






项目介绍
Apache Hudi(发音为 Hoodie)代表Hadoop Upserts Deletes and Incrementals. Hudi 管理 DFS(云存储、HDFS 或任何与 Hadoop 文件系统兼容的存储)上的大型分析数据集的存储。
产品介绍
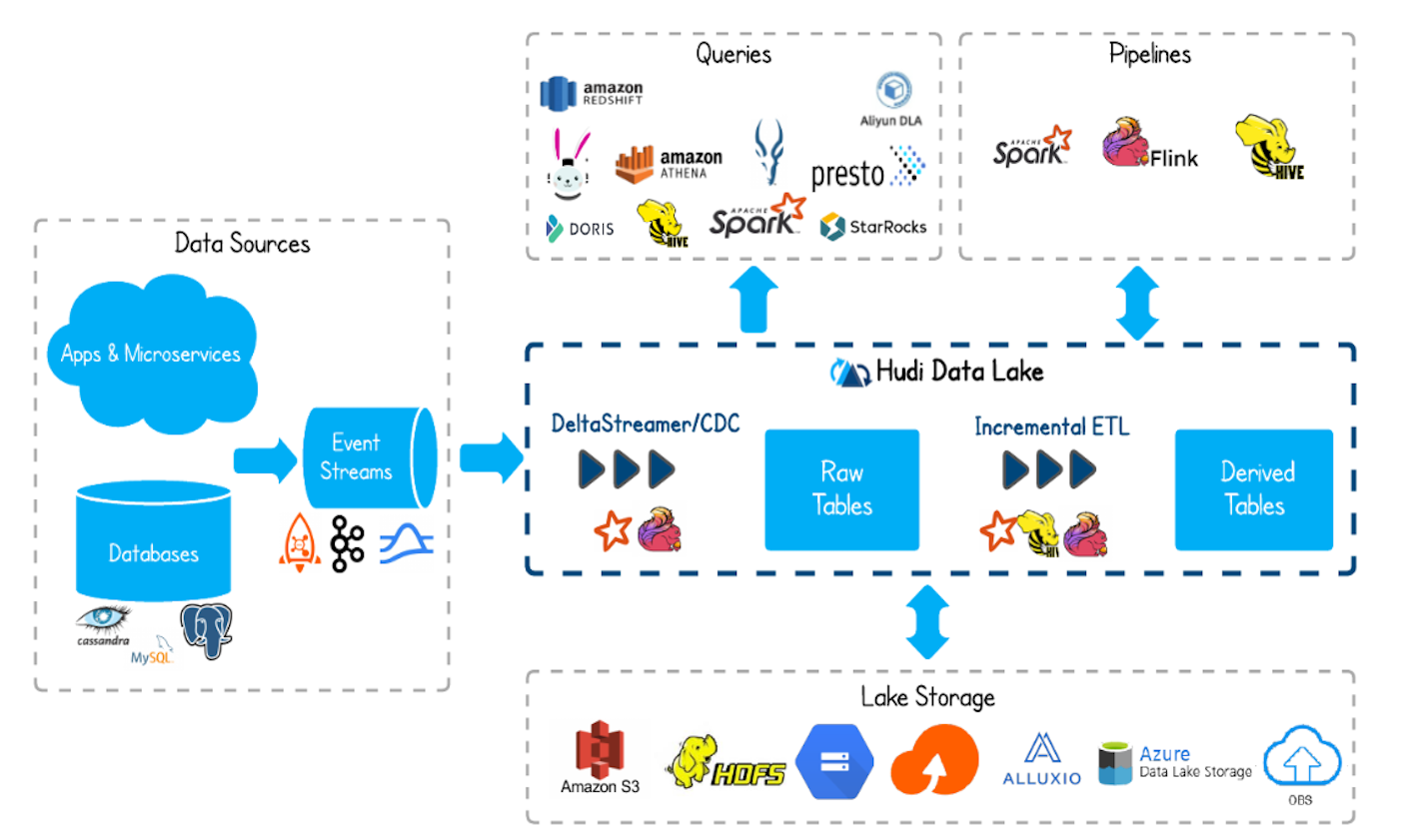
特征
- 通过快速、可插入的索引支持 Upsert
- 支持回滚以原子方式发布数据
- 编写器和查询之间的快照隔离
- 数据恢复的保存点
- 使用统计信息管理文件大小、布局
- 行和列数据的异步压缩
- 用于跟踪血统的时间线元数据
- 通过集群优化数据湖布局
Hudi 支持三种类型的查询:
- 快照查询- 使用基于列和行的存储(例如Parquet + Avro)的组合,提供对实时数据的快照查询。
- 增量查询- 提供一个更改流,其中包含在某个时间点之后插入或更新的记录。
- 读取优化查询- 通过纯列存储(例如Parquet )提供出色的快照查询性能。
在https://hudi.apache.org了解有关 Hudi 的更多信息
从源代码构建 Apache Hudi
构建 Apache Hudi 的先决条件:
- 类 Unix 系统(如 Linux、Mac OS X)
- Java 8(Java 9 或 10 可能工作)
- 吉特
- Maven (>=3.3.1)
# Checkout code and build
git clone https://github.com/apache/hudi.git && cd hudi
mvn clean package -DskipTests
# Start command
spark-2.4.4-bin-hadoop2.7/bin/spark-shell \
--jars `ls packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-*.*.*-SNAPSHOT.jar` \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'要构建包含 的集成测试hudi-integ-test-bundle,请使用-Dintegration-tests.
