







目录
一、前情提要
上篇解释了树的一系列概念,这篇围绕树的三种存储方式:双亲表示法,孩子表示法和孩子兄弟表示法进行解释,并给出相应代码并附以注释。
二、树的三种存储方式
树的基本操作
相对于线性结构,树的操作就完全不同了,这里我们给出一些基本和常用的操作。
ADT 树(Tree)
Data
树是由一个根结点和若干棵子树构成的。树中结点具有相同数据类型及层次关系。
Operation
InitTree(*T);//构造空树T
DestroyTree(*T);//销毁树T
CreateTree(*T,definition);//按definition中给出树的定义来构造树
ClearTree(*T);//若树T存在,则将树T清空为空树
TreeEmpty(T);//若T为空树,返回True,否则返回False
TreeDepth(T);//返回T的深度
Root(T);//返回T的根结点
Value(T,Cur_E);//Cur_E是树T中一个结点,返回此结点的值。
Assign(T,Cur_E,Value);//给树T的结点Cur_E赋值为Value。
Parent(T,Cur_E);//若Cur_E是树T的非根结点,则返回它的双亲,否则返回空。
LeftChild(T,Cur_E);//若Cur_E是树T的非叶结点,则返回它的最左孩子,否则返回空。
RightChild(T,Cur_E);//若Cur_E有右兄弟,则返回它的右兄弟,否则返回空。
InsertChild(*T,*P,i,c);//其中p所指向树T的某个结点,i为所指结点p的度+1,
//非空树c与T不相交,操作结果为插入c为树T中p所指结点的第i棵子树。
DeleteChild(*T,*p,i);//其中p所指树T的某个结点,i为所指结点p的度
//操作结果为删除T中p所指结点的第i棵子树。
endADT(一)双亲表示法
对于一棵树而言,除了根结点外,其余的每个结点,它不一定有孩子,但是一定有且仅有一个双亲。
我们假设以一组连续的空间存储树的结点,同时在每个结点中,附设一个指示器指示其双亲结点在数组中的位置。也就是说,每个结点除了知道自己是谁之外,还知道它的双亲在哪里。
所以它的结构就有两部分:
data:数据域,存储结点的数据信息。
parent:指针域,存储该结点的双亲在数组中的下标。
如下图所示:

由于根结点是没有双亲的,所以我们约定根结点的指针域设置为-1,这就意味着,我们所有的结点都存有它双亲的位置。
优缺点说明:
优点:这样的存储结构,我们可以根据结点的parent指针,很容易的找到他们的双亲结点。所用的时间复杂度为O(1),知道parent为-1时,表示找到了树的根。
缺点:那如果我们想知道结点的孩子是什么?没有办法,只能遍历一边才能知道。
Q1:那如果我们想知道结点的孩子,怎么办???
Q2:那如果我们想知道结点的兄弟,怎么办???
(二)孩子表示法
由于树中每个结点可能存在多棵子树,可以考虑用多重链表。
即每个结点有多个指针域,其中每个指针指向一棵子树的根结点,我们把这种方法叫做多重链表表示法。
但是,树的每个结点的度,也就是它的孩子个数是不同的。所以可以设计两种方案来解决。
方案一
一种是指针域的个数就等于树的度。我们知道树的度就是树中各个结点度的最大值。
结构如下图所示:

