







本周我们主要收集了训练DrugChat的数据集。
为了训练DrugChat,我们从两个来源(ChEMBL和PubChem)收集药物化合物的指令调优数据。
| Dataset | 药物的数量 | 问题对的数量 |
| CheMBL | 3892 | 129699 |
| PuBChem | 6942 | 13818 |
训练数据准备
ChEMBL数据集:
从ChEMBL网站上收集数据,该网站共包含2,354,965种化合物的信息。我们下载了数据转储的sqlite版本。在整个数据集中,我们确定了14,816种包含药物信息的化合物。在进一步过滤排除描述信息不足的药物后,我们最终得到了一个包含3892种药物的数据集。对于每种药物,我们首先收集其SMILES字符串,代表其分子结构。随后,我们获得了各种分子特征,包括完整的分子式及其酸、碱或中性化合物的分类。此外,我们收集了药物特异性,如作用机制和治疗应用。基于这些属性。
PubChem 数据集:
我们从PubChem网站上收集数据,该网站上有66,469,244种化合物的信息。在这些化合物中,有19319种具有药物信息,在过滤掉缺乏详细文字描述的药物后,我们保留了6942种药物。对于每种药物,我们手机SMILES字符串和描述,然后制作成问答对。
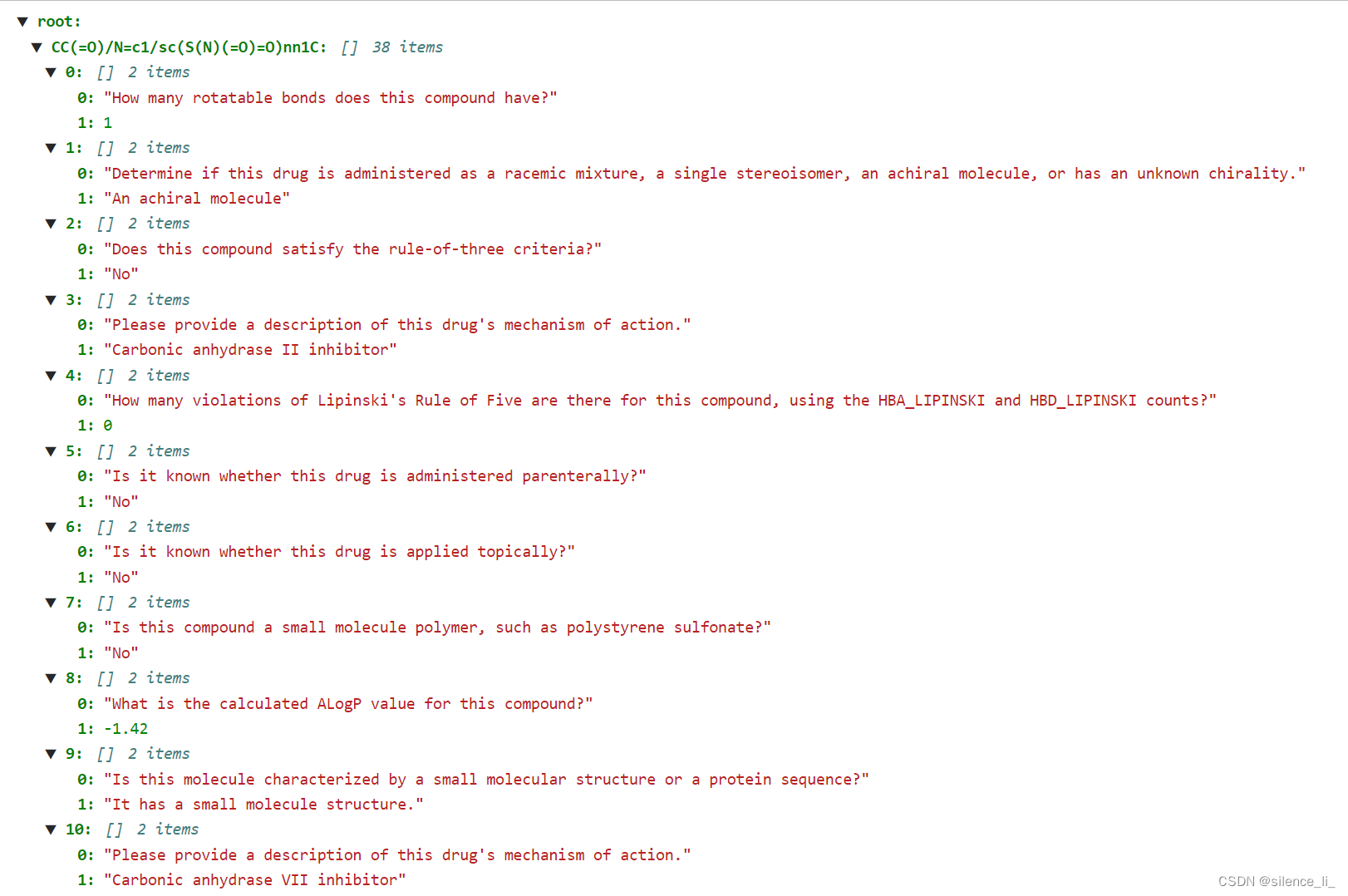
最终我们进行训练使用的数据集结构如下:
使用ChEMBL药物指令调整数据集和PubChem药物指令调整数据集的数据。数据结构如下:data/ChEMBL_QA.json data/PubChem_QA.json {SMILES字符串:[[问题1, 答案1],[问题2, 答案2] …… ]}















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









