






Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular, Stereo, and RGB-D Cameras
参考:Photo-Slam
摘要
同时利用显式几何特征进行定位,并学习隐式光度特征来表示观测环境的纹理信息。
除了基于几何特征主动致密化超基元外,我们还进一步引入了基于高斯金字塔的训练方法,以逐步学习多级特征,从而提高逼真的映射性能。
论文的主要贡献包括:
- 开发了第一个基于“超原语地图”的同步定位和逼真地图构建系统,该新框架支持在室内和室外环境中使用单目、立体和RGB-D摄像头。
- 提出了基于高斯金字塔的学习方法,使模型能够高效、有效地学习多级特征,实现高保真的地图构建。
- 该系统完全用C++和CUDA实现,性能达到了行业领先水平,并能在嵌入式平台上实时运行。
相关
-
图解求解器 vs 神经网络求解器:传统的SLAM方法通常采用因子图来建模变量(如姿态和地标)与测量(如观测和约束)之间的复杂优化问题。这些方法通过增量更新姿态估计,避免昂贵的计算操作。深度学习模型的成功也使可学习的参数和模型被引入SLAM,使整个流程可微分。一些方法通过神经网络端到端预测相机姿态,但精度有限。为提高性能,部分方法引入单目深度估计或稠密光流估计模型作为监督信号。然而,纯粹基于神经网络的求解器计算开销大,在未见过的场景中性能会显著下降。
-
显式表示 vs 隐式表示:为了获得稠密重建,一些方法使用截断符号距离函数(TSDF)来集成RGB-D图像并重建连续表面,这可以在GPU上实时运行。尽管这些方法能够实现稠密重建,但渲染质量有限。近年来,以神经辐射场(NeRF)为代表的神经渲染技术在新视图合成方面取得了惊人的成果。然而,隐式联合优化相机姿态和几何表示仍然面临条件差的问题,通常依赖于RGB-D相机的显式深度信息或额外的模型预测以加快辐射场的收敛。
-
Photo-SLAM 的创新:Photo-SLAM旨在恢复一个简洁的环境表示,支持沉浸式探索,而不是重建稠密网格。它在线维护一个超原语地图,利用显式几何特征点实现准确高效的定位,同时利用隐式表示捕捉和建模纹理信息。Photo-SLAM实现了高质量的映射,而无需依赖稠密深度信息,支持RGB-D相机、单目相机和立体相机。
流程
1. 输入图像
Photo-SLAM接收来自单目、立体或RGB-D摄像头的图像流,作为系统的输入数据。
2. 特征提取和初始化
- ORB特征提取:从每帧图像中提取ORB特征,这些特征用于在帧间进行特征匹配,以帮助后续的姿态估计。
- 初始化超原语地图:在图像中检测到足够的特征点之后,利用三角测量初始化3D超原语点云,形成初始的超原语地图。每个超原语包括位置、ORB特征、密度、球谐系数等信息。
3. 并行线程:定位、几何映射和光度映射
Photo-SLAM的核心算法被分成多个并行线程,各自负责不同的任务:
3.1 定位线程
- 2D-3D匹配:基于ORB特征进行2D-3D匹配,将当前图像的2D特征点与超原语地图中的3D点进行关联。
- 姿态估计:使用Levenberg-Marquardt算法进行运动束调整,优化相机的6自由度位姿(位置和方向),即计算相机的旋转和平移矩阵。
