







一、下载 Hadoop
Hadoop 发布版本在 https://hadoop.apache.org/releases.html 页面可下载 ;
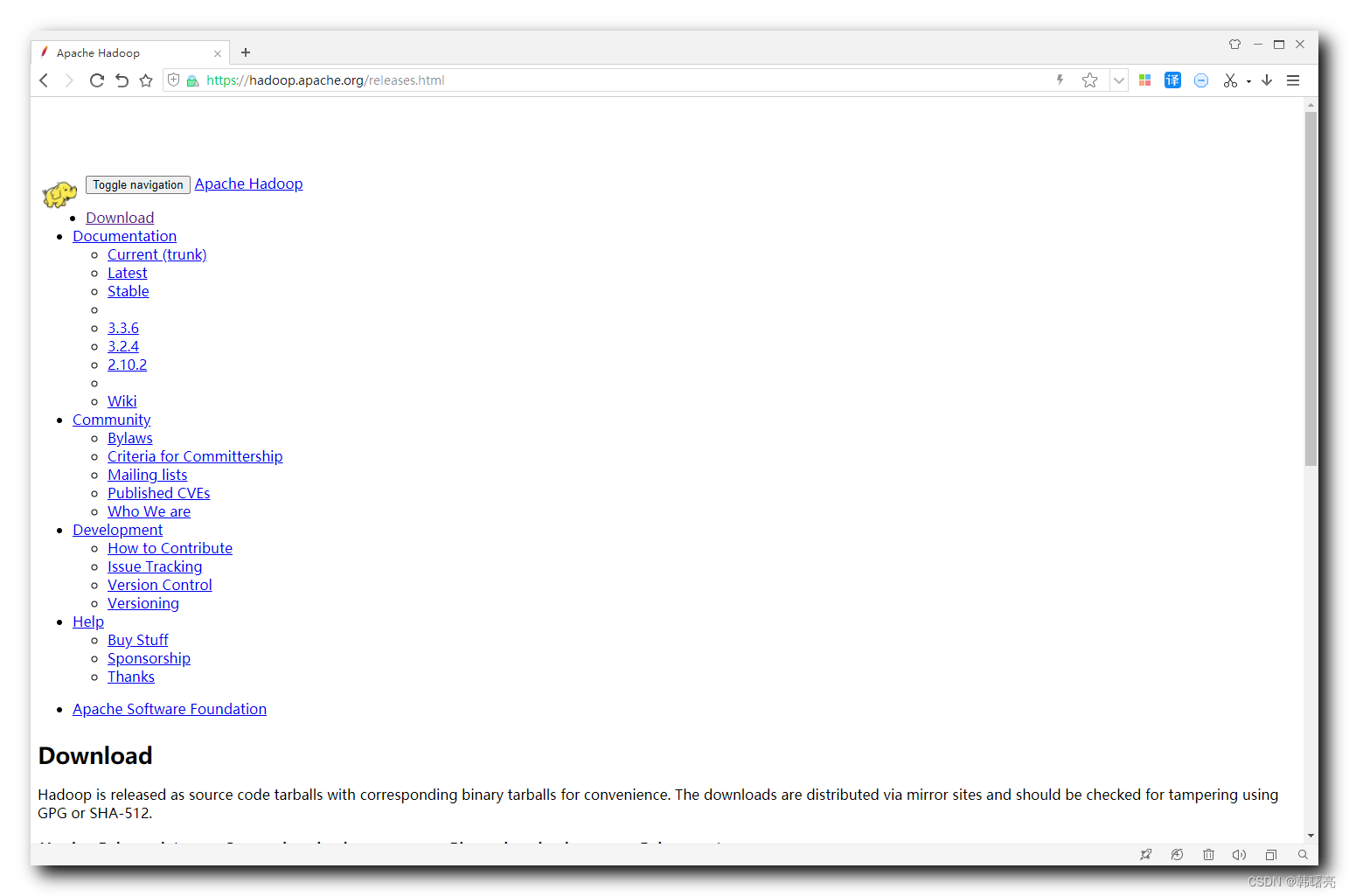
当前最新版本是 3.3.6 , 点击 Binary download 下的 binary (checksum signature) 链接 ,
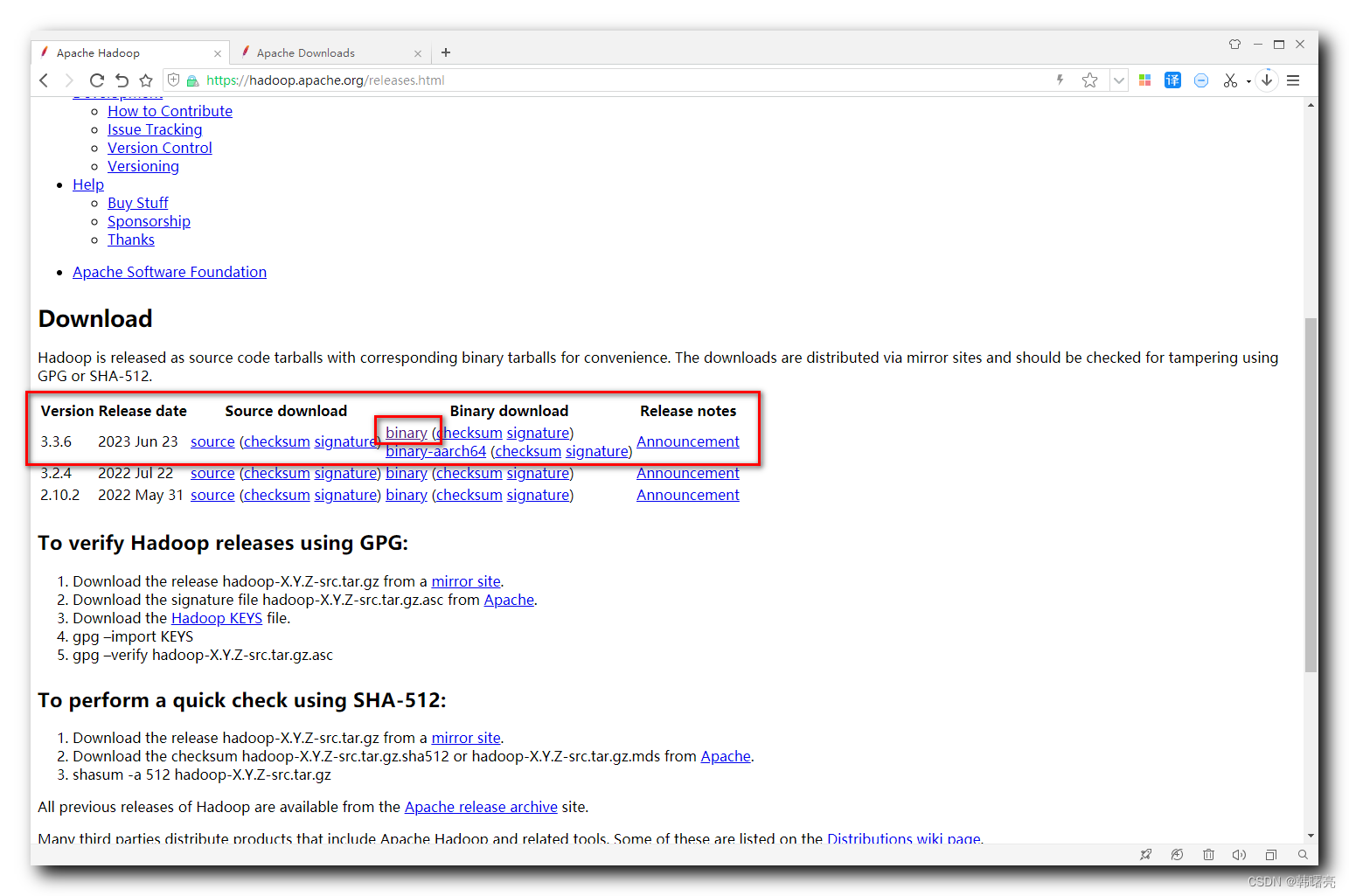
进入到 Hadoop 3.3.6 下载页面 :
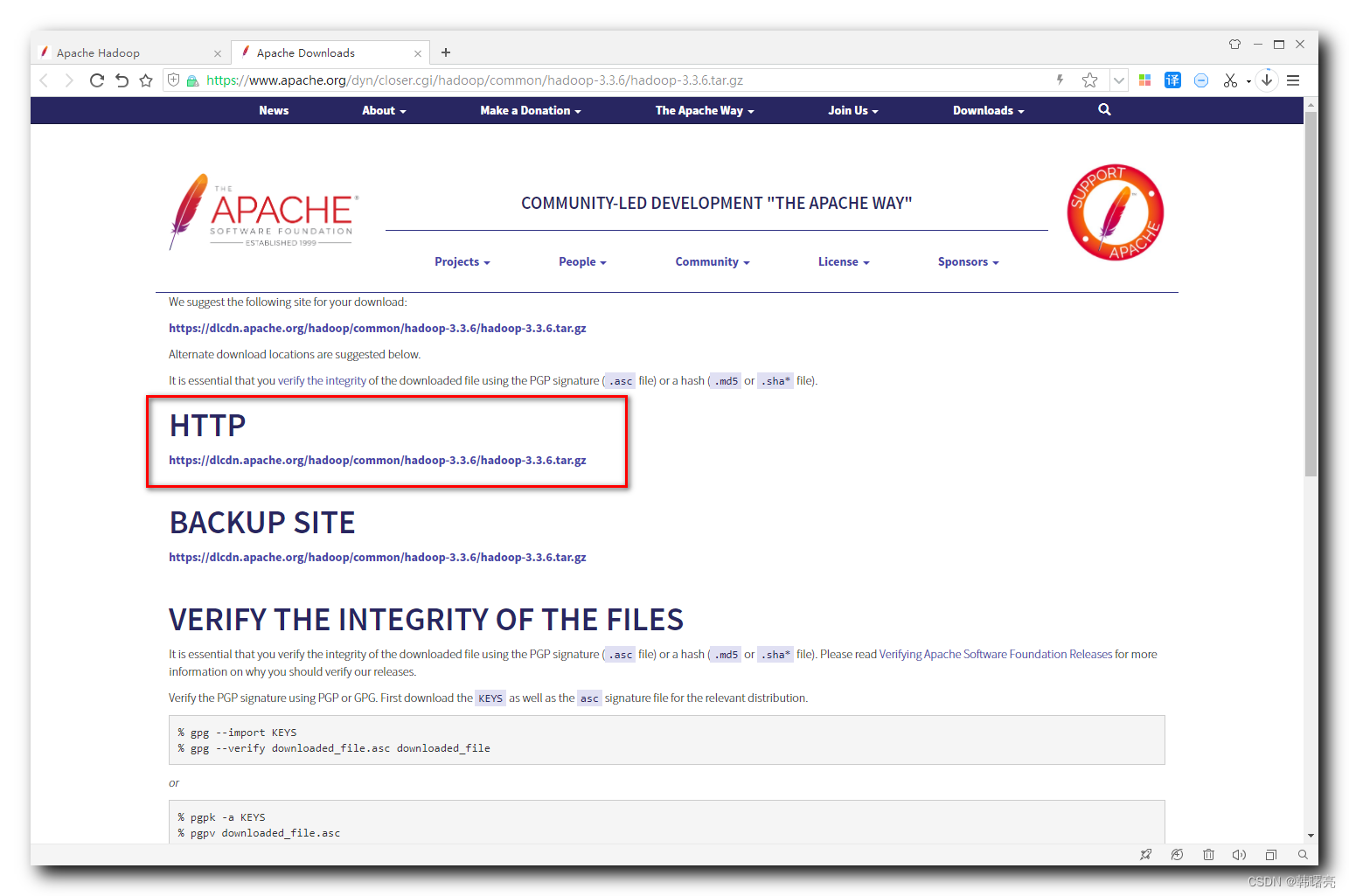
下载地址为 :
https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