为所有 Java 和 Scala 类构建 Javadoc:
# Javadoc generated under target/site/apidocs
mvn clean javadoc:aggregate -Pjavadocs使用不同的 Spark 版本构建
支持的默认 Spark 2.x 版本是 2.4.4。默认的 Spark 3.x 版本,对应的spark3profile 是 3.3.0。有关使用不同 Spark 和 Scala 版本进行构建的信息,请参阅下表。
| Maven 构建选项 | 预期的 Spark 包 jar 名称 | 笔记 |
|---|---|---|
| (空的) | hudi-spark-bundle_2.11(旧包名称) | 对于 Spark 2.4.4 和 Scala 2.11(默认选项) |
-Dspark2.4 | hudi-spark2.4-bundle_2.11 | 对于 Spark 2.4.4 和 Scala 2.11(与默认相同) |
-Dspark2.4 -Dscala-2.12 | hudi-spark2.4-bundle_2.12 | 对于 Spark 2.4.4 和 Scala 2.12 |
-Dspark3.1 -Dscala-2.12 | hudi-spark3.1-bundle_2.12 | 对于 Spark 3.1.x 和 Scala 2.12 |
-Dspark3.2 -Dscala-2.12 | hudi-spark3.2-bundle_2.12 | 对于 Spark 3.2.x 和 Scala 2.12 |
-Dspark3.3 -Dscala-2.12 | hudi-spark3.3-bundle_2.12 | 对于 Spark 3.3.x 和 Scala 2.12 |
-Dspark3 | hudi-spark3-bundle_2.12(旧捆绑包名称) | 对于 Spark 3.3.0 和 Scala 2.12 |
-Dscala-2.12 | hudi-spark-bundle_2.12(旧包名称) | 对于 Spark 2.4.4 和 Scala 2.12 |
例如,
# Build against Spark 3.2.x
mvn clean package -DskipTests -Dspark3.2 -Dscala-2.12
# Build against Spark 3.1.x
mvn clean package -DskipTests -Dspark3.1 -Dscala-2.12
# Build against Spark 2.4.4 and Scala 2.12
mvn clean package -DskipTests -Dspark2.4 -Dscala-2.12那么“spark-avro”模块呢?
从 0.11 版本开始,不再需要spark-avro使用指定Hudi--packages
使用不同的 Flink 版本构建
支持的默认 Flink 版本是 1.14。有关使用不同 Flink 和 Scala 版本进行构建的信息,请参阅下表。
| Maven 构建选项 | 预期的 Flink 包 jar 名称 | 笔记 |
|---|---|---|
| (空的) | hudi-flink1.14-bundle_2.11 | 对于 Flink 1.14 和 Scala 2.11(默认选项) |
-Dflink1.14 | hudi-flink1.14-bundle_2.11 | 对于 Flink 1.14 和 Scala 2.11(与默认相同) |
-Dflink1.14 -Dscala-2.12 | hudi-flink1.14-bundle_2.12 | 对于 Flink 1.14 和 Scala 2.12 |
-Dflink1.13 | hudi-flink1.13-bundle_2.11 | 对于 Flink 1.13 和 Scala 2.11 |
-Dflink1.13 -Dscala-2.12 | hudi-flink1.13-bundle_2.12 | 对于 Flink 1.13 和 Scala 2.12 |
运行测试
单元测试可以使用 maven profile 运行unit-tests。
mvn -Punit-tests test带有 标记的功能测试@Tag("functional")可以使用 maven profile 运行functional-tests。
mvn -Pfunctional-tests test要在启用 spark 事件日志记录的情况下运行测试,请定义 Spark 事件日志目录。这允许使用 Spark History Server UI 可视化测试 DAG 和阶段。
mvn -Punit-tests test -DSPARK_EVLOG_DIR=/path/for/spark/event/log快速开始
请访问https://hudi.apache.org/docs/quick-start-guide.html以使用 spark-shell 快速探索 Hudi 的功能。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









