheus/prometheus/rules 下创建各个预警规则。
mysql-alert.yml
groups:
- name: MySQLStatsAlert
rules:
- alert: MySQL is down
expr: mysql_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} MySQL is down"
description: "MySQL 数据库挂了. 请立即采取行动!"
- alert: open files high
expr: mysql_global_status_innodb_num_open_files > (mysql_global_variables_open_files_limit) * 0.75
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} open files high"
description: "Open files is high. Please consider increasing open_files_limit."
- alert: Read buffer size is bigger than max. allowed packet size
expr: mysql_global_variables_read_buffer_size > mysql_global_variables_slave_max_allowed_packet
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} Read buffer size is bigger than max. allowed packet size"
description: "Read buffer size (read_buffer_size) is bigger than max. allowed packet size (max_allowed_packet).This can break your replication."
- alert: Sort buffer possibly missconfigured
expr: mysql_global_variables_innodb_sort_buffer_size <256*1024 or mysql_global_variables_read_buffer_size > 4*1024*1024
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} Sort buffer possibly missconfigured"
description: "Sort buffer size is either too big or too small. A good value for sort_buffer_size is between 256k and 4M."redis-alert.yml
groups:
- name: redis_alert
rules:
- alert: redis is down
expr: redis_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} redis is down"
description: "redis 挂了. 请立即采取行动!"
### 内存 ###
# 默认内存告警策略
- alert: redis内存95%
expr: ((floor(redis_memory_used_rss_bytes / redis_memory_max_bytes * 100) >= 95) or (floor(redis_mem_use_ratio) >= 95)) and ((redis_memory_max_bytes <= 1024 * 1024 * 1024 * 4) or (redis_mem_total_size <= 4))
for: 3m
labels:
severity: warning
annotations:
description: "[{{ $labels.alias }}],地址:[{{ $labels.addr }}],告警值为:[{{ $value }}%],告警初始时长为3分钟."
- alert: redis内存98%
expr: ((floor(redis_memory_used_rss_bytes / redis_memory_max_bytes * 100) >= 98) or (floor(redis_mem_use_ratio) >= 98)) and ((redis_memory_max_bytes > 1024 * 1024 * 1024 * 4) or (redis_mem_total_size > 4))
for: 3m
labels:
severity: warning
annotations:
description: "[{{ $labels.alias }}],地址:[{{ $labels.addr }}],告警值为:[{{ $value }}%],告警初始时长为3分钟."
然后启动alertmanager和prometheus。
效果
关掉 redis或者是mysql ,微信会受到以下消息
















 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