- 局部优化:通过局部束调整进一步优化姿态,以降低累积误差。
3.2 几何映射线程
- 超原语更新:根据相机的新视角,逐步在超原语地图中添加新的几何特征点,形成稀疏的3D点云。
- 几何密度化:通过密集化策略(例如基于几何的密度化方法),增加超原语地图中的点数,以更详细地描述场景中的复杂区域。
3.3 光度映射线程
- 球谐系数优化:根据当前帧的颜色信息,优化超原语的球谐系数,以更准确地表示光照效果。
- 基于高斯金字塔的学习:在光度映射中,使用高斯金字塔逐层学习特征,逐渐提高地图的细节层次和渲染质量。
- 渲染损失优化:通过计算渲染图像和真实图像之间的光度损失(如L1损失和结构相似性SSIM),不断优化超原语的密度、位置和颜色信息,使得渲染效果更真实。
4. 闭环检测和修正
- 闭环检测:通过特征点的相似性检测是否回到先前已经探索过的区域。闭环检测能够纠正长期累积的误差(如漂移)。
- 相机姿态和超原语地图修正:当检测到闭环后,通过相似性变换对姿态和超原语地图进行全局优化,减少定位和映射的累积误差。
5. 输出实时定位和逼真地图
- 实时渲染:系统基于优化后的超原语地图,通过3D高斯模糊渲染出当前视角下的逼真图像。
- 定位信息:系统输出实时的相机位姿,以支持机器人或其他设备的导航需求。
概念解释
1. 超原语地图 (Hyper Primitives Map)
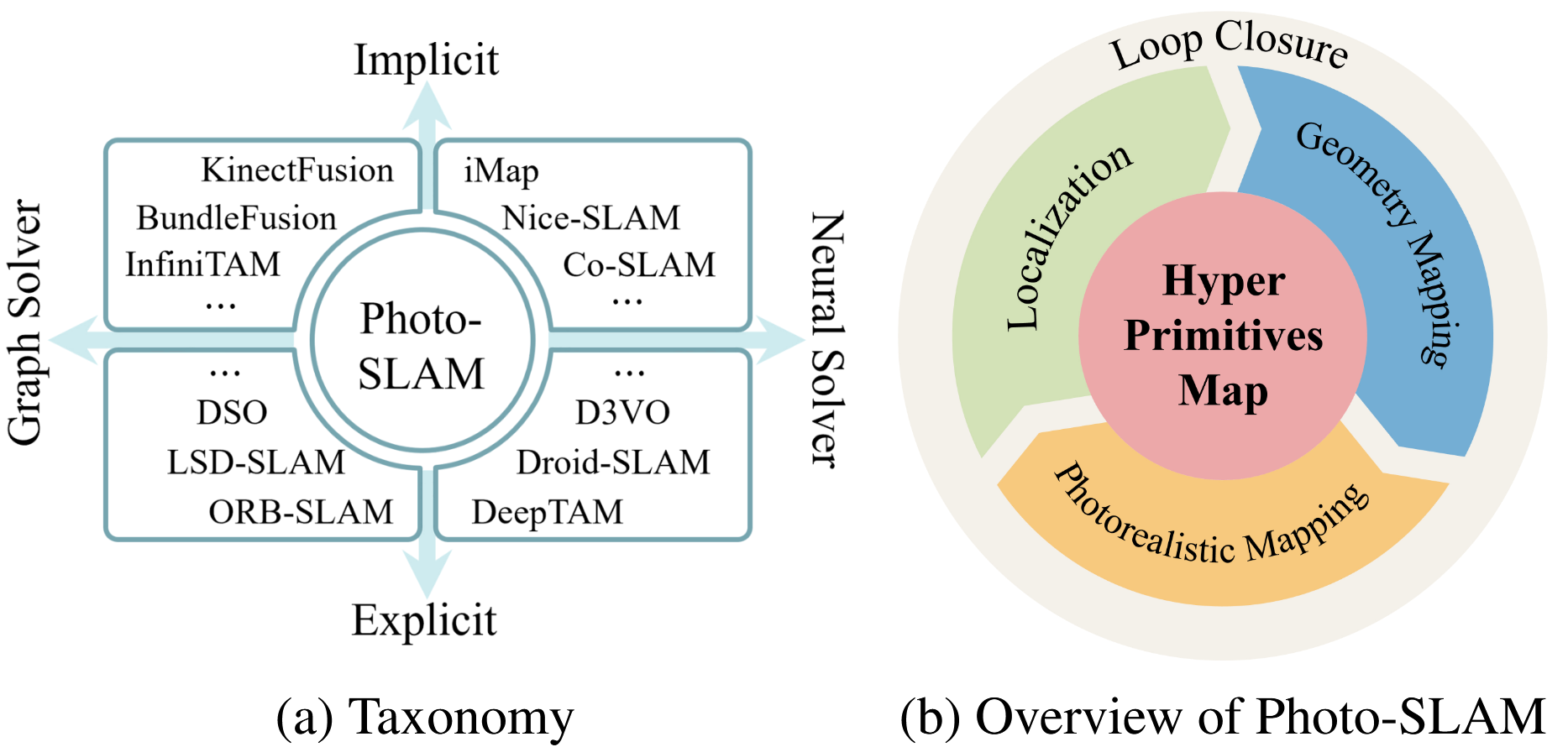
-
定义:超原语是一组包含3D点云、ORB特征、旋转、缩放、密度和球谐系数的集合。具体来说,3D点云表示空间中的位置,ORB特征用于图像的2D到3D匹配,旋转和缩放描述物体的姿态,密度表示点云的稠密程度,而球谐系数则用于捕捉光照和纹理信息。
-
初始化:当系统通过相邻帧之间的2D到2D特征点匹配,成功估计出转化矩阵后,超原语地图通过三角测量被初始化。这意味着地图的基础结构开始形成,并且系统开始追踪相机的姿态。
-
追踪与更新:在定位过程中,系统使用2D到3D的对应关系持续计算当前相机的姿态,同时几何映射组件逐步创建并初始化稀疏的超原语,逐步丰富地图。
Hyper Primitives: are defined as a set of point clouds associated with
- Position P∈ R3
- ORB feature O ∈ R256
ORB特征,即BRIEF描述符,是一个256位的字符串,每一位是0或者1,0与1表示该像素与周围像素大小的比较结果(确定特征点,如边缘和角点)。
- Rotation r ∈ SO(3)
旋转: 三维空间中的特殊正交群,也就是所有能够描述三维空间旋转的正交矩阵集合
- Scaling s∈ R3
尺度因子,表示x, y, z三个方向上的缩放比例
- Density δ∈ R1
密度,或者不透明度
- Spherical harmonic coefficients SH ∈ R16
球谐系数
2. 定位与几何映射 (Localization and Geometry Mapping)

