







Token Transformation Matters: Towards Faithful Post-hoc Explanation for Vision Transformer

Transformer 在计算机视觉应用中表现出色,但其后验解释方法存在不足。现有方法仅关注注意力权重,忽略了 token 变换的影响,导致无法准确解释模型预测。本文 “Token Transformation Matters: Towards Faithful Post-hoc Explanation for Vision Transformer” 提出 TokenTM 这一新颖的后验解释方法,通过测量 token 变换效应(考虑长度和方向变化),并结合注意力权重,建立聚合框架整合多层信息,以获得更忠实的解释。实验结果表明,TokenTM 在定位能力、对模型精度的影响及对预测概率的捕捉方面均优于现有方法,且各组件和更深层次的聚合对提升性能有重要作用。
摘要-Abstract
While Transformers have rapidly gained popularity in various computer vision applications, post-hoc explanations of their internal mechanisms remain largely unexplored. Vision Transformers extract visual information by representing image regions as transformed tokens and integrating them via attention weights. However, existing post-hoc explanation methods merely consider these attention weights, neglecting crucial information from the transformed tokens, which fails to accurately illustrate the rationales behind the models’ predictions. To incorporate the influence of token transformation into interpretation, we propose TokenTM, a novel post-hoc explanation method that utilizes our introduced measurement of token transformation effects. Specifically, we quantify token transformation effects by measuring changes in token lengths and correlations in their directions pre- and post-transformation. Moreover, we develop initialization and aggregation rules to integrate both attention weights and token transformation effects across all layers, capturing holistic token contributions throughout the model. Experimental results on segmentation and perturbation tests demonstrate the superiority of our proposed TokenTM compared to state-of-theart Vision Transformer explanation methods.
