






在我2022年出版的《程序员的底层思维》中,关于抽象思维的开篇,我这样写到:“ 每当我对抽象思维有进一步的理解和认知时,我都能切身感受到它给我在编码和设计上带来的变化,同时也不禁感慨之前对它的理解为什么如此肤浅。如果时间可以倒流,我希望在职业生涯的早期就能充分意识到抽象思维的重要性,能多花时间认真研究并深刻理解它,这样应该可以少走很多弯路。 ”
2年时间过去,对于抽象思维在软件设计中的运用,我又有了一些新的体会。这个新体会一句话总结是:做软件抽象设计,从分析变化开始,到沉淀新知识结束。因为内容比较多,我会用两篇文章分别介绍。
1. 代码为什么不能被重用
我们写代码是为了被调用,当只有一个使用场景时,不存在重用问题。如下图所示,出现重用问题,是因为引入了新的场景,有了变化,导致老的代码不能满足新场景的需要,从而出现重用问题。为了解决差异,我们需要重新抽象,新抽象意味着新概念、新知识,这就是我开篇说的,从变化开始,抽象到新知识结束的含义。
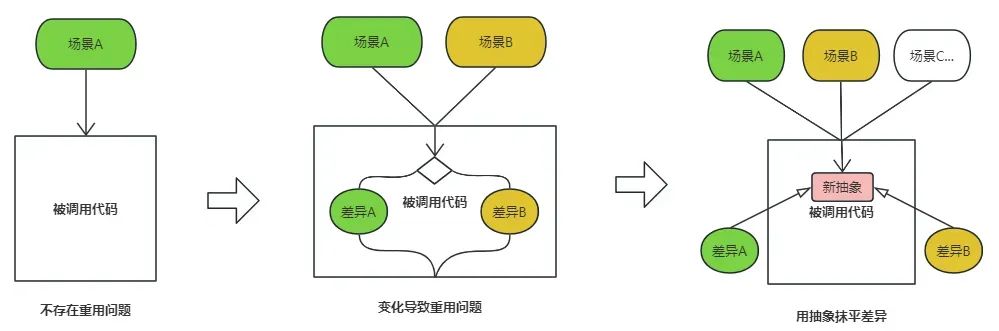
我们可以通过一个简单的案例感受一下这个过程,我写了一个吃苹果的程序eat(Apple apple),有一天我苹果吃腻了,想吃香蕉,问题来了,原来的eat(Apple apple)并不能被重用。差异性体现在Apple和Banana的不同,针对这个变化,我们需要一个新的抽象去抹平差异,关于如何抽象,关键是要寻找共性。Apple和Banana向上抽象的共性是什么呢?这个简单,我们都知道是Fruit,这个Fruit就是我们通过抽象获得的“新知识”、“新概念”。
为了让原来的eat更通用,我们可以用eat(Fruit fruit)来代替eat(Apple apple)。如果有一天我又想吃肉了,那么Fruit的抽象层次也不够了,必须要eat(Food food)才行。如下图所示,最后我们不断演化的过程,就是抽象层次不断提升的过程。(关于抽象层次,推荐去看《程序员的底层思维》)
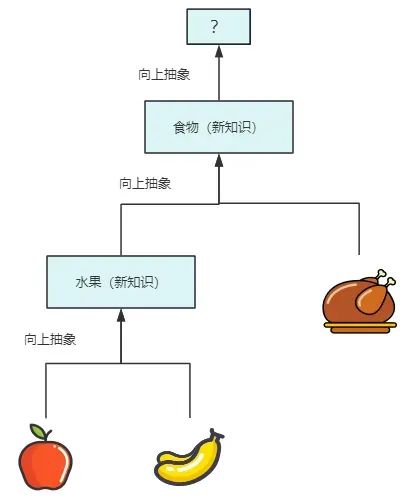
那有同学可能会问,如果一开始能预见到这些变化,那一开始就设计成eat(Food food)岂不是更好?嗯,理论上是这样的。那又有同学说,为了更好地扩展性,我一开始设计成eat(Object object)可以吗?呃…… 一般我们不这么做,除非你是给广东人建模:)因为Object的抽象层次太高了,万物皆对象,在抹平万物的差异的同时,也失去了可理解性,以及业务语义直观表达的能力。
这是一个简单的抽象案例,之所以简单,是因为我们都熟悉水果、食物的概念,抽象起来很容易。而实际工作中,并不是所有的抽象都是如此显而易见,很多时候,我们不得不深入理解问题域,了解很多的背景知识,不断犯错迭代才能挖掘(有时候是创造)出“新知识”,难就难在这个地方。比如在下一篇中我会介绍一个通用规则引擎的实现,里面有一个概念叫Fact(事实),像这样的新概念抽象,就需要我们对问题域有深入的理解,才能建模出来。
以上,我们通过一个类型变化为案例导入,介绍变化和抽象的关系,抽象就是一个使用新概念(新知识)统合差异的过程。所以发现变化、分析变化、明确差异点,找到新概念抹平差异,是我们进行抽象的一般思考路径。实际上,仔细考察软件中代码层面的变化因素,主要有三类变化:
数据变化:比如针对不同的场景,我们需要不同的配置数据。
类型变化:比如上面提到的Apple和Banana的差异。
行为变化:比如我需要用if-else来处理不同的场景。
2. 如何抽象数据变化
程序=数据+算法,数据变化是最常见的变化,如果我们能分离数据变化,算法就可以变得更通用。我们可以用“数据外推”的抽象过程来处理数据变化。这个外推的过程,可以分解成4步:
数据参数化:将可能变化的变量,提升为函数的参数,可提升函数的复用性
参数结构化:将有关联的数据变量聚合成有意义的结构。
结构模型化:按照数据结构的生命周期和使用频率关系,将数据结构进行分类抽象。通过建模让数据结构之间形成关系;
数据配置化:静态数据可以外置成配置文件;动态数据可以外置到DB(DB Schema建模)
我们以一个简单的计算奖金的例子,来阐述这个过程。假设对管理层和普通员工计算奖金的方式是:baseSalary(基础工资)* baseRatio(基础系数)* yearRatio(年系数)* perfmanceScore(绩效分)* years(工作年限)* 奖金因子(yearBonusFactor)
我们最开始的版本是分别有两个函数来处理奖金:
//计算管理层员工的绩效奖金
double calcManagerBonus(double baseSalary, double performanceScore, int years) {
double baseRatio = 4.0;
double yearRatio = 0.5;
return baseSalary * baseRatio * yearRatio * performanceScore * years * 10;
}
//计算普通员工员工的绩效奖金
double calcRegularEmployeeBonus(double baseSalary, double performanceScore, int years) {
double baseRatio = 2.0;
double yearRatio = 0.3;
return baseSalary * baseRatio * yearRatio * performanceScore * years * 5;
}第一步,数据参数化