-
定位:
- 目的:定位线程的主要任务是提供输入图像的六自由度(6-DoF)相机姿态估计。通过运动束调整(motion-only bundle adjustment,BA),系统优化相机的旋转矩阵 ® 和位移向量 (t),以最小化2D几何关键点与其对应的3D点之间的重投影误差。

-
公式:
-
其中,Σg是与尺度相关的协方差矩阵,π(·)是3D到2D的投影函数,ρ是鲁棒的Huber损失函数。
-
几何映射:
-
目的:几何映射线程通过局部束调整优化一组共视的3D点和关键帧。关键帧从相机序列中选取,提供良好的视觉信息,构成因子图的节点,边则表示关键帧与匹配的3D点之间的约束。
-
优化过程:几何映射通过迭代最小化重投影残差,逐步优化关键帧的姿态和3D点。具体的残差计算为:

-
系统会固定那些同时观测到该3D点但不在优化集合KL中的关键帧的姿态,以减少几何不一致性。
3. 写实映射 (Photorealistic Mapping)
-
功能:写实映射线程负责优化由几何映射线程逐步创建的超原语。通过基于平铺的渲染器将超原语光栅化,以生成与关键帧姿态对应的图像。
-
渲染与优化:渲染公式为

其中,N表示超原语的数量,ci表示从球谐系数转换的颜色,αi表示密度σi与3D高斯分布G(R, t, Pi, ri, si)的乘积。优化通过最小化渲染图像Ir与真实图像Igt之间的光度损失L来进行:

其中,SSIM(Ir, Igt)表示两幅图像之间的结构相似性,λ是平衡因子。
- 基于几何的稠密化(Geometry-based Densification):为了达到实时映射的需求,几何映射组件只创建稀疏的超原语。在写实映射过程中,需要对这些粗略的超原语进行稠密化,以更好地建模场景的复杂性。除了基于损失梯度对超原语进行拆分或克隆外,还引入了一种几何基础的稠密化策略,通过创建临时超原语来增强写实映射的效果。