官方下载速度很慢 ;

这里提供一个 Hadoop 版本 , Hadoop 3.3.4 + winutils , CSDN 0 积分下载地址 :
https://download.csdn.net/download/han1202012/88157568
二、解压 Hadoop
解压时 , 不要直接使用 解压工具 解压 , 会报错 ;
在 " 搜索 " 中 , 搜索 cmd , 然后右键点击 命令提示符 应用 ,
此时弹出的 命令提示符 有 管理员 权限 ;
进入 Hadoop 的安装目录 D:\001_Develop\052_Hadoop ,
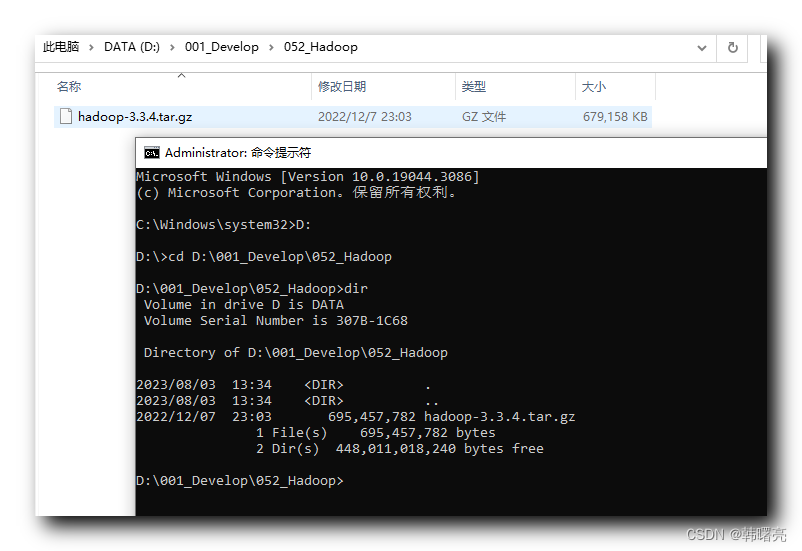
执行
