









前言
因为部分工作的需要(不涉及后端开发)
需要在windows下使用python调用pysaprk的库。
需要安装单机版的Hadoop和spark
所以写下一个记录。
hadoop 3.2.1
spark 3.1.1
默认电脑已经安装JAVA1.8和python3.6以上。
(没有安装的搜一下,网上搜一下即可)

下载地址
去官网下载:
hadoop:https://hadoop.apache.org/releases.html
spark:https://spark.apache.org/downloads.html
下载最新版(当前最新版本hadoop-3.2.1和spark-3.1.1-bin-hadoop3.2)
hadoop-3.2.1.tar.gz
spark-3.1.1-bin-hadoop3.2.tgz
下载完成后解压。
我个人直接在D盘创建一个文件夹,放置Hadoop生态
电脑路径是这样的
D:\Hadoop\hadoop-3.2.1
D:\Hadoop\spark-3.1.1-bin-hadoop3.2

添加环境变量
添加系统变量



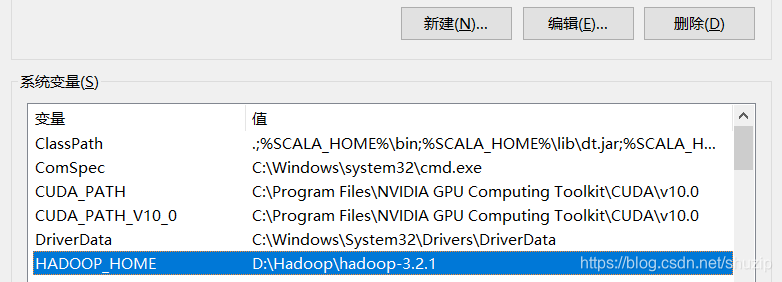
添加path
%HADOOP_HOME%\bin
%SPARK_HOME%\bin


查看是否安装成功
cmd命令行输入
hadoop -version
显示

hadoop安装成功
输入
spark-shell

spark 安装成功
(如果不涉及后端开发,不需要用到hdfs,可以不用像其他教程里一样修改xml那些文件
如果涉及后端开发,请参考其他hadoop安装教程)
Windows下有个小坑
普通的PC如果没有调整过管理员权限的话。
在hadoop解压时,需要使用管理员权限解压,否则提示解压文件不完整。
但spark使用管路员权限解压,则会出问题:添加环境变量后,命令行会无法找到。
解压spark时,不要使用管理员权限解压。
Python调用pyspark
安装寻找spark的库findspark
pip install findspark
word count示例
import findspark
findspark.init()
from pyspark import SparkConf, SparkContext
# 创建SparkConf和SparkContext
conf = SparkConf().setMaster("local").setAppName("lichao-wordcount")
sc = SparkContext()
data=["hello","world","hello","word","count","count","hello"]
rdd=sc.parallelize(data)
resultRdd = rdd.map(lambda word: (word,1)).reduceByKey(lambda a,b:a+b)
# rdd转为collecton并打印
resultColl = resultRdd.collect()
for line in resultColl:
print(line)
# 结束
sc.stop()
输出结果:
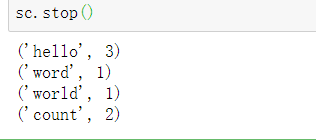
完成~















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