概念:
几何基础的稠密化是为了在不影响实时性的情况下,通过增加超原语的密度来提高场景的表示能力。稠密化的目的是让系统能够更好地捕捉到复杂场景中的细节,尤其是在高复杂度纹理区域。
实现步骤:
识别稀疏超原语:
- 初始的几何映射组件会生成稀疏的超原语,这些超原语仅代表场景中部分区域的几何信息。系统会监测这些区域的重投影误差,并识别出需要进一步稠密化的部分。
创建临时超原语:
- 对于那些在初始映射过程中未被激活的2D几何特征点(即没有对应的3D点),系统会在关键帧创建时主动生成临时超原语。
- 在RGB-D相机的场景中,可以直接通过深度信息将这些2D特征点投影到3D空间中,生成新的超原语。
- 在单目相机的场景中,系统会估算这些特征点的深度,通常使用其邻近的已知深度的特征点来推断。
- 在双目相机的场景中,使用立体匹配算法估算这些特征点的深度,进而生成超原语。
优化稠密化后的超原语:
- 对于创建的临时超原语,系统会在后续的写实映射过程中,通过最小化光度损失等方式进行优化。这些临时超原语会逐步被集成到整个超原语地图中,以提高最终的映射质量。
- 在高损失梯度的区域,系统还可以通过分裂或克隆现有超原语来进一步增加稠密度。
几何基础的稠密化的核心在于,通过主动创建更多的超原语,尤其是在复杂纹理区域,系统可以更细致地表示场景,最终提高渲染质量和映射精度。
4. 基于高斯金字塔的学习 (Gaussian-Pyramid-Based Learning)

概念:
高斯金字塔是一种用于多尺度图像处理的技术,它通过反复应用高斯平滑和下采样操作,将一张图像逐步变为不同分辨率的版本,形成一个金字塔结构。在Photo-SLAM中,高斯金字塔被用于逐步优化模型,使得系统能够从粗略到精细地进行训练。
实现步骤:
-
构建高斯金字塔:
-
对每张输入图像进行高斯平滑,然后下采样,生成多个不同分辨率的图像(例如,从原始分辨率到逐渐降低的分辨率)。这个过程会产生一个由高到低分辨率图像组成的金字塔。
-
逐步训练:
-
训练从最高层级(即最低分辨率)的图像开始。在这个阶段,模型只需要处理图像的全局信息,因此优化过程相对简单且快速。
-
随着训练的进行,逐步将金字塔中的低层级图像(即更高分辨率的图像)引入训练过程。每次引入新的图像分辨率时,使用前一层训练好的模型参数作为初始化,这样可以加速收敛。
-
最终,训练到原始分辨率图像上,确保模型能够捕捉到细节信息。
-
优化目标:
-
在每个分辨率层次,使用损失函数(例如光度损失L)来优化模型参数,使得渲染图像(Ir)与对应分辨率的真实图像(GP(Igt))之间的差异最小。
-
每次层次下降后,重新调整损失函数以适应更高分辨率的细节,这样可以让模型逐步学习到从粗糙到精细的细节信息。
这种渐进式训练方法的优点在于,模型可以逐层掌握图像的全局和局部信息,从而更有效地进行优化。
基于高斯金字塔的学习和几何基础的稠密化策略都是为了逐步优化和细化SLAM系统的场景表示能力。前者侧重于多尺度的逐步训练,从粗到精进行优化;后者则通过在关键区域增加几何超原语的密度,使得系统能够更好地处理复杂的场景细节。两者结合,确保了Photo-SLAM系统既能高效地训练,又能在高复杂度的场景中保持较高的精度。
5. 回环检测 (Loop Closure)
- 重要性:回环检测在SLAM系统中至关重要,因为它可以修正累积的误差和漂移。当系统检测到回环时,可以通过相似变换来校正局部关键帧和超原语,从而消除由于里程计漂移导致的图像重影,进一步提高映射质量。通过回环检测,Photo-SLAM能够更好地处理长时间运行中的累积误差问题,确保系统的长期稳定性和准确性。
总结
整个Photo-SLAM流程包括以下步骤:图像输入→特征提取与初始化→并行执行定位、几何映射和光度映射→闭环检测和修正→输出实时定位和逼真地图。系统的多线程结构和基于超原语的表示方式,帮助实现了高效、精准的SLAM效果,并在嵌入式设备上实现实时性能。

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