我们可以通过将变量提升为参数,提升函数的通用性,从而两个函数可以合成一个函数
double calcBonus(double baseSalary, double performanceScore, int years,
double baseRatio, double yearRatio, int yearBonusFactor) {
return baseSalary * baseRatio * yearRatio * performanceScore * years * yearBonusFactor;
}第二步,参数结构化
散落的参数不好管理,要group起来,这里的关键还是抽象,需要一个新概念去把这些参数统合在一起,关于这个新概念,我们暂且就叫BonusParams
class BonusParams {
double baseSalary;
double performanceScore;
int years;
double baseRatio;
double yearRatio;
int yearBonusFactor;
}
double calcBonus(BonusParams bonusParams) {
return bonusParams.baseSalary * bonusParams.performanceScore * bonusParams.years *
bonusParams.baseRatio * bonusParams.yearRatio * bonusParams.yearBonusFactor;
}第三步,结构模型化
观察这个结构实际上是由两部分组成的,一部分是相对静态的系数和因子,一部分是和员工相关的数据。所以可以对现有的结构做进一步分类(建模)。分类也是一种非常关键的思维能力,和抽象思维息息相关。关于更多分类思维的内容推荐阅读《程序员的底层思维》。
class StaticBonusParams {
double baseRatio;
double yearRatio;
int yearBonusFactor;
}
class EmployeeBonusParams{
double baseSalary;
double performanceScore;
int years;
}
double calcBonus(EmployeeBonusParams employeeBonusParams, StaticBonusParams staticBonusParams){
return employeeBonusParams.baseSalary * employeeBonusParams.performanceScore * employeeBonusParams.years *
staticBonusParams.baseRatio * staticBonusParams.yearRatio * staticBonusParams.yearBonusFactor;
}第四步,数据配置化
更进一步,我们可以将StaticBonusParams系数数据放置到配置文件,进一步提升系统应对变化的能力。而EmployeeBonusParams相关的数据会存在和Employee相关的数据库表中。配置化意味着我们可以在Runtime去更改系统的行为,而不用重新发布系统,无疑是提供了更大的灵活性。
ManagerBonusStaticParams:
baseRatio: 4.0
yearRatio: 0.5
yearBonusFactor: 10
RegularEmployeeBonusStaticParams:
baseRatio: 2.0
yearRatio: 0.3
yearBonusFactor: 5以上案例,我们展示了一条关于如何处理数据变化的系统演化路径。通过一层一层的将数据变化抽取、结构化、建模、直到外推到系统之外——配置文件,我们不仅提升了代码的可理解性,也让系统获得了更大的灵活性和可维护性。
3. 如何抽象行为变化、类型变化
相比较于数据变化,类型和行为变化会更加普遍,这同样需要我们有很好的抽象思维。我们还是从案例开始说明这个过程。首先,我们需要对学生按照身高从高到低进行排序,我们写了如下的冒泡排序代码:
public static void sort_students_by_height(Student[] students, int numOfStudents) {
for (int y = 0; y < numOfStudents - 1; y++) {
for (int x = 1; x < numOfStudents - y; x++) {
if (students[x].height > students[x - 1].height) {
swap(students, x, x - 1);
}
}
}
}
private static void swap(Student[] students, int i, int j) {
Student tmp = students[i];
students[i] = students[j];
students[j] = tmp;
}之后,我们又需要对老师按照年龄进行排序,于是,我们又写了如下的代码来实现:
public static void sort_teachers_by_age(Teacher[] teachers, int numOfTeachers) {
for (int y = 0; y < numOfTeachers - 1; y++) {
for (int x = 1; x < numOfTeachers - y; x++) {