虽然 Transformer 在各种计算机视觉应用中迅速普及,但其内部机制的后验解释在很大程度上仍未得到充分探索。视觉 Transformer 通过将图像区域表示为经过变换的 token,并借助注意力权重对它们进行整合,以此来提取视觉信息。然而,现有的后验解释方法仅仅考虑了这些注意力权重,却忽略了来自变换后 token 的关键信息,这使得它们无法准确阐释模型预测背后的原理。
为了将 token 变换的影响纳入解释中,我们提出了 TokenTM,这是一种全新的后验解释方法,它利用了我们所引入的对 token 变换效应的度量方式。具体而言,我们通过测量 token 变换前后的长度变化以及方向相关性,来量化 token 的变换效应。此外,我们制定了初始化和聚合规则,以整合所有层的注意力权重和 token 变换效应,从而捕捉整个模型中 token 的整体贡献。在分割和扰动测试上的实验结果表明,与最先进的视觉 Transformer 解释方法相比,我们提出的 TokenTM 具有优越性。
引言-Introduction
这部分主要阐述了研究的背景和意义,指出视觉 Transformer 缺乏可解释性,现有后验解释方法存在不足,进而提出 TokenTM 方法,具体内容如下:
- 研究背景:Transformer 模型在计算机视觉领域取得优异成果,但其内在复杂性导致缺乏可解释性,影响决策信任度,因此需要对其进行解释。后验解释方法通过在输入像素空间生成热图来阐释模型预测,具有有效性和高效性,分为传统方法和基于注意力的方法。
- 现有方法的问题:传统解释方法在处理视觉 Transformer 时,因模型架构差异,效果明显下降。基于注意力的解释方法虽设计了针对 Transformer 的范式,但由于模型中多头自注意力(MHSA)和前馈网络(FFN)的复杂性,仍面临可解释性挑战。这些方法仅考虑注意力权重,忽略了token变换的影响,可能导致对模型预测原理的误解。
- TokenTM方法的提出:提出 TokenTM 这一新颖的后验解释方法。该方法从通用视角重新审视视觉 Transformer 层,将 MHSA 和 FFN 的输出视为原始和变换 token 的加权线性组合。通过引入一种关注 token 长度和方向这两个基本属性的测量方法来量化变换效应,并将其与注意力信息相结合。同时,考虑到视觉 Transformer 层的堆叠特性,构建了一个聚合框架,通过严格的初始化和更新规则,生成全面的贡献图,以揭示 token 在整个模型中的贡献。实验证明,TokenTM 在分割和扰动测试中优于现有方法。
- 研究贡献:一是探索了视觉 Transformer 的后验解释,指出当前存在的主要问题是对 token 变换和注意力权重缺乏综合考虑;二是提出 TokenTM 方法,通过测量 token 变换效应(考虑长度和方向变化),更准确地评估其对 token 贡献的影响;三是建立聚合框架,整合多层注意力和 token 变换效应,捕捉视觉 Transformer 的累积特性;四是实验表明 TokenTM 相比现有方法性能更优。
