







这是大数据课程第四节的笔记,笔者自己的理解使用斜体注明,正确性有待验证。
This is the note of lecture 4 in Big Data Algorithm class. The use of italics indicates the author’s own understanding, whose correctness needs to be verified.
1. Synopsis Structure
Most contents of the synopsis structure are collected from the lecture note in http://www.cohenwang.com/edith/bigdataclass2013 .
1.1. Definition
A small summary of a large data set that (approximately) captures some statistics/properties we are interested in.
Example: random samples, sketches/projections, histograms,…
1.2. Functionality
Some operations, such as insertion, deletion, query and merging databases, may be required.
1.3. Motivation/ Why?
Data can be too large to
- Keep for long or even short term
- Transmit across the network
- Process queries over in reasonable time/computation
1.4. Limitation
The size of working cpu/memory can be limited compared with the size of data.
Only one or two passes of data in cpu are affordable.
1.5. Applications:
network traffic management
I/O Efficiency
Real Time Data
2. Frequent Elements: Misra Gries Algorithm
2.1. Purpose
In brief, the system reads the data in one pass and outputs the frequencies of the top-k most frequent elements.
2.2. Motivation/Application
zipf law: Typical frequency distributions are highly skewed: with few very frequent elements. Say top 10% of elements have 90% of total occurrences. We are interested in finding the heaviest elements.
According to the zipf law, the most frequent elements are significant to represent the data.
Some applications:
- Networking: Find “elephant” flows
- Search: Find the most frequent queries
2.3. A simple algorithm
Simply create a counter for each distinct element and count it in its following occurrence.
However, this algorithm requires about nlogm bits, where n is the number of distinct elements, and
2.4. Misra Gries Algorithm
2.4.1. Insert, Query
1. Place a counter on the first k distinct elements.
2. On the (k + 1)-st elements, reduce each counter by 1 and remove counters of value zero.
3. Report counter value on any query.2.4.2. One simple example for Insertion and Query
The input stream is “abccbcbae” (simply chosen randomly), and the maximum counter number k is 2.
| step number | current element | counter1’s element | counter1’s value | counter2’s element | counter2’s value |
|---|---|---|---|---|---|
| 0 | a | a | 1 | - | - |
| 1 | b | a | 1 | b | 1 |
| 2 | c | - | - | - | - |
| 3 | c | c | 1 | - | - |
| 4 | b | c | 1 | b | 1 |
| 5 | c | c | 2 | b | 1 |
| 6 | b | c | 2 | b | 2 |
| 7 | a | c | 1 | b | 1 |
| 8 | e | - | - | - | - |
2.4.3. Analyze the output
As illustrated in the previous example, the output is obviously an underestimate. However the maximum error is limited. When zipf law / power law property of data holds, the error is acceptable.
m is the total number of elements in the input, and
The error is proportional to the inverse of k . So the error is small when memory is large enough. Furthermore, when
2.4.4. Merge
The merge operation is similar to insertion, as following:
1. Merge the common element counter, keep distinct counters.
2. Remove small counters to keep k largest (by reducing counter then remove counters of value zero.The estimate error is also at most m−m′k+1 . More details can be found in the lecture note in http://www.cohenwang.com/edith/bigdataclass2013 .
3. Stream Counting
3.1. Purpose
The system reads the data in one pass and output the total number of elements. It’s simply a counter.
3.2. A simple algorithm
One simple way is to keep one number as the counter, which increases by one for each element read.
The required space O(logN) , where N is the total number of input.
3.3. Morris’s idea
Instead of counting store
It also uses the powerful tool: randomization, and guarantee that the expectation of the output is the same as the correct output, while saving space.
The algorithm is as follows:
- Keep a counter x of value “
logn ”.- Increase the counter with probability p=2−x .
- On a query, return 2x−1 .
3.4. One example
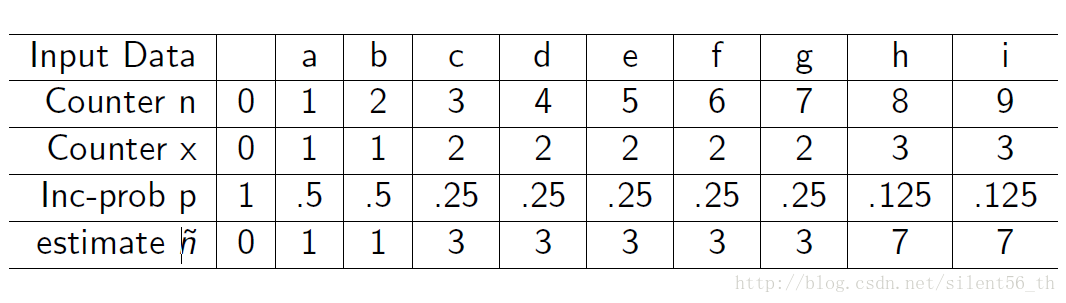
3.5. Analyze: the expected return value
The claim: Expected value after reading n input data is
Proof: Using the inductive principle, the proof is simple.
- Base case: n=0 , x=0 , n^=2x−1=0=n . Base case approved.
- Assume the claim is true for all n≤k , which means EX[n^]=n .
- When n=k+1 , we have
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