其中Data是数据域,Child1~Childn是n个指针域,都用来指向该结点的孩子结点。

对于上面这张图来说,树的度就是3。所以我们指针域的个数就是3。
树的指针指向如下图所示:
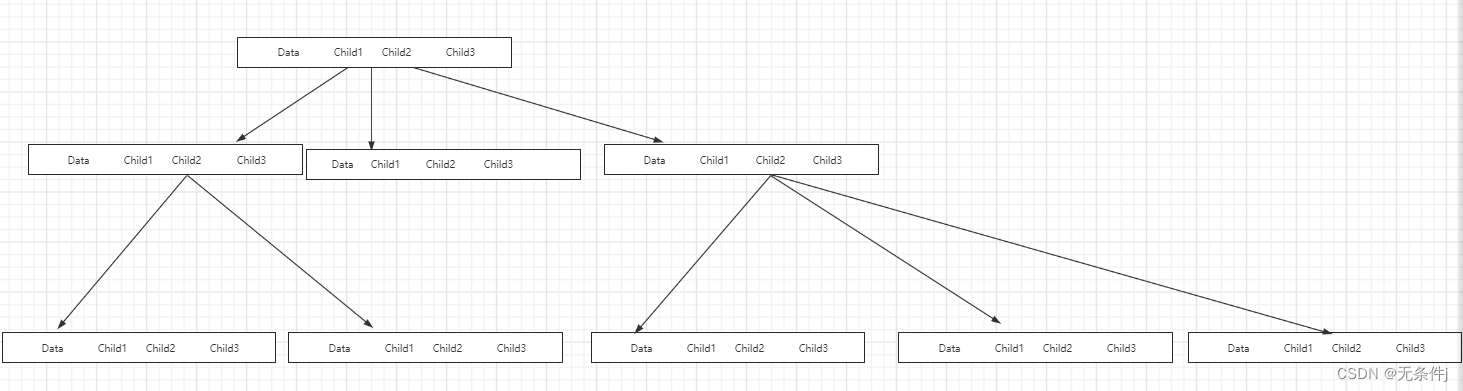
缺点Or优点?
这种方法在面对树中各结点的度相差很大时,显然是很浪费空间的,因为有很多的结点,它没有那么多孩子结点,所以造成了指针域是空的。不过如果树的各结点的度相差很小的时候,那就意味着开辟的空间被充分利用了,这时存储结构的缺点反而成为了优点。
既然很多指针域都可能为空,为什么不按需分配呢?于是我们就想出了第二种方法。
方案二
第二种方案每个结点指针域的个数等于该结点的度,我们专门取一个位置Degree来存储结点指针域的个数,其结构如下表所示:

其中,Data是数据域;Degree是度域,也就是存储该结点的孩子结点个数;Child1~Childn就是指针域,指向该结点的各个孩子结点。
这种方法说白了,就是在方案一中进一步优化,多一个Degree。图的样子和方案一的差不多。
优点Or缺点?
这种方法克服了浪费空间的缺点,对空间的利用率是很高了,但是由于各个结点的链表是不同的结构,加上要维护结点的度的数值,在运算上就会带来时间的损耗。
那有没有办法,既可以提高空间利用率又能使结点的结构相同呢?
其实是可以的。在之前我们为了遍历整棵树,把每一个结点放到一个顺序存储结构的数组中是合理的。但是每个结点的孩子是有多少是不确定的。所以我们可以对每个结点的孩子建立一个单链表体现它的关系。
这就是我们要讲的孩子表示法。
具体办法是,把每个结点的孩子排列起来,以单链表作为存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空。然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中。
以下图为参照:

左边一条ABCDEFGHIGJ都是头结点,被存在一维数组中。
每一个头结点后面都连着一条单链表,单链表连接着这个结点的孩子结点。
但是,这也存在着问题,我们如何知道某个结点的双亲是谁呢?
如果不修改代码的话,我们必须遍历一整棵树,会很费时。但是也有解决方法,就是将双亲表示法和孩子表示法结合一下,多开辟一块地方,存放该结点的双亲。我们将这种方法叫做“双亲孩子表示法”。应该算是孩子表示法的一种改进。
(三)孩子兄弟表示法
上面分别从双亲的角度和孩子的角度去研究树的存储结构,如果我们从树结点兄弟的角度考虑一下呢?当然,对于树这样的层级结构来说,只研究结点的兄弟是不行的,我们观察后发现,任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的兄弟。
结点的结构如图所示:

我们可以看出来,左边的指针指向该结点的第一个孩子,右边的则指向它的第一个兄弟。
这种方法实现的示意图如下图所示:

这种表示法,给查找某个结点的某个孩子带来了方便,只需要通过孩子指针域,来找到该结点的第一个孩子,然后再通过孩子结点的兄弟指针域来找到孩子的兄弟,接着一直下去,直到找到具体的孩子。
当然,如果想找到某个结点的双亲,这个表示法也是有缺陷的,那怎么办呢?
如果真的有必要的话,其实完全可以再增加一个双亲指针域来解决快速查找双亲的问题。这里就不细说了。
三、代码实现
(一)双亲表示法
#include <stdio.h>
#include <stdlib.h>
#define MaxSize 10
typedef struct TreeNode
{
int Data;//结点中存放的数据
int Parent;//双亲指针域
}Node;
Node* Tree[MaxSize];//双亲表示法顺序存储
int Size=0;//目前存储结点的数量
int Max=MaxSize;//存储的最大个数
//创建根结点
void Insert_Root(int Data)
{
Node* New_Node=(Node*)malloc(sizeof(Node)); //开辟结点的内存空间
if(New_Node==NULL)
{
printf("申请内存失败");
return;
}
New_Node->Data=Data;
New_Node->Parent=-1; //给结点赋值
Tree[Size++]=New_Node; //将指针装进数组中。注意Size++,和++Size的区别。
}
//寻找双亲结点的下标
int Find_Parent(int Parent)
{
for(int i=0;i<Size;i++) //遍历存储结点的数组
{
if(Tree[i]->Data==Parent)
{
return i;//找到就返回
}
}
return -1;
}
//插入元素
void Insert_Child(int Data,int Parent)
{
if(Size==Max) //如果满了就退出
{
printf("元素已满");
return;
}
else
{
int Parent_Index=Find_Parent(Parent);//找到双亲结点的下标
if(Parent==-1)//没有找到
{
printf("不存在此双亲结点");
return;
}
else
{
Node* New_Node=(Node*)malloc(sizeof(Node));
if(New_Node==NULL)
{
printf("申请内存失败");
return;
}
New_Node->Data=Data;
New_Node->Parent=Parent;//处理新的结点,使新结点的指针指向自己的双亲结点。
Tree[Size++]=New_Node;//最后存入结点数组中
}
}
}
//展示树中的结点,顺带检验一下。
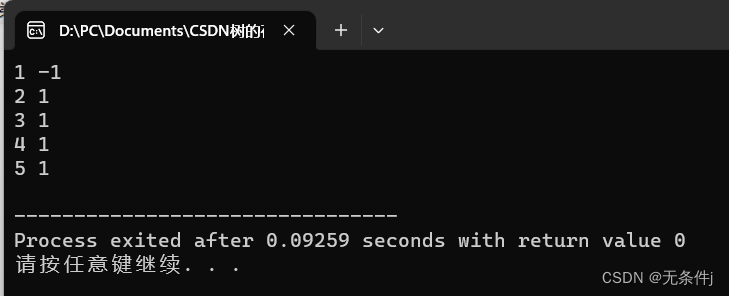
void Show()
{
for(int i=0;i<Size;i++)
{
printf("%d %d\n",Tree[i]->Data,Tree[i]->Parent);
}
}
int main()
{
Insert_Root(1);//创建根结点
Insert_Child(2,1);//下面创建的结点的双亲结点都是根结点。
Insert_Child(3,1);
Insert_Child(4,1);
Insert_Child(5,1);
Show();
return 0;
}
(二)孩子表示法
#include <stdio.h>
#include <stdlib.h>
#define MaxSize 10
typedef struct TreeNode
{
int Data; //数据域
struct TreeNode* Next;//指针域指向孩子结点
}Node;
Node* Tree[MaxSize]; //线性表存储头结点
int Size=0; //目前存储结点的个数
int Max=MaxSize; //存储的最大容量
//初始化操作
void Init(int Data)
{
Size=0; //目前的存储个数清零
Tree[Size]=(Node*)malloc(sizeof(Node));//创建根结点
Tree[Size]->Data=Data;
Tree[Size]->Next=NULL; //根结点指针域指向NULL
Size++;
}
//找到父节点
int Find_Parent(int Parent)
{
for(int i=0;i<Size;i++)//遍历结点,找到双亲结点
{
if(Tree[i]->Data==Parent)
{
return i;//找到就返回
}
}
return -1; //没找到就返回-1
}
//插入结点
void Create_Tree(int Data, int Parent)
{
if(Size==Max)//先判断是否存满了
{
printf("已满");
return;
}
Tree[Size]=(Node*)malloc(sizeof(Node));