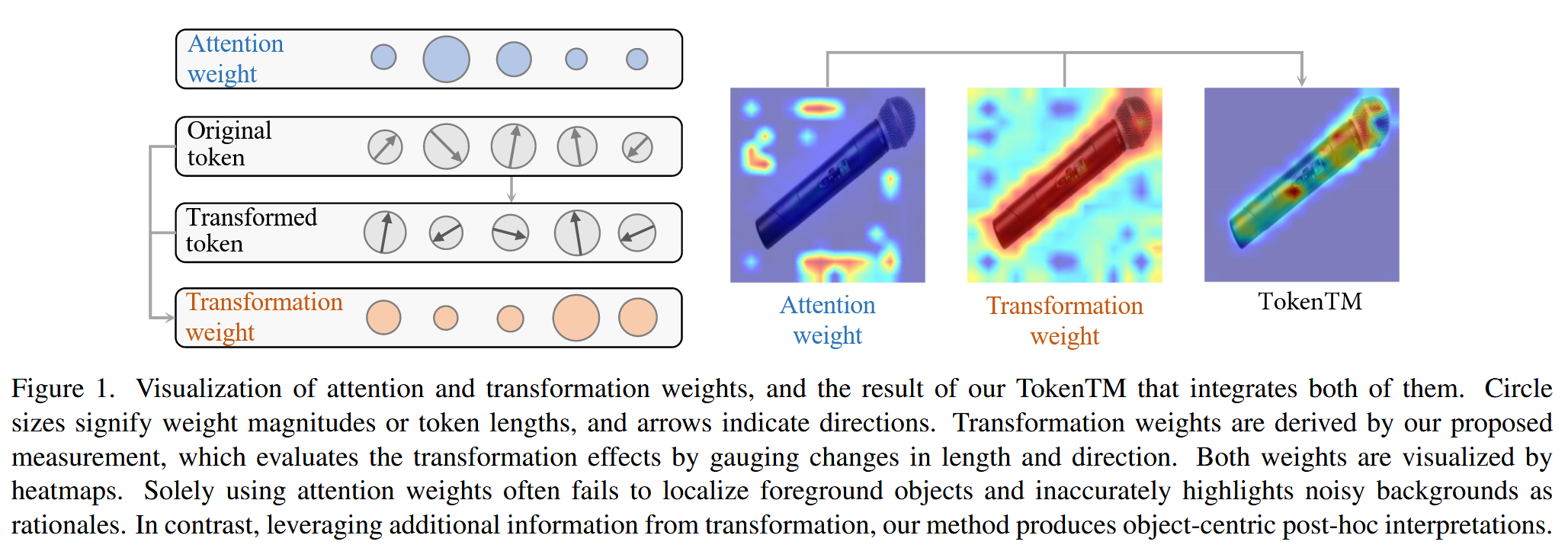
图1. 注意力权重和变换权重的可视化,以及我们整合二者的 TokenTM 方法的结果。圆圈大小表示权重大小或 token 长度,箭头表示方向。变换权重由我们提出的测量方法得出,该方法通过衡量长度和方向的变化来评估变换效果。这两种权重均通过热图进行可视化。仅使用注意力权重往往无法定位前景物体,还会错误地将嘈杂的背景突出显示为模型决策的依据。相比之下,我们的方法利用变换带来的额外信息,能够生成以物体为中心的后验解释。
相关工作-Related Work
该部分主要介绍了与视觉 Transformer 后验解释相关的两类工作,分别指出它们在解释视觉 Transformer 时存在的不足,具体内容如下:
- 通用传统解释方法:传统的后验解释方法主要分为基于梯度和基于归因两类。基于梯度的方法如 Gradient*Input、SmoothGrad 等利用梯度生成显著性图;基于归因的方法基于深度泰勒分解,将分类分数反向传播到输入。此外还有基于显著性、Shapley可加解释(SHAP)和基于扰动的方法等。虽然部分传统方法已被适配用于 Transformer,但由于缺乏对注意力权重的考量,在视觉 Transformer 上仍难以取得理想效果。
- 特定于 Transformer 的基于注意力的解释方法:这一系列工作专为 Transformer 设计新的解释范式,广泛使用注意力图,因为其本质上是 token 缩放权重的分布。代表性方法包括将注意力直接视为解释的 Raw Attention、线性累积注意力图的 Rollout、针对 Transformer 变体的框架 GAE、通过制定注意力类激活 token 来估计重要性的 ATTCAT,以及提出使用注意力进行路径积分的 IIA 和 DIX 等。然而,这些方法忽视了 token 变换的相对效应,无法在所有模块中准确聚合 token 的贡献,从而阻碍了对视觉 Transformer 进行可靠的后验解释 。
分析-Analysis
这部分内容从通用视角重新诠释了 Transformer 层,并分析了视觉 Transformer 在解释方面存在的问题,具体如下:
- 重新审视 Transformer 层:从通用观点出发,MHSA 和 FFN 都处理原始和变换后的 token 的加权线性组合。对于 MHSA,输入序列的每个 token 通过将嵌入投影到查询(query)、键(key)和值(value)来关注其他所有 token,计算注意力图 A 后对值 V 进行情境化,再通过线性变换和多头整合得到最终输出。通过重新表述,可将 MHSA 的输出视为原始嵌入与变换后嵌入的加权和。FFN 则是一种特殊的“情境化”形式,其中头数 n H = 1 n_{H}=1 nH=1,注意力图 A A A 为单位矩阵,其输出同样可表示为原始和变换后 token 的加权和。
- 解释视觉 Transformer 的问题:视觉 Transformer 层通常表示为原始和变换后 token 的加权和,每个 token 都乘以一个缩放权重。现有的基于注意力的解释方法通常将这些缩放权重视为相应 token 的贡献,但这种方式忽略了 token 本身所带来的影响。仅依靠注意力权重可能会错误地表示来自不同图像块的贡献,因此需要一种更全面的方法来准确解释 Transformer 层的内部机制,并捕捉模型预测背后的真正原理。
提出的方法-The Proposed Method
基于注意力的解释-Attention-based Explanations