tar zxvf hadoop-3.3.4.tar.gz
命令 , 解压该压缩包 , 这样可以将 hadoop 完美解压出来 , 不会报错 ;
解压 Hadoop 完成后 , Hadoop 路径为
D:\001_Develop\052_Hadoop\hadoop-3.3.4
三、设置 Hadoop 环境变量
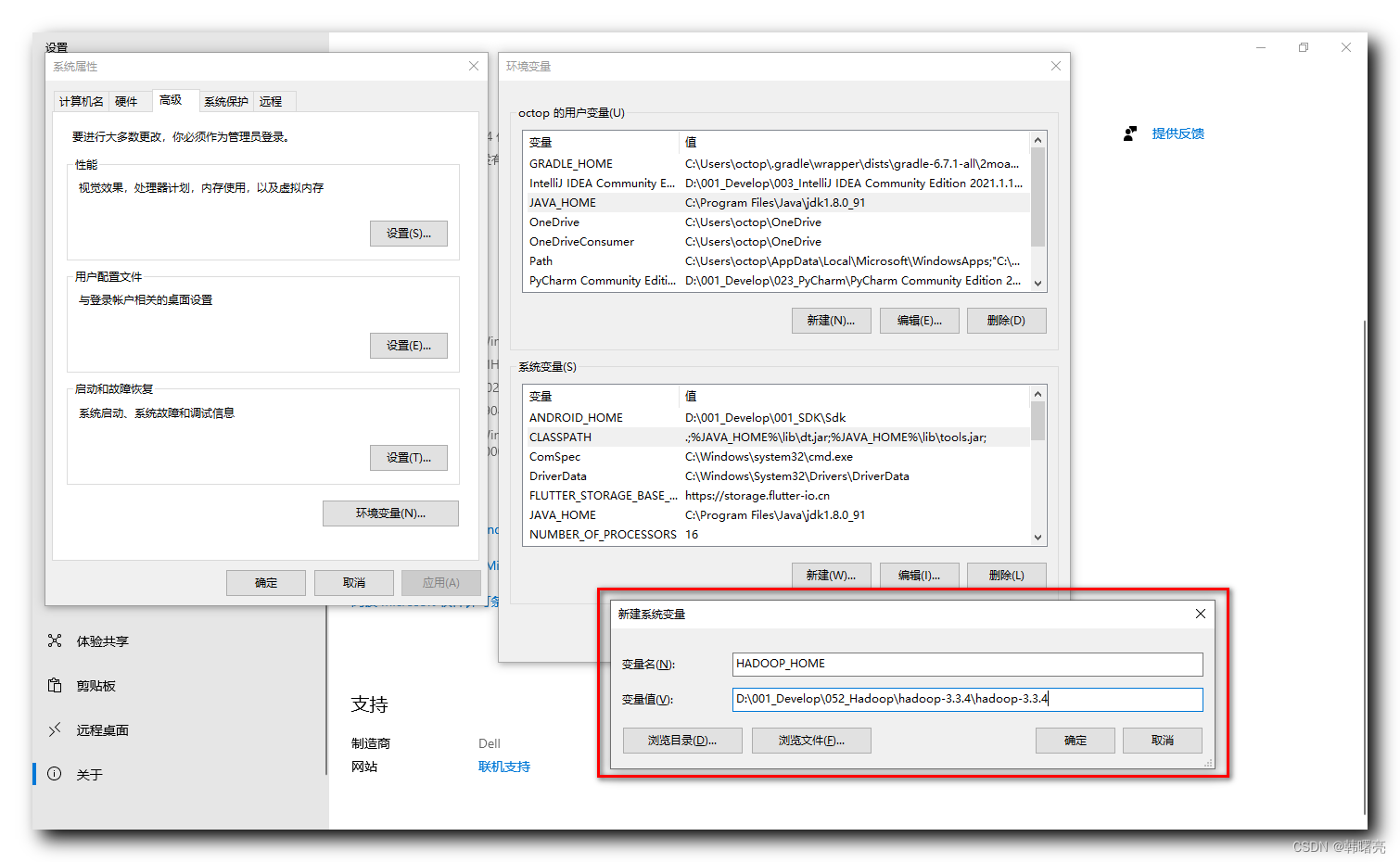
在 环境变量 中 , 设置
HADOOP_HOME = D:\001_Develop\052_Hadoop\hadoop-3.3.4
系统 环境变量 ;
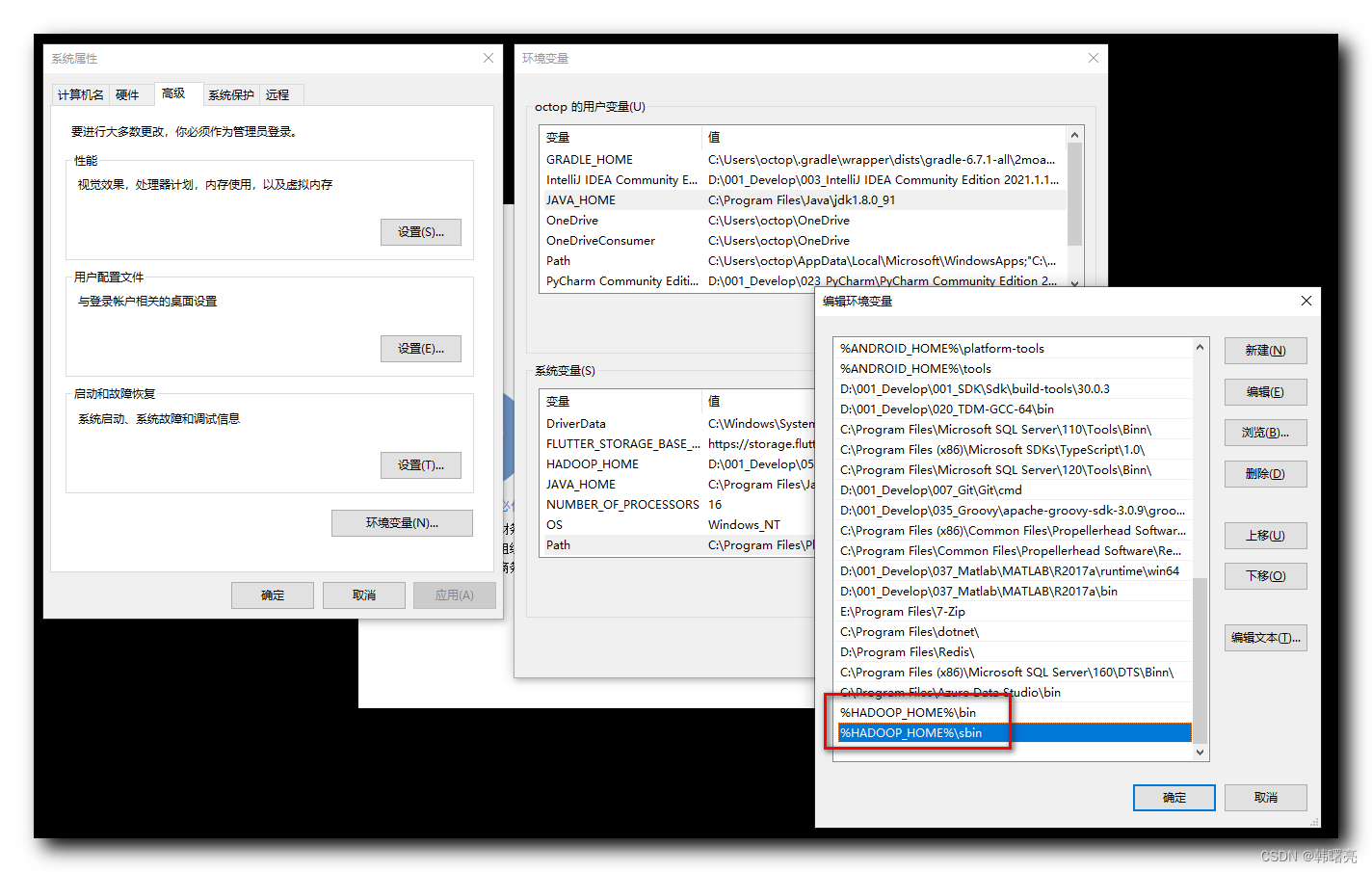
在 Path 环境变量中 , 增加
