







表示学习旨在学习一系列低维稠密向量来表征语义信息,而知识表示学习是面向知识库中实体和关系的表示学习。当今大规模知识库(或称知识图谱)的构建为许多NLP任务提供了底层支持,但由于其规模庞大且不完备,如何高效存储和补全知识库成为了一项非常重要的任务,这就依托于知识表示学习。
transE算法就是一个非常经典的知识表示学习,用分布式表示(distributed representation)来描述知识库中的三元组。想象一下,这类表示法既避免了庞大的树结构构造,又能通过简单的数学计算获取语义信息,因此成为了当前表示学习的根基。
1 transE算法原理
我们知道知识图谱中的事实是用三元组 ( h , l , t ) (h,l,t) (h,l,t) 表示的,那么如何用低维稠密向量来表示它们,才能得到这种依赖关系呢?transE算法的思想非常简单,它受word2vec平移不变性的启发,希望 h + l ≈ t h+l≈t h+l≈t(此为归纳偏差?)。
光有这一个约束可不够。想让
h
+
l
≈
t
h+l≈t
h+l≈t,如何设置损失函数是个关键。我们发现表示学习都没有明显的监督信号,也就是不会明确告诉模型你学到的表示正不正确,那么想要快速收敛就得引入“相对”概念,即相对负例来说,正例的打分要更高,方法学名“negative sampling”。损失函数设计如下:
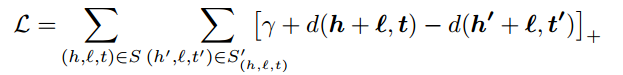
其中
(
h
′
,
l
,
t
′
)
(h',l,t')
(h′,l,t′)称为corrupted triplet,是随机替换头或尾实体得到(非同时,其实也可以替换relation)。
γ
\gamma
γ为margin。细看发现这就是SVM的soft margin损失函数,所以可以说,transE针对给定三元组进行二分类任务,其中负例是通过替换自行构造的,目标是使得最相近的正负例样本距离最大化。
论文中给出了详细的算法流程:

其中距离度量方式有L1范数和L2范数两种。在测试时,以一个三元组为例,用语料中所有实体替换当前三元组的头实体计算距离
d
(
h
′
+
l
,
t
)
d(h'+l,t)
d(h′+l,t),将结果按升序排序,用正确三元组的排名情况来评估学习效果(同理对尾实体这样做)。度量标准选择hits@10和mean rank,前者代表命中前10的次数/总查询次数,后者代表正确结果排名之和/总查询次数。
还有一点值得一提,文中给了两种测试结果raw和filter,其动机是我们在测试时通过替换得到的三元组并不一定就是负例,可能恰巧替换对了(比如(奥巴马,总统,美国)被替换成了(特朗普,总统,美国)),那么它排名高也是正确的,把当前三元组挤下去也正常。(存疑:这样的话训练时是否也应当过滤corrupted triplet呢) 所以测试时在替换后要检查一下新三元组是否出现在训练集中,是的话就删掉,这就是filter训练方法(不检查的是raw)。
2 transE算法的简单python实现
为了更好地理解(其实是因为看不懂别人的),用python简单实现了transE算法,使用数据集FB15k。这里记录一些细节和几个小坑。完整代码见github。
1. 训练transE
- Tbatch更新:在update_embeddings函数中有一个deepcopy操作,目的就是为了批量更新。这是ML中mini-batch SGD的一个通用的训练知识,在实际编码时很容易忽略。
- 两次更新:update_embeddings函数中,要对correct triplet和corrupted triplet都进行更新。虽然写作 ( h , l , t ) (h,l,t) (h,l,t)和 ( h ′ , l , t ′ ) (h',l,t') (h′,l,t′),但两个三元组只有一个entity不同(前面说了,不同时替换头尾实体),所以在每步更新时重叠的实体要更新两次(和更新relation一样),否则就会导致后一次更新覆盖前一次。
- 关于L1范数的求导方法:先对L2范数求导,逐元素判断正负,为正赋值为1,负则为-1。
- 超参选择:对FB15k数据集,epoch选了1000(其实不需要这么大,后面就没什么提高了),nbatches选了400(训练最快),embedding_dim=50, learning_rate=0.01, margin=1。
2. 测试
- isFit参数:区分raw和filter。filter会非常慢。
3 transE算法的局限性
transE效果很好且非常简单,后续大量的工作都是在此基础上的改进(简称trans大礼包),传统方法已经基本不用了(有些思想还是值得借鉴的,比如矩阵分解、双线性模型)。改进大体针对以下几个问题:
- 复杂关系建模效果差。对1-N,N-1,N-N关系,会出现冲突映射,一个实体在不同三元组内的表示融合,导致不明确甚至错误的语义信息。
- 多源信息融合。 如何充分利用知识库中的额外信息(如实体类型、实体描述)。
- 关系路径建模。 对relation之间的依赖进行建模。
理解或实现有错误欢迎指出!
参考文献:
[1] Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[C]//Advances in neural information processing systems. 2013: 2787-2795.
[2] 刘知远, 孙茂松, 林衍凯, et al. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2):247-261.















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