这部分内容介绍了基于注意力的视觉 Transformer 解释方法,分析了其原理和局限性,具体内容如下:
- 方法原理:基于注意力的解释方法通过注意力信息衡量每个 token 的贡献,其计算贡献图的公式为 C = O + E h [ ( ∇ A p ( c ) ) + ⊙ T ] C = O + \mathbb{E}_{h}[(\nabla_{A}p(c))^{+} \odot T] C=O+Eh[(∇Ap(c))+⊙T],其中 C C C 是贡献图, C i j C_{ij} Cij 表示第 j j j 个输入 token 对第 i i i 个输出 token 的影响; O O O 和 T T T分别反映原始和变换后 token 的贡献,以往方法简单用缩放权重量化它们, O O O 通常设为单位矩阵表示原始 token 的自贡献, T T T 则用注意力权重 A A A 表示变换后 token 的缩放; ∇ A p ( c ) \nabla_{A}p(c) ∇Ap(c) 是注意力图关于预测类 c c c 概率的偏导数, E h \mathbb{E}_{h} Eh 是对多头求平均,并且在求平均前去除负贡献以避免失真。
- 方法局限:以往方法的局限性在于假设跳跃连接和注意力权重的影响相同,忽略了原始 token 和变换后 token 之间的差异。这种假设导致在解释模型时,无法准确反映不同 token 的真实贡献,进而影响对模型决策原理的理解。
Token 变换度量-Token Transformation Measurement
这部分主要介绍了为改进视觉 Transformer 解释方法而提出的 token 变换测量方法,通过考虑 token 的长度和方向属性来衡量变换效应,具体内容如下:
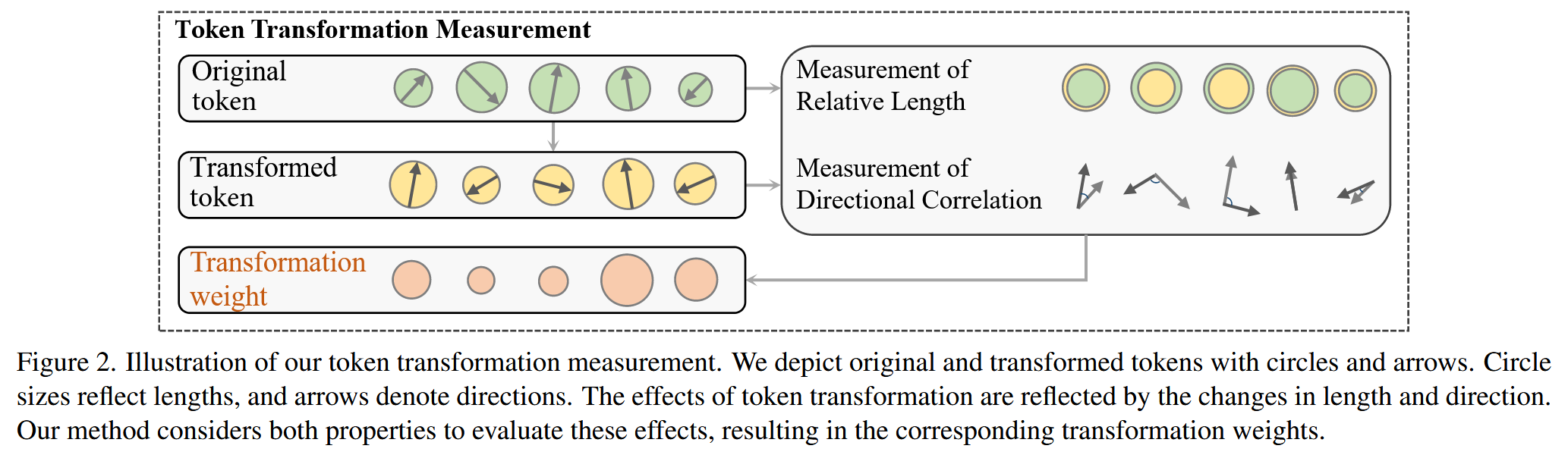
图2. 我们的 token 变换测量的图示。我们用圆形和箭头来表示原始的和经过变换的标记。圆形的大小反映长度,箭头表示方向。标记变换的效果通过长度和方向的变化体现。我们的方法综合考虑这两个属性来评估这些效果,从而得出相应的变换权重。
- 测量背景与目的:为了考量变换后 token 的贡献,引入一种测量方法来评估 token 变换的影响并导出变换权重,以此重新校准相关矩阵,全面捕捉注意力和变换信息。由于 MHSA 和 FFN 在结构上具有统一形式,该测量方法先基于 MHSA 推导,再从通用视角适配到FFN。
- 基于长度的测量:强调 token 的长度和方向是两个核心属性,长度函数 L ( x ) = ∥ x ∥ 2 L(x)=\|x\|_{2} L(x)=∥x∥2 用于测量 token(原始或变换后)在嵌入空间 R d \mathbb{R}^{d} Rd 的长度。基于此,重新定义矩阵 O O O 和 T T T, O = I ⋅ d i a g ( L ( E 1 ) , L ( E 2 ) , ⋯ , L ( E n ) ) O = I \cdot diag\left(L\left(E_{1}\right), L\left(E_{2}\right), \cdots, L\left(E_{n}\right)\right) O=I⋅diag(L(E1),L(E2),⋯,L(En)), T = A ⋅ d i a g ( L ( E ~ 1 ) , L ( E ~ 2 ) , ⋯ , L ( E ~ n ) ) T = A \cdot