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
环境变量 ;
四、配置 Hadoop 环境脚本
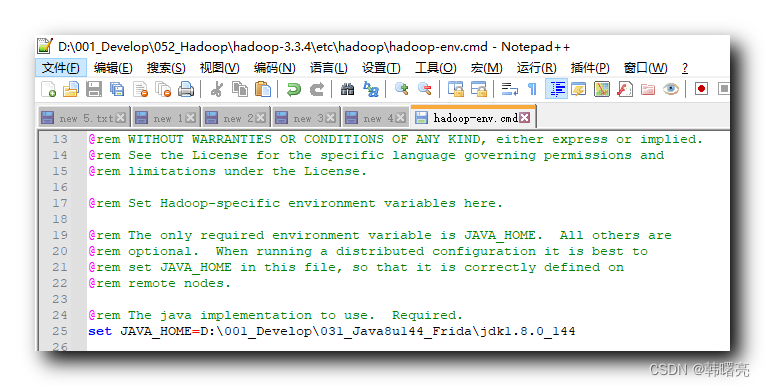
设置 D:\001_Develop\052_Hadoop\hadoop-3.3.4\etc\hadoop\hadoop-env.cmd 脚本中的 JAVA_HOME 为真实的 JDK 路径 ;
将
set JAVA_HOME=%JAVA_HOME%
修改为
set JAVA_HOME=D:\001_Develop\031_Java8u144_Frida\jdk1.8.0_144
注意 : 路径中不要出现空格 , 尤其是 Program Files 目录 , 不要把 JDK 安装在这个目录中 , 有大坑 ;