Tree[Size]->Data=Data;
Tree[Size]->Next=NULL;
Size++;
int Parent_Index=Find_Parent(Parent);
if(Parent_Index==-1)//没找到双亲结点就退出
{
printf("未找到该双亲结点");
return;
}
else
{
Node* New_Node=(Node*)malloc(sizeof(Node));
if(New_Node==NULL)
{
printf("申请内存失败");
return;
}
else
{
New_Node->Data=Data;//给新的结点赋值
New_Node->Next=Tree[Parent_Index]->Next;//跟单链表头插的方式一样。
Tree[Parent_Index]->Next=New_Node;
}
}
}
//展示一下,顺带检验
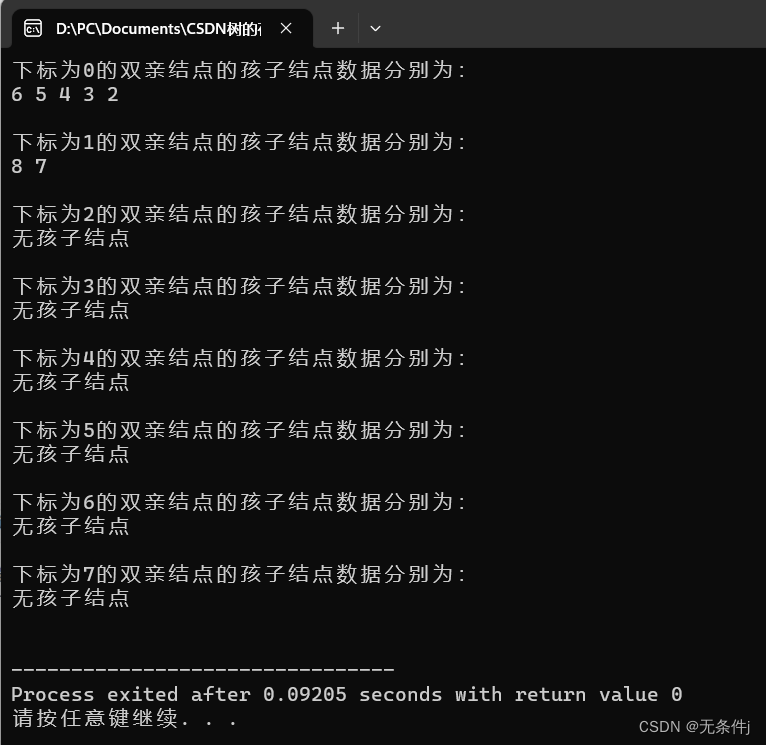
void Show()
{
for(int i=0;i<Size;i++)
{
printf("下标为%d的双亲结点的孩子结点数据分别为:\n",i);
if(Tree[i]->Next==NULL) printf("无孩子结点");
for(Node* j=Tree[i]->Next;j!=NULL;j=j->Next)
{
printf("%d ",j->Data);
}
printf("\n\n");
}
}
int main()
{
Init(1);
Create_Tree(2,1);
Create_Tree(3,1);
Create_Tree(4,1);
Create_Tree(5,1);
Create_Tree(6,1);
Create_Tree(7,2);
Create_Tree(8,2);
Show();
return 0;
} 
(三)孩子兄弟表示法
#include <stdio.h>
#include <stdlib.h>
typedef struct ChildSibling
{
int Data; //数据域
struct ChildSibling* Child;//孩子指针域
struct ChildSibling* Sibling;//兄弟指针域
}Node;
Node* Root;//根结点
Node* T;//临时结点
//初始化,建立根节点
void Init(int Data)
{
Root=(Node*)malloc(sizeof(Node));
Root->Data=Data;
Root->Child=NULL;//根结点的孩子指针和兄弟指针初始化为NULL
Root->Sibling=NULL;
}
//在以R为根的树中,查找数据为Key的结点
Node* GetNode(Node* R,int Key)
{
if(R->Data==Key) //如果该结点的值和Key相同,那么就直接返回
{
return Root;
}
if(R->Child!=NULL)//如果该结点的值和Key不同,并且有孩子结点
{
Node* P=GetNode(R->Child,Key);//递归查找以R->Child为根结点的树中,查找数据为Key的结点
if(P!=NULL&&P->Data==Key) //符合要求就返回
{
return P;
}
}
if(R->Sibling!=NULL)//如果该结点的值和Key不同,并且有兄弟结点
{
Node* P=GetNode(R->Sibling,Key);//递归查找以R->Sibling为根结点的树中,查找数据为Key的结点
if(P!=NULL&&P->Data==Key)//符合要求就返回
{
return P;
}
}
return NULL;
}
//插入 :Key是插入的数据,parent是Key的父亲结点的数据
void Insert(int Data,int Parent)
{
T=GetNode(Root,Parent);//先找到双亲结点
if(T!=NULL)//如果存在
{
Node* P=(Node*)malloc(sizeof(Node));
P->Data=Data;
if(T->Child!=NULL) //如果双亲结点其他有孩子结点
{
T=T->Child; //单链表的插入操作
P->Sibling=T->Sibling;
T->Sibling=P;
P->Child=NULL;
}
else //如果双亲结点没有孩子结点
{
T->Child=P; //让此结点称为双亲结点的孩子结点
P->Sibling=NULL;
P->Child=NULL;
}
}
else
{
printf("未找到对应的双亲结点");
}
}
int main()
{
Init(1);
Insert(2,1);
Insert(3,1);
Insert(4,1);
Insert(5,1);
Insert(6,1);
return 0;
}













 39万+
39万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