diag\left(L\left(\tilde{E}_{1}\right), L\left(\tilde{E}_{2}\right), \cdots, L\left(\tilde{E}_{n}\right)\right) T=A⋅diag(L(E~1),L(E~2),⋯,L(E~n)),并通过对 O O O 和 T T T 按原始 token 长度进行列归一化,得到 O = I O = I O=I, T = A ⋅ d i a g ( L ( E ~ 1 ) L ( E 1 ) , L ( E ~ 2 ) L ( E 2 ) , ⋯ , L ( E ~ n ) L ( E n ) ) T = A \cdot diag\left(\frac{L\left(\tilde{E}_{1}\right)}{L\left(E_{1}\right)}, \frac{L\left(\tilde{E}_{2}\right)}{L\left(E_{2}\right)}, \cdots, \frac{L\left(\tilde{E}_{n}\right)}{L\left(E_{n}\right)}\right) T=A⋅diag(L(E1)L(E~1),L(E2)L(E~2),⋯,L(En)L(E~n))。这种处理将原始 token 作为参考单元,通过长度比值体现变换后 token 相对原始 token 的影响,为基于模型输入 token 长度初始化贡献图,并在跨层迭代更新时追踪 token 变换奠定基础。
- 基于方向的测量:token 变换不仅改变长度,还影响方向。采用余弦相似度函数 C ( x , x ~ ) = c o s < x , x ~ > C(x, \tilde{x}) = cos <x, \tilde{x}> C(x,x~)=cos<x,x~> 量化 token 变换前后的方向相关性。但直接将其作为系数可能会使贡献图出现负值,影响聚合结果。为此,提出归一化指数余弦相关(NECC),公式为 N E C C ( i ) = e x p ( C ( E i , E ~ i ) ) ∑ k = 1 n e x p ( C ( E k , E ~ k ) ) NECC(i)=\frac{exp \left(C\left(E_{i}, \tilde{E}_{i}\right)\right)}{\sum_{k=1}^{n} exp \left(C\left(E_{k}, \tilde{E}_{k}\right)\right)} NECC(i)=∑k=1nexp(C(Ek,E~k))exp(C(Ei,E~i)),该方法强调相对相关性大小而非极性,作为有效的正向加权因子,衡量每个变换后 token 与原始 token 的相关程度。
- 综合测量与 FFN 适配:综合长度和方向两个测量维度,定义变换权重 W = d i a g ( L ( E ~ 1 ) L ( E 1 ) N E C C ( 1 ) , ⋯ , L ( E ~ n ) L ( E n ) N E C C ( n ) ) W = diag\left(\frac{L\left(\tilde{E}_{1}\right)}{L\left(E_{1}\right)} NECC(1), \cdots, \frac{L\left(\tilde{E}_{n}\right)}{L\left(E_{n}\right)} NECC(n)\right) W=diag(L(E1)L(E~1)NECC(1),⋯,L(En)L(E~n)NECC(n)),并得到 MHSA 的更新图 U = O + E h [ ( ∇ A p ( c ) ) + ⊙ T ] U = O + \mathbb{E}_{h}[(\nabla_{A}p(c))^{+} \odot T] U=O+Eh[(∇Ap(c))+⊙T] (其中 O = I O = I O=I, T = A ⋅ W T = A \cdot W T=A⋅W) 。