






前置环境
见上一篇:https://blog.csdn.net/shuzip/article/details/115606522
官方示例
https://spark.apache.org/docs/3.1.1/quick-start.html
/* SimpleApp.java */
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "YOUR_SPARK_HOME/README.md"; // Should be some file on your system
SparkSession spark = SparkSession.builder().appName("Simple Application").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
long numAs = logData.filter(s -> s.contains("a")).count();
long numBs = logData.filter(s -> s.contains("b")).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
spark.stop();
}
}
三个小坑
maven文件
官方示例里 scope指定为provided
<project>
<groupId>edu.berkeley</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.1</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
但是如果想在本地执行调试的话,scope需要改为compile
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.shuzip</groupId>
<artifactId>simple-project</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.1</version>
<scope>compile</scope>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
引用不明确
把pox文件修改完后,再把代码里的文件地址替换后成个人路径后,在个人的Windows上跑这个示例,会发现报错
java: 对filter的引用不明确

所以需要修改一下代码
long numAS = logData.filter((FilterFunction<String>) s -> s.contains("a")).count();
long numBs = logData.filter((FilterFunction<String>) s -> s.contains("b")).count();
未传递master url
基于上面的修改,再执行,会发现,还有个小问题没解决
ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
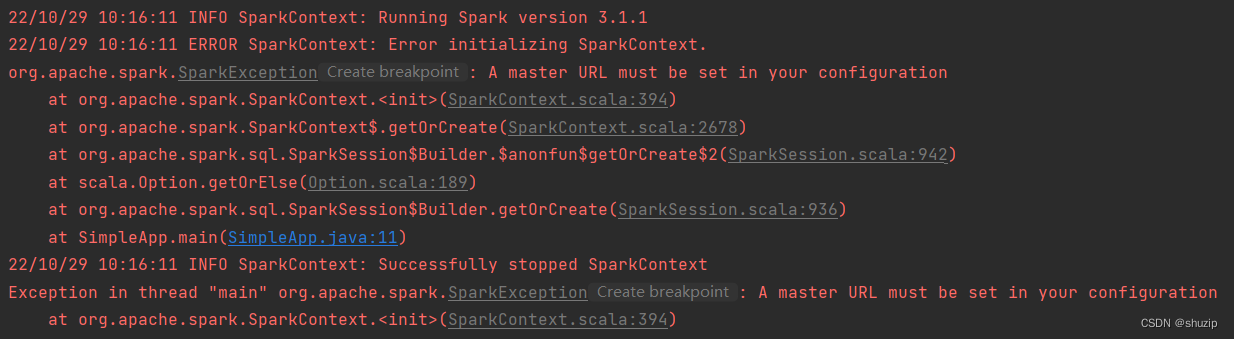
需要在spark初始化前,设置一下
System.setProperty("spark.master", "local");
最后能顺利执行的完整代码
/*SimpleApp.java */
import org.apache.spark.api.java.function.FilterFunction;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
public class SimpleApp{
public static void main(String[] args) {
System.setProperty("spark.master", "local");//设置指定本地启动
String logFile = "D:\\JAVA_project\\simple-project\\src\\main\\resources\\README.md";
SparkSession spark = SparkSession.builder().appName("SimpleAppliaction").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
long numAS = logData.filter((FilterFunction<String>) s -> s.contains("a")).count();
long numBs = logData.filter((FilterFunction<String>) s -> s.contains("b")).count();
System.out.println("Lines with a: " + numAS + ", lines with b: " + numBs);
spark.stop();
}
}
执行成功
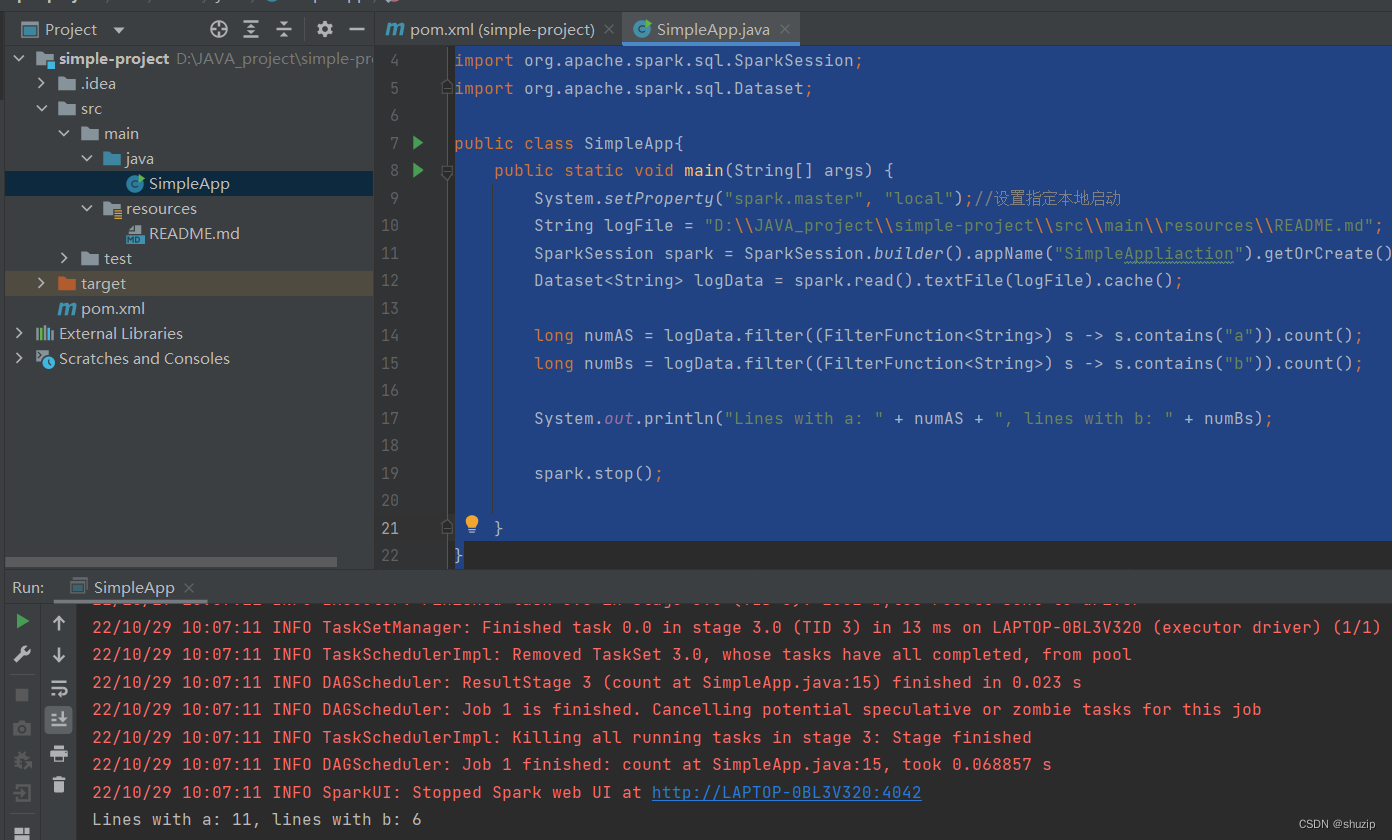
顺利执行打印统计,接下来就可以顺利的在官方文档里畅游学习了~














 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









