







hadoop只有MapReduce和HDFS组件的时候的不足
1)抽象层次低,需要大量的人工编码
2)表达能力有限(不是所有的问题都能转化成MapReduce)
3)开发者自己管理作业(job)之间的依赖关系
4)难以看到程序整体逻辑(只能通过看代码才能理解到其中执行的逻辑)
5)执行迭代操作效率低(每执行一次都需要读写一次磁盘)
6)资源浪费(Map和Reduce分两个阶段运行)
7)实时性差(适合批注理,不支持实时交互)
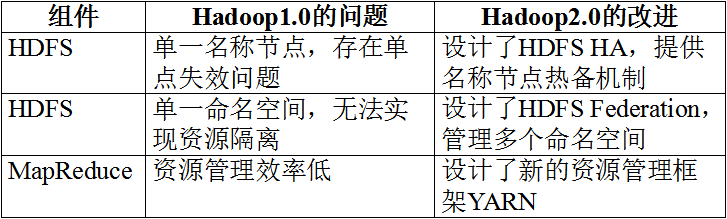
优化:1>自身核心组件MapReduce和HDFS的改进(hadoop2.0)
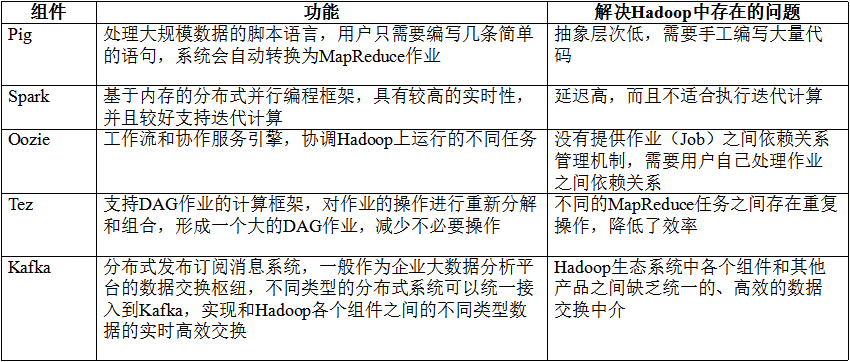
2>其他组件的不断加入和更新(pig、spark、kafka和tez等组件)
HDFS HA(high available解决热备份的问题)
HDFS HA是为了解决单点故障问题
HA集群设置两个名称节点,“活跃”和“待命”
两个名称节点的状态同步,可以借助于一个共享存储系统来实现(实现同步Editlog)
一旦活跃名称节点出现故障,就可以理解切换到待命名称节点
Zookeeper确保一个名称节点在对外服务(只能有一个节点对外提供服务)
名称节点维护映射信息,数据节点同时向两个名称节点汇报信息(实现同步FSImage)

HDFS Feferation(解决扩展性、系统的吞吐量(性能)、隔离性)
HDFS Feferation中设计了多个相互独立的名称节点,使得HDFS的命名服务能够水平的扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联盟(Feferation)的关系,不需要彼此协调。
HDFS Feferation所有的名称节点共享底层的存储资源,数据节点向所有的名称节点汇报
属于同一命名空间的块构成一个“块池”(块池是一个逻辑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4388
4388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