对于 FFN 层,因其结构相对简单,为单头且局部加权组合,对上述公式进行调整,去除梯度加权多头积分,将注意力图 A A A 换为单位矩阵,得到 FFN 层的更新图 U = O + T U = O + T U=O+T(其中 O = I O = I O=I, T = I ⋅ W T = I \cdot W T=I⋅W) 。更新图用于捕捉相对效应,在多层聚合时对整体贡献图进行优化。
聚合框架-Aggregation Framework
这部分主要介绍了用于视觉 Transformer 解释的聚合框架,该框架通过初始化和更新规则,整合多层信息,以全面评估 token 的贡献,具体内容如下:
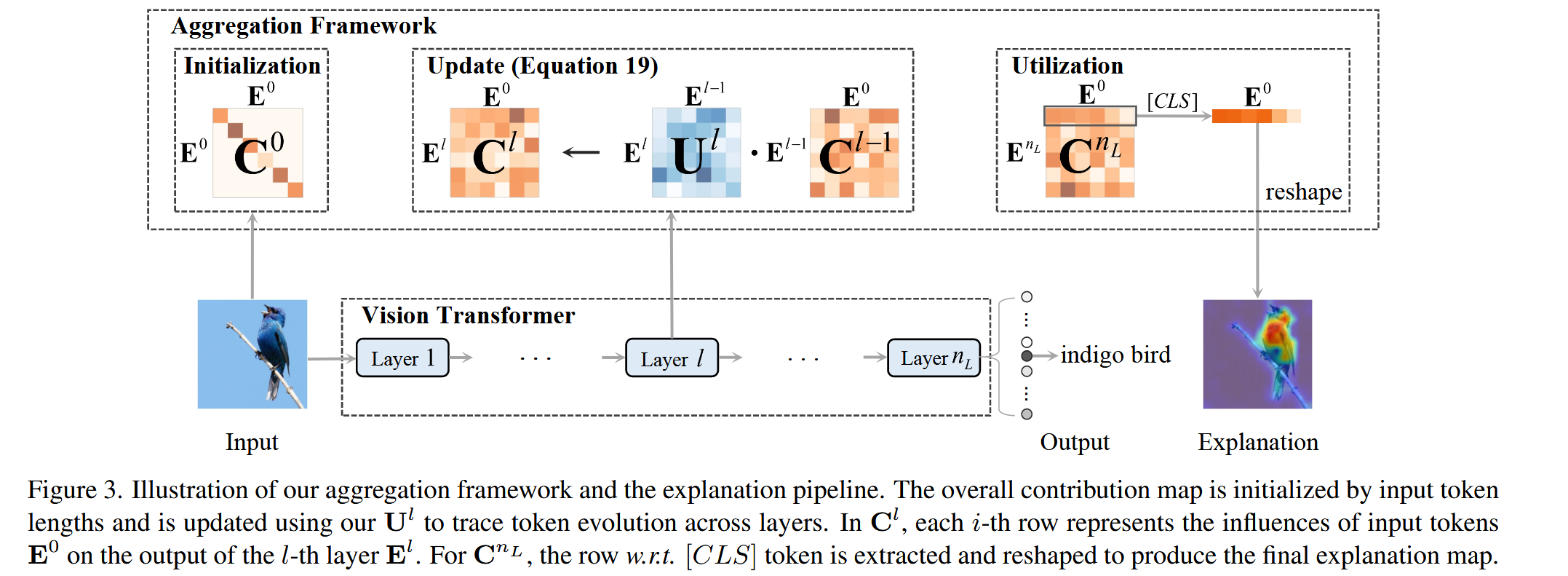
图3. 我们的聚合框架和解释流程的示意图。整体贡献图由输入标记长度初始化,并通过我们的
U
t
U^{t}
Ut 更新,以追踪标记在各层之间的演变。在
C
l
C^{l}
Cl 中,每行第
i
i
i 行表示输入标记
E
0
E^{0}
E0 对第
l
l
l 层输出
E
t
E^{t}
Et 的影响。对于
C
n
L
C^{n_{L}}
CnL,提取与 [CLS] 标记对应的行并重新调整形状,以生成最终的解释图。
- 框架的必要性:在视觉 Transformer 中,token 变换和情境化的影响并非局限于单个图层,而是在各层间累积。为了得到能反映初始 token(对应输入图像区域)作用的综合贡献图,需要评估输入 token 与更深层中演变后的 token 之间的关系,因此引入聚合框架。
- 初始化:用 C ∈ R n × n C \in \mathbb{R}^{n ×n} C∈Rn×n 表示总体贡献图,其中 n n n 是 token 的数量, C i j C_{ij} Cij 用于忠实累积第 j j j 个输入 token 对第 i i i 个输出 token 的影响。在初始状态,输入 token 未经过情境化或变换,此时将贡献图初始化为对角矩阵 C 0 = d i a g ( L ( E 1 0 ) , L ( E 2 0 ) , ⋯ , L ( E n 0 ) ) C^{0}=diag\left(L\left(E_{1}^{0}\right), L\left(E_{2}^{0}\right), \cdots, L\left(E_{n}^{0}\right)\right) C0=diag(L(E10),L(E20),⋯,L(En0)), E 0 E^{0} E0 是输入到第一层 Transformer 的初始嵌入。
- 更新规则:基于信息流动的有向无环图(DAG)表示,层间聚合在数学上等价于中间图的矩阵乘法,这种方式可追踪整个模型中 token 的贡献。初始化后,使用 U l U^{l} Ul 迭代更新贡献图 C l − 1 C^{l - 1} Cl−1,公式为 C l ← U l ⋅ C l − 1 C^{l} \leftarrow U^{l} \cdot C^{l - 1} Cl←Ul⋅Cl−1( l = 1 , 2 , ⋯ , n L l = 1, 2, \cdots, n_{L} l=1,2,⋯,nL) 。其中, C l − 1 C^{l - 1} Cl−1 是已追踪到第 ( l − 1 ) (l - 1) (l−1) 层 token 贡献但未包含第 l l l 层影响的图, U l U^{l} Ul 是第 l l l 层的更新图。