if (teachers[x].age > teachers[x - 1].age) {
swap(teachers, x, x - 1);
}
}
}
}
private static void swap(Teacher[] teachers, int i, int j) {
Teacher tmp = teachers[i];
teachers[i] = teachers[j];
teachers[j] = tmp;
}很明显,两段代码功能相似,他们的共性都是实现了冒泡排序。如何对上面的代码进行重构,我们可以从识别变化点开始。对比发现,两段代码主要有以下变化点:
类型变化:排序对象类型(Student类型和Teacher类型)
行为变化:排序比较规则(if语句的条件部分,比较的是height还是age)
如果我们可以把这些变化从代码中分离出来,那么冒泡排序算法本身就可以被独立复用了。要如何抽取呢?这里需要动用我们抽象的核心原则——分析差异性、寻找共性,结合问题域,提炼新概念,沉淀新知识。
Student和Teacher的差异性不必多说,这里的关键是要寻找共性,他们的共性是什么? 我们第一反应可能是他们都是人Human,没错,这是一个共性。你也可以说他们都是求是小学的,没错,这也是共性。但这些抽象对于当前的对象比较问题并没有什么帮助。任何两个事物,如果不加约束的话,我们总是可以从很多角度进行抽象。比如我在《程序员的底层思维》中讲过一个笑话,问:金鱼和激光笔有什么共同之处?答:它们都不会吹口哨。类似这样天马行空的“抽象”,可以说是无穷无尽。但真正有用的抽象是在领域上下文下,对我们解决问题有帮助的抽象。
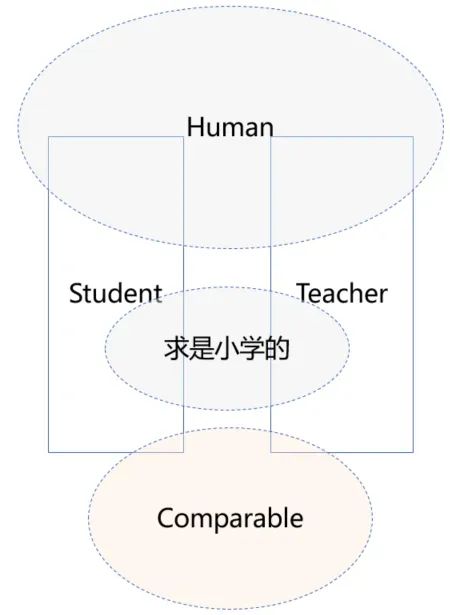
针对当前的排序问题,我们可以说Student和Teacher都是Comparable(可比较的)。使用Comparable抽象,我们解决了Student和Teacher的类型变化问题,与此同时, 行为变化(比较height和age的差异)也能通过compareTo( )这个行为抽象进行抹平,基于这个抹平变化之后的新抽象,我们可以将上面的代码重构为:
public static void bulbSort(Comparable[] objects){
int numOfObjects = objects.length;
for (int y = 0; y < numOfObjects - 1; y++) {
for (int x = 1; x < numOfObjects - y; x++) {
if (objects[x].compareTo(objects[x-1]) > 0) {
swap(objects, x, x - 1);
}
}
}
}
private static void swap(Comparable[] objects, int i, int j) {
Comparable tmp = objects[i];
objects[i] = objects[j];
objects[j] = tmp;
}为了适配新的排序框架,我们的Student和Teacher也要实现Comparable接口:
class Student implements Comparable{
public int height;
public Student(int height) {
this.height = height;
}
@Override
public String toString() {
return String.valueOf(height);
}
@Override
public int compareTo(@NotNull Object o) {
Student other = (Student) o;
return Integer.compare(this.height, other.height);
}
}
class Teacher implements Comparable{
public int age;
public Teacher(int age) {
this.age = age;
}
@Override
public String toString() {
return String.valueOf(age);
}
@Override
public int compareTo(@NotNull Object o) {
Teacher other = (Teacher) o;
return Integer.compare(this.age, other.age);
}
}至此,我们就得到了一个通用的冒泡排序框架,而且其可复用范围远远超出了Student和Teacher,所有实现了Comparable接口的对象都可以通过bulbSort进行排序。这里的关键是我们通过抽象,提炼了一个新的领域概念——Comparable。这里的领域你可以理解为“排序”,事实证明Comparable正是“排序”领域里最核心的概念,在JDK中也占有重要的位置。
这正是合理抽象的意义,我们通过深入洞察事物的本质,分离变化和不变的部分,提炼出重要的领域概念,沉淀重要的领域知识,从而让算法可重用,提升代码的灵活性。
接下来,在下一篇《再谈软件设计中的抽象思维(下)》文章中,我会用规则引擎的案例,进一步阐释抽象思维的妙用。















 6571
6571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