五、安装 winutils
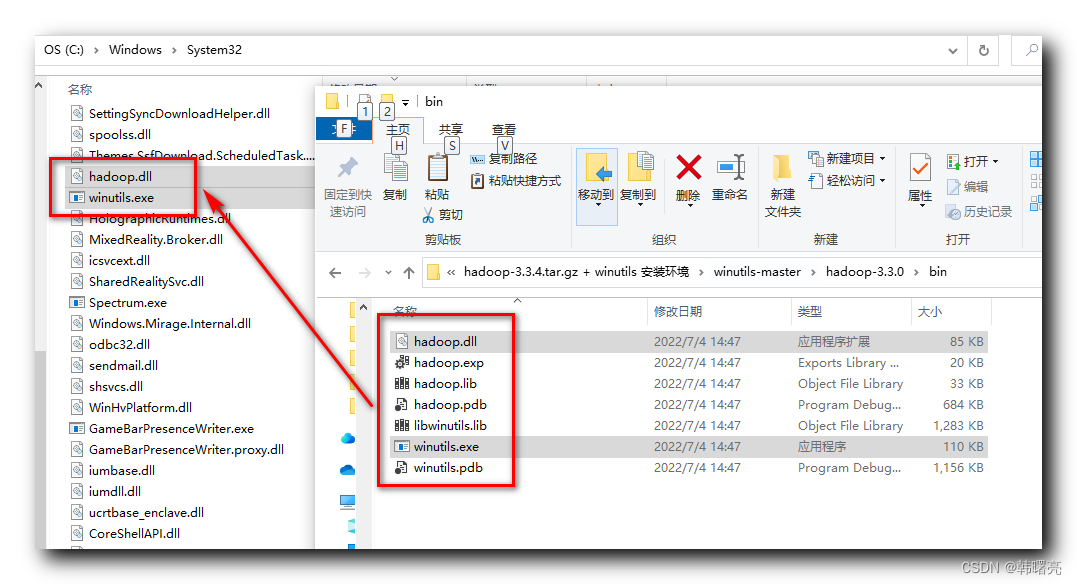
将 winutils-master\hadoop-3.3.0\bin 中的 hadoop.dll 和 winutils.exe 文件拷贝到 C:\Windows\System32 目录中 ;
六、重启电脑
重启电脑 , 一定要重启 , 否则不生效 ;
七、验证 Hadoop 安装效果
然后在命令行中 , 执行
hadoop -version
验证 Hadoop 是否安装完成 ;
C:\Windows\system32>hadoop -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) Client VM (build 25.144-b01, mixed mode)
C:\Windows\system32>hadoop
Usage: hadoop [--config confdir] [--loglevel loglevel] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
conftest validate configuration XML files
distch path:owner:group:permisson
distributed metadata changer
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
jnipath prints the java.library.path
kerbname show auth_to_local principal conversion
kdiag diagnose kerberos problems
key manage keys via the KeyProvider
trace view and modify Hadoop tracing settings
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
C:\Windows\system32>















 4018
4018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