经过所有层的更新后,最终贡献图为 C n L = U n L ⋅ U n L − 1 ⋅ ⋯ ⋅ U 1 ⋅ C 0 C^{n_{L}}=U^{n_{L}} \cdot U^{n_{L}-1} \cdot \cdots \cdot U^{1} \cdot C^{0} CnL=UnL⋅UnL−1⋅⋯⋅U1⋅C0. 通过该递归公式,贡献图可聚合整个模型中 token 变换和情境化的信息,从而理解初始输入 token 对最终输出的贡献。
- 框架的作用:该聚合框架提供了对初始输入 token 如何对最终输出产生贡献的累积理解,能够忠实地定位对视觉 Transformer 预测最重要的像素,为模型解释提供更全面、准确的依据。
实验-Experiments
这部分主要介绍了为验证 TokenTM 方法有效性所进行的实验,涵盖基线方法、评估属性、实验结果和消融研究等方面,具体内容如下:
- 基线方法:选取三类广泛应用的方法作为对比基线,包括基于梯度的 Grad-CAM;基于归因的 LRP、Conservative LRP、Transformer Attribution;基于注意力的 Raw Attention、Rollout、ATTCAT、GAE。
- 评估属性
- 定位能力:通过在 ImageNet-Segmentation 数据集上进行分割实验来评估。将解释热图作为初步语义信号,以热图平均值为阈值生成二值分割图,基于真实标签图,使用像素准确率(Pix. Acc.)、平均交并比(mIoU)和平均精度均值(mAP)三个指标衡量解释方法对模型识别的前景对象的定位效果,可靠的解释应能以对象为中心,准确突出模型决策所依据的对象。
- 对精度的影响:在 CIFAR-10、CIFAR-100 和 ImageNet 数据集上进行扰动测试评估。使用预训练的 DeiT 模型,对预测类别和真实类别分别进行正负扰动测试。在正测试中,从最重要到最不重要逐渐移除像素;负测试则相反。通过计算不同扰动水平下精度曲线的曲线下面积(AUC)进行量化评估,可靠的解释应使正测试中模型精度大幅下降,负测试中精度保持稳定。
- 对概率的影响:同样通过扰动测试评估,采用扰动曲线下面积(AOPC)和对数优势分数(LOdds)指标,量化输出概率相对于预测标签的平均变化,在ViT-B和ViT-L模型上进行测试,以衡量解释方法对模型预测概率重要像素的捕捉能力。
- 实验结果
- 定性评估:TokenTM 的解释热图更精确、更全面,能有效消除噪声区域,聚焦于对象,相比其他方法,更能突出对模型预测有重要影响的区域。

图4. 后验解释热图的可视化结果。我们的方法捕捉到了更多以物体为中心的区域,并将其作为(模型预测的)依据。 - 定量评估:在定位能力方面,TokenTM 在像素准确率、mIoU 和 mAP 指标上显著优于所有基线方法;对精度的影响评估中,在正测试中 TokenTM 的 AUC 更低,负测试中更高,表现更优;对概率的影响评估中,TokenTM 在 AOPC 和 LOdds 指标上也取得最佳性能。
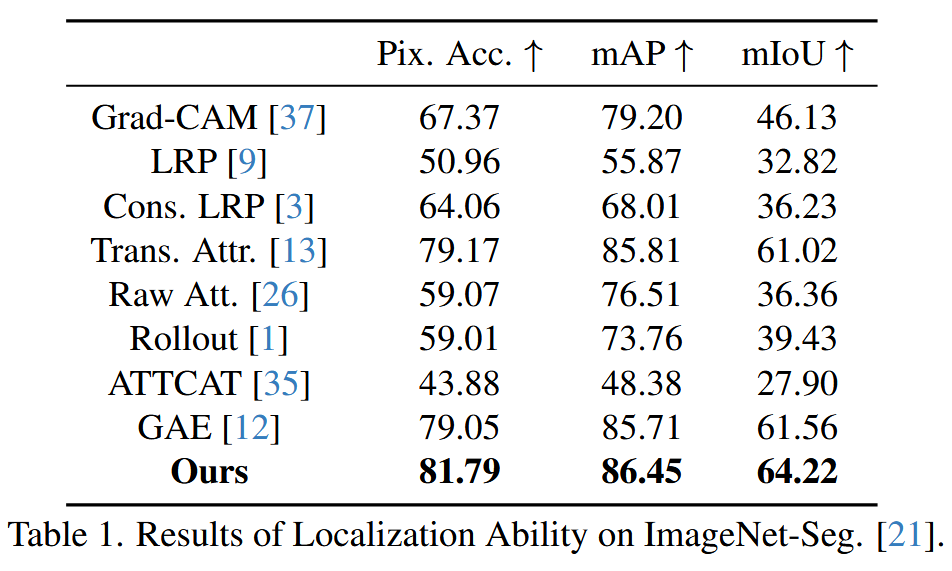
表1. 在 ImageNet-Seg 数据集上的定位能力结果。
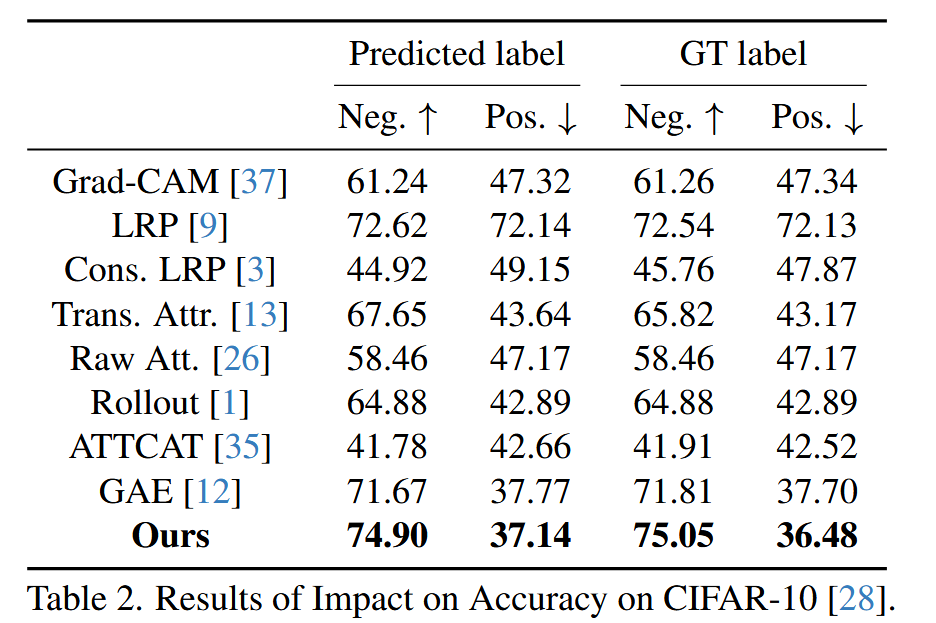
表2. 在 CIFAR-10 数据集上对精度影响的结果。
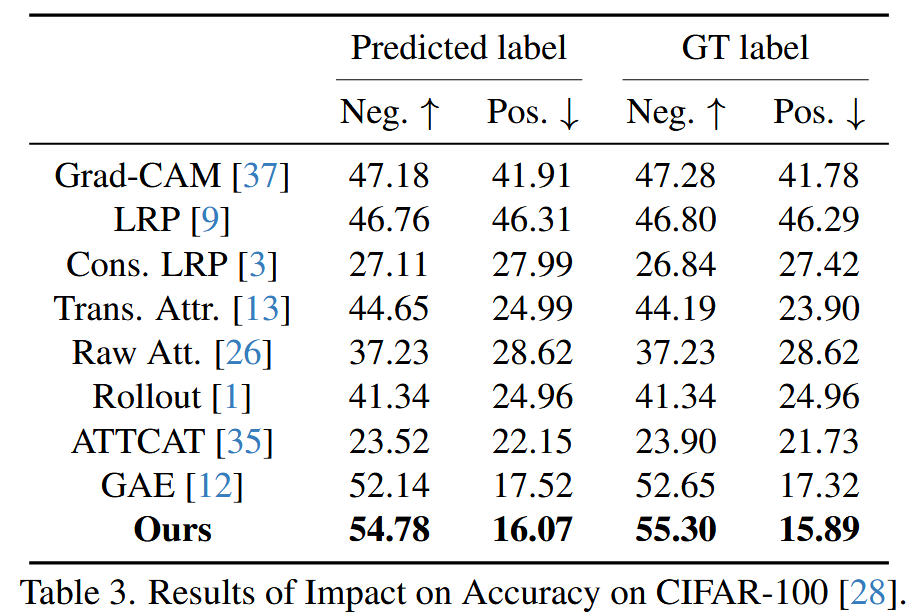
表3. 在 CIFAR-100 数据集上对精度影响的结果。
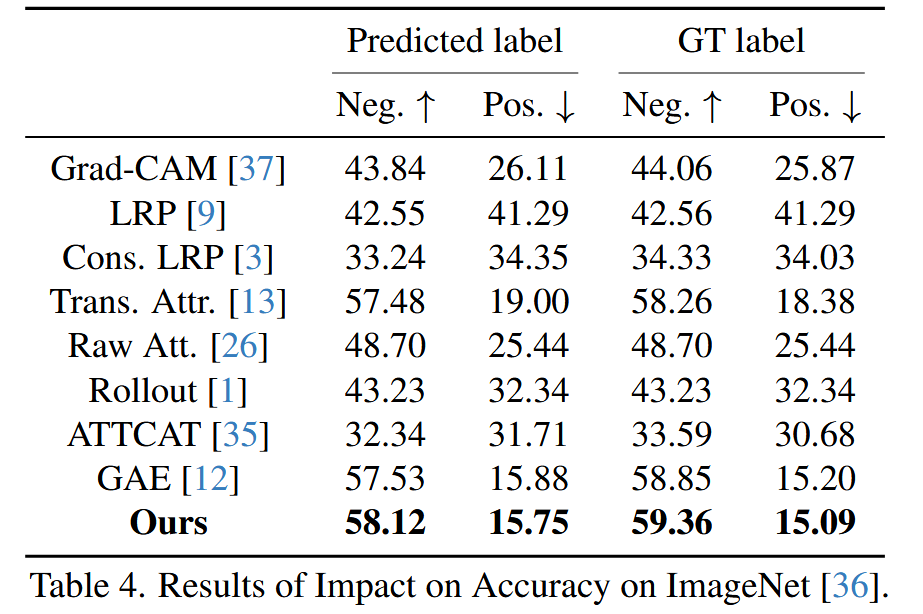
表4. 在 ImageNet 数据集上对精度影响的结果。
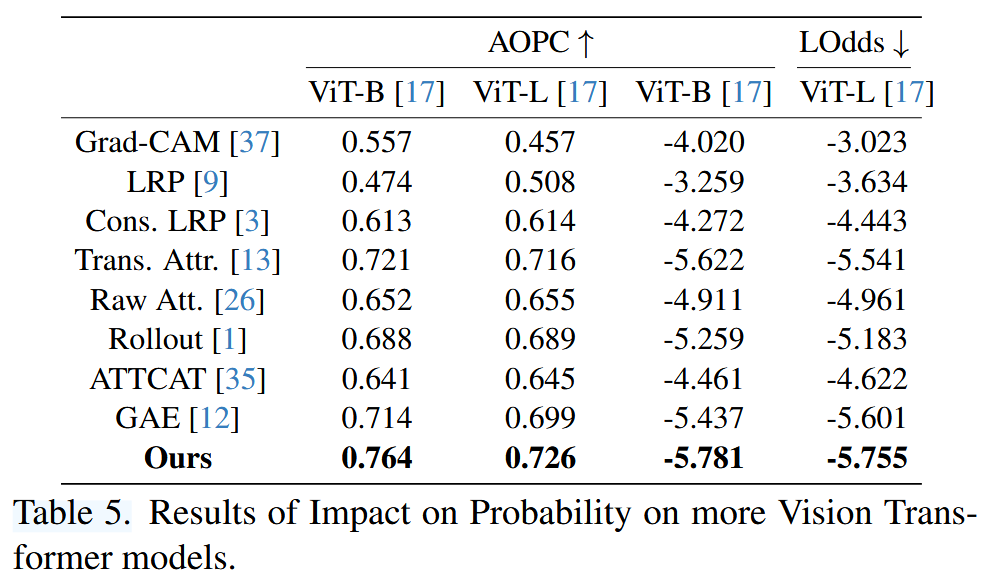
表5. 对更多视觉 Transformer 模型的概率影响结果。
- 定性评估:TokenTM 的解释热图更精确、更全面,能有效消除噪声区域,聚焦于对象,相比其他方法,更能突出对模型预测有重要影响的区域。
- 消融研究
- 组件消融:对 TokenTM 的变换测量(长度测量 L 和 NECC)和聚合框架(AF)进行消融研究。基于 ViT-B 在 ImageNet 上实验,设置四个变体:仅应用基础公式的基线、添加聚合框架的 Baseline + AF、再添加长度测量的 Baseline + AF + L 以及完整的 TokenTM(Baseline + AF + L + NECC)。结果表明,每个组件都能提升在分割和扰动测试中的性能,验证了其有效性。
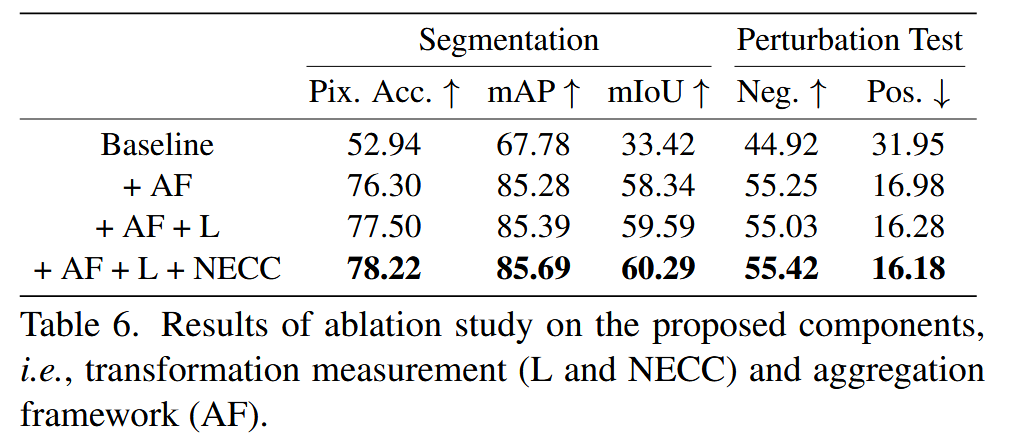
表6. 对所提出组件(即变换测量(L 和 NECC)和聚合框架(AF))的消融研究结果。 - 聚合深度消融:研究聚合深度对 TokenTM 的影响,增加聚合层数从初始少数层到整个网络深度。基于 ViT-B 在 ImageNet 上实验,结果显示随着聚合层数增加,性能不断提升,热图对模型识别对象区域的聚焦效果更好,表明更深层次的聚合对捕捉模型推理的真实原理至关重要。
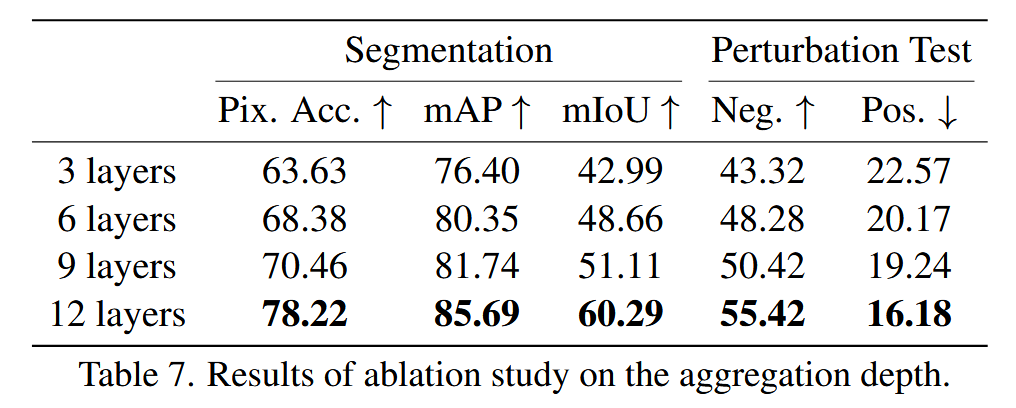
表7. 聚合深度的消融研究结果。
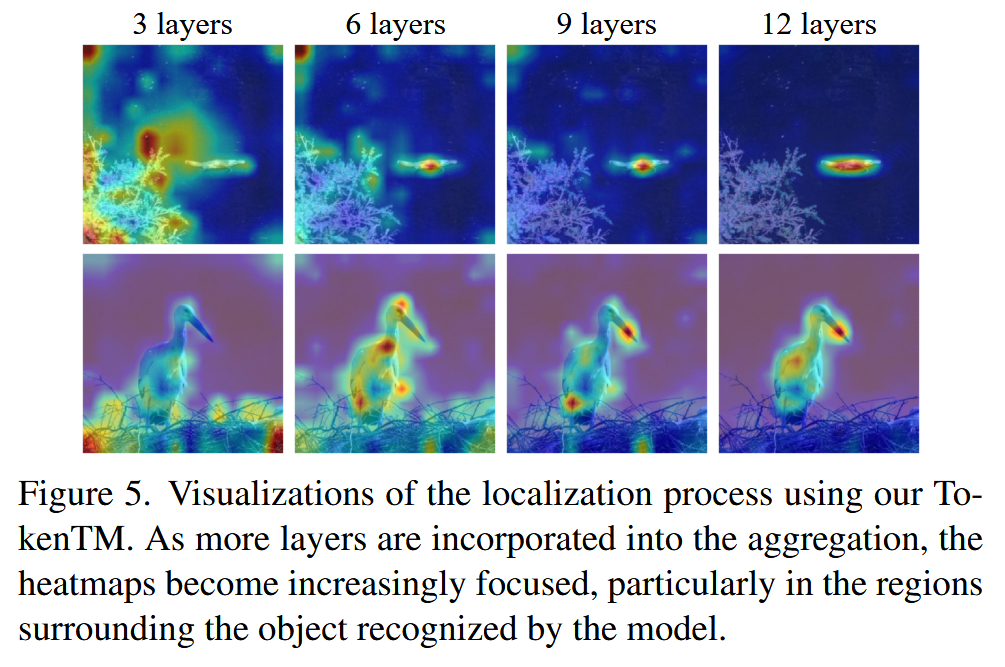
图5. 使用我们的 TokenTM 进行定位过程的可视化。随着聚合中纳入的层数增多,热图变得越来越聚焦,尤其是在模型识别出的物体周围区域。
- 组件消融:对 TokenTM 的变换测量(长度测量 L 和 NECC)和聚合框架(AF)进行消融研究。基于 ViT-B 在 ImageNet 上实验,设置四个变体:仅应用基础公式的基线、添加聚合框架的 Baseline + AF、再添加长度测量的 Baseline + AF + L 以及完整的 TokenTM(Baseline + AF + L + NECC)。结果表明,每个组件都能提升在分割和扰动测试中的性能,验证了其有效性。
结论-Conclusion
在这部分内容中,作者对研究进行回顾总结,点明现有方法问题,突出 TokenTM 方法优势,具体如下:
- 现有方法问题重述:通过重新诠释 Transformer 层,将其表示为原始和变换 token 的加权线性组合,发现现有后验解释方法存在关键缺陷。这些方法仅依赖注意力权重,忽视了 token 变换带来的重要信息,这会导致对模型决策背后的原理产生误解,无法准确解释模型行为。
- TokenTM 方法总结:为解决上述问题,提出 TokenTM 解释方法,该方法主要包含 token 变换测量和聚合框架两部分。通过量化整个模型中输入 token 的贡献,能够为视觉 Transformer 生成更可靠的后验解释,弥补了现有方法的不足,为理解视觉 Transformer 的内部机制提供了更有效的途径。


















